このチュートリアルでは、Azure Toolkit for IntelliJ プラグインを使用して、Scala で記述された Apache Spark アプリケーションを開発し、それを IntelliJ 統合開発環境 (IDE) からサーバーレス Apache Spark プールに直接送信する方法について説明します。 このプラグインには、次のような使い方があります。
- Scala Spark アプリケーションを開発して Spark プール に送信する。
- Spark プール リソースにアクセスする。
- Scala Spark アプリケーションをローカルで開発して実行する。
このチュートリアルでは、以下の内容を学習します。
- Azure Toolkit for IntelliJ プラグインを使用する
- Apache Spark アプリケーションを開発する
- アプリケーションを Spark プールに送信する
前提条件
Azure ツールキット プラグイン 3.27.0-2019.2 - IntelliJ プラグイン リポジトリからインストール
Scala プラグイン - IntelliJ プラグイン リポジトリからインストール。
次の前提条件は、Windows ユーザーのみを対象としています。
Windows コンピューターでローカルの Spark Scala アプリケーションを実行中に、SPARK-2356 で説明されている例外が発生する場合があります。 この例外は、Windows 上に WinUtils.exe がないことが原因で発生します。 このエラーを回避するには、WinUtils 実行可能ファイルをダウンロードして、C:\WinUtils\bin などの場所に保存します。 次に、環境変数 HADOOP_HOME を追加し、この変数の値を C:\WinUtils に設定します。
Spark プールの Spark Scala アプリケーションを作成する
IntelliJ IDEA を起動し、 [Create New Project](新しいプロジェクトの作成) を選択して、 [New Project](新しいプロジェクト) ウィンドウを開きます。
左側のウィンドウから [Apache Spark/HDInsight] を選択します。
メイン ウィンドウから [サンプルありの Spark プロジェクト (Scala)] を選択します。
