SAP HANA 用 Azure NetApp Files 上の NFS v4.1 ボリューム
Azure NetApp Files には、 /hana/shared、 /hana/data、 /hana/log の各ボリュームに使用できるネイティブ NFS 共有が用意されています。 /hana/data および /hana/log のボリュームに ANF ベースの NFS 共有を使用するには、v4.1 NFS プロトコルを使用する必要があります。 共有が ANF ベースの場合、/hana/data および /hana/log ボリュームに NFS プロトコル v3 を使用することはできません。
重要
Azure NetApp Files に実装されている NFS v3 プロトコルの使用は、 /hana/data および /hana/log ではサポートされていません。 機能的観点から、 /hana/data および /hana/log ボリュームには、NFS 4.1 の使用が必須となります。 一方、 /hana/shared ボリュームの場合、機能的観点から NFS v3 または NFS v4.1 プロトコルを使用できます。
重要な考慮事項
SAP Netweaver および SAP HANA 用に Azure NetApp Files を検討するときは、以下の重要な考慮事項に注意してください。
最小容量プールは 4 TiB です
最小ボリューム サイズは 100 GiB です。
ANF ベースの NFS 共有と、それらの共有をマウントする仮想マシンは、同じ Azure Virtual Network 内、または同じリージョンのピアリングされた仮想ネットワーク内にある必要があります
選択した仮想ネットワークには、Azure NetApp Files に委任されているサブネットがある必要があります。 SAP ワークロードの場合は、ANF に委任されたサブネットの /25 範囲を構成することを強くお勧めします。
たとえば、SAP HANA で再実行ログの書き込みが要求された際に待機時間を短縮するためには、仮想マシンを Azure NetApp ストレージに十分に近接して配置しておくことが重要です。
- 一方、Azure NetApp Files には、NFS ボリュームを特定の Azure Availability Zones に配置する機能があります。 1ミリ秒未満の待機時間を実現するためには、ほとんどの場合、このようなゾーン近接性で十分です。 この機能はパブリック プレビュー段階であり、記事「Azure NetApp Files の可用性ゾーン ボリュームの配置を管理する」で説明されています。 この機能では、VM と割り当てる NFS ボリュームとの間の近接性を実現するために、Microsoft との会話型プロセスは必要ありません。
- 最適な近接性を実現するためのアプリケーション ボリューム グループの機能を利用できます。 この機能は、最適な近接性だけでなく、HANA データと再実行ログ ボリュームが異なるコントローラーで処理されるように、NFS ボリュームを最適に配置することを目的としています。 欠点は、この方法では VM を固定するために Microsoft と何らかの会話型プロセスが必要なことです。
データベース サーバーから ANF ボリュームへの待機時間が計測されており、1 ミリ秒未満であることを確認します
Azure NetApp ボリュームのスループットは、「Azure NetApp Files のサービス レベル」に記載されているように、ボリューム クォータとサービス レベルの機能です。 HANA Azure NetApp ボリュームのサイズを設定するときは、そのスループットが HANA システム要件を満たしていることを確認してください。 または、ボリュームの容量とスループットを個別に構成およびスケーリングできる手動 QoS 容量プールの使用を検討してください (SAP HANA の具体的な例については、このドキュメントを参照してください)。
大きなボリュームでより高いパフォーマンスを実現するために、可能であれば、/sapmnt、/usr/sap/trans などに対して 1 つのボリュームを使用するなど、ボリュームを "統合" してみてください。 可能な場合
Azure NetApp Files のエクスポート ポリシーでは、ユーザーが制御できるのは、許可されたクライアント、アクセスの種類 (読み取りおよび書き込み、読み取り専用など) です。
仮想マシン上の sidadm のユーザー ID と
