C++ の型システム
C++ では、型の概念が重要です。 変数、関数の引数、関数の戻り値をコンパイルするには、それぞれに型が必要です。 また、すべての式 (リテラル値を含む) は、評価される前にコンパイラによって暗黙的に型が指定されます。 型の例としては、整数値の格納、浮動小数点値doubleの格納などのint組み込み型、テキストを格納するクラスstd::basic_stringなどの標準ライブラリ型などがあります。 class や struct を定義することで、独自の型を作成できます。 この型は、変数 (または式の結果) に割り当てられるメモリの量を指定します。 この型では、格納できる値の種類、コンパイラがそれらの値のビット パターンを解釈する方法、およびそれらに対して実行できる操作も指定します。 ここでは、C++ の型システムの主な機能の概要を示します。
用語
スカラー型: 定義された範囲の 1 つの値を保持する型。 スカラーには、算術型 (整数または浮動小数点値)、列挙型メンバー、ポインター型、メンバーへのポインター型、および std::nullptr_t. 基本的な型は通常、スカラー型です。
複合型: スカラー型ではない型。 複合型には、配列型、関数型、クラス (または構造体) 型、共用体型、列挙型、参照、および非静的クラス メンバーへのポインターが含まれます。
変数: データ量のシンボリック名。 名前は、定義されているコードのスコープ全体で参照するデータにアクセスするために使用できます。 C++ では、変数はスカラー データ型のインスタンスを参照するためによく使用されますが、他の型のインスタンスは通常オブジェクトと呼ばれます。
オブジェクト: わかりやすく一貫性を保つため、この記事ではオブジェクトという用語を使用して、クラスまたは構造体の任意のインスタンスを参照します。 一般的な意味で使用される場合は、スカラー変数であっても、すべての型が含まれます。
POD 型 (Plain Old Data): C++ のこの非公式なデータ型カテゴリは、スカラーであるか (「基本型」セクションを参照)、POD クラスである型を指しています。 POD クラスには、POD でもない静的データ メンバーがなく、ユーザー定義コンストラクター、ユーザー定義デストラクター、またはユーザー定義代入演算子もありません。 また、POD クラスに仮想関数、基底クラス、プライベートまたは保護された非静的データ メンバーもありません。 POD 型は、外部データ交換によく使用されます。たとえば、C 言語で記述されたモジュール (POD 型しかありません) との交換などです。
変数と関数の型の指定
C++ は厳密 に型指定された 言語と 静的に型指定された 言語の両方です。すべてのオブジェクトには型があり、その型は変更されません。 コード内で変数を宣言するときは、その型を明示的に指定するか、auto キーワードを使用して、コンパイラが初期化子から型を推論するように指示する必要があります。 コードで関数を宣言するときは、戻り値の型と各引数の型を指定する必要があります。 関数から値が返されない場合は、戻り値の型 void を使用します。 例外は、任意の型の引数を許可する関数テンプレートを使用している場合です。
最初に変数を宣言した後は、後で型を変更することはできません。 ただし、変数の値または関数の戻り値を別の型の別の変数にコピーできます。 このような操作は、"型変換" と呼ばれます。この操作が必要になることがありますが、データ損失や不正確なデータの原因となる可能性もあります。
POD 型の変数を宣言するときは、初期化することを強くお勧めします。つまり、初期値を指定します。 変数を初期化しないと、以前そのメモリ位置にたまたま存在していたビットで構成される "不要な" 値が含まれたままになります。 特に初期化を処理する別の言語から来ている場合は、覚えておく必要がある C++ の重要な側面です。 非 POD クラス型の変数を宣言すると、コンストラクターは初期化を処理します。
次の例は、それぞれ記述を含む、いくつかの簡単な変数宣言を示しています。 この例は、コンパイラが型情報を使用して、特定の後続の処理を許可または拒否する方法も示しています。
int result = 0; // Declare and initialize an integer.
double coefficient = 10.8; // Declare and initialize a floating
// point value.
auto name = "Lady G."; // Declare a variable and let compiler
// deduce the type.
auto address; // error. Compiler cannot deduce a type
// without an intializing value.
age = 12; // error. Variable declaration must
// specify a type or use auto!
result = "Kenny G."; // error. Can't assign text to an int.
string result = "zero"; // error. Can't redefine a variable with
// new type.
int maxValue; // Not recommended! maxValue contains
// garbage bits until it is initialized.
