Tip
Microsoft Fabric Data Warehouse は、将来のアーキテクチャ、組み込みの AI、および新機能を備えた、Data Lake 基盤上のエンタープライズ 規模のリレーショナル ウェアハウスです。 データ ウェアハウスを初めて使用する場合は、Fabric Data Warehouseから始めます。 既存の dedicated SQL プール ワークロードは、Fabric にアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
- Fabric無料試用版を開始します。
- Fabric Data Warehouse 用マイグレーションアシスタント
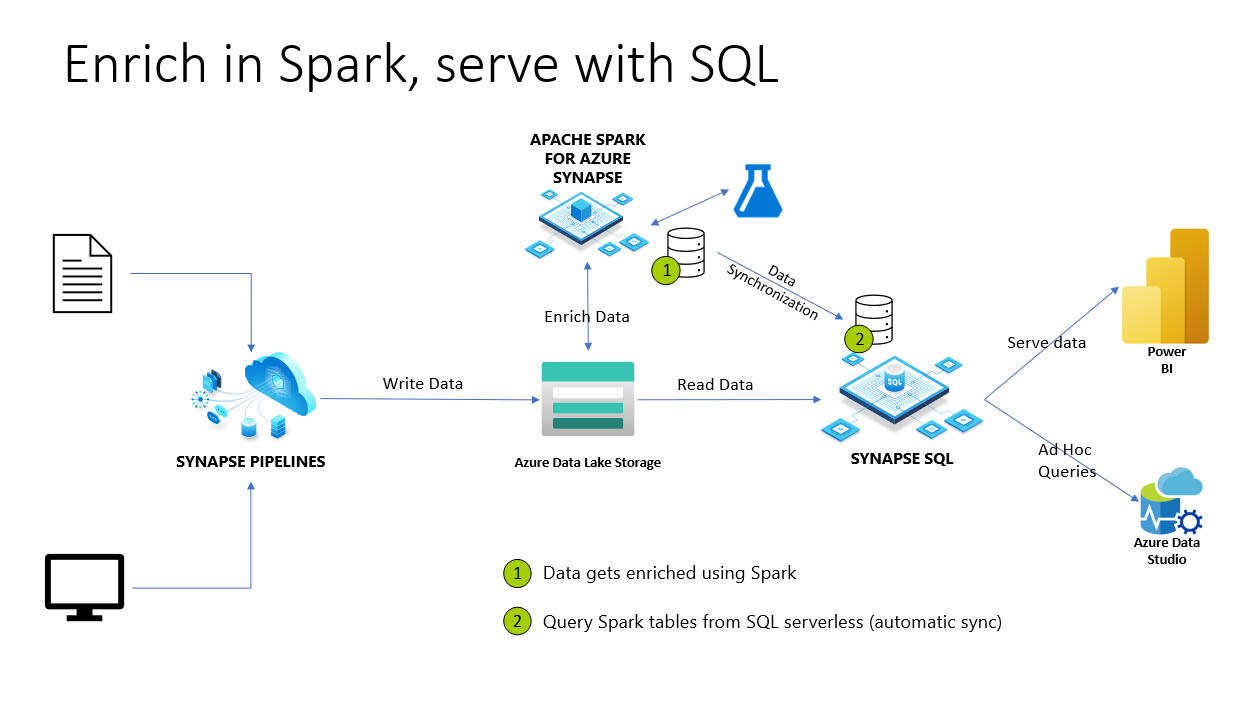
Azure Synapse Analyticsでは、Spark databases および tables はサーバーレス SQL プールと共有されます。 Spark で作成された Lake Database、Parquet、CSV ベースのテーブルは、サーバーレス SQL プールで自動的に使用できます。 この機能を使用すると、サーバーレス SQL プールを使用して、Spark プールを使用して準備されたデータを探索してクエリを実行できます。 次の図では、この機能を利用するためのアーキテクチャの概要を確認できます。 まず、Azure Synapse パイプラインは、オンプレミス (またはその他の) ストレージからAzure Data Lake Storageにデータを移動します。 Spark でデータを強化し、サーバーレス Synapse SQL に同期されるデータベースとテーブルを作成できるようになりました。 後で、ユーザーはエンリッチされたデータの上にアドホック クエリを実行したり、Power BIに提供したりできます。
完全な管理者アクセス (sysadmin)
これらのデータベースとテーブルが Spark からサーバーレス SQL プールに同期されると、サーバーレス SQL プール内のこれらの外部テーブルを使用して同じデータにアクセスできます。 ただし、サーバーレス SQL プール内のオブジェクトは、Spark プール オブジェクトとの整合性を維持するため、読み取り専用です。 この制限により、Synapse SQL 管理者ロールまたは Synapse 管理者ロールを持つユーザーのみがサーバーレス SQL プール内のこれらのオブジェクトにアクセスできるようになります。 管理者以外のユーザーが同期されたデータベース/テーブルに対してクエリを実行しようとすると、次のようなエラーが表示されます。
External table '<table>' is not accessible because content of directory cannot be listed. それにもかかわらず、基になるストレージ アカウント上のデータにアクセスできるにもかかわらず、
サーバーレス SQL プール内の同期されたデータベースは読み取り専用であるため、変更することはできません。 ユーザーの作成、または他のアクセス許可の付与は、試行された場合に失敗します。 同期されたデータベースを読み取る場合は、特権サーバー レベルのアクセス許可 (sysadmin など) が必要です。 この制限は、サーバーレス SQL プール内の外部テーブルにも存在し、Azure Synapse Link for Dataverseおよびレイク データベース テーブルで使用する場合にも適用されます。