[Build tool](ビルド ツール) ドロップダウン ボックスの一覧で、次のいずれかの種類を選択します。
- Scala プロジェクト作成ウィザードをサポートする場合は Maven。
- 依存関係を管理し、Scala プロジェクトをビルドする場合は SBT。
![IntelliJ IDEA の [New Project]\(新しいプロジェクト\) ダイアログ ボックス](media/intellij-tool-synapse/create-synapse-application01.png)
[次へ] を選択します。
[New Project](新しいプロジェクト) ウィンドウで、次の情報を指定します。
プロパティ 説明 プロジェクト名 名前を入力します。 このチュートリアルでは myAppを使用します。プロジェクトの場所 プロジェクトを保存する場所を入力します。 Project SDK (プロジェクト SDK) IDEA を初めて使用するとき、これは空白の場合があります。 [New](新規作成) を選択し、自分の JDK に移動します。 Spark バージョン 作成ウィザードにより、Spark SDK と Scala SDK の適切なバージョンが統合されます。 ここでは、必要な Spark バージョンを選択できます。 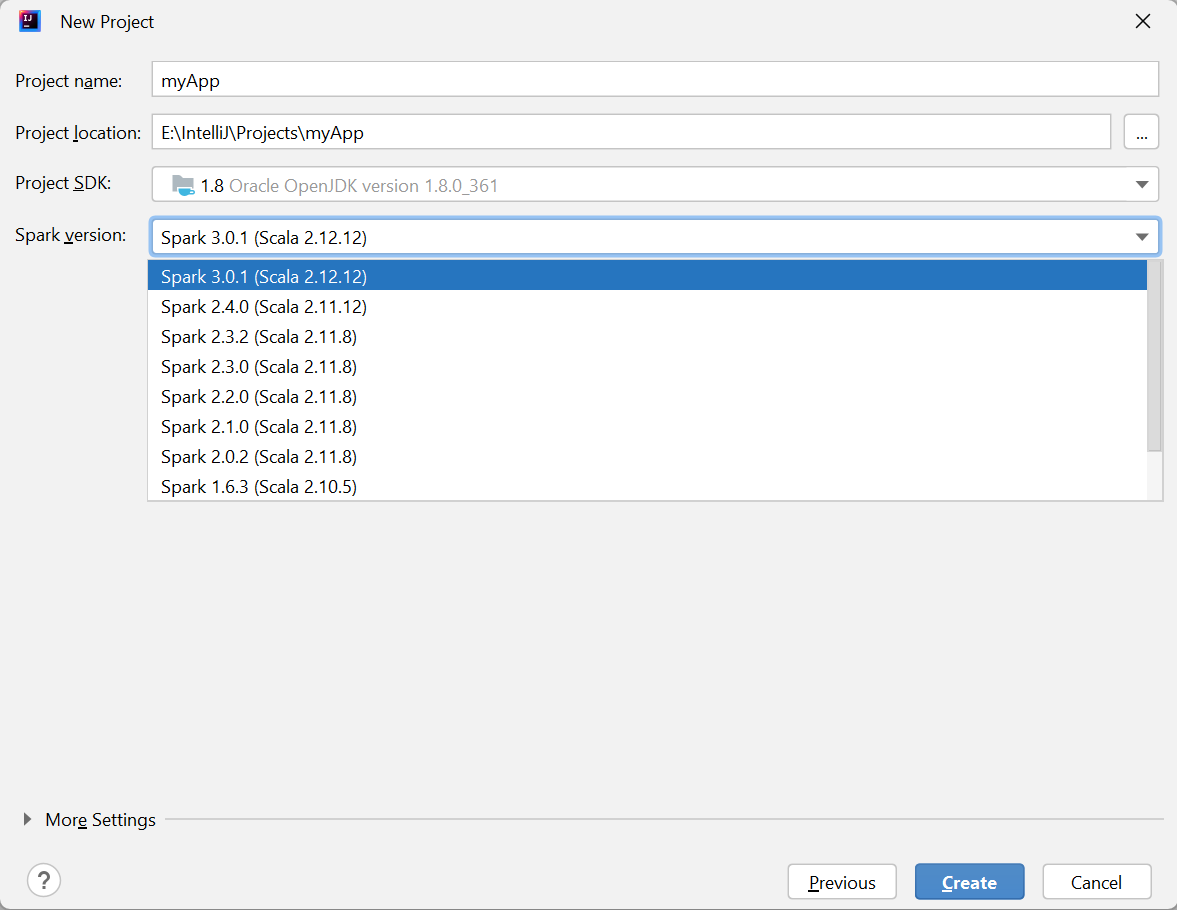
[完了] を選択します。 プロジェクトが使用可能になるまで数分かかる場合があります。
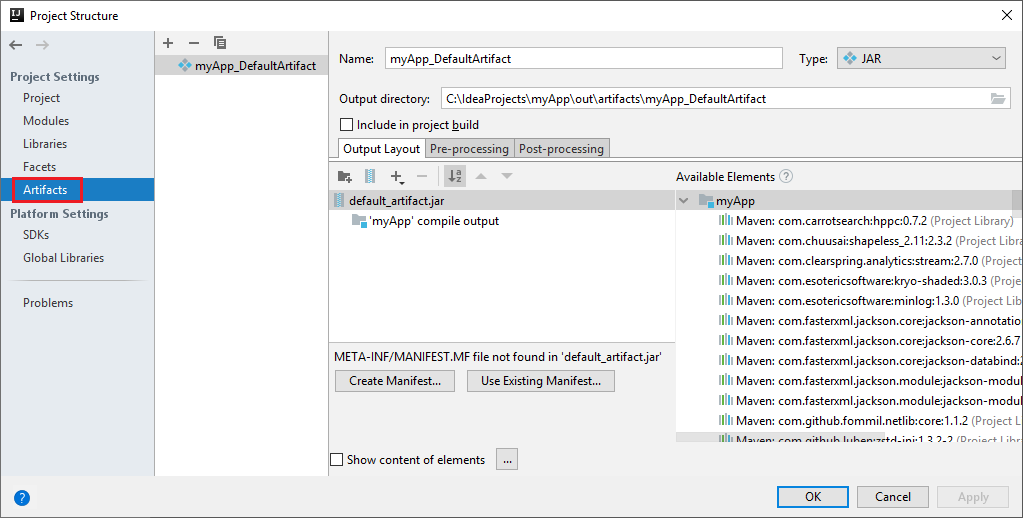
Spark プロジェクトによって自動的に成果物が作成されます。 成果物を表示するには、次の操作を実行します。
a. メニュー バーから、 [ファイル]>[プロジェクトの構造...] に移動します。
b. [プロジェクトの構造] ウィンドウで、 [アーティファクト] を選択します。
c. 成果物の表示後、 [キャンセル] をクリックします。
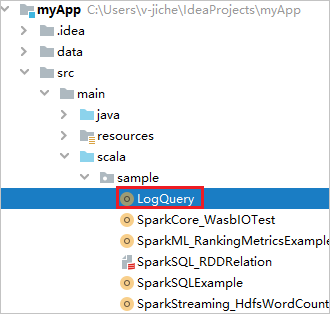
LogQuery を myApp>src>main>scala>sample>LogQuery から見つけます。 このチュートリアルでは、実行に LogQuery を使用します。
Spark プールに接続する
