Pandas を使用して、Azure Synapse Analytics のサーバーレス Apache Spark プールを使用して Azure Data Lake Storage Gen2 (ADLS) にデータの読み取り/書き込みを行う方法について説明します。 このチュートリアルの例では、Synapse、Excel ファイル、Parquet ファイルで Pandas を使用して csv データを読み取る方法を示します。
このチュートリアルで学習する内容は次のとおりです。
- Spark セッションで、Pandas を使用して ADLS Gen2 データの読み取り/書き込みを行います。
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
前提条件
Azure Data Lake Storage Gen2 ストレージ アカウントが既定のストレージ (つまりプライマリ ストレージ) として構成されている Azure Synapse Analytics ワークスペース。 使用する Data Lake Storage Gen2 ファイル システムの "Storage Blob データ共同作成者" である必要があります。
Azure Synapse Analytics ワークスペースのサーバーレス Apache Spark プール。 詳細については、Azure Synapse での Spark プールの作成に関する記事を参照してください。
セカンダリ Azure Data Lake Storage Gen2 アカウント (Synapse ワークスペースの既定値ではない) を構成します。 使用する Data Lake Storage Gen2 ファイル システムの "Storage Blob データ共同作成者" である必要があります。
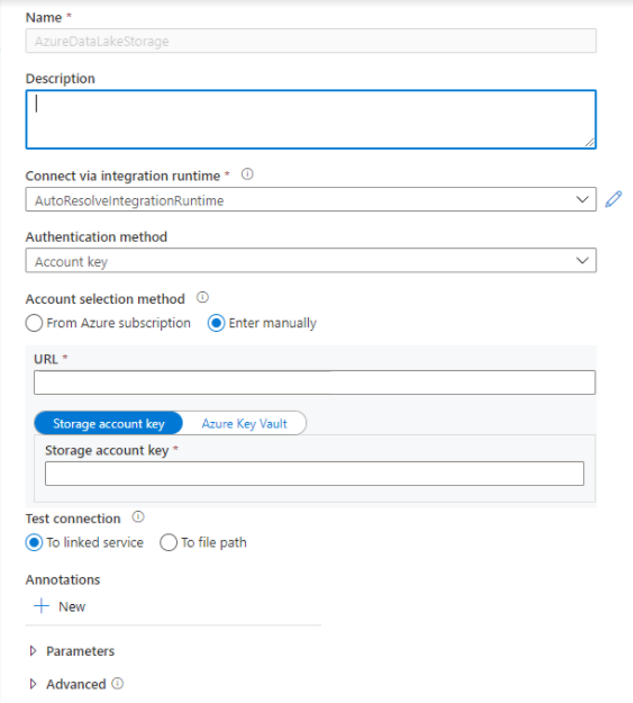
リンクされたサービスを作成します。Azure Synapse Analytics では、リンクされたサービスは、サービスへの接続情報を定義します。 このチュートリアルでは、Azure Synapse Analytics および Azure Data Lake Storage Gen2 のリンクされたサービスを追加します。
- Azure Synapse Studio を開き、[管理] タブを選択します。
- [外部接続] で、[リンクされたサービス] を選択します。
- リンクされたサービスを追加するには、[新規] を選択します。
- リストから [Azure Data Lake Storage Gen2] タイルを選択し、[続行] を選択します。
- ご利用の認証資格情報を入力します。 アカウント キー、サービス プリンシパル (SP)、資格情報、およびマネージド サービス ID (MSI) は、現在サポートされている認証の種類です。 認証のために選択する前に、Storage BLOB データ共同作成者が SP と MSI のストレージに割り当てられていることを確認してください。 ご利用の資格情報が正しいことを確認するために、接続をテストします。 [作成]を選択します
重要
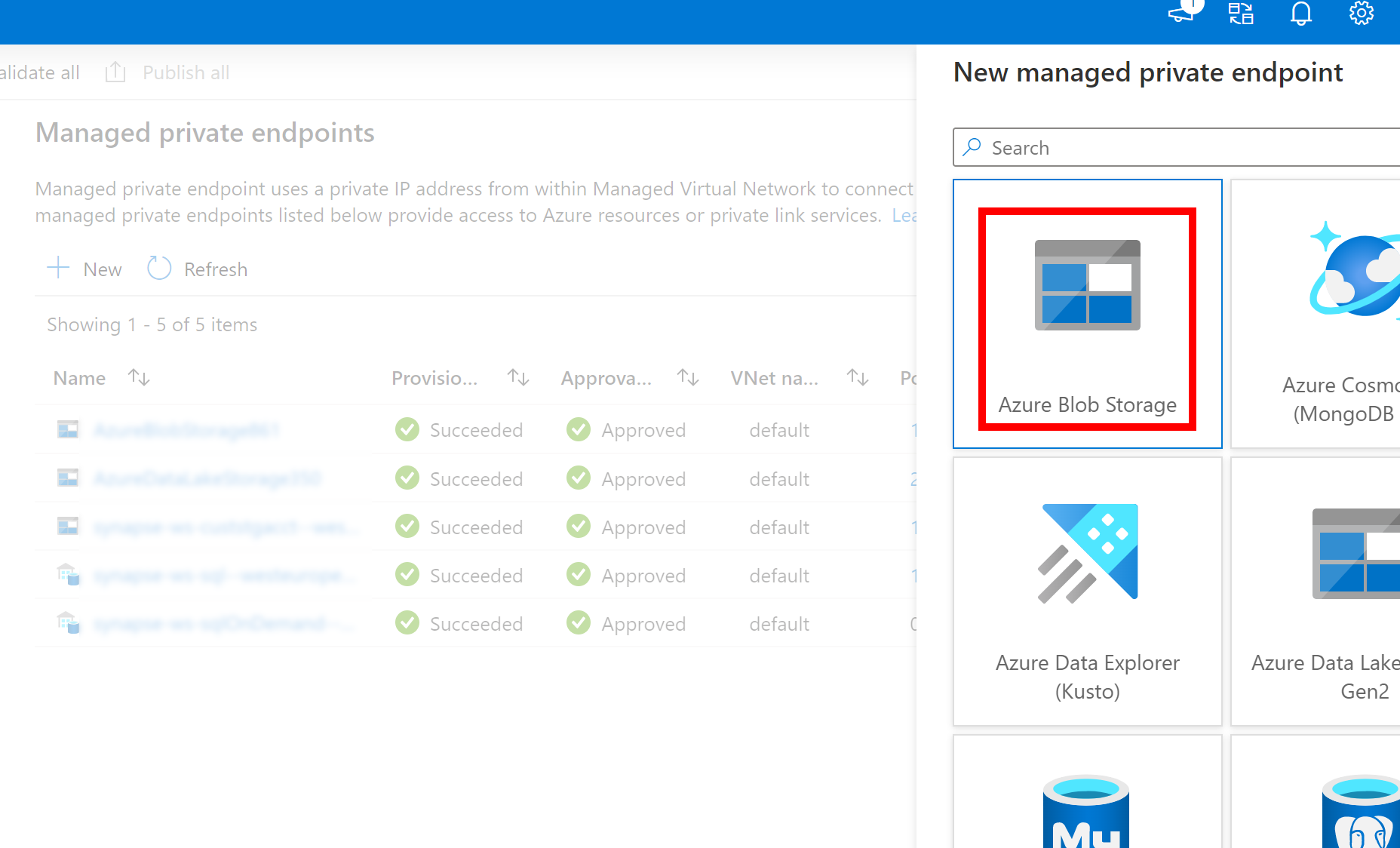
- 上記で作成した Azure Data Lake Storage Gen2 への Linked Service がマネージド プライベート エンドポイント (dfs URI を使用) を使用する場合、内部の fsspec/adlfs コードが BlobServiceClient インターフェイスを使用して接続できるように、Azure Blob Storage オプション (BLOB URI を使用) を使用した別のセカンダリ マネージド プライベート エンドポイントを作成する必要があります。
- セカンダリ マネージド プライベート エンドポイントが正しく構成されていない場合、ServiceRequestError: Cannot connect to host [storageaccountname].blob.core.windows.net:443 ssl:True [Name or service not known] のようなエラー メッセージが表示されます
