Tip
Microsoft Fabric Data Warehouse は、将来のアーキテクチャ、組み込みの AI、および新機能を備えた、Data Lake 基盤上のエンタープライズ 規模のリレーショナル ウェアハウスです。 データ ウェアハウスを初めて使用する場合は、Fabric Data Warehouseから始めます。 既存の dedicated SQL プール ワークロードは、Fabric にアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
- Fabric無料試用版を開始します。
- Fabric Data Warehouse 用マイグレーションアシスタント
外部テーブルは、Hadoop、Azure Storage Blob、または Azure Data Lake Storage (ADLS) にあるデータを参照します。
Azure Storage 内のファイルからデータを読み取ったり、ファイルにデータを書き込んだりするために、外部テーブルを使用できます。 Azure Synapse SQL では、外部テーブルを使用し、専用 SQL プールまたはサーバーレス SQL プールを使って外部データを読み取ることができます。
外部データ ソースの種類に応じて、次の 2 種類の外部テーブルを使用できます。
- Hadoop 外部テーブル。各種データ形式 (CSV、Parquet、ORC など) のデータを読み取ったりエクスポートしたりする際に使用できます。 Hadoop 外部テーブルは、専用 SQL プールでは利用できますが、サーバーレス SQL プールでは利用できません。
- ネイティブ外部テーブル。各種データ形式 (CSV、Parquet など) のデータの読み取りとエクスポートに使用できます。 ネイティブ外部テーブルは、サーバーレス SQL プールと専用 SQL プールで利用できます。 CETAS とネイティブ外部テーブルを使用したデータの書き込み/エクスポートは、サーバーレス SQL プールでのみ使用できますが、専用 SQL プールでは使用できません。
Hadoop 外部テーブルとネイティブ外部テーブルの主な違い:
| 外部テーブルの種類 | Hadoop | ネイティブ |
|---|---|---|
| 専用 SQL プール | 対応可能 | Parquet のみ |
| サーバーレス SQL プール | 使用不可 | 対応可能 |
| サポートされるフォーマット | 区切り形式 (CSV)、Parquet、ORC、Hive RC、RC | サーバーレス SQL プール: 区切り形式 (CSV)、Parquet、Delta Lake 専用 SQL プール: Parquet |
| フォルダー パーティションの除外 | いいえ | パーティションの除外は、Apache Spark プールから同期される Parquet 形式または CSV 形式で作成されたパーティション テーブルでのみ使用できます。 Parquet パーティション フォルダー上の外部テーブルを作成することはできますが、パーティション分割列はアクセス不能になり、無視されます。一方、パーティションの除外は適用されません。 Delta Lake フォルダー上の外部テーブルは作成しないでください。これらはサポートされていないためです。 パーティション分割された Delta Lake データのクエリを実行する必要がある場合は、Delta パーティション ビューを使用します。 |
| ファイルの削除 (述語プッシュダウン) | いいえ | Yes (サーバーレス SQL プールの場合)。 文字列のプッシュダウンでは、Latin1_General_100_BIN2_UTF8 列に VARCHAR の照合順序を使用して、プッシュダウンを有効にする必要があります。 照合順序の詳細については、「Azure Synapse Analytics での Synapse SQL のデータベース照合順序のサポート」を参照してください。 |
| 場所のカスタム形式 | いいえ | はい。Parquet 形式または CSV 形式に /year=*/month=*/day=* などのワイルドカードを使用します。 カスタム フォルダー パスは Delta Lake では使用できません。 サーバーレス SQL プールでは、再帰的なワイルドカード /logs/** を使って、参照先フォルダーの下にある任意のサブフォルダー内の Parquet または CSV ファイルを参照することもできます。 |
| 再帰的フォルダー スキャン | はい | はい。 サーバーレス SQL プールでは、ロケーション パスの末尾に指定する必要があります (/**)。 専用プールでは、フォルダーは常に再帰的にスキャンされます。 |
| ストレージ認証 | ストレージ アクセス キー (SAK)、Microsoft Entra パススルー、マネージド ID、カスタム アプリケーションの Microsoft Entra ID | Shared Access Signature (SAS)、Microsoft Entra パススルー、マネージド ID、カスタム アプリケーションの Microsoft Entra ID。 |
