この記事では、Azure VMware Solution ワークロードのアプリケーション プラットフォーム設計領域について説明します。 この領域では、Azure VMware Solution環境でホストするアプリケーションのデプロイ、構成、保守に関連する特定のタスクと責任について説明します。 アプリケーション所有者は、Azure VMware Solution環境のアプリケーションを担当します。 この個人またはチームは、アプリケーションのデプロイ、構成、監視、およびメンテナンスに関連する側面を管理します。
適切に設計されたアプリケーションの主な目的は次のとおりです。
- スケール向けの設計。 低下やサービスの中断なしに、より高いユーザー要求と同時トランザクションを適切に処理します。
- パフォーマンス。 迅速で短い待機時間の応答時間を実現し、リソース使用率を効率的に管理します。
- 信頼性と回復性。 冗長でフォールト トレラントなパターンを設計して、アプリケーションの応答性を維持し、障害から迅速に復旧できるようにします。
この記事では、開発者、アーキテクト、アプリケーション所有者に、Azure VMware Solutionに固有のベスト プラクティスを提供することを目的としています。 これらのプラクティスは、ライフサイクル全体を通じて堅牢で、セキュリティで保護され、スケーラブルで保守可能なアプリケーションを構築するのに役立ちます。
スケーラビリティと効率的なリソース分散のための設計
影響: 信頼性、パフォーマンス効率、セキュリティ
このセクションでは、Azure VMware Solutionプライベート クラウド内の仮想マシン (VM) とワークロード間でのコンピューティング リソースの効果的な割り当てと使用率について説明します。 これらのリソースには、CPU、メモリ、ストレージ、ネットワーク リソースを含めることができます。 このセクションでは、応答性の高いスケーリング手法の実装についても説明します。 これらの手法を使用して、需要の変動に対応するようにリソース プロビジョニングを動的に調整できます。 主な目的は、非効率性とコストのエスカレートにつながる可能性がある過小使用と過剰プロビジョニングを軽減することで、最適なリソース使用率を実現することです。
障害ドメインを使用する
Azure VMware Solutionの障害ドメインは、ストレッチ クラスター内のリソースの論理グループを表します。 これらのリソースは、共通の物理障害ドメインを共有します。 障害ドメインは、さまざまな障害シナリオでの可用性の向上に役立ちます。 リソースを障害ドメインに整理すると、アプリケーションの重要なコンポーネントが複数の障害ドメインに分散されます。
VM やその他のリソースを個別の障害ドメインに配置することで、アプリケーション チームは、データセンターまたはインフラストラクチャの障害時にアプリケーションを確実に使用できるように支援します。 たとえば、VM を、地理的に分散したデータセンターに分散した障害ドメインに分割できます。 その後、1 つのデータセンターで完全な障害が発生した場合でも、アプリケーションは動作を維持できます。
