ヒント
Microsoft Fabric Data Warehouse は、将来のアーキテクチャ、組み込みの AI、および新機能を備えた、Data Lake 基盤上のエンタープライズ 規模のリレーショナル ウェアハウスです。 データ ウェアハウスを初めて使用する場合は、Fabric Data Warehouseから始めます。 既存の dedicated SQL プール ワークロードは、Fabric にアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
- Fabric無料試用版を開始します。
- Fabric Data Warehouse 用マイグレーションアシスタント
OPENROWSET(BULK...) 関数を使用すると、Azure Storage 内のファイルにアクセスできます。
OPENROWSET 関数は、リモート データ ソース (ファイルなど) の内容を読み取って行のセットとして返します。 サーバーレス SQL プール リソース内では、OPENROWSET 関数を呼び出し、BULK オプションを指定することによって、OPENROWSET BULK 行セット プロバイダーにアクセスします。
OPENROWSET 関数は、テーブル名 FROM であるかのように、クエリの OPENROWSET 句で参照できます。 組み込みの BULK プロバイダーによる一括操作がサポートされ、ファイルのデータを行セットとして読み取り、返すことができます。
注意
OPENROWSET 関数は、専用 SQL プールではサポートされていません。
データ ソース
Synapse SQL の OPENROWSET 関数は、データ ソースからファイルの内容を読み取ります。 データ ソースは Azure ストレージ アカウントであり、OPENROWSET 関数で明示的に参照することも、読み取ろうとするファイルの URL から動的に推論することもできます。
OPENROWSET 関数には、必要に応じて、ファイルを含むデータ ソースを指定するための DATA_SOURCE パラメーターを含めることができます。
OPENROWSETを指定しないDATA_SOURCEを使用すると、BULKオプションに指定された URL の場所からファイルの内容を直接読み取ることができます。SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
これは、事前に構成せずに、ファイルの内容をすばやく簡単に読み取ることができる方法です。 この方法では、基本認証オプションを使用してストレージにアクセスできます (Microsoft Entra ログインでは Microsoft Entra パススルー、および SQL ログインでは SAS トークン)。
OPENROWSETを指定したDATA_SOURCEを使用すると、指定したストレージ アカウントのファイルにアクセスできます。SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]この方法では、データソースにストレージ アカウントの場所を構成し、ストレージへのアクセスに使用する認証方法を指定できます。
重要
OPENROWSETを指定しないDATA_SOURCEでは、ストレージ ファイルにすばやく簡単にアクセスできますが、認証オプションが限られます。 例として、Microsoft Entra プリンシパルは、Microsoft Entra ID を使用した場合にのみファイルにアクセスできるほか、公開されているファイルにアクセスすることができます。 より強力な認証オプションが必要な場合は、DATA_SOURCEオプションを使用して、ストレージへのアクセスに使用する資格情報を定義します。
セキュリティ
データベース ユーザーが ADMINISTER BULK OPERATIONS 関数を使用するには OPENROWSET 権限が必要です。
また、ストレージ管理者が、有効な SAS トークンを提供するか、Microsoft Entra プリンシパルでストレージ ファイルにアクセスできるようにして、ユーザーがファイルにアクセスできるようにする必要があります。 ストレージ アクセス制御の詳細については、この記事を参照してください。
OPENROWSET は、次の規則を使用してストレージへの認証方法を決定します。
-
OPENROWSETを指定しないDATA_SOURCEでは、認証メカニズムは呼び出し元の種類によって異なります。- すべてのユーザーは、
OPENROWSETなしでDATA_SOURCEを使用して、Azure Storage で公開されているファイルを読み取ることができます。 - Azure Storage で Microsoft Entra ユーザーによる基になるファイルへのアクセスが許可されている場合 (たとえば、呼び出し元が Azure Storage に対する アクセス許可を持っている場合)、Microsoft Entra ログインは、独自の
Storage Readerを使用して保護されたファイルにアクセスできます。 - SQL ログインは、