sapsysのグループ ID は、Azure NetApp Files の構成と一致している必要があります。SAP Note 3024346 で説明されている Linux OS パラメーターを実装する
重要
SAP HANA ワークロードにとって、待ち時間の短縮は重要です。 Microsoft の担当者と協力して、仮想マシンと Azure NetApp Files ボリュームが確実に近接してデプロイされるようにします。
重要
仮想マシンと Azure NetApp の構成の間で、sidadm のユーザー ID と、sapsys のグループ ID が一致しない場合は、VM にマウントされた Azure NetApp ボリューム上のファイルのアクセス許可が nobody として表示されます。 Azure NetApp Files に新しいシステムをオンボードするときに、正しい sidadm のユーザー ID と sapsys のグループ ID を指定していることを確認してください。
NCONNECT マウント オプション
Nconnect は、ANF でホストされている NFS ボリュームのマウント オプションであり、NFS クライアントが 1 つの NFS ボリュームに対して複数のセッションを開くことができるようにするものです。 値が 1 より大きい nconnect を使用すると、NFS クライアントは(ゲスト OS 内の) クライアント側で複数の RPC セッションを使用して、ゲスト OS とマウントされた NFS ボリュームの間のトラフィックを処理します。 1 つの NFS ボリュームのトラフィックを処理する複数のセッションを使用するだけでなく、複数の RPC セッションを使用すると、次のようなパフォーマンスとスループットのシナリオに対処できます。
- 1 つの VM に異なるサービス レベルを持つ ANF でホストされている NFS ボリュームを複数マウントする
- ボリュームと 1 つの Linux セッションの最大書き込みスループットは、1.2 から 1.4 GB/秒です。 1 つの ANF でホストされている NFS ボリュームに対して複数のセッションを持つことで、スループットを向上させることができます。
マウント オプションとして nconnect をサポートする Linux OS リリースと nconnect の重要な構成に関する考慮事項 (特に NFS サーバー エンドポイントが異なる場合) については、「Azure NetApp Files 用の Linux NFS マウント オプションのベスト プラクティス」のドキュメントを参照してください。
Azure NetApp Files 上の HANA データベースのサイズ指定
Azure NetApp ボリュームのスループットは、「Azure NetApp Files のサービス レベル」に記載されているように、ボリューム サイズとサービス レベルの機能です。
重要なのは、サイズに対応するパフォーマンスと、サービスのストレージ エンドポイントには物理的な制限があるということを理解することです。 各ストレージ エンドポイントは、ボリューム作成時に Azure NetFiles の委任されたサブネットに動的に挿入されて IP アドレスを受信します。 Azure NetApp Files ボリュームは、使用可能な容量とデプロイ ロジックに応じて、ストレージ エンドポイントを共有できます。
次の表は、バックアップを格納するには大規模な "Standard" ボリュームを作成するのが理にかなっていること、そして 12 TB を超える "Ultra" ボリュームを作成すると 1 つのボリュームの物理的な帯域幅の最大容量を超えてしまうため、理にかなっていないことを示しています。
1 つの Linux セッションで提供できる最大書き込みスループットを超える /hana/data ボリュームが必要な場合は、代わりに SAP HANA データ ボリュームのパーティション分割を使用することもできます。 SAP HANA データ ボリュームのパーティション分割を使用すると、データの再読み込み時または HANA セーブポイントの I/O アクティビティを、複数の NFS 共有に配置されている複数の HANA データ ファイル間でストライピングできます。 HANA データ ボリュームのストライピングの詳細については、これらの記事をご覧ください。
| サイズ | スループット (Standard) | スループット (Premium) | スループット (Ultra) |