Azure サブスクリプションにサインインして、Spark プールに接続します。
Azure サブスクリプションにサインインします。
メニュー バーから、 [表示]>[ツール ウィンドウ]>[Azure Explorer] に移動します。
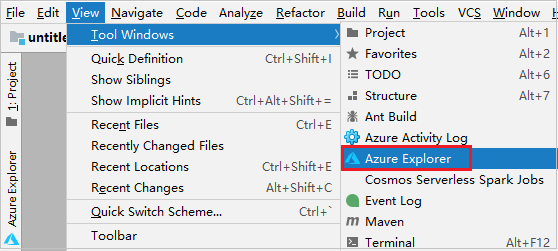
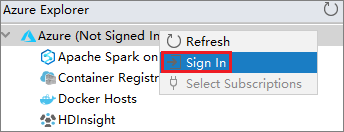
Azure Explorer から、 [Azure] ノードを右クリックし、 [サインイン] を選択します。
[Azure Sign In](Azure サインイン) ダイアログ ボックスで、 [デバイスのログイン] を選択してから、 [サインイン] を選択します。
![IntelliJ IDEA の [Azure Sign In]\(Azure サインイン\)](media/intellij-tool-synapse/intellij-view-explorer2.png)
[Azure Device Login]\(Azure デバイスのログイン\) ダイアログ ボックスで [Copy&Open]\(コピーして開く\) を選択します。
![IntelliJ IDEA の [Azure Device Login]\(Azure デバイスのログイン\)](media/intellij-tool-synapse/intellij-view-explorer5.png)
ブラウザー インターフェイスで、コードを貼り付けて [次へ] を選択します。
![Microsoft の HDI の [コードの入力] ダイアログ](media/intellij-tool-synapse/intellij-view-explorer6.png)
自分の Azure 資格情報を入力して、ブラウザーを閉じます。
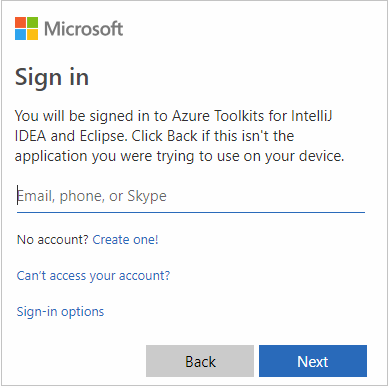
サインイン後、 [Select Subscriptions](サブスクリプションの選択) ダイアログ ボックスに、その資格情報に関連付けられているすべての Azure サブスクリプションの一覧が表示されます。 該当するサブスクリプションを選択して、 [選択] を選択します。
![[サブスクリプションの選択] ダイアログ ボックス](media/intellij-tool-synapse/select-subscriptions.png)