OPENROWSETを指定しないDATA_SOURCEを使用して、一般公開されたファイル、または SAS トークンや Synapse ワークスペースのマネージド ID を使用して保護されたファイルにアクセスすることもできます。 ストレージのファイルへのアクセスを許可するには、サーバースコープ資格情報を作成する必要があります。
- すべてのユーザーは、
-
OPENROWSETとDATA_SOURCEの環境で、参照されるデータソースに割り当てられているデータベース範囲の資格情報に認証メカニズムが定義されています。 この方法では、一般公開されているストレージへのアクセスや、SAS トークン、ワークスペースのマネージド ID、または呼び出し元の Microsoft Entra ID (呼び出し元が Microsoft Entra プリンシパルの場合) を使用しているストレージへのアクセスが行えます。 公開されていない Azure Storage をDATA_SOURCEが参照している場合は、データベース スコープ資格情報を作成して、それをDATA SOURCEで参照し、ストレージ ファイルへのアクセスを許可する必要があります。
呼び出し元が、ストレージへの認証に資格情報を使用するには資格情報に対する REFERENCES 権限が必要です。
構文
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
引数
クエリの対象データを含む入力ファイルには、3 つの選択肢があります。 有効な値は次のとおりです。
'CSV' - 行と列の区切り文字によって形式化されたテキストファイル全般を含みます。 任意の文字をフィールド区切り文字として使用できます。例: TSV:FIELDTERMINATOR = tab。
'PARQUET' - Parquet 形式のバイナリ ファイル。
'DELTA' - Delta Lake (プレビュー版) 形式で整理された Parquet ファイルのセット。
空白スペースを含む値は無効です。 たとえば、'CSV ' は有効な値ではありません。
'unstructured_data_path'
データへのパスを確立する unstructured_data_path には、絶対パスまたは相対パスを指定できます。
-
\<prefix>://\<storage_account_path>/\<storage_path>形式の絶対パスを使用すると、ユーザーがファイルを直接読み取ることができるようになります。 -
<storage_path>形式の相対パスは、DATA_SOURCEパラメーターと一緒に使用する必要があり、< に定義された >storage_account_pathEXTERNAL DATA SOURCEの場所にあるファイル パターンを指定します。
以下に、特定の外部データ ソースにリンクする、関連する <ストレージ アカウント パス> 値を示します。
| 外部データ ソース | Prefix | ストレージ アカウント パス |
|---|---|---|
| Azure Blob Storage | http[s] | <storage_account>.blob.core.windows.net/path/file |
| Azure Blob Storage | wasb[s] | <コンテナ>@<ストレージアカウント>.blob.core.windows.net/path/file |
| Azure Data Lake ストア Gen1 | http[s] | <storage_account>.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake ストア Gen2 | http[s] | <storage_account>.dfs.core.windows.net/path/file |
| Azure Data Lake ストア Gen2 | abfs[s] | <file_system>@<account_name>.dfs.core.windows.net/path/file |
'<storage_path>'
読み取り対象のフォルダーまたはファイルを指す、ストレージ内のパスを指定します。 パスがコンテナーまたはフォルダーを指している場合は、その特定のコンテナーまたはフォルダーからすべてのファイルが読み取られます。 サブフォルダー内のファイルは含まれません。
ワイルドカードを使用して、複数のファイルまたはフォルダーを対象にすることができます。 連続しない複数のワイルドカードを使用できます。
次に示すのは、 /csv/population で始まるすべてのフォルダーから、population で始まるすべての csv ファイルを読み取る例です。
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
unstructured_data_path をフォルダーとして指定すると、サーバーレス SQL プール クエリによってそのフォルダーからファイルが取得されます。
例のように、パスの末尾に /* を指定することで、フォルダーをスキャンするようサーバーレス SQL プールに指示できます: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
注意
