このトピックでは、x86 アーキテクチャの 64 ビット拡張機能である x64 用の基本的なアプリケーション バイナリ インターフェイス (ABI) について説明します。 呼び出し規則、型レイアウト、スタックとレジスタの使用状況などのトピックについて説明します。
x64 呼び出し規則
x86 と x64 には、次の 2 つの重要な違いがあります。
- 64 ビット アドレス指定機能
- 一般的な使用のための 16 個の 64 ビット レジスタ。
拡張レジスタ セットを指定すると、x64 は __fastcall 呼び出し規則と RISC ベースの例外処理モデルを使用します。
__fastcall 規則では、最初の 4 つの引数にレジスタを使用し、スタック フレームを使用して追加の引数を渡します。 レジスタの使用、スタック パラメーター、戻り値、スタック アンワインドなど、x64 呼び出し規則の詳細については、「x64 での呼び出し規則」を参照してください。
__vectorcall 呼び出し規則の詳細については、__vectorcall の説明を参照してください。
x64 コンパイラの最適化を有効にする
次のコンパイラ オプションは、x64 用にアプリケーションを最適化するのに役立ちます。
x64 型とストレージ レイアウト
このセクションでは、x64 アーキテクチャのデータ型のストレージについて説明します。
スカラー型
どのようなアラインメントでもデータにアクセスできますが、パフォーマンスの低下を避けるために、データをその自然境界 (またはその複数の自然境界) にアラインすることをお勧めします。 列挙型は定数の整数で、32 ビット整数として扱われます。 次の表では、次のアラインメント値を使用したアラインメントに関連するデータの型の定義と推奨されるストレージについて説明します。
- バイト - 8 ビット
- ワード - 16 ビット
- ダブルワード - 32 ビット
- クアッドワード - 64 ビット
- オクタワード - 128 ビット
| スカラー型 | C言語のデータ型 | ストレージ サイズ (バイト単位) | 推奨されるアラインメント |
|---|---|---|---|
INT8 |
char |
1 | Byte |
UINT8 |
unsigned char |
1 | Byte |
INT16 |
short |
2 | ワード |
UINT16 |
unsigned short |
2 | ワード |
INT32 |
int、long |
4 | ダブルワード |
UINT32 |
unsigned int、unsigned long |
4 | ダブルワード |
INT64 |
__int64 |
8 | クアッドワード |
UINT64 |
unsigned __int64 |
8 | クアッドワード |
FP32 (単精度) |
float |
4 | ダブルワード |
FP64 (倍精度) |
double |
8 | クアッドワード |
POINTER |
* | 8 | クアッドワード |
__m64 |
struct __m64 |
8 | クアッドワード |
__m128 |
struct __m128 |
16 | オクタワード |
x64 アグリゲートとユニオンのレイアウト
配列、構造体、共用体などの他の型には、一貫性のある集計と共用体のストレージおよびデータ取得を保証する、より厳密なアラインメント要件があります。 配列、構造体、および共用体の定義を次に示します。
配列
隣接するデータ オブジェクトの順序付けされたグループが含まれています。 各オブジェクトは、"要素" と呼ばれます。 配列内のすべての要素のサイズとデータ型は同じです。
構造
データ オブジェクトの順序付けされたグループが含まれています。 配列の要素とは異なり、構造体のメンバーのデータ型とサイズは異なる場合があります。
結合
名前付きメンバーのセットのいずれかを保持するオブジェクト。 名前付きセットのメンバーは任意の型であることができます。 共用体に割り当てられたストレージは、その共用体の最大のメンバーに必要なストレージに、アラインメントに必要なパディングを加えたものに相当します。
次の表は、共用体と構造体のスカラー メンバーに対して強く推奨されるアラインメントを示しています。
| スカラー型 | C データ型 | 必須のアラインメント |
|---|---|---|
INT8 |
char |
Byte |
UINT8 |
unsigned char |
Byte |
INT16 |
short |
ワード |
UINT16 |
unsigned short |
ワード |
INT32 |
int、long |
ダブルワード |
UINT32 |
unsigned int、unsigned long |
ダブルワード |
INT64 |
__int64 |
クアッドワード |
UINT64 |
unsigned __int64 |
クアッドワード |
FP32 (単精度) |
float |
ダブルワード |
FP64 (倍精度) |
double |
クアッドワード |
POINTER |
* | クアッドワード |
__m64 |
struct __m64 |
クアッドワード |
__m128 |
struct __m128 |
オクタワード |
次の集約アラインメント規則が適用されます。
配列のアラインメントは、その配列の要素のいずれかのアラインメントと同じです。
構造体または共用体の先頭のアラインメントは、個々のメンバーの最大のアラインメントです。 構造体または共用体内の各メンバーは、前の表で定義されている適切なアラインメントに配置する必要があります。これには、前のメンバーに応じて、暗黙的な内部パディングが必要になる場合があります。
構造体のサイズは、そのアラインメントの整数倍数である必要があるため、最後のメンバーの後にパディングが必要になる場合があります。 構造体と共用体は配列でグループ化できるため、構造体または共用体の各配列要素は、事前に決定された適切なアラインメントで開始および終了する必要があります。
前のルールが保持されている限り、データがアラインメント要件よりも大きくなるように配置できます。
個々のコンパイラでは、サイズ上の理由から構造体のパッキングを調整できます。 たとえば /Zp (構造体メンバーのアラインメント) では、構造体のパッキングを調整できます。
x64 構造体の配置例
次の 4 つの例では、それぞれがアラインされた構造体または共用体を宣言し、対応する図は、メモリ内のその構造体または共用体のレイアウトを示します。 図の各列はメモリのバイトを表し、列の数値はそのバイトのディスプレイスメントを示します。 各図の 2 番目の行の名前は、宣言内の変数の名前に対応しています。 影付きの列は、指定されたアラインメントを実現するために必要なパディングを示します。
例 1
// Total size = 2 bytes, alignment = 2 bytes (word).