|---|---|---|---|
| 1 TB (テラバイト) | 16 MB/秒 | 64 MB/秒 | 128 MB/秒 |
| 2 TB | 32 MB/秒 | 128 MB/秒 | 256 MB/秒 |
| 4 TB | 64 MB/秒 | 256 MB/秒 | 512 MB/秒 |
| 10 TB | 160 MB/秒 | 640 MB/秒 | 1,280 MB/秒 |
| 15 TB | 240 MB/秒 | 960 MB/秒 | 1,400 MB/sec1 |
| 20 TB | 320 MB/秒 | 1,280 MB/秒 | 1,400 MB/sec1 |
| 40 TB | 640 MB/秒 | 1,400 MB/sec1 | 1,400 MB/sec1 |
1: 書き込みまたは単一セッションの読み取りスループットの制限 (NFS マウント オプション nconnect を使用しない場合)
データは、ストレージ バックエンドの同じ SSD に書き込まれていることを理解しておくことが重要です。 容量プールからのパフォーマンス クォータは、環境を管理できるように作成されています。 ストレージ KPI は、すべての HANA データベース サイズで同じです。 ほとんどの場合、この想定は現実と顧客の期待を反映していません。 HANA システムのサイズは、必ずしも小規模なシステムでは必要なストレージのスループットが低く、大規模なシステムでは必要なストレージのスループットが高いことを意味しません。 しかし、一般的には、より大きな HANA データベース インスタンスでは、より高いスループットの要件があると考えられます。 基となるハードウェアに対する SAP のサイズ設定ルールにより、このような大規模な HANA インスタンスでは、インスタンスの再起動後にデータをロードするようなタスクでも、より多くの CPU リソースと、より多くの並列処理を提供しています。 そのため、ボリュームのサイズは顧客の期待と要件に合わせて採用する必要があります。 純粋な容量の要件だけで判断すべきではありません。
Azure で SAP のインフラストラクチャを設計する際には、SAP による (運用システムの) 最小ストレージ スループット要件に注意する必要があります。 これらの要件は、最小スループット特性につながります。
| ボリュームの種類と I/O の種類 | SAP で要求される最小 KPI | Premium サービス レベル | Ultra サービス レベル |
|---|---|---|---|
| ログ ボリュームの書き込み | 250 MB/秒 | 4 TB | 2 TB |
| データ ボリュームの書き込み | 250 MB/秒 | 4 TB | 2 TB |
| データ ボリュームの読み取り | 400 MB/秒 | 6.3 TB | 3.2 TB |
3 つのすべての KPI が要求されるため、読み取りの最小要件を満たすには、 /hana/data のボリュームを、より大きな容量にサイズ調整する必要があります。 手動 QoS 容量プールを使用する場合、ボリュームのサイズとスループットを個別に定義できます。 容量とスループットの両方が同じ容量プールから取得されるため、プールのサービス レベルとサイズは全体のパフォーマンスを提供できる十分な大きさにする必要があります (例については、こちらを参照してください)。
高帯域幅を必要としない HANA システムの場合、ボリューム サイズを小さくするか、手動 QoS を使用してスループットを直接調整することで、ANF ボリュームのスループットを下げることができます。 また、HANA システムのスループットを向上させる必要がある場合は、容量をオンラインでサイズ変更することでボリュームを調整できます。 KPI は、バックアップ ボリュームに対しては定義されていません。 ただし、高パフォーマンスの環境には、バックアップ ボリュームのスループットが不可欠です。 ログ、およびデータ ボリュームのパフォーマンスは、顧客の期待に合わせて設計する必要があります。
重要
1 つの NFS ボリュームにデプロイする容量に関係なく、スループットは、単一セッションでコンシューマーによって活用される毎秒 1.2 から 1.4 GB までの帯域幅範囲にとどまるものと予想されます。 これは、ANF プランの基礎アーキテクチャと NFS 関連の Linux セッション上限に関係があります。 「Azure NetApp Files のパフォーマンス ベンチマークのテスト結果」という記事に記載されているパフォーマンスとスループットの数値は、1 つの共有 NFS ボリュームと複数のクライアント VM (結果として複数のセッション) に対して行われたものです。 このシナリオは、SAP で測定するシナリオとは異なります。 その場合、ANF でホストされている NFS ボリュームに対して 1 つの VM からの スループットを測定します。
