適用対象: Azure Synapse Analytics 専用 SQL プール
ユーザーが専用 SQL プールの列ストア テーブルに対してクエリを実行すると、オプティマイザーによって各セグメントに格納されている最小値と最大値がチェックされます。 クエリ述語の範囲外にあるセグメントは、ディスクからメモリに読み取られません。 読み取るセグメントの数が少なく、その合計サイズが小さい場合、クエリを短時間で完了できます。
注記
この記事は Azure Synapse Analytics 専用 SQL プールに適用されます。 SQL Server およびその他の SQL プラットフォームでの順序指定列ストア インデックスの詳細については、「順序指定クラスター化列ストア インデックスを使用したパフォーマンス チューニング」を参照してください。
順序指定と非順序指定のクラスター化列ストア インデックス
既定では、インデックス オプションを指定せずに作成されたテーブルごとに、内部コンポーネント (インデックス ビルダー) によって非順序指定クラスター化列ストア インデックス (CCI) が作成されます。 各列のデータは、個別の CCI 行グループ セグメントに圧縮されます。 各セグメントの値の範囲にメタデータがあるため、クエリ述語の境界外にあるセグメントがクエリの実行時にディスクから読み取られることはありません。 CCI では、最高レベルのデータ圧縮が提供され、読み取るセグメントのサイズが抑制されるため、クエリをより高速に実行できます。 ただし、インデックス ビルダーはデータをセグメントに圧縮する前に並べ替えないため、値の範囲が重複するセグメントが発生し、その結果、クエリがディスクから読み取るセグメントが増えて、完了にかかる時間が長くなる可能性があります。
効率的なセグメントの削除を有効にして順序付けされたクラスター化列ストア インデックスでは、クエリ述語と一致しない大量の順序付きデータをスキップすることで、パフォーマンスが大幅に向上します。 順序指定 CCI を作成する場合、インデックス ビルダーがインデックス セグメントへと圧縮する前に、専用 SQL プール エンジンによってメモリ内の既存のデータが順序キーで並べ替えられます。 データの並べ替えによってセグメントの重複が減少することで、ディスクから読み取るセグメントの数が少なくなるため、クエリでより効率的なセグメントの除外が行われ、パフォーマンスの高速化が実現します。 メモリ内ですべてのデータを一度に並べ替えられる場合、セグメントの重複を回避することができます。 データ ウェアハウス内のテーブルが大きいため、このシナリオはあまり発生しません。
列のセグメント範囲を確認するには、テーブル名と列名を指定して次のコマンドを実行します。
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
注記
順序指定 CCI テーブルで、DML またはデータ読み込み操作によって同一バッチから作成された新しいデータは、そのバッチの範囲内で並べ替えられます。テーブル内の全データを対象としたグローバルな並べ替えは実行されません。 ユーザーは、順序付きのクラスタ化列ストア・インデックス(CCI)を再構築して、テーブル内のすべてのデータを並べ替えることができます。 専用 SQL プールでは、列ストア インデックスの再構築はオフライン操作です。 パーティション テーブルの場合、再構築は一度に 1 つのパーティションずつ実行されます。 再構築されるパーティション内のデータは "オフライン" であり、そのパーティションの再構築が完了するまで使用できません。
クエリ パフォーマンス
順序指定 CCI から得られるクエリのパフォーマンスの向上は、クエリのパターン、データのサイズ、データの並べ替えがどの程度適切に行われているか、セグメントの物理的構造、およびクエリの実行に対して選択された DWU とリソース クラスによって異なります。 ユーザーは、順序指定 CCI テーブルを設計する際、順序付け列を選択する前に、これらすべての要素を確認する必要があります。
次のすべてのパターンを持つクエリは、通常、順序指定 CCI でより速く実行されます。
- クエリに、等値、非等値、または範囲の述語がある