Azure Explorer から、 [Apache Spark on Synapse] を展開し、自分のサブスクリプションにあるワークスペースを表示します。
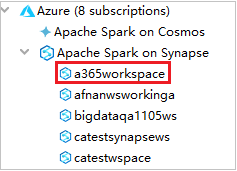
Spark プールを表示するには、ワークスペースをさらに展開します。
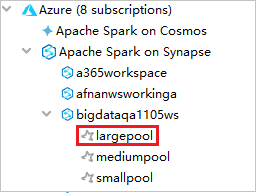
Spark プールの Spark Scala アプリケーションをリモート実行する
Scala アプリケーションを作成した後、これをリモートから実行できます。
アイコンをクリックして、 [Run/Debug Configurations](実行/デバッグ構成) ウィンドウを開きます。
![[Submit Spark Application to HDInsight]\(HDInsight への Spark アプリケーションの送信\) コマンド 1](media/intellij-tool-synapse/open-configuration-window.png)
[Run/Debug Configurations](実行/デバッグ構成) ダイアログ ウィンドウで、 []+ を選択してから、 [Apache Spark on Synapse] を選択します。
![[Submit Spark Application to HDInsight]\(HDInsight への Spark アプリケーションの送信\) コマンド 2](media/intellij-tool-synapse/create-synapse-configuration02.png)
[Run/Debug Configurations](実行/デバッグ構成) ウィンドウで、次の値を指定して [OK] を選択します。
プロパティ 値 Spark プール アプリケーションを実行する Spark プールを選択します。 送信するアーティファクトの選択 既定の設定のままにします。 メイン クラス名 既定値は、選択したファイルのメイン クラスです。 クラスを変更するには、省略記号 ( ... ) をクリックし、別のクラスを選択します。 ジョブの構成 既定のキーと値を変更できます。 詳細については、Apache Livy REST API に関するページを参照してください。 