基本 (組み込み) 型
一部の言語とは異なり、C++ には他のすべての型の派生元となる汎用基本型はありません。 この言語には、多くの "基本型" ("組み込み型" とも呼ばれます) が含まれています。 これらの型には、,, , , などの数値型intに加えてchar、それぞれ ASCII 文字と wchar_t UNICODE 文字の型が含まれます。 boollongdouble ほとんどの整数の基本型 (bool、double、wchar_t と関連する型を除く) には、変数に格納できる値の範囲を変更する unsigned バージョンがあります。 たとえば、32 ビット符号付き整数が格納される int は、-2,147,483,648 から 2,147,483,647 の値を表すことができます。 32 ビットとしても格納される An unsigned intは、0 から 4,294,967,295 までの値を格納できます。 各ケースで格納できる値の合計数は同じです。範囲のみ異なります。
コンパイラはこれらの組み込み型を認識し、それらに対して実行できる操作とその他の基本的な型への変換方法を制御する組み込みの規則を備えています。 組み込みの型とそのサイズおよび数値制限の詳細な一覧については、「Built-in types」(組み込み型) を参照してください。
次の図は、Microsoft C++ 実装での組み込み型の相対的なサイズを示しています。
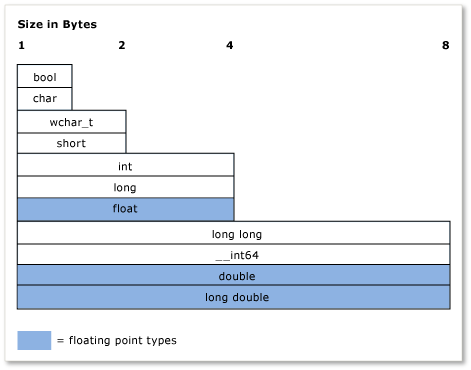
次の表は、最もよく使用される基本型と、Microsoft C++ 実装でのサイズの一覧です。
| Type | サイズ | 解説 |
|---|---|---|
int |
4 バイト | 整数値の既定のオプション。 |
double |
8 バイト | 浮動小数点値の既定のオプション。 |
bool |
1 バイト | true または false になる値を表します。 |
char |
1 バイト | 以前の C スタイル文字列内の ASCII 文字や、UNICODE に変換する必要がない std::string オブジェクトの ASCII 文字に使用します。 |
wchar_t |
2 バイト | UNICODE 形式でエンコードできるワイド文字を表します (Windows では UTF-16。他のオペレーティング システムでは異なる場合があります)。 wchar_t は、型の文字列で使用される文字型です std::wstring。 |
unsigned char |
1 バイト | C++ には組み込みのバイト型はありません。 バイト値を表すには unsigned char を使用します。 |
unsigned int |
4 バイト | ビット フラグの既定のオプション。 |
long long |
8 バイト | はるかに広い範囲の整数値を表します。 |
他の C++ 実装では、特定の数値型のサイズが異なることがあります。 C++ 標準で要求されるサイズおよびサイズの関係性の詳細については、「Built-in types」(組み込み型) を参照してください。
void 型
型は void 特殊な型です。型 voidの変数を宣言することはできませんが、型 void * (ポインター) の変数を void宣言することはできます。これは、生の (型指定されていない) メモリを割り当てるときに必要な場合があります。 ただし、ポインターは void 型セーフではなく、最新の C++ では使用しないことをお勧めします。 関数宣言では、 void 戻り値は、関数が値を返さないことを意味します。戻り値の型として使用することは、一般的で許容される使用 voidです。 C 言語では、パラメーター リストで宣言 void するパラメーターが 0 個の関数が必要ですが、 fn(void)最新の C++ ではこの方法はお勧めしません。パラメーターなしの関数を宣言 fn()する必要があります。 詳細については、「型変換とタイプ セーフ」を参照してください。
const type 修飾子
組み込み型またはユーザー定義型は、キーワード (keyword)によってconst修飾できます。 また、メンバー関数は const で修飾したり、const でオーバーロードしたりすることはできます。 型の const 値は、初期化後に変更できません。
const double PI = 3.1415;
PI = .75; //Error. Cannot modify const variable.