データとログの SAP 最小スループット要件を満たすため、および /hana/shared のガイドラインに従うと、推奨されるサイズは次のようになります。
| ボリューム | サイズ Premium ストレージ層 |
サイズ Ultra ストレージ層 |
サポートされる NFS プロトコル |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | v4.1 |
| /hana/data | 6.3 TiB | 3.2 TiB | v4.1 |
| /hana/shared scale-up | 最小 (1 TB、1 x RAM) | 最小 (1 TB、1 x RAM) | v3 または v4.1 |
| /hana/shared scale-out | 1 x ワーカー ノードの RAM 4 つのワーカー ノードあたり |
1 x ワーカー ノードの RAM 4 つのワーカー ノードあたり |
v3 または v4.1 |
| /hana/logbackup | 3 x RAM | 3 x RAM | v3 または v4.1 |
| /hana/backup | 2 x RAM | 2 x RAM | v3 または v4.1 |
すべてのボリュームについて、NFS v4.1 を強くお勧めします。
/hana/shared のサイズ設定に関するの考慮事項を注意深く確認してください。適切にサイズ設定された /hana/shared ボリュームがシステムの安定性に寄与するためです。
バックアップ ボリュームのサイズは推定値です。 正確な要件は、ワークロードと運用プロセスに基づいて定義する必要があります。 バックアップの場合は、異なる SAP HANA インスタンスの複数のボリュームを 1 つ (または 2 つ) の大きなボリュームに統合できます。これにより、ANF のサービス レベルが低くなる可能性があります。
Note
このドキュメントで説明されている Azure NetApp Files のサイズ設定の推奨事項は、SAP がそのインフラストラクチャ プロバイダーに表明している最小要件を対象としています。 実際の顧客のデプロイとワークロードのシナリオでは、これらは十分ではない場合があります。 これらの推奨事項は開始点として利用し、ご自分の固有のワークロードの要件に合わせて調整してください。
そのため、Ultra Disk Storage 用に記載されているのと同様の ANF ボリューム用のスループットをデプロイすることを検討してください。 また、Ultra ディスク テーブルの場合と同じように、さまざまな VM SKU のボリュームに対して記載されているサイズも考慮してください。
ヒント
Azure NetApp Files ボリュームは、ボリュームを unmount したり、仮想マシンを停止したり、SAP HANA を停止したりすることなく、動的にサイズ変更することができます。 これにより、予想されるスループット要求と予期しないスループット要求の両方を柔軟に満たすことができます。
ANF ベースの NFS v4.1 ボリュームを使用して、スタンバイ ノードを含む SAP HANA スケールアウト構成をデプロイする方法については、SUSE Linux Enterprise Server 上に Azure VM のスタンバイ ノードと Azure NetApp Files を使用して SAP HANA をスケールアウトする方法に関するドキュメントを参照してください。
Linux のカーネル設定
ANF に SAP HANA を正常にデプロイするには、Linux のカーネル設定を SAP Note 3024346 に従って実装する必要があります。
pacemaker と Azure Load Balancer を使用する高可用性 (HA) を使用するシステムの場合は、ファイル /etc/sysctl.d/91-NetApp-HANA.conf で次の設定を実装する必要があります
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