コマンド ライン引数 必要に応じて、main クラスの引数をスペースで区切って入力できます。 参照される JAR と参照されるファイル 参照されている Jar およびファイルのパスを入力できます (存在する場合)。 現在 ADLS Gen2 クラスターのみをサポートする Azure 仮想ファイル システム内のファイルを参照することもできます。 詳細情報:Apache Spark 構成およびリソースをクラスターにアップロードする方法。 ジョブ アップロード ストレージ 展開して追加のオプションを表示します。 ストレージ型 ドロップダウンリストから [Use Azure Blob to upload](Azure BLOB を使用してアップロード) または [Use cluster default storage account to upload](クラスターの既定のストレージ アカウントを使用してアップロード) を選択します。 ストレージ アカウント ストレージ アカウントを入力します。 ストレージ キー ストレージ キーを入力します。 ストレージ コンテナー [ストレージ アカウント] と [ストレージ キー] の入力後、ドロップダウン リストからストレージ コンテナーを選択します。 ![[Spark Submission]\(Spark 送信\) ダイアログ ボックス 1](media/intellij-tool-synapse/create-synapse-configuration03.png)
[SparkJobRun] アイコンを選択して、プロジェクトを選択した Spark プールに送信します。 [Remote Spark Job in Cluster](クラスターのリモート Spark ジョブ) タブの下部には、ジョブの実行の進行状況が表示されます。 赤いボタンを選択すると、アプリケーションを停止できます。
![[Apache Spark Submission]\(Apache Spark 送信\) ウィンドウ](media/intellij-tool-synapse/remotely-run-synapse.png)
![[Spark Submission]\(Spark 送信\) ダイアログ ボックス 2](media/intellij-tool-synapse/remotely-run-result.png)