_declspec(align(2)) struct {
short a; // +0; size = 2 bytes
}

例 2
// Total size = 24 bytes, alignment = 8 bytes (quadword).
_declspec(align(8)) struct {
int a; // +0; size = 4 bytes
double b; // +8; size = 8 bytes
short c; // +16; size = 2 bytes
}

この図は、24 バイトのメモリを示しています。 メンバー a (int) は、バイト 0 から 3 を占有します。 この図は、バイト 4 から 7 のパディングを示しています。 メンバー b (double) は、バイト 8 から 15 を占有します。 メンバー c (short) はバイト 16 から 17 を占有します。 バイト 18 から 23 は使用されません。
例 3
// Total size = 12 bytes, alignment = 4 bytes (doubleword).
_declspec(align(4)) struct {
char a; // +0; size = 1 byte
short b; // +2; size = 2 bytes
char c; // +4; size = 1 byte
int d; // +8; size = 4 bytes
}
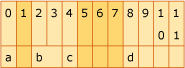
この図は、12 バイトのメモリを示しています。 メンバー a、char はバイト 0 を占有します。 バイト 1 はパディングです。 メンバー b (short) はバイト 2 から 4 を占有します。 メンバー c、char はバイト 4 を占有します。 バイト 5 ~ 7 はパディングです。 メンバー d (int) は、バイト 8 から 11 を占有します。
例 4
// Total size = 8 bytes, alignment = 8 bytes (quadword).
_declspec(align(8)) union {
char *p; // +0; size = 8 bytes
short s; // +0; size = 2 bytes
long l; // +0; size = 4 bytes
}

この図は、8 バイトのメモリを示しています。 メンバー p (char) はバイト 0 を占有します。 メンバー s (short) は、バイト 0 から 1 を占有します。 メンバー l (long) はバイト 0 から 3 を占有します。 バイト 4 から 7 はパディングです。
ビット フィールド
構造体のビット フィールドは 64 ビットに制限されており、signed int、unsigned int、int64、または unsigned int64 のいずれかの型になります。 型の境界を越えるビットフィールドは、次の型のアラインメントに合わせてビットをスキップします。 たとえば、整数ビット フィールドは 32 ビット境界を越えてはなりません。
x86 コンパイラとの競合
4 バイトを超えるデータ型は、x86 コンパイラを使用してアプリケーションをコンパイルするときに、スタックに自動的にはアラインされません。 x86 コンパイラのアーキテクチャは 4 バイトでアラインされたスタックであるため、64 ビット整数のように 4 バイトを超えるものは、8 バイトのアドレスに自動的にアラインすることはできません。
アラインされていないデータの操作には、2 つの意味合いがあります。
アラインされた場所にアクセスする場合よりも、アラインされていない場所にアクセスするほうが時間がかかることがあります。
アラインされていない場所は、インタロック操作では使用できません。
より厳密なアラインメントが必要な場合は、変数宣言で __declspec(align(N)) を使用します。 これにより、コンパイラは、指定された仕様に合わせてスタックを動的にアラインします。 ただし、実行時にスタックを動的に調整すると、アプリケーションの実行速度が低下する可能性があります。
x64 レジスタの使用
x64 アーキテクチャには、16 個の汎用レジスタ (これ以降、整数レジスタと呼びます) と 16 個の浮動小数点用の XMM/YMM レジスタが用意されています。 volatile レジスタは、呼び出しで使用された後に内容が破棄されることが、呼び出し元によって想定されているスクラッチ レジスタです。 関数呼び出しで使用された後もレジスタの値を保持するには非 volatile レジスタが必要です。使用された非 volatile レジスタの保存は、呼び出し先が行う必要があります。