- 述語列と順序指定 CCI 列が同じである。
この例で、テーブル T1 には、Col_C、Col_B、および Col_A のシーケンスで順序指定されたクラスター化列ストア インデックスがあります。
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
クエリ 1 とクエリ 2 は順序指定された CCI 列をすべて参照するため、そのパフォーマンスは、他のクエリよりも順序指定 CCI のメリットが多くなります。
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
データ読み込みのパフォーマンス
順序指定 CCI テーブルへのデータ読み込みのパフォーマンスは、パーティション テーブルと似ています。 順序指定 CCI テーブルへのデータの読み込みは、データの並べ替え操作のため、非順序指定 CCI テーブルよりも時間がかかる可能性があります。ただし、その後、順序付けされた CCI では、クエリをより高速で実行できます。
例として、スキーマが異なるテーブルへのデータ読み込みのパフォーマンス比較を次に示します。
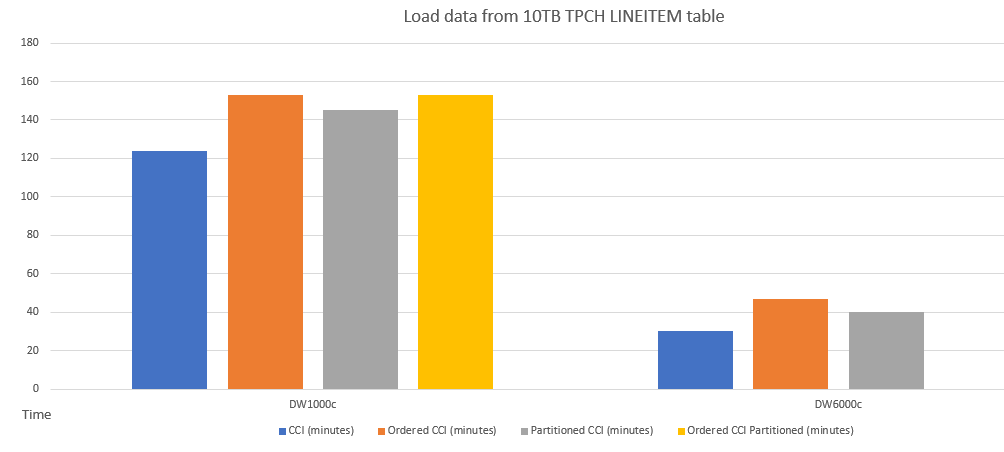
CCI と順序指定 CCI のクエリ パフォーマンスの比較の例を次に示します。
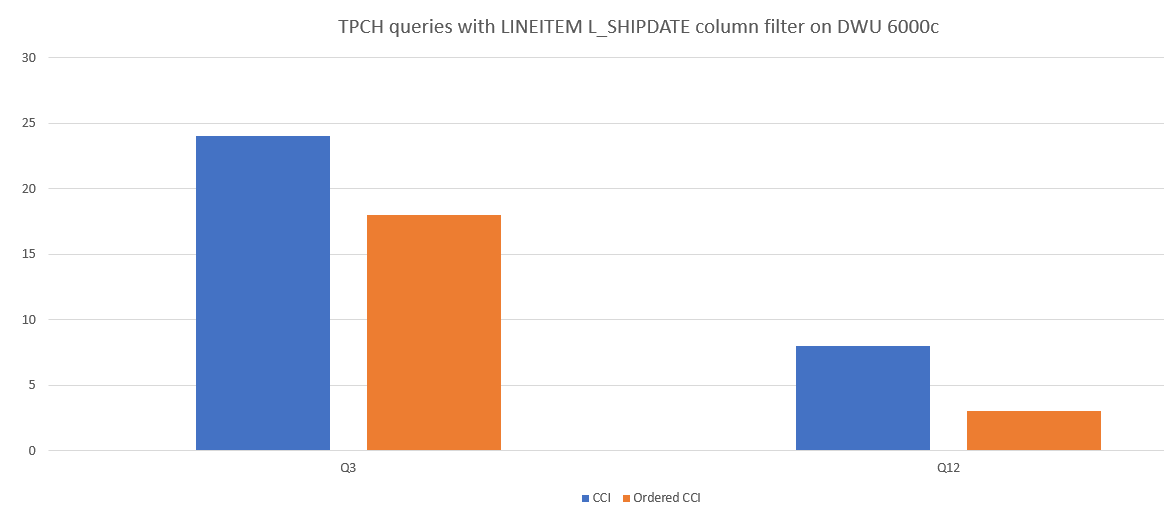
セグメントの重複の抑制
重複するセグメントの数は、並べ替えるデータのサイズ、使用可能なメモリ、および順序指定 CCI 作成時の並列処理の最大限度 (MAXDOP) 設定によって異なります。 次の戦略では、順序指定 CCI を作成するときにセグメントの重複が削減されます。
インデックス ビルダーがデータを複数のセグメントに圧縮する前に、より高い DWU で
xlargercリソース クラスを使用して、データの並べ替え用に、より多くのメモリを準備します。 インデックス セグメント内では、データの物理的な場所を変更することはできません。 セグメント内またはセグメント間でデータの並べ替えが行われることはありません。OPTION (MAXDOP = 1)を指定して順序指定 CCI を作成します。 順序指定 CCI の作成に使用される各スレッドでは、データのサブセットが処理され、ローカルで並べ替えられます。 異なるスレッドによって並べ替えられたデータ全体での並べ替えは行われません。 並列スレッドを使用すると、順序指定 CCI を作成する時間を短縮できますが、単一のスレッドを使用するよりも生成されるセグメントの重複が多くなります。 シングル スレッド操作を使用すると、圧縮品質が最も高くなります。 次に例を示します。
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
注記
現在、Azure Synapse Analytics の専用 SQL プールで MAXDOP オプションがサポートされるのは、CREATE TABLE AS SELECT コマンドを使用した順序指定 CCI テーブルの作成のみです。
CREATE INDEX または CREATE TABLE コマンド経由での順序指定 CCI の作成では、MAXDOP オプションがサポートされません。 この制限は、SQL Server 2022 以降のバージョンには適用されません。これには、CREATE INDEX または CREATE TABLE コマンドで MAXDOP を指定できます。
- 並べ替えキーによってデータを事前に並べ替えてから、テーブルに読み込みます。
上記の推奨事項に従った、重複するセグメントの数が 0 個の順序指定 CCI テーブルの分散の例を次に示します。 順序指定 CCI テーブルは、MAXDOP 1 と xlargerc を使用して 20 GB のヒープ テーブルから CTAS を介して DWU1000c データベースに作成されます。 CCI は、重複なしで BIGINT 列で順序付けされます。
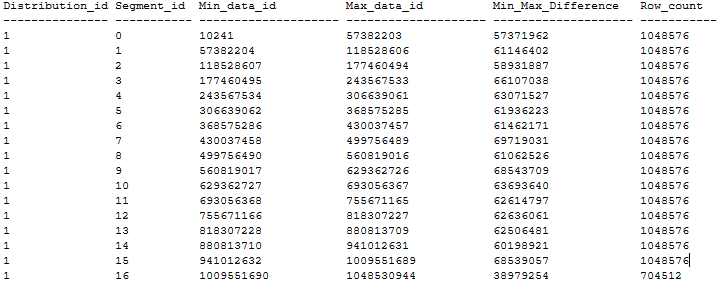
大きなテーブルでの順序指定 CCI の作成