Apache Spark アプリケーションをローカル実行およびデバッグする
以下の手順に従って、Apache Spark ジョブのローカル実行とローカル デバッグを設定できます。
シナリオ 1:ローカル実行する
[Run/Debug Configurations](実行/デバッグ構成) ダイアログを開き、プラス記号 (+) を選択します。 次に [Apache Spark on Synapse] オプションを選択します。 [名前] 、 [Main class name](メイン クラス名) に保存する情報を入力します。
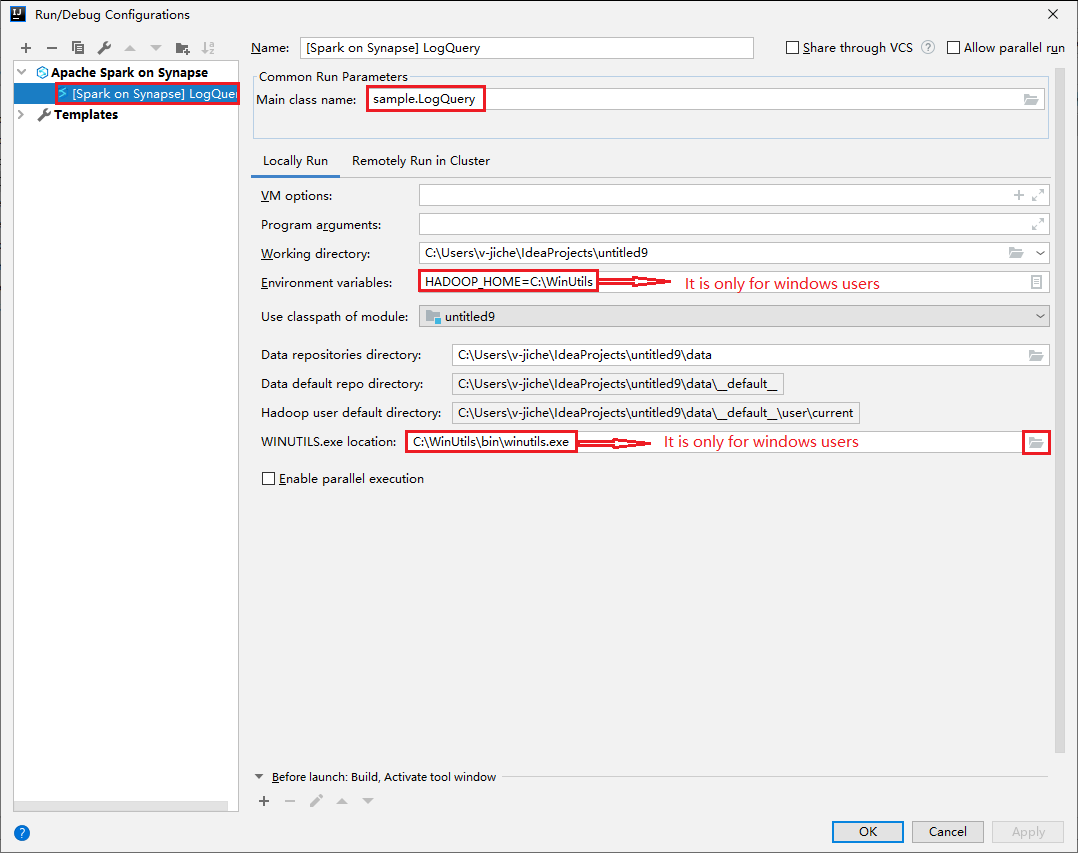
- [環境変数] と [WinUtils.exe Location](WinUtils.exe の場所) は、Windows ユーザーのみを対象としています。
- 環境変数:システム環境変数は、以前設定されている場合は自動検出され、手動で追加する必要はありません。
- [WinUtils.exe Location](WinUtils.exe の場所):WinUtils の場所を指定するには、右側にあるフォルダー アイコンを選択します。
次に、ローカル再生ボタンを選択します。

ローカル実行が完了したら、スクリプトに出力が含まれている場合は、 [data]>[default] から出力ファイルを確認できます。
シナリオ 2: ローカル デバッグを実行する
LogQuery スクリプトを開き、ブレークポイントを設定します。
[ローカル デバッグ] アイコンを選択してローカル デバッグを実行します。

Synapse ワークスペースへアクセスして管理する
Azure Toolkit for IntelliJ 内の Azure Explorer では、さまざまな操作を実行できます。 メニュー バーから、 [表示]>[ツール ウィンドウ]>[Azure Explorer] に移動します。
ワークスペースを起動する
Azure Explorer から、 [Apache Spark on Synapse] に移動して展開します。
ワークスペースを右クリックし、 [ワークスペースの起動] を選択すると、Web サイトが開きます。
Spark コンソール
Spark Local Console(Scala) を実行するか、Spark Livy Interactive Session Console(Scala) を実行することができます。