Hadoop や PolyBase とは異なり、サーバーレス SQL プールの場合、パスの末尾に /** を指定しない限りサブフォルダーは返されません。 Hadoop や PolyBase と同様、名前が下線 (_) やピリオド (.) で始まるファイルは返されません。
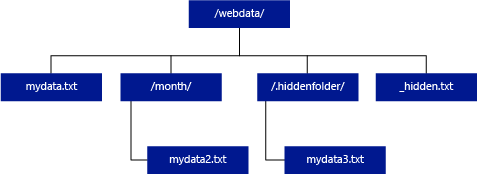
次の例で unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/ の場合、サーバーレス SQL プール クエリによって、mydata.txt から行が返されます。 mydata2.txt と mydata3.txt はサブフォルダー内にあるため、これらは返されません。
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
WITH 句を使用すると、ファイルから読み取る列を指定できます。
CSV データ ファイルの場合、すべての列を読み取るには、列名とそのデータ型を指定します。 列のサブセットが必要な場合は、序数を使用して、元のデータ ファイルから序数で列を選択します。 列は、序数の指定によってバインドされます。 HEADER_ROW = TRUE を使用すると、序数位置ではなく列名によって列バインドが行われます。
ヒント
CSV ファイルの場合は WITH 句を省略することもできます。 データ型は、ファイルの内容から自動的に推論されます。 HEADER_ROW 引数を使用してヘッダー行の存在を指定することができます。この場合、列名はヘッダー行から読み取られます。 詳細については、「スキーマの自動検出」を参照してください。
Parquet または Delta Lake ファイルの場合は、元のデータ ファイル内の列名と一致する列名を指定します。 列は名前によってバインドされます (大文字と小文字が区別されます)。 WITH 句を省略すると、Parquet ファイルのすべての列が返されます。
重要
Parquet および Delta Lake ファイル内の列名では大文字と小文字が区別されます。 大文字と小文字の区別がファイル内の列名と異なる列名を指定すると、その列に対して
NULL値が返されます。
column_name = 出力列の名前。 指定した場合、ソース ファイル内の列名および JSON パスに指定された列名 (存在する場合) は、この名前によってオーバーライドされます。 json_path を指定しなかった場合、"$.column_name" として自動的に追加されます。 動作については、json_path 引数をチェックしてください。
column_type = 出力列のデータ型。 ここでは、暗黙的なデータ型の変換が行われます。
column_ordinal = ソース ファイル内の列の序数番号。 Parquet ファイルの場合、バインドは名前で行われるため、この引数は無視されます。 次の例では、CSV ファイルからのみ 2 列目が返されます。
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = 列または入れ子になったプロパティへの JSON パス式。 既定のパス モードは lax です。
注意
厳格モードでは、指定されたパスが存在しない場合、エラーが発生してクエリが失敗します。 lax モードでは、クエリが成功し、JSON パス式が NULL に評価されます。
<一括オプション>
FIELDTERMINATOR ='field_terminator'
使用するフィールド ターミネータを指定します。 既定のフィールド ターミネータはコンマ (" , ") です。
ROWTERMINATOR ='row_terminator'`
使用する行ターミネータを指定します。 行ターミネータが指定されていない場合は、既定のターミネータの 1 つが使用されます。 PARSER_VERSION = '1.0' の既定のターミネータは、\r\n、\n、および \r です。 PARSER_VERSION = '2.0' の既定のターミネータは、\r\n および \n です。
注意
PARSER_VERSION='1.0' を使用し、\n (改行) を行ターミネータとして指定すると、自動的に \r (キャリッジ リターン) 文字が前に付加され、結果的には行ターミネータが \r\n になります。
ESCAPE_CHAR = 'char'
ファイル内でそれ自体とすべての区切り記号の値をエスケープするために使用するファイル内の文字を指定します。 エスケープ文字の後にそれ自体以外の値、またはいずれかの区切り記号の値が続く場合は、その値を読み取るときにエスケープ文字が削除されます。
ESCAPECHAR パラメーターは、FIELDQUOTE が有効かどうかに関係なく適用されます。 引用文字をエスケープする目的で使われることはありません。 引用文字は、別の引用文字でエスケープする必要があります。 引用文字は、値が引用文字で囲まれている場合にのみ、列の値の中で使用できます。
FIRSTROW = 'first_row'
読み込み開始行の行番号を指定します。 既定値は 1 で、指定のデータ ファイルの先頭行を表します。 行番号は行ターミネータの数をカウントして決定されます。 FIRSTROW は 1 から始まります。