レジスタの揮発性と保持
関数呼び出しで各レジスタがどのように使用されるかを次の表に示します。
| 登録する | ステータス | 使用 |
|---|---|---|
| RAX | 揮発性 | 戻り値レジスタ |
| RCX | 揮発性 | 1 番目の整数引数 |
| RDX | 揮発性 | 2 番目の整数引数 |
| R8 | 揮発性 | 3 番目の整数引数 |
| R9 | 揮発性 | 4 番目の整数引数 |
| R10:R11 | 揮発性 | 必要に応じて、呼び出し元によって保持される必要があります。syscall/sysret 命令で使用されます。 |
| R12:R15 | 不揮発性 | 呼び出し先によって保持される必要があります。 |
| RDI | 不揮発性 | 呼び出し先によって保持される必要があります。 |
| RSI(反復性ストレス障害) | 不揮発性 | 呼び出し先によって保持される必要があります。 |
| RBX | 不揮発性 | 呼び出し先によって保持される必要があります。 |
| RBP | 不揮発性 | フレーム ポインターとして使用できます。呼び出し先によって保持される必要があります。 |
| RSP | 不揮発性 | スタック ポインター |
| XMM0、YMM0 | 揮発性 | 1 番目の FP 引数。__vectorcall が使用された場合の 1 番目のベクター型引数 |
| XMM1、YMM1 | 揮発性 | 2 番目の FP 引数。__vectorcall が使用された場合の 2 番目のベクター型引数 |
| XMM2、YMM2 | 揮発性 | 3 番目の FP 引数。__vectorcall が使用された場合の 3 番目のベクター型引数 |
| XMM3、YMM3 | 揮発性 | 4 番目の FP 引数。__vectorcall が使用された場合の 4 番目のベクター型引数 |
| XMM4、YMM4 | 揮発性 | 必要に応じて、呼び出し元によって保持される必要があります。__vectorcall が使用された場合の 5 番目のベクター型引数 |
| XMM5、YMM5 | 揮発性 | 必要に応じて、呼び出し元によって保持される必要があります。__vectorcall が使用された場合の 6 番目のベクター型引数 |
| XMM6:XMM15、YMM6:YMM15 | 非 volatile (XMM)、volatile (YMM の上半分) | 呼び出し先によって保持される必要があります。 必要に応じて、呼び出し元によって YMM レジスタが保持される必要があります。 |
関数の終了時および C ランタイム ライブラリの呼び出しと Windows システムの呼び出しに対する関数の入力時に、CPU フラグ レジスタの方向フラグがクリアされることが想定されます。
スタックの使用
x64 でのスタック割り当て、配置、関数型、スタック フレームの詳細については、 x64 スタックの使用方法に関するページを参照してください。
プロローグとエピローグ
スタック領域を割り当てる、他の関数を呼び出す、非揮発性レジスタを保存する、例外処理を使用するすべての関数には、それぞれに対応する関数テーブル エントリに関連付けられたアンワインド データでアドレス制限が記述されたプロローグと、それぞれの関数の終了時にエピローグが必要です。 x64 で必要なプロローグとエピローグ コードの詳細については、「x64 でのプロローグとエピローグ」を参照してください。
x64 での例外処理
x64 での構造化例外処理と C++ 例外処理の動作を実装するために使用される規則とデータ構造の詳細については、「x64 での例外処理」を参照してください。
組み込みおよびインライン アセンブリ
x64 コンパイラの制約の 1 つは、インライン アセンブラーをサポートしないことです。 つまり、C または C++ で記述できない関数は、サブルーチンとして記述するか、コンパイラでサポートされている組み込み関数として記述する必要があります。 一部の関数ではパフォーマンスが重視されますが、他の関数はそうではありません。 パフォーマンスが重視される関数は、組み込み関数として実装してください。
コンパイラでサポートされている組み込み関数の詳細については、「コンパイラの組み込み」を参照してください。
x64 イメージの形式
x64 の実行可能イメージ形式は PE32+ です。 実行可能イメージ (DLL と EXE の両方) は最大サイズが 2 GB に制限されているため、32 ビットのディスプレイスメントに相対アドレスを使用することで、静的な画像データに対処できます。 このデータには、インポート アドレス テーブル、文字列定数、静的グローバル データなどが含まれます。