Spark ローカル コンソール (Scala)
WINUTILS.EXE の前提条件を満たしていることを確実にします。
メニュー バーから、 [Run](実行)>[Edit Configurations](構成の編集) に移動します。
[Run/Debug Configurations](実行/デバッグ構成) ウィンドウから、左側のペインで、 [Apache Spark on Synapse]>[[Spark on Synapse] myApp] を選択します。
メイン ウィンドウで、 [Locally Run](ローカル実行) タブを選択します。
次の値を指定し、 [OK] を選択します。
プロパティ 値 環境変数 HADOOP_HOME の値が正しいことを確認します。 WINUTILS.exe の場所 パスが正しいことを確認します。 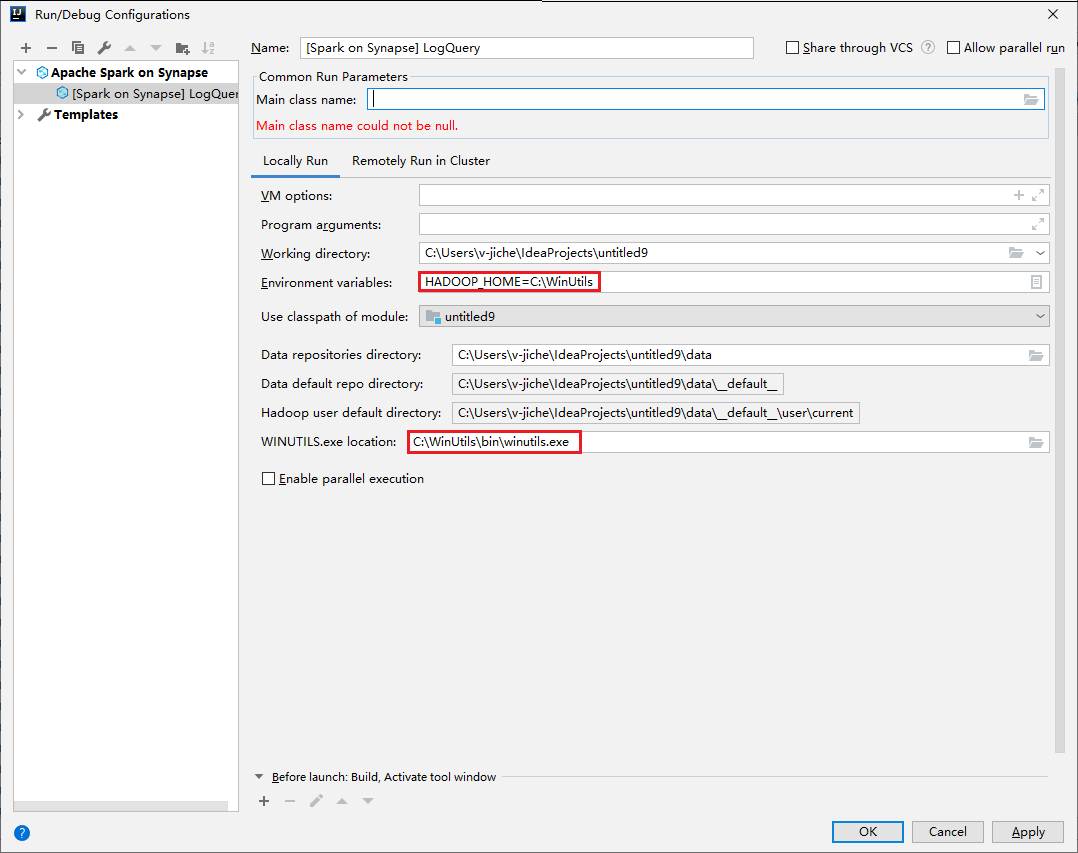
[Project](プロジェクト) から myApp>src>main>scala>myApp に移動します。
メニュー バーから、 [Tools](ツール)>[Spark console](Spark コンソール)>[Run Spark Local Console(Scala)](Spark Local Console(Scala) の実行) に移動します。
次に、依存関係を自動修正するかどうかを確認する 2 つのダイアログ ボックスが表示されます。 そうする場合は、 [Auto Fix](自動修正) を選択します。
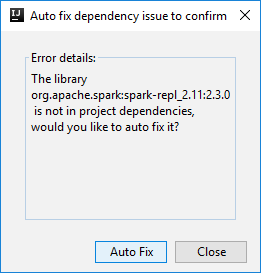
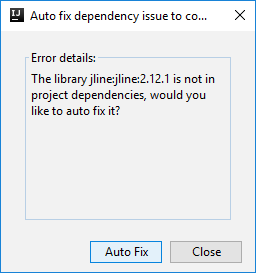
コンソールは次の図のようになります。 コンソール ウィンドウに「
sc.appName」と入力し、Ctrl + Enter キーを押します。 結果が表示されます。 赤いボタンを選択すると、ローカル コンソールを終了できます。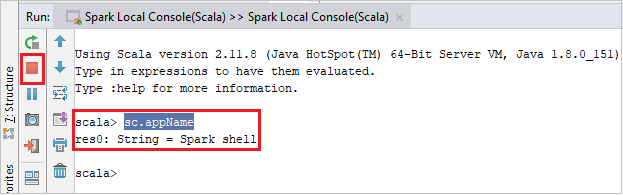
Spark Livy Interactive Session Console (Scala)
これは、IntelliJ 2018.2 および 2018.3 でのみサポートされます。