同期されたデータベースへの管理者以外のアクセス
データの読み取りとレポートの作成が必要なユーザーは、通常、完全な管理者アクセス権 (sysadmin) を持っていません。 このユーザーは通常、既存のテーブルを使用してデータを読み取って分析するだけで済むデータ アナリストです。 新しいオブジェクトを作成する必要はありません。
最小限のアクセス許可を持つユーザーは、次のことが可能である必要があります。
- Spark からレプリケートされたデータベースに接続する
- 外部テーブルを使用してデータを選択し、基になる ADLS データにアクセスします。
以下のコード スクリプトを実行すると、管理者以外のユーザーが任意のデータベースに接続するためのサーバー レベルのアクセス許可を持つことができます。 また、テーブルやビューなど、すべてのスキーマ レベルのオブジェクトのデータを表示することもできます。 データ アクセス セキュリティは、ストレージ 層で管理できます。
-- Creating Azure AD login (same can be achieved for Azure AD app)
CREATE LOGIN [login@contoso.com] FROM EXTERNAL PROVIDER;
go;
GRANT CONNECT ANY DATABASE to [login@contoso.com];
GRANT SELECT ALL USER SECURABLES to [login@contoso.com];
GO;
注
これらのステートメントはすべてサーバー レベルのアクセス許可であり、マスター データベースで実行する必要があります。
ログインを作成し、アクセス許可を付与した後、ユーザーは同期された外部テーブルの上にクエリを実行できます。 この軽減策は、Microsoft Entraセキュリティ グループにも適用できます。
オブジェクトのセキュリティを強化するには、特定のスキーマを使用して管理し、特定のスキーマへのアクセスをロックします。 この回避策には、追加の DDL が必要です。 このシナリオでは、ADLS 上の Spark テーブル データを指す新しいサーバーレス データベース、スキーマ、およびビューを作成できます。
ストレージ アカウント上のデータへのアクセスは、ACL または通常の Storage BLOB データ所有者/閲覧者/共同作成者ロールを介してMicrosoft Entraユーザー/グループに対して管理できます。 サービス プリンシパル (Microsoft Entra アプリ) の場合は、ACL の設定を使用していることを確認します。
注
- データの上に OPENROWSET を使用することを禁止する場合は、
DENY ADMINISTER BULK OPERATIONS to [login@contoso.com];を使用して詳細については、「 DENY サーバーのアクセス許可」を参照してください。 - 特定のスキーマの使用を禁止する場合は、
DENY SELECT ON SCHEMA::[schema_name] TO [login@contoso.com];を使用して詳細については、「 DENY Schema Permissions」を参照してください。
次のステップ
詳細については、「 SQL 認証」を参照してください。