pacemaker および Azure Load Balancer なしで実行されるシステムの場合、/etc/sysctl.d/91-NetApp-HANA.conf でこれらの設定を実装する必要があります
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
ゾーン近接による配置
NFS ボリュームと VM のゾーン近接性を得るには、「Azure NetApp Files の可用性ゾーン ボリュームの配置を管理する」の説明に従います。 この方法では、VM と NFS ボリュームは同じ Azure 可用性ゾーン内に配置されます。 ほとんどの Azure リージョンで、SAP HANA の小規模な再実行ログ書き込みで 1 ミリ秒未満の待機時間を実現するには、この種類の近接性で十分でしょう。 この方法では、VM を特定のデータセンターに配置して固定するために、Microsoft との対話型作業は必要ありません。 その結果、配置した可用性ゾーンで提供されるすべての VM の種類とファミリ内で VM サイズとファミリを柔軟に変更することができます。 そのため、状況の変化に柔軟に対応し、よりコスト効率の高い VM サイズやファミリに迅速に移行することができます。 この方法は、非運用システムおよび再実行ログの待機時間が 1 ミリ秒に迫る運用システムに推奨されます。 現在この機能はパブリック プレビュー版です。
Azure NetApp Files アプリケーション ボリューム グループを介した SAP HANA (AVG) のデプロイ
VM に近接して ANF ボリュームをデプロイするために、SAP HANA (AVG) 向けの Azure NetApp Files アプリケーション ボリューム グループと呼ばれる新しい機能が開発されました。 機能について説明する一連の記事があります。 最初に読むのに最も適している記事は、「SAP HANA の Azure NetApp Files アプリケーション ボリューム グループについて」です。 記事を読むと、AVG の使用には Azure 近接配置グループの使用も関連していることが明らかになってきます。 近接配置グループは、作成されているボリュームと関連付けるために、新しい機能によって使用されます。 HANA システムの有効期間中に、VM が ANF ボリュームから移動されないようにするために、配置先のゾーンごとに Avset/PPG を組み合わせて使用することをお勧めします。 デプロイの順序は次のとおりです。
- フォームを使用して、空の Avset をコンピューティング HW にピン留めするように要求して、VM が移動しないようにする必要があります
- 可用性セットに PPG を割り当て、この可用性セットに割り当てられた VM を起動する
- SAP HANA 機能向けの Azure NetApp Files アプリケーション ボリューム グループを使用して HANA ボリュームをデプロイする
最適な方法で AVG を使用するための近接配置グループの構成は次のとおりです。
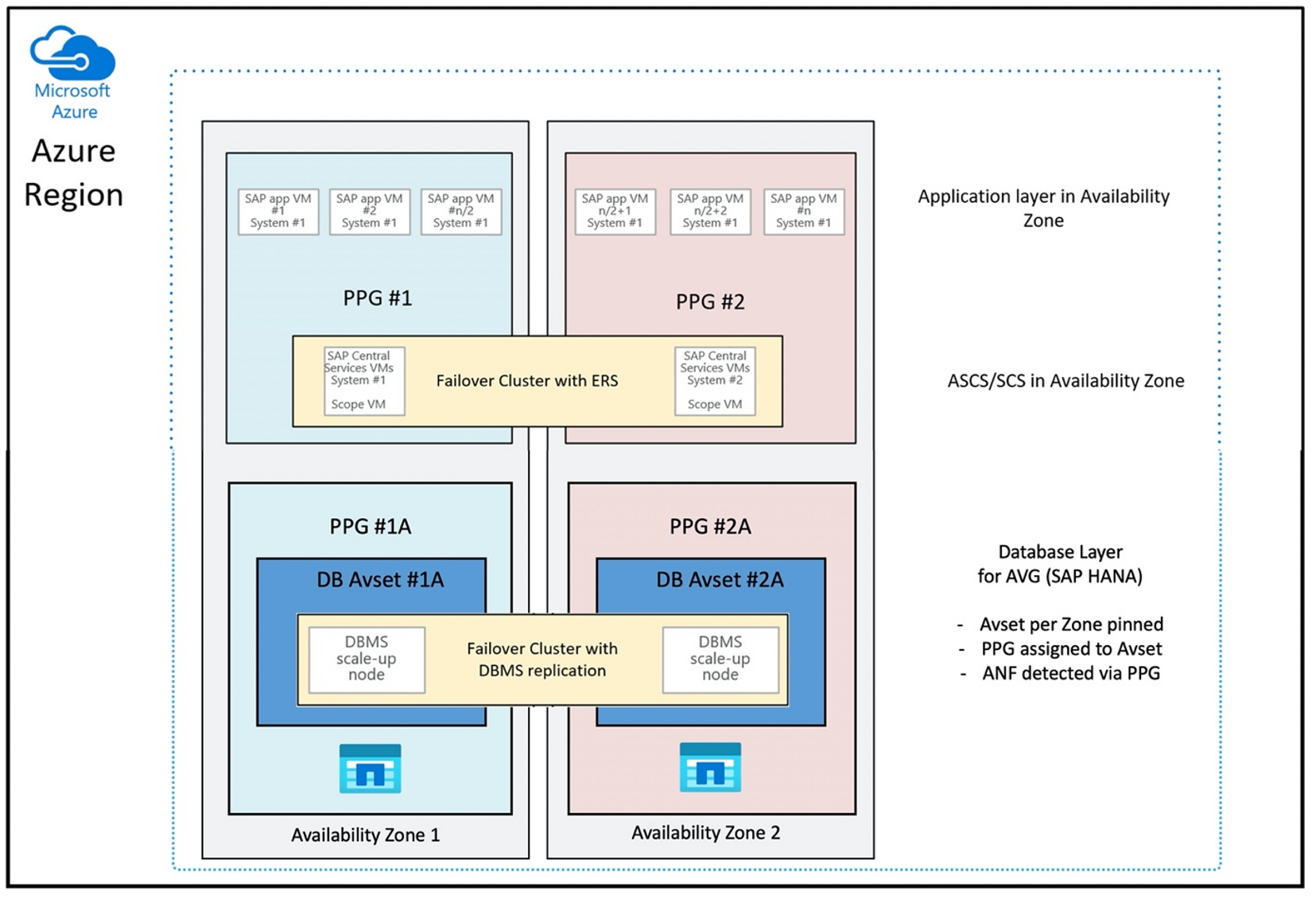
この図は、DBMS レイヤーに Azure 近接配置グループを使用する場合を示しています。 そのため、AVG と連携して使用できます。 HANA インスタンスを実行する VM のみを近接配置グループに含めるのが最善です。 1 つの HANA インスタンスを持つ VM が 1 つのみ使用されている場合でも、近接配置グループが必要です。これは、AVG が、最も近接する ANF ハードウェアを識別するためです。 また、ANF 上の NFS ボリュームを、NFS ボリュームを使用している VM に可能な限り近接して割り当てるためです。
この方法では、低待機時間に関して最適な結果が得られます。 NFS ボリュームと VM を可能な限り近づけるだけではありません。 データおよび再実行ログ ボリュームを NetApp バックエンドの異なるコントローラーに配置する際の考慮事項も考慮されます。 一方、欠点は、VM の配置が 1 つのデータセンターに固定されることです。 そのため、VM の種類やファミリを変更する柔軟性が失われます。 結果として、この方法は、このようなストレージ待機時間が必ず短い必要があるシステムに限定する必要があります。 他のすべてのシステムでは、VM と ANF の従来のゾーン デプロイを使用してデプロイを試みる必要があります。 ほとんどの場合、待機時間の短縮という点ではこれで十分です。 これにより、VM と ANF のメンテナンスと管理も容易になります。