アプリケーション チームは、障害ドメインに基づく VM-VM アフィニティとアンチアフィニティルールの定義を検討する必要があります。 VM-VM アフィニティ ルールは、重要な VM を同じ障害ドメインに配置して、複数のデータセンターに分散しないようにします。 アンチアフィニティ ルールを使用すると、関連する VM が同じ障害ドメイン内にまとめて配置されるのを防ぐことができます。 この方法は、冗長性を確保するのに役立ちます。
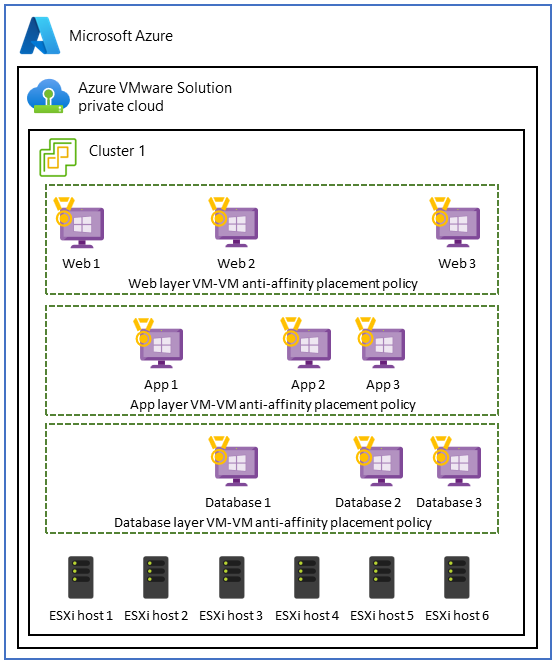
3 層アプリケーションで VM-VM のアフィニティ対策ポリシーを使用する
Azure VMware Solutionでは、VM-VM のアフィニティ対策ポリシーのユース ケースには、3 層アプリケーションが含まれます。 目標は、各アプリケーション層の高可用性、フォールト トレランス、回復性を強化することです。 この目標を達成するために、アンチアフィニティ ポリシーを使用して、Azure VMware Solutionプライベート クラウド内のさまざまなホストに階層を分散させることができます。
このユース ケースを実装するには、3 つの層にわたる VM-VM のアンチアフィニティ ポリシーを使用して、分散型のフォールト トレラント アーキテクチャを作成します。 このセットアップにより、アプリケーション全体の可用性が向上し、1 つのホストの障害によって階層全体またはアプリケーション全体が中断されないようにすることができます。
たとえば、ユーザー要求を提供するフロントエンド Web 層では、VM-VM のアフィニティ対策ポリシーを適用して、Web サーバーを異なる物理ホストに分散させることができます。 このアプローチは、高可用性とフォールト トレランスの向上に役立ちます。 同様に、アフィニティ対策を使用して、ビジネス 層内のアプリケーション サーバーを保護し、データベース レイヤー内のデータの回復性を強化できます。
推奨事項
- VM の相互依存関係、通信、および使用パターンを示すマップを作成して、近接性が要件であることを確認します。
- 配置ポリシー VM と VM のアフィニティが、パフォーマンス メトリックまたはサービス レベル アグリーメント (SLA) を満たすのに役立つかどうかを判断します。
- ホストの障害から保護し、アプリケーションを複数のホストに分散するために、配置 VM-VM のアフィニティ対策ポリシーを実装して高可用性を実現するように設計します。
- オーバープロビジョニングを回避するには、いくつかの大規模な VM ではなく、小規模な VM にワークロードを分散します。
- アフィニティ ポリシーを定期的に監視、確認、微調整して、リソースの競合の可能性を特定します。 必要に応じて、これらのポリシーを時間の経過と同時に調整します。
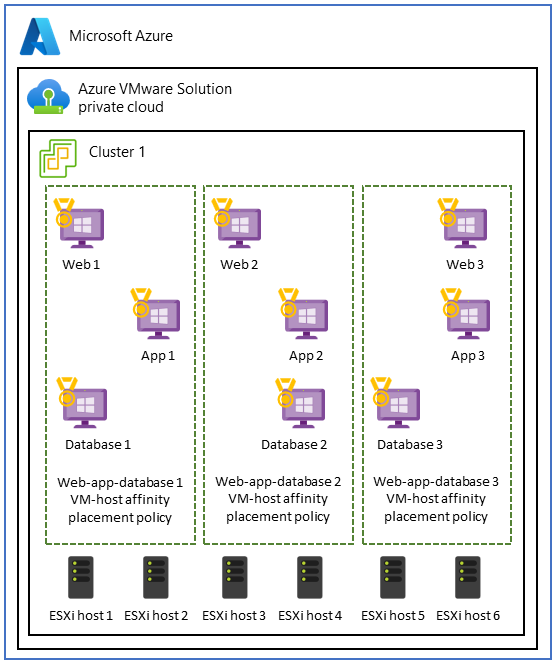
VM ホスト アフィニティ ポリシーを使用してパフォーマンスを分離する