注意
- Pandas 機能は、Azure Synapse Analytics の Python 3.8 および Spark3 サーバーレス Apache Spark プールでサポートされています。
- 次のバージョンで使用可能なサポート: pandas 1.2.3、fsspec 2021.10.0、adlfs 0.7.7
- Azure Data Lake Storage Gen2 URI (abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path) と FSSPEC の短い URL (abfs[s]://container_name/file_path) の両方をサポートする機能があります。
Azure portal にサインインする
Azure portal にサインインします。
Synapse ワークスペースの既定の ADLS ストレージ アカウントに対してデータの読み取り/書き込みを行う
Pandas は、既定の ADLS Gen 2 ストレージからファイル パスを直接指定することで、ADLS データの読み取り/書き込みを行うことができます。
次のコードを実行します。
注意
このスクリプトのファイル URL を更新してから実行してください。
#Read data file from URI of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://container_name/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path')
セカンダリ ADLS アカウントを使用してデータの読み取り/書き込みを行う
Pandas は、セカンダリ ADLS アカウント データの読み取り/書き込みを、次の方法で行うことができます。
- リンクされたサービスを使用します (ストレージ アカウント キー、サービス プリンシパルなどの認証オプションを使用して、サービス ID と資格情報を管理します)。
- ストレージ オプションを使用して、クライアント ID とシークレット、SAS キー、ストレージ アカウント キー、接続文字列を直接渡します。
次のコードを実行します。
注意
このスクリプトを実行する前に、スクリプトのファイル URL とリンクされたサービス名を更新します。
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'linked_service' : 'linked_service_name'})
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
Parquet ファイルの読み取り/書き込みの例
次のコードを実行します。
注意
このスクリプトのファイル URL を更新してから実行してください。
import pandas
#read parquet file
df = pandas.read_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
print(df)
#write parquet file
df.to_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
Microsoft Excel ファイルの読み取り/書き込みの例
次のコードを実行します。
注意
このスクリプトのファイル URL を更新してから実行してください。
import pandas
#read excel file
df = pandas.read_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ excel_file_path')
print(df)
#write excel file
df.to_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/excel_file_path')