可用性
ANF システムの更新とアップグレードは、お客様の環境に影響を与えることなく適用されます。 定義された SLA は 99.99% です。
ボリュームと IP アドレスと容量プール
ANF を使用する際は、基になるインフラストラクチャがどのように構築されているかを理解することが重要です。 容量プールは、容量プールのサービス レベルに基づいて、容量とパフォーマンスの予算と請求単位を提供する単なる構成体です。 容量プールには、基になるインフラストラクチャとの物理的な関係はありません。 サービスでボリュームを作成すると、ストレージ エンドポイントが作成されます。 ボリュームへのデータ アクセスを提供するために、このストレージ エンドポイントに 1 つの IP アドレスが割り当てられます。 複数のボリュームを作成した場合、すべてのボリュームは、このストレージ エンドポイントに関連付けられて、基になるベアメタル フリート全体に分散されます。 ANF には、構成されたストレージのボリュームまたは容量が内部で事前に定義されたレベルに達した際に、顧客のワークロードを自動的に分散するロジックが備わっています。 このような場合は、新しい IP アドレスを持つ新しいストレージ エンドポイントがボリュームにアクセスするために自動的に作成されます。 ANF サービスでは、この配布ロジックの顧客による制御は提供されていません。
ログ ボリュームとログ バックアップ ボリューム
"ログ ボリューム" ( /hana/log) は、オンライン REDO ログの書き込みに使用されます。 そのため、このボリュームにはオープンなファイルが存在し、このボリュームのスナップショットを作成しても意味がありません。 オンラインの redo ログ ファイルがいっぱいになるか、redo ログ バックアップが実行されると、オンライン redo ログ ファイルは、ログ バックアップ ボリュームにアーカイブまたはバックアップされます。 適切なバックアップ パフォーマンスを実現するには、ログ バックアップ ボリュームに十分なスループットが必要です。 ストレージ コストを最適化するには、複数の HANA インスタンスのログ バックアップ ボリュームを統合することが有効です。 これにより、複数の HANA インスタンスで同じボリュームが使用され、異なるディレクトリにバックアップが書き込まれます。 このような統合を使用すると、ボリュームを若干大きくする必要があるため、スループットを向上させることができます。
これは、HANA データベースの完全バックアップの書き込みに使用するボリュームにも当てはまります。
バックアップ
「Azure Virtual Machines 上の SAP HANA のバックアップ ガイド」の説明にある SAP HANA データベースをバックアップするストリーミング バックアップと Azure Back サービスに加えて、Azure NetApp Files により、ストレージベースのスナップショット バックアップを実行することができるようになります。
SAP HANA では以下がサポートされます。
- SAP HANA 1.0 SPS7 以降を使用する単一コンテナー システムのストレージベースのスナップショット バックアップのサポート
- SAP HANA 2.0 SPS1 以降を使用する単一テナントのマルチ データベース コンテナー (MDC) HANA 環境のストレージベースのスナップショット バックアップのサポート
- SAP HANA 2.0 SPS4 以降を使用する複数テナントのマルチ データベース コンテナー (MDC) HANA 環境のストレージベースのスナップショット バックアップのサポート
ストレージベースのスナップショット バックアップの作成は、簡単な 4 つの手順で行います。
- HANA (内部) データベース スナップショットを作成する - これは、ユーザーまたはツールで実行する必要があるアクティビティです
- SAP HANA によってデータがデータファイルに書き込まれることで、ストレージに一貫性のある状態が作り出される - この手順は、HANA スナップショットの作成後に実行されます
- ストレージ上に /hana/data ボリュームのスナップショットを作成する - これは、ユーザーまたはツールで実行する必要があるステップです。 /hana/log ボリュームのスナップショットを実行する必要はありません