異なるアプリケーション層で VM を実行する一部のワークロードは、併置されるとパフォーマンスが向上します。 このユース ケースは、多くの場合、アプリケーションで次のことが必要な場合に発生します。
- リソースを集中的に使用する高パフォーマンスのコンピューティング ワークロードのパフォーマンスの分離。
- ライセンス契約への準拠。 たとえば、システム仕様では、Windows またはSQL Server ライセンスへの準拠を維持するために、VM を特定のコア セットに関連付けるマッピングが必要になる場合があります。
- 特定のセキュリティ ドメインまたはデータ分類に属する VM が、クラスター内の特定のホストまたはホストのサブセットに限定されるようにするための規制コンプライアンスとデータ整合性。
- VM を同じホストに配置する 簡略化されたネットワーク構成 。 この場合、層間のネットワーク構成が簡略化されます。 層は同じネットワーク接続を共有し、追加のネットワーク ホップは必要ありません。
アプリケーション層のコロケーションを維持することが不可欠な場合は、 VM ホスト アフィニティ ポリシーを選択して、同じホストと同じ可用性ゾーン内に層がデプロイされるようにすることができます。
注意
プラットフォーム チームは、VM の配置、ホスト アフィニティルール、リソース プールの設定を担当します。 ただし、アプリケーション チームは、アプリケーションのニーズが満たされていることを確認するために、各アプリケーションのパフォーマンス要件を理解する必要があります。
アプリケーション チームは、VM の配置を包括的に評価し、細心の計画に取り組む必要があります。 VM の配置により、リソースの不均衡やワークロードの分散が不均等な場合など、潜在的な課題が生じる可能性があります。 このような状況は、パフォーマンスとリソースの最適化に悪影響を及ぼす可能性があります。 また、すべてのワークロードを 1 つの可用性ゾーンに配置すると、障害発生時に単一障害点が発生する可能性があります。 障害発生時のデータセンターの回復性を高めるために、複数の可用性ゾーン間で構成をレプリケートすることを検討してください。
推奨事項
- 配置ポリシー VM ホスト アフィニティ ポリシーの使用方法を慎重に計画します。 可能な場合は、負荷分散、VMware vSphere のリソース プール、分散データベース、コンテナー化、可用性ゾーンなどの代替ソリューションを検討してください。
- リソースの使用率とパフォーマンスを定期的に監視して、不均衡や問題を特定します。
- バランスと柔軟性を備えた VM 配置戦略を選択します。 このアプローチは、高可用性を維持しながらリソースの使用率を最大化し、ライセンス要件へのコンプライアンスを確保するのに役立ちます。
- 配置ポリシー VM とホストのアフィニティ構成をテストして検証し、それらがアプリケーションの特定の要件に合っていることを確認し、全体的なパフォーマンスと回復性に悪影響を与えないようにします。
アプリケーションまたはネットワーク ロード バランサーを使用してトラフィックを分散する