| 列マッピング | 序数 - 外部テーブル定義の列は、基になる Parquet ファイル内の列に位置によってマップされます。 | サーバーレス プール: 名前によります。 外部テーブル定義の列は、基になる Parquet ファイル内の列に列名の一致によってマップされます。 専用プール: 順序数マッチング。 外部テーブル定義の列は、基になる Parquet ファイル内の列に位置によってマップされます。 |
| CETAS (エクスポート/変換) | はい | ターゲットとしてネイティブ テーブルを使用する CETAS は、サーバーレス SQL プールでのみ機能します。 ネイティブ テーブルを使ってデータをエクスポートするために、専用 SQL プールを使うことはできません。 |
注意
ネイティブ外部テーブルは、一般的に利用可能なプールで推奨されるソリューションです。 外部データにアクセスする必要がある場合は、常にサーバーレス プールまたは専用プール内のネイティブ テーブルを使用してください。 Hadoop テーブルは、ネイティブ外部テーブルでサポートされていない一部の種類 (ORC、RC など) にアクセスする必要がある場合、またはネイティブ バージョンが使用できない場合にのみ使います。
専用 SQL プールとサーバーレス SQL プールにおける外部テーブル
外部テーブルを使用して次のことができます。
- Transact-SQL ステートメントを使用して、Azure Blob Storage と ADLS Gen2 に対するクエリを実行する。
- CETAS と Synapse SQL を使用して、クエリ結果を Azure Blob Storage または Azure Data Lake Storage 内のファイルに格納する。
- Azure Blob Storage や Azure Data Lake Storage からデータをインポートして、専用 SQL プールに格納する (専用プールでは Hadoop テーブルのみ)。
注意
CREATE TABLE AS SELECT ステートメントで使う場合は、外部テーブルから選ぶと、専用 SQL プール内のテーブルにデータがインポートされます。
専用プール内の Hadoop 外部テーブルのパフォーマンスが、パフォーマンスの目標に達しない場合は、COPY ステートメントを使ってデータ ウェアハウス テーブルに外部データを読み込むことを検討します。
読み込みのチュートリアルについては、PolyBase を使用した Azure Blob Storage からのデータの読み込みに関するページを参照してください。
次の手順を通じて、Synapse SQL プールに外部テーブルを作成できます。
- CREATE EXTERNAL DATA SOURCE で、外部 Azure ストレージを参照し、ストレージへのアクセスに使用する資格情報を指定します。
- CREATE EXTERNAL FILE FORMAT で、CSV または Parquet ファイルの形式を記述します。
- CREATE EXTERNAL TABLE を、データ ソースに配置されているファイル上で、同じファイル形式を使用して実行します。
フォルダー パーティションの除外
Synapse プール内のネイティブ外部テーブルでは、クエリに関係のないフォルダーに置かれたファイルを無視できます。 ファイルがフォルダー階層 (例: /year=2020/month=03/day=16) に格納され、year、month、dayの値が列として公開されている場合、year=2020 のようなフィルターを含むクエリでは、year=2020 フォルダー内に配置されたサブフォルダーからのみファイルが読み取られます。 このクエリでは、他のフォルダー (year=2021 や year=2022) に配置されたファイルとフォルダーは無視されます。 この除外はパーティションの除外と呼ばれます。
フォルダー パーティションの除外は、Synapse Spark プールから同期されるネイティブ外部テーブルで使用できます。 データ セットをパーティション分割してあり、作成する外部テーブルでパーティションの除去を使いたい場合は、外部テーブルではなくパーティション ビューを使います。
ファイルの除外
Parquet や Delta などの一部のデータ形式には、各列のファイル統計 (各列の最小/最大値など) が含まれます。 データをフィルター処理するクエリでは、必要な列の値が存在しないファイルは読み取られません。 クエリでは、最初に、クエリ述語で使われている列の最小と最大値が調べられて、必要なデータを含まないファイルが検索されます。 これらのファイルは無視され、クエリ プランから除外されます。