順序指定 CCI の作成はオフライン操作です。 パーティションがないテーブルの場合、順序指定 CCI の作成プロセスが完了するまで、ユーザーはデータにアクセスできません。 パーティション テーブルでは、エンジンによってパーティション単位で順序指定 CCI パーティションが作成されるため、ユーザーは、順序指定 CCI の作成が処理中ではないパーティションのデータにアクセスできます。 このオプションを使用すると、大きなテーブルでの順序指定 CCI の作成時に、ダウンタイムを最小限に抑えることができます。
- ターゲットとなる大きなテーブル (
Table_A) にパーティションを作成します。 - テーブルとパーティションのスキーマが
Table_Aと同じ、空の順序指定 CCI テーブル (Table_B) を作成します。 -
Table_AからTable_Bにパーティションを 1 つ切り替えます。 -
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>を実行して、スイッチイン パーティションをTable_Bに再構築します。 -
Table_Aのパーティションごとに手順 3 および 4 を繰り返します。 - すべてのパーティションが
Table_AからTable_Bに切り替えられて再構築が完了したら、Table_Aをドロップし、Table_Bの名前をTable_Aに変更します。
ヒント
順序付けされた CCI を持つ専用の SQL プール テーブルでは、ALTER INDEX REBUILD は tempdb を使用してデータを再並べ替えします。 再構築操作中に tempdb を監視します。
tempdb 領域がさらに必要な場合は、プールをスケールアップします。 インデックスの再構築が完了したら、スケールダウンします。
順序付けされた CCI を持つ専用の SQL プール テーブルでは、ALTER INDEX REORGANIZE でデータの再並べ替えは行われません。 データを再度並べ替えるには、ALTER INDEX REBUILD を使用します。
順序付けされた CCI メンテナンスの詳細については、「クラスター化列ストア インデックスの最適化」を参照してください。
SQL Server 2022 機能の違い
SQL Server 2022 (16.x) では、 Azure Synapse 専用 SQL プールのフィーチャーと同様の、順序付けされたクラスター化列ストア インデックスが導入されました。
- 現時点では、SQL Server 2022 (16.x) 以降のバージョンでのみ、文字列、バイナリ、guid データ型、および 2 より大きいスケールの datetimeoffset データ型に対して、クラスター化列ストアの拡張セグメント除去機能がサポートされます。 これまで、このセグメントの削除は、数値、日付、時刻のデータ型、およびスケールが 2 以下の datetimeoffset データ型に適用されています。
- 現時点では、SQL Server 2022 (16.x) 以降のバージョンでのみ、
LIKE述語のプレフィックス (column LIKE 'string%'など) に対してクラスター化列ストアの行グループ除去がサポートされます。 LIKE のプレフィックス以外の使用 (column LIKE '%string'など) では、セグメントの削除がサポートされません。
詳細については、「列ストア インデックスの新機能」を参照してください。
例
A. 順序指定された列と序数を確認するには:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. 列序数の変更、順序のリストに対する列の追加または削除を行ったり、CCI から順序指定 CCI に変更したりするには:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
次のステップ
- 開発についてのその他のヒントは、開発の概要に関するページをご覧ください。
- 列ストア インデックス: 概要
- 列ストア インデックスの新機能
- 列ストア インデックス - 設計ガイダンス
- 列ストア インデックス - クエリ パフォーマンス