- HANA (内部) データベース スナップショットを削除して通常の操作を再開する - これは、ユーザーまたはツールで実行する必要があるステップです
警告
最後のステップを行わなかった場合、または最後のステップを実行できなかった場合、SAP HANA のメモリ需要に深刻な影響を及ぼし、SAP HANA が停止する可能性があります
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
このスナップショット バックアップの手順は、さまざまなツールを使用してさまざまな方法で管理できます。 1 つの例として、GitHub (https://github.com/netapp/ntaphana) にある Python スクリプト "ntaphana_azure.py" があります。これは、メンテナンスやサポートのない、"現状有姿" で提供されるサンプル コードです。
注意事項
スナップショット自体は、スナップショットを作成したボリュームと同じ物理ストレージに配置されているため、保護されたバックアップではありません。 1 日あたり少なくとも 1 つのスナップショットを、別の場所に "保護" する必要があります。 これは、同じ環境でも、リモートの Azure リージョンでも、Azure Blob Storage 上でも可能です。
ストレージ スナップショット ベースのアプリケーション整合性バックアップに使用できるソリューション:
- Microsoft Azure アプリケーション整合性スナップショット ツールとは、サードパーティ製データベースのデータ保護を可能にするコマンドライン ツールです。 ストレージ スナップショットの取得前に、データベースをアプリケーションと整合性のある状態にするために必要なすべてのオーケストレーションが処理されます。 ストレージ スナップショットの取得後、このツールによりデータベースは動作状態に戻されます。 AzAcSnap は、HANA L インスタンスと Azure NetApp Files のスナップショット ベースのバックアップをサポートしています。 詳細については、「Azure アプリケーション整合性スナップショット ツールとは」の記事を参照してください
- Commvault バックアップ製品のユーザーの場合、もう 1 つのオプションとして Commvault IntelliSnap V.11.21 以降があります。 これ以降のバージョンの Commvault は Azure NetApp Files スナップショットをサポートしています。 詳細については、Commvault IntelliSnap 11.21 に関する記事を参照してください。
Azure Blob Storage を使用してスナップショットをバックアップする
Azure Blob Storage へのバックアップは、ANF ベースの HANA データベース ストレージのスナップショット バックアップを保存する費用対効果の高い高速な方法です。 スナップショットを Azure Blob Storage に保存するには、AzCopy ツールを使用することをお勧めします。 このツールの最新版をダウンロードして、GitHub の Python スクリプトがインストールされている bin ディレクトリなどにインストールします。 次のように、最新の AzCopy ツールをダウンロードします。
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
最も高度な機能は、同期オプションです。 同期オプションを使用すると、azcopy によってソースと同期先ディレクトリが常に同期されます。 パラメーター --delete-destination を使用することは重要です。 このパラメーターを指定しないと、azcopy によって同期先のサイトのファイルが削除されず、同期先の領域使用率が増加します。 Azure ストレージ アカウントでブロック BLOB コンテナーを作成します。 次に、BLOB コンテナーの SAS キーを作成し、スナップショット フォルダーを Azure Blob コンテナーに同期します。
たとえば、データを保護するために、毎日のスナップショットを Azure Blob コンテナーに同期する必要があるとします。 その 1 つのスナップショットのみを保持する必要がある場合は、以下のコマンドを使用できます。
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
次のステップ
以下の記事を参照してください。