FIELDQUOTE = 'field_quote'
CSV ファイルで引用符文字として使用される文字を指定します。 指定しない場合、引用文字 (") が使用されます。
DATA_COMPRESSION = 'データ圧縮メソッド'
圧縮方法を指定します。 PARSER_VERSION='1.0' でのみサポートされます。 次の圧縮方法がサポートされています。
- GZIP
PARSER_VERSION = 'parser_version'
ファイルの読み取り時に使用するパーサーのバージョンを指定します。 現在サポートされている CSV パーサーのバージョンは 1.0 および 2.0 です。
- PARSER_VERSION = 「1.0」
- PARSER_VERSION = 「2.0」
CSV パーサー バージョン 1.0 が既定であり、機能が豊富です。 バージョン 2.0 はパフォーマンス重視で構築されており、すべてのオプションとエンコードがサポートされているわけではありません。
CSV パーサー バージョン 1.0 の詳細:
- 次のオプションはサポートされていません。HEADER_ROW。
- 既定のターミネータは \r\n、\n、\r です。
- \n (改行) を行ターミネータとして指定すると、自動的に \r (キャリッジ リターン) 文字が前に付加され、結果的には行ターミネータが \r\n になります。
CSV パーサー バージョン 2.0 の詳細:
- すべてのデータ型がサポートされているわけではありません。
- 列の最大長は 8,000 文字です。
- 行の最大サイズの上限は 8 MB です。
- 次のオプションはサポートされていません。DATA_COMPRESSION
- 引用符で囲まれた空の文字列 ("") は、空の文字列として解釈されます。
- DATEFORMAT SET オプションは受け付けられません。
- DATE データ型でサポートされている形式: YYYY-MM-DD
- TIME データ型でサポートされている形式: HH:MM:SS[.秒の小数部]
- DATETIME2 データ型でサポートされている形式: YYYY-MM-DD HH:MM:SS[.秒の小数部]
- 既定のターミネータは \r\n と \n です。
HEADER_ROW = { TRUE | FALSE }
CSV ファイルにヘッダー行を含めるかどうかを指定します。 既定値は FALSE. です。PARSER_VERSION='2.0' でサポートされています。 TRUE の場合、列名は、FIRSTROW 引数に従って最初の行から読み取られます。 TRUE であり、WITH を使用してスキーマを指定すると、列名のバインドは序数位置ではなく列名によって行われます。
DATAFILETYPE = { 'char' | 'widechar' }
エンコードを指定します。UTF8 には char が使用され、UTF16 ファイルには widechar が使用されます。
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
データ ファイル内のデータのコード ページを指定します。 既定値は 65001 (UTF-8 エンコード) です。 このオプションの詳細については、こちらを参照してください。
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
このオプションを選択すると、クエリの実行中にファイル変更チェックが無効にされ、クエリの実行中に更新されたファイルが読み取られます。 これは、クエリの実行中に追加される追加専用ファイルを読み取る必要がある場合に便利なオプションです。 追加可能なファイルでは、既存のコンテンツは更新されず、新しい行の追加のみが行われます。 そのため、更新可能なファイルと比較して、結果が不正確になる可能性が最小限に抑えられます。 このオプションを使用すると、エラーを処理する必要なく、頻繁に追加されるファイルを読み取ることができるようになります。 詳細については、追加可能な CSV ファイルのクエリに関する記事を参照してください。
拒否オプション
注意
拒否された行機能はパブリック プレビュー段階にあります。 拒否された行機能は、区切られたテキスト ファイルと PARSER_VERSION 1.0 で動作することに注意してください。
外部データ ソースから取得したダーティ レコードがどのように処理されるかを決める reject パラメーターを指定できます。 データ レコードが "ダーティ" と見なされるのは、実際のデータ型が外部テーブルの列の定義と一致しない場合です。
拒否オプションを指定も変更もしないと、既定値が使用されます。 サービスによって拒否オプションが使用され、実際のクエリが失敗する前に拒否できる行数が決定されます。 拒否のしきい値を超えるまで、クエリの (部分的な) 結果が返されます。 その後、適切なエラー メッセージと共に失敗します。
MAXERRORS = reject_value
クエリが失敗するまでに拒否できる行数を指定します。 MAXERRORS は 0 から 2,147,483,647 までの整数にする必要があります。