配置ポリシーの使用に加えて、負荷分散は、最新のアプリケーションの重要なコンポーネントでもあります。
- 効率的なリソース分散。
- アプリケーションの可用性の向上。
- 最適なアプリケーション パフォーマンス。
負荷分散は、ワークロードのスケーリングと管理の柔軟性を維持しながら、これらの条件を満たしています。
VM にアプリケーションをデプロイした後は、Azure Application Gatewayなどの負荷分散ツールを使用してバックエンド プールを作成することを検討してください。 Application Gatewayは、Web アプリケーションへの受信 HTTP および HTTPS トラフィックを管理および最適化できる、マネージド Web トラフィック ロード バランサーとアプリケーション配信サービスです。 Application Gatewayは、Web トラフィックのエントリ ポイントとして、さまざまな種類の機能を提供します。 たとえば、TLS/SSL 終端、URL ベースのルーティング、セッション アフィニティ、Web アプリケーション ファイアウォール機能などがあります。
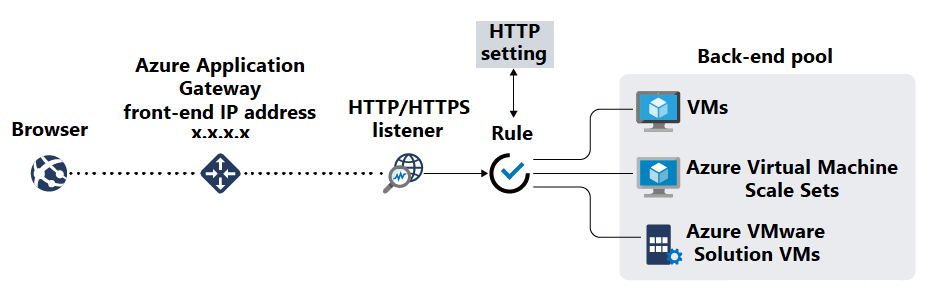
バックエンド プール内のリソースを使用できるようになったら、リスナーを作成して、受信要求のポートとルーティング規則を指定します。 その後、正常性プローブを作成して VM の正常性を監視し、異常なバックエンド リソースをローテーションから削除するタイミングを示すことができます。
TLS/SSL 終了と証明書管理を実装する
アプリケーションとユーザーのブラウザー間のすべての通信に TLS/SSL 暗号化を適用する必要があります。 この暗号化は、傍受攻撃や中間者攻撃からセッション データを保護するのに役立ちます。 アプリケーションで TLS/SSL 終了が必要な場合は、バックエンド VM から TLS/SSL 処理をオフロードするために、Application Gatewayで必要な TLS/SSL 証明書を構成します。
TLS/SSL 証明書を生成したら、Azure Key Vault などのサービスに配置し、安全に保存してアクセスできるようにします。 PowerShell、Azure CLI、または Azure Automation などのツールを使用して、証明書を更新および更新します。
API を管理する
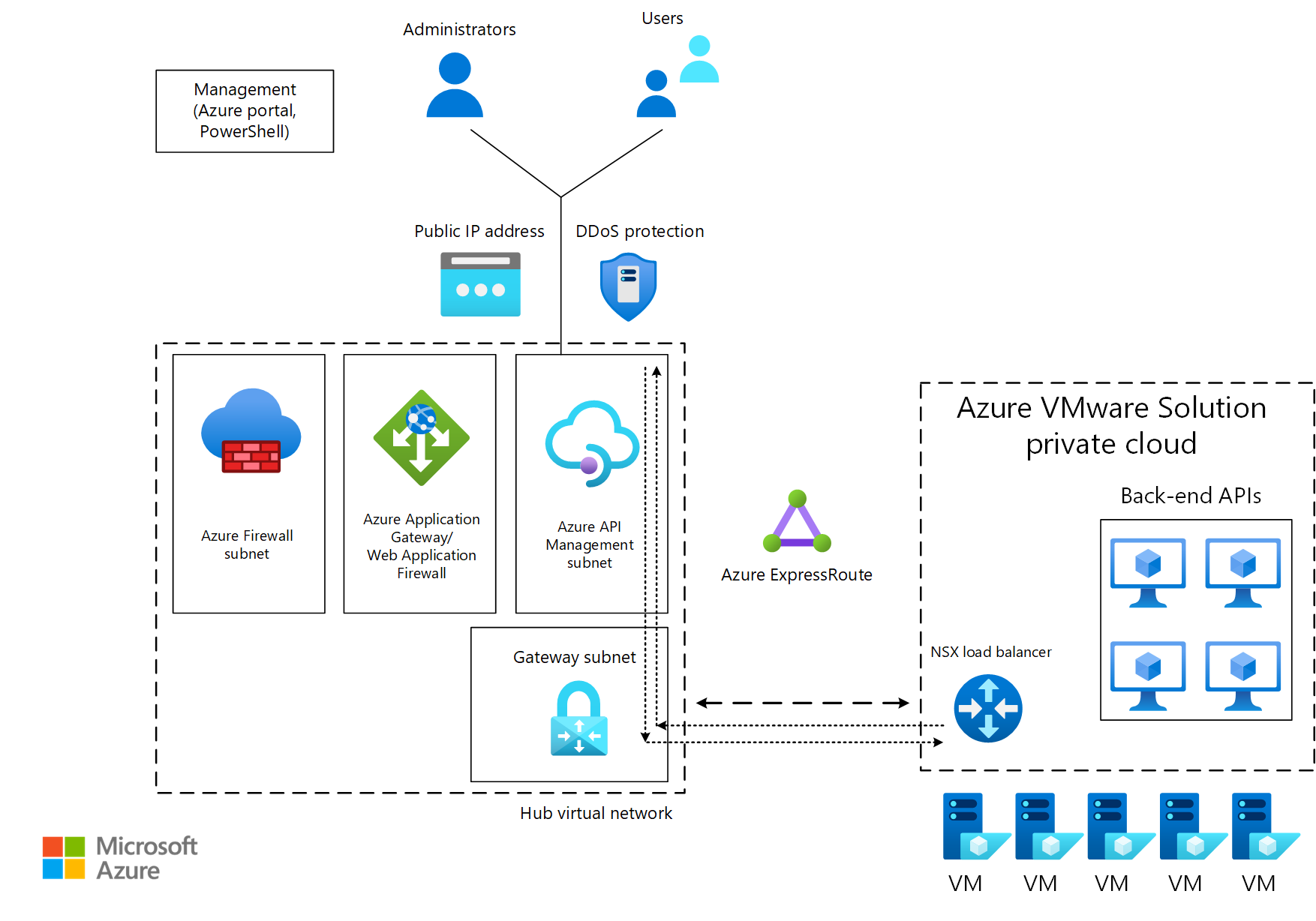
Azure API Managementは、内部および外部にデプロイされた API エンドポイントを安全に発行するのに役立ちます。 エンドポイントの例としては、ロード バランサーまたはApplication Gatewayの背後にあるAzure VMware Solutionプライベート クラウド内にあるバックエンド API があります。 API Managementは、セキュリティ ポリシーを適用して認証と承認を適用するなど、API のメソッドと動作を管理するのに役立ちます。 API Managementでは、Application Gatewayを介してバックエンド サービスに API 要求をルーティングすることもできます。