この手法はフィルター述語のプッシュダウンとも呼ばれ、クエリのパフォーマンスを向上させることができます。 フィルター プッシュダウンは、Parquet および Delta 形式のサーバーレス SQL プールで使用できます。 文字列型にフィルター プッシュダウンを適用するには、VARCHAR 型と Latin1_General_100_BIN2_UTF8 照合順序を使います。 照合順序の詳細については、「Azure Synapse Analytics での Synapse SQL のデータベース照合順序のサポート」を参照してください。
セキュリティ
ユーザーは、外部テーブルのデータを読み取る場合、それに対する SELECT アクセス許可が必要です。
外部テーブルから、基になる Azure Storage へのアクセスは、次の規則を使用してデータソース内で定義されているデータベース スコープ資格情報を使用して行います。
- 資格情報なしのデータソースの場合、外部テーブルからは、Azure Storage 上の一般公開されているファイルにアクセスできます。
- SAS トークンまたはワークスペースのマネージド ID を使用して外部テーブルが Azure Storage 上のファイルにしかアクセスできないようにするための資格情報をデータソースに含めることができます。例については、ストレージ ファイルのストレージ アクセス制御の開発に関する記事を参照してください。
注釈
信頼性の高いクエリ実行を確実に行うには、操作の期間中、外部テーブルによって参照されるソース ファイルとフォルダーが変更されないようにする必要があります。
- クエリの実行中に参照されているファイルまたはフォルダーを変更、削除、または置き換えると、エラーが発生したり、一貫性のない結果が生じる可能性があります。
- 専用 SQL プール内の外部テーブルに対してクエリを実行する前に、すべてのソース データが安定しており、実行中に変更されないことを確認します。
CREATE EXTERNAL DATA SOURCE の例
次の例では、公開されている New York データ セットを参照する ADLS Gen2 の Hadoop 外部データ ソースを専用 SQL プールに作成します。
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
次の例では、一般公開されている New York データ セットを参照する ADLS Gen2 の外部データ ソースを作成します。
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
CREATE EXTERNAL FILE FORMAT の例
次の例では、国勢調査ファイルの外部ファイル形式を作成します。
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
CREATE EXTERNAL TABLE の例
次の例では、外部テーブルを作成します。 最初の行が返されます。
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Azure Data Lake 内のファイルから外部テーブルを作成してクエリを実行する
Synapse Studio のデータ レイク探索機能を使うと、Synapse SQL プールとファイルの右クリックを使って、外部テーブルの作成とクエリを行うことができます。 ADLS Gen2 ストレージ アカウントから外部テーブルを作成するワンクリック ジェスチャーは、Parquet ファイルでのみサポートされます。
前提条件
少なくとも、ファイルに対してクエリを実行できるよう、ADLS Gen2 アカウントまたはアクセス制御リスト (ACL) への
Storage Blob Data Contributorアクセス ロールが設定されたワークスペースにアクセスできる必要があります。Synapse SQL プール (専用またはサーバーレス) で外部テーブルを作成するためのアクセス許可と外部テーブルに対してクエリを実行するためのアクセス許可が少なくとも必要です。
[データ] パネルで、外部テーブルの作成元にするファイルを選択します。

ダイアログ ウィンドウが開きます。 専用 SQL プールかサーバーレス SQL プールを選択し、テーブルに名前を付けて [スクリプトを開く] を選択します。
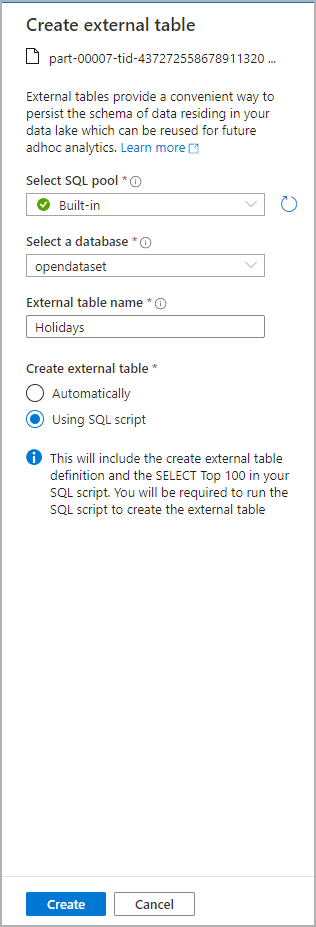
SQL スクリプトは、ファイルからのスキーマの推論により自動的に生成されます。

スクリプトを実行します。 このスクリプトでは、SELECT TOP 100 * が自動的に実行されます。

これで外部テーブルが作成されました。 データ ペインから直接外部テーブルに対してクエリを実行できるようになりました。
関連するコンテンツ
クエリの結果を Azure Storage の外部テーブルに保存する方法については、CETAS に関する記事をご覧ください。 また、Azure Synapse 外部テーブルの Apache Spark に対するクエリを開始することもできます。