ERRORFILE_DATA_SOURCE = データ ソース
拒否された行と対応するエラー ファイルが書き込まれるデータ ソースを指定します。
ERRORFILE_LOCATION = ディレクトリの場所
指定された場合、拒否された行と対応するエラーファイルが書き込まれるディレクトリとして、DATA_SOURCE または ERROR_FILE_DATASOURCE 内のディレクトリを指定します。 指定したパスが存在しない場合、サービスによってそのパスが作成されます。 "rejectedrows" という名前で子ディレクトリが作成されます。" " 文字があることで、場所パラメーターで明示的に指定されない限り、他のデータ処理ではこのディレクトリがエスケープされます。 このディレクトリ内には、読み込み送信時刻に基づいて作成されたフォルダーが存在し、これは次の形式になっています: YearMonthDay_HourMinuteSecond_StatementID (例: 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891)。 ステートメント id を使用して、フォルダーをその生成元のクエリと関連付けることができます。 このフォルダーには、2 つのファイルが書き込まれます。具体的には、error.json ファイルとデータ ファイルです。
error.json ファイルには、拒否された行に関連する、発生したエラーの json 配列が含まれています。 エラーを表す各要素には、次の属性が含まれています。
| 属性 | 説明 |
|---|---|
| エラー | 行が拒否された理由。 |
| 行 | ファイル内の拒否された行の序数。 |
| 列 | 拒否された列の序数番号。 |
| 値 | 拒否された列の値。 値が 100 文字を超える場合は、最初の 100 文字のみが表示されます。 |
| ファイル | 行が属しているファイルのパス。 |
高速の区切りテキスト解析
使用できる区切りテキスト パーサーのバージョンは 2 つあります。 既定の CSV パーサー バージョン 1.0 は機能が豊富です。一方、パーサー バージョン 2.0 はパフォーマンス重視で構築されています。 パーサー 2.0 のパフォーマンス強化は、高度な解析手法とマルチスレッド処理によってもたらされています。 ファイル サイズが大きくなるほど、速度の違いが大きくなります。
スキーマの自動検出
スキーマがわからない場合や、WITH 句を省略してスキーマを指定していない場合でも、CSV と Parquet の両方のファイルに簡単にクエリを実行できます。 列名とデータ型はファイルから推論されます。
Parquet ファイルには、読み取られる列のメタデータが含まれています。型マッピングについては、「Parquet の型マッピング」を参照してください。 サンプルについては、「スキーマを指定せずに Parquet ファイルを読み取る」を参照してください。
CSV ファイルの場合、列名はヘッダー行から読み取ることができます。 HEADER_ROW 引数を使用して、ヘッダー行が存在するかどうかを指定できます。 HEADER_ROW = FALSE の場合、汎用の列名が使用されます: C1、C2、...Cn の n はファイル内の列番号です。 データ型は、最初の 100 データ行から推論されます。 サンプルについては、「スキーマを指定せずに CSV ファイルを読み取る」を参照してください。
一度に多数のファイルを読み取る場合、スキーマはストレージから取得した最初のファイル サービスから推測されることに注意してください。 これは、スキーマを定義するためにサービスで使用されるファイルにこれらの列が含まれていなかったため、予想される列の一部が省略されていることを意味する場合があります。 その場合は、OPENROWSET WITH 句を使用してください。
重要
情報不足のために適切なデータ型を推論できず、代わりにより大きいデータ型が使用される場合もあります。 この場合、パフォーマンスのオーバーヘッドが発生します。特に、varchar (8000) として推論される文字型の列で大きな影響があります。 最適なパフォーマンスを得るには、推論されたデータ型を確認し、適切なデータ型を使用します。
Parquet の型マッピング
Parquet および Delta Lake ファイルには、すべての列のデータ型の記述が含まれています。 次の表では、Parquet 型を SQL ネイティブ型にマップする方法について説明します。
| Parquet 型 | Parquet 論理型 (注釈) | SQL データ型 |
|---|---|---|
| BOOLEAN | bit | |
| BINARY / BYTE_ARRAY | varbinary | |
| DOUBLE | float | |
| FLOAT | real | |
| INT32 | INT | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| 固定長バイト配列 | binary | |
| バイナリ | UTF8 | varchar *(UTF8 照合順序) |
| バイナリ | STRING | varchar *(UTF8 照合順序) |