次の図では、コンシューマーからのトラフィックがAPI Managementパブリック エンドポイントに移動します。 その後、トラフィックは、Azure VMware Solutionで実行されるバックエンド API に転送されます。
推奨事項
- Azure VMware Solution アプリケーションのセキュリティとパフォーマンスを向上させるには、Azure VMware SolutionバックエンドでApplication Gatewayを使用して、アプリケーション エンドポイントにトラフィックを分散します。
- Azure VMware Solutionをホストするバックエンド セグメントと、Application Gatewayまたはロード バランサーを含むサブネットとの間に接続があることを確認します。
- バックエンド インスタンスの正常性を監視するための正常性の構成が証明されます。
- バックエンド VM の処理オーバーヘッドを減らすために、TLS/SSL 終了をApplication Gatewayにオフロードします。
- TLS/SSL キーをコンテナーに安全に格納します。
- 証明書の更新や更新などのタスクを自動化することで、プロセスを効率化します。
ストレッチ クラスターを最適化してビジネス継続性とディザスター リカバリーの準備を強化する
影響: 信頼性
ストレッチ クラスターは、複数の地理的に分散されたデータセンターにわたって高可用性とディザスター リカバリー機能を VMware クラスターに提供します。
次のセットアップでは、アクティブ/アクティブ アーキテクチャがサポートされています。 仮想記憶域ネットワーク (vSAN) は、2 つのデータセンターにまたがる。 3 つ目の可用性ゾーンは vSAN 監視にマップされ、スプリット ブレイン シナリオのクォーラムとして機能します。
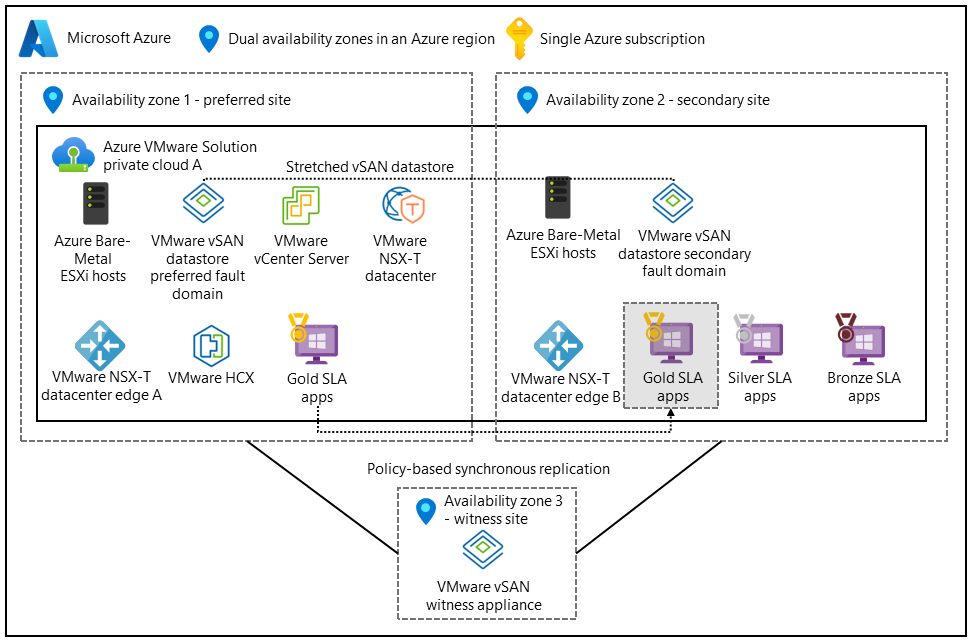
複数の可用性ゾーンとリージョンにアプリケーションを分散すると、データセンターの障害時に継続的な可用性を確保するのに役立ちます。 アプリケーション層とデータ層を両方のデータセンターにデプロイし、同期レプリケーションを有効にします。
フォールト トレランスと障害を構成して許容 (FTT) ポリシーを構成する
アプリケーションの使用可能な合計容量は、いくつかの変数によって異なります。 たとえば、独立ディスク (RAID) 構成の冗長配列、属性の failures to tolerate 値、ストレージ システムが許容できる障害の数を制御する許容 (FTT) ポリシーの障害などがあります。 アプリケーション チームは、アプリケーションに必要な冗長性のレベルを決定する必要があります。 また、FTT 値が高いほどデータの回復性は向上しますが、ストレージのオーバーヘッドは増加します。
推奨事項