修飾子は const 関数と変数の宣言で広く使用され、"const correctness" は C++ の重要な概念です。基本的には、コンパイル時に値が意図せずに変更されないようにするために使用 const することを意味します。 詳細については、constを参照してください。
const型は、バージョン以外constとは異なります。たとえば、const int〘〘とは異なる型intです。 変数から "不変性" を取り除かなければならないまれな状況では、C++ の const_cast 演算子を使用できます。 詳細については、「型変換とタイプ セーフ」を参照してください。
文字列型
厳密に言うと、C++ 言語には組み込みの文字列型がありません。char と wchar_t には単一の文字が格納されます。文字列に近づけるには、これらの型の配列を宣言し、最後の有効な文字の 1 つ後の配列要素に終端の null 値 (ASCII '\0' など) を追加する必要があります ("C スタイル文字列" とも呼ばれます)。 C スタイル文字列では、かなり多くのコードを記述するか、外部文字列ユーティリティ ライブラリ関数を使用する必要がありました。 しかし、最新の C++ には、標準ライブラリの型 std::string (8 ビットの char 型文字列の場合) または std::wstring (16 ビットの wchar_t 型文字列の場合) があります。 これらの C++ 標準ライブラリ コンテナーは、準拠している C++ ビルド環境に含まれる標準ライブラリの一部であるため、ネイティブ文字列型と考えることができます。 ディレクティブを #include <string> 使用して、これらの型をプログラムで使用できるようにします。 (MFC または ATL を使用している場合は、CStringクラスも使用できますが、C++ 標準の一部ではありません)。最新の C++ では、null で終わる文字配列 (以前にメンションされた C スタイルの文字列) を使用しないことをお勧めします。
ユーザー定義データ型
class、struct、union、または enum を定義すると、コードの残りの部分では、そのコンストラクトは基本型と同じように使用することができます。 メモリ内には既知のサイズがあり、コンパイル時のチェックを要求し、実行時にプログラムの有効期間を問い合わせるために使用する方法に関する一定の規則もあります。 基本の組み込み型とユーザー定義型の主な相違点は次のとおりです。
コンパイラには、ユーザー定義型に関する組み込みの情報はありません。 コンパイル プロセス中に初めて定義を検出したときに、型について知ります。
クラス メンバーまたは非メンバー関数として適切な演算子を定義することで (オーバーロードを通じて)、型で実行可能な操作と他の方に変換する方法を指定します。 詳細については、「関数のオーバーロード」を参照してください 。
ポインター型
C 言語の初期のバージョンと同様に、C++ では引き続き、特殊な宣言子 * (アスタリスク) を使用してポインター型の変数を宣言できます。 ポインター型には、実際のデータ値が格納されているメモリ位置のアドレスが格納されます。 最新の C++ では、これらのポインター型は生ポインターと呼ばれ、特殊な演算子 * (アスタリスク) または -> (大きい値を持つダッシュ、多くの場合矢印と呼ばれます) を使用してコード内でアクセスされます。 このメモリ アクセス操作は逆参照と呼ばれます。 どの演算子を使用するかは、スカラーへのポインターを逆参照するか、オブジェクト内のメンバーへのポインターを逆参照するかによって異なります。
ポインター型の使用は、長い間 C および C++ プログラム開発における最も困難で複雑な側面の 1 つでした。 このセクションでは、生ポインターを使用する場合に役立ついくつかの事実とプラクティスについて説明します。 ただし、最新の C++ では、スマート ポインターが進化しているため (このセクションの最後で詳しく説明します)、オブジェクトの所有権に生ポインターを使用する必要がなくなりました (または推奨されます)。 オブジェクトを観察するために生のポインターを使用することは、依然として便利で安全です。 ただし、オブジェクトの所有権に使用する必要がある場合は、慎重に行い、所有するオブジェクトがどのように作成および破棄されるかを慎重に考慮する必要があります。
最初に知っておくべきことは、生のポインター変数宣言では、アドレスを格納するのに十分なメモリ (逆参照時にポインターが参照するメモリの場所) のみを割り当てることです。 ポインター宣言では、データ値の格納に必要なメモリは割り当てられません。 (そのメモリはバッキング ストアとも呼ばれます)。つまり、生ポインター変数を宣言することで、実際のデータ変数ではなく、メモリ アドレス変数を作成します。 バッキング ストアの有効なアドレスが含まれていることを確認する前にポインター変数を逆参照すると、プログラムで未定義の動作 (通常は致命的なエラー) が発生します。 この種のエラーの例を次に示します。
int* pNumber; // Declare a pointer-to-int variable.