| バイナリ | ENUM | varchar *(UTF8 照合順序) |
| 固定長バイト配列 | UUID(ユニバーサルユニーク識別子) | ユニーク識別子 |
| バイナリ | DECIMAL | 10 進 |
| バイナリ | JSON | varchar(8000) *(UTF8 照合順序) |
| バイナリ | BSON | サポートされていません |
| 固定長バイト配列 | DECIMAL | 10 進 |
| バイト配列 | インターバル | サポートされていません |
| INT32 | INT(8, true) | smallint |
| INT32 | INT(16, 真) | smallint |
| INT32 | INT(32, true) | INT |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | INT |
| INT32 | INT(32, false) | bigint |
| INT32 | 日付 | 日付 |
| INT32 | DECIMAL | 10 進 |
| INT32 | 時間 (ミリ秒) | 時間 |
| INT64 | INT(64, 真) | bigint |
| INT64 | INT(64, false) | decimal (20,0) |
| INT64 | DECIMAL | 10 進 |
| INT64 | 時間 (マイクロ秒) | 時間 |
| INT64 | 時間 (ナノ秒) | サポートされていません |
| INT64 | TIMESTAMP (UTC に正規化) (MILLIS/MICROS) | datetime2 |
| INT64 | TIMESTAMP (UTCに非正規化) (MILLIS/MICROS) | bigint - datetime 値に変換する前に、bigint 値がタイムゾーン オフセットで明示的に調整されていることを確認します。 |
| INT64 | TIMESTAMP (NANOS) | サポートされていません |
| 複合型 | リスト | varchar(8000)、JSON にシリアル化 |
| 複合型 | マップ | varchar(8000)、JSON にシリアル化 |
例示
スキーマを指定せずに CSV ファイルを読み取る
次の例では、列名とデータ型を指定せずに、ヘッダー行を含む CSV ファイルを読み取ります。
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
次の例では、列名とデータ型を指定せずに、ヘッダー行を含まない CSV ファイルを読み取ります。
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
スキーマを指定せずに Parquet ファイルを読み取る
次の例では、列名とデータ型を指定せずに、census データ セットの最初の行のすべての列が Parquet 形式で返されます。
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
スキーマを指定せずに Delta Lake ファイルを読み取る
次の例では、列名とデータ型を指定せずに、census データ セットの最初の行のすべての列が Delta Lake 形式で返されます。
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
CSV ファイルから特定の列を読み取る
次の例では、population*.csv ファイルから序数 1 と 4 の 2 列だけが返されます。 ファイルにはヘッダー行がないため、最初の行から読み取りを開始します。
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Parquet ファイルから特定の列を読み取る
次の例では、census データ セットから最初の行の 2 列のみが Parquet 形式で返されます。
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
JSON パスを使用して列を指定する
WITH 句で JSON パス式を使用する例を次に示します。lax パス モードと厳格モードの違いについても説明しています。
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
複数のファイルまたはフォルダーを BULK パスで指定する
次の例は、BULK パラメーターで複数のファイルまたはフォルダーのパスを使用する方法を示しています。
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
次のステップ
その他のサンプルについては、データ ストレージに対するクエリに関するクイックスタートを参照して、OPENROWSET を使用して CSV、PARQUET、DELTA LAKE、および JSON ファイル形式を読み取る方法について学習してください。 最適なパフォーマンスが得られるように、ベスト プラクティスをご確認ください。 また、CETAS を使用してクエリの結果を Azure Storage に保存する方法も確認できます。