- ストレッチ クラスター全体で VM データの一貫性が維持されるように、共有ストレージ間でアプリケーションをデプロイします。 同期レプリケーションを有効にします。
- 障害シナリオでストレッチ クラスターが応答する方法を定義するように、障害ドメインを構成します。
- 自動フェールオーバーとフェールバックを実装して、フェールオーバーおよび復旧イベント中の手動介入を最小限に抑えます。
データ同期とストレージ ポリシーを構成する
データ同期方法は、アプリケーションがステートフル データとデータベースに依存して、障害発生時の一貫性と可用性を確保する場合に重要です。 データ同期は、アプリケーションを実行する重要な VM の高可用性とフォールト トレランスを提供するのに役立ちます。
アプリケーション所有者は、次のことを確実にするためにストレージ ポリシーを定義できます。
- アプリケーションを実行する重要な VM は、必要なレベルのデータ冗長性とパフォーマンスを受け取ります。
- VM は、Azure VMware Solutionのストレッチ クラスターの高可用性機能を利用するように配置されています。
ポリシーの例には、次の要因が含まれる場合があります。
- vSAN 構成。 可用性ゾーン間でストレッチ クラスターを使用して VMware vSAN を使用します。
- 許容するエラーの数。 少なくとも 1 つ以上の障害を許容するようにポリシーを設定します。 たとえば、RAID-1 レイアウトを使用します。
- パフォーマンス。 重要な VM の IOPS と待機時間を最適化するために、パフォーマンス関連の設定を構成します。
- アフィニティ ルール。 データセンターの障害時の可用性を最大化するために、VM または VM のグループがストレッチ クラスター内の個別のホストまたは障害ドメインに配置されるように、アフィニティ ルールを設定します。
- バックアップとレプリケーション。 バックアップおよびレプリケーション ソリューションとの統合を指定して、VM データが定期的にバックアップされ、追加のデータ保護のためにセカンダリの場所にレプリケートされるようにします。
推奨事項
- vSAN でデータ ストレージ ポリシーを定義して、さまざまな VM ディスクに必要な冗長性とパフォーマンスを指定します。
- 重要なアプリケーション コンポーネントがデータセンターの障害時に失敗するように、アクティブ/アクティブまたはアクティブ/パッシブ構成で実行するようにアプリケーションを構成します。
- 各アプリケーションのネットワーク要件を理解します。 可用性ゾーン間で実行されるアプリケーションでは、可用性ゾーン内のトラフィックを含むアプリケーションよりも待機時間が長くなる可能性があります。 この待機時間を許容するようにアプリケーションを設計します。
- 配置ポリシーでパフォーマンス テストを実行して、アプリケーションへの影響を評価します。
次のステップ
アプリケーション プラットフォームを確認したので、接続を確立し、ワークロードの境界を作成し、アプリケーション ワークロードにトラフィックを均等に分散する方法を確認します。
評価ツールを使用して、設計の選択を評価します。