メニュー バーから、 [Run](実行)>[Edit Configurations](構成の編集) に移動します。
[実行/デバッグ構成] ウィンドウから、左側のペインで、 [Apache Spark on Synapse]>[[Spark on Synapse] myApp] を選択します。
メイン ウィンドウから [Remotely Run in Cluster](クラスターでリモート実行) タブを選択します。
次の値を指定し、 [OK] を選択します。
プロパティ 値 メイン クラス名 Main クラス名を選択します。 Spark プール アプリケーションを実行する Spark プールを選択します。 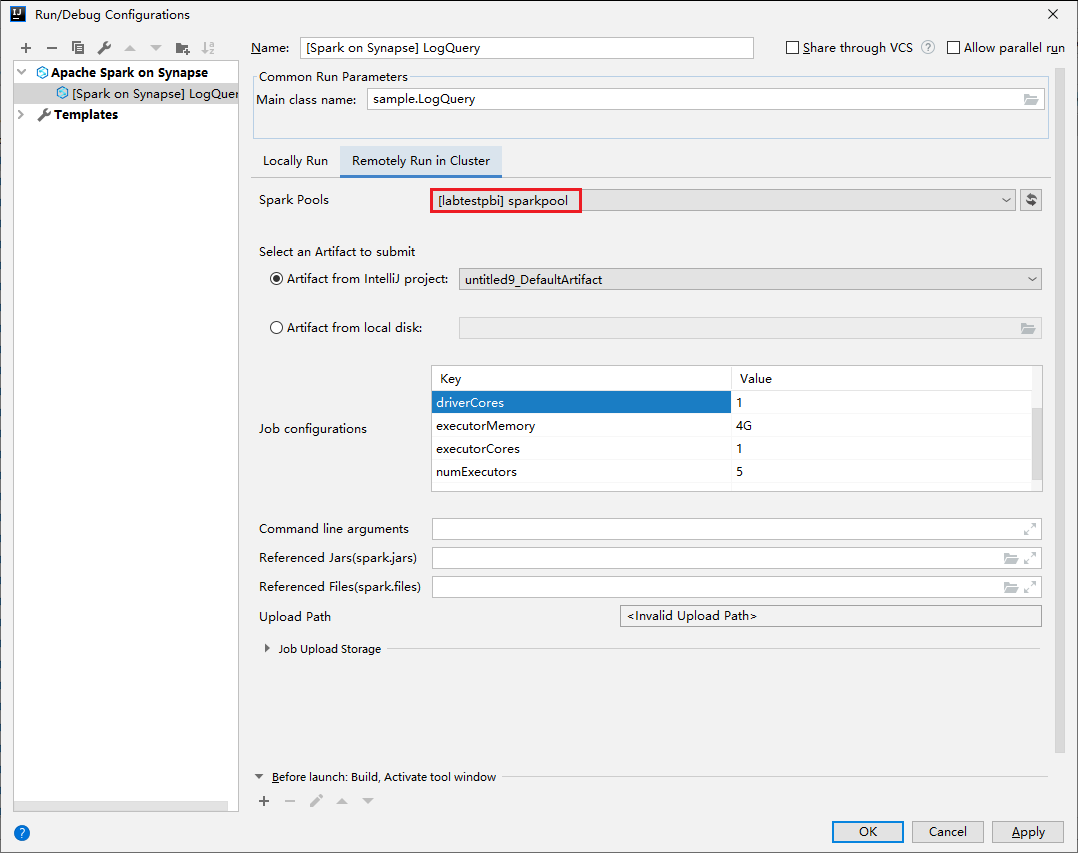
[Project](プロジェクト) から myApp>src>main>scala>myApp に移動します。
メニュー バーで、 [Tools](ツール)>[Spark console](Spark コンソール)>[Run Spark Livy Interactive Session Console(Scala)](Spark Livy Interactive Session Console(Scala) の実行) に移動します。
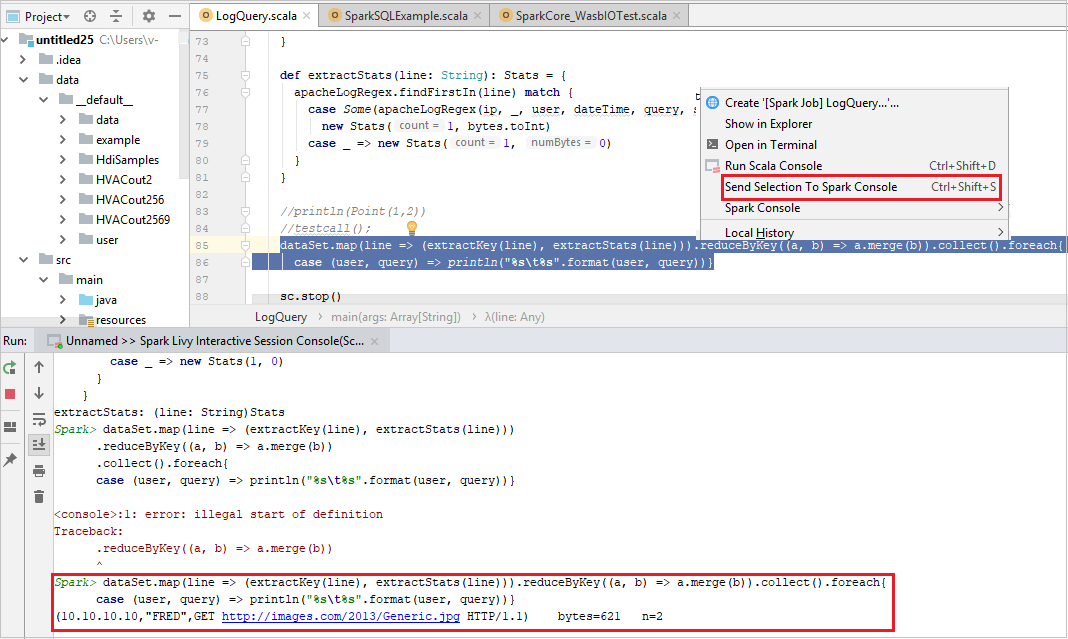
コンソールは次の図のようになります。 コンソール ウィンドウに「
sc.appName」と入力し、Ctrl + Enter キーを押します。 結果が表示されます。 赤いボタンを選択すると、ローカル コンソールを終了できます。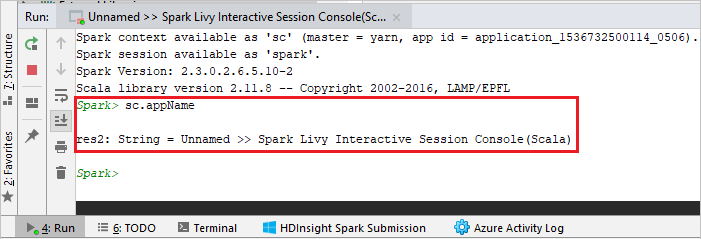
選択内容を Spark コンソールに送信する
ローカル コンソールまたは Livy Interactive Session Console(Scala) に何らかのコードを送信することで、スクリプトの結果を確認することをお勧めします。 それを行うには、Scala ファイル内の一部のコードを強調表示し、 [選択内容を Spark コンソールに送信する] を右クリックします。 選択したコードがコンソールに送信され、実行されます。 結果は、コンソールのコードの後に表示されます。 コンソールでは、既存のエラーが確認されます。