*pNumber = 10; // error. Although this may compile, it is
// a serious error. We are dereferencing an
// uninitialized pointer variable with no
// allocated memory to point to.
この例では、実際の整数データまたはそこに割り当てられた有効なメモリ アドレスを格納するメモリを割り当てずに、ポインター型を逆参照しています。 このエラーを修正するコード例を次に示します。
int number = 10; // Declare and initialize a local integer
// variable for data backing store.
int* pNumber = &number; // Declare and initialize a local integer
// pointer variable to a valid memory
// address to that backing store.
...
*pNumber = 41; // Dereference and store a new value in
// the memory pointed to by
// pNumber, the integer variable called
// "number". Note "number" was changed, not
// "pNumber".
修正後のコード例では、ローカル スタック メモリを使用して、pNumber がポイントするバッキング ストアを作成します。 ここでは、説明を簡単にするために基本型を使用しています。 実際には、ポインターのバッキング ストアは、最も多くの場合、キーワード (keyword)式を使用してヒープ (またはフリー ストア) と呼ばれるメモリ領域に動的に割り当てられるユーザー定義型です (C スタイルのプログラミングでは、以前malloc()の C ランタイム ライブラリ関数が使用newされました)。 割り当てられると、これらの変数は通常、特にクラス定義に基づいている場合に、オブジェクトと呼ばれます。 new によって割り当てられたメモリは、対応する delete ステートメント (または、malloc() 関数を使用して割り当てる場合は、C ランタイム関数 free()) によって削除される必要があります。
ただし、特に複雑なコードでは、動的に割り当てられたオブジェクトを削除することを忘れやすくなります。これにより、メモリ リークと呼ばれるリソース バグが発生します。 このため、最新の C++ では生ポインターを使用しないことをお勧めします。 ほとんどの場合、生のポインターをスマート ポインターでラップすることをお勧めします。これは、デストラクターが呼び出されたときにメモリを自動的に解放します。 (つまり、コードがスマート ポインターのスコープ外になった場合)。スマート ポインターを使用すると、C++ プログラムのバグのクラス全体を実質的に排除できます。 次の例では、MyClass がパブリック メソッド DoSomeWork(); を持つユーザー定義型であることを前提としています。
void someFunction() {
unique_ptr<MyClass> pMc(new MyClass);
pMc->DoSomeWork();
}
// No memory leak. Out-of-scope automatically calls the destructor
// for the unique_ptr, freeing the resource.
スマート ポインターの詳細については、「スマート ポインター」を参照してください。
ポインター変換の詳細については、「型変換と型セーフ」を参照してください。
ポインター全般の詳細については、「ポインター」を参照してください。
Windows のデータ型
C および C++ 向けの従来の Win32 プログラミングでは、ほとんどの関数は Windows 固有の typedef マクロと #define マクロ (windef.h で定義) を使用して、パラメーターと戻り値の型を指定します。 これらの Windows データ型は、主に C/C++ 組み込み型に与えられる特別な名前 (エイリアス) です。 これらの typedef とプリプロセッサ定義の詳細な一覧については、「Windows のデータ型」を参照してください。 HRESULT や LCID など、typedef には便利で内容がわかりやすいものがあります。 INT など、他の typedef には特別な意味がなく、C++ の基本型のエイリアスにすぎません。 他の Windows のデータ型には、C プログラミングおよび 16 ビット プロセッサの時代から残っている名前がありますが、最新のハードウェアやオペレーティング システムでは目的も意味もありません。 「Windows ランタイムの基本データ型」に挙げられているように、Windows ランタイム ライブラリに関連付けられている特殊なデータ型もあります。 最新の C++ では、Windows 型が値の解釈方法に関する追加の意味を伝えない限り、一般的なガイドラインは C++ の基本型を優先することです。
詳細情報
C++ 型システムの詳細については、次の記事を参照してください。
値型
"値の型" とその使用に関連する問題について説明します。
型変換とタイプ セーフ
よくある型変換の問題について説明し、その回避方法を示します。
関連項目
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示