この記事は、ビジネス クリティカルなシナリオでオンプレミス データ ゲートウェイをデプロイすることを計画しているユーザーを対象としています。 オンプレミス データ ゲートウェイは、ビジネスの通常の運用に不可欠であり、ビジネスクリティカルなデータを処理する場合、ビジネス クリティカルです。
ビジネス クリティカルなゲートウェイが適切に管理されていない場合は、クエリの失敗やパフォーマンスの低下が発生する可能性があります。 ビジネスクリティカルなゲートウェイ ソリューションを適切に計画、スケーリング、保守すると、ビジネスに影響を与える問題の可能性を最小限に抑えることができます。
用語
この記事では、次の重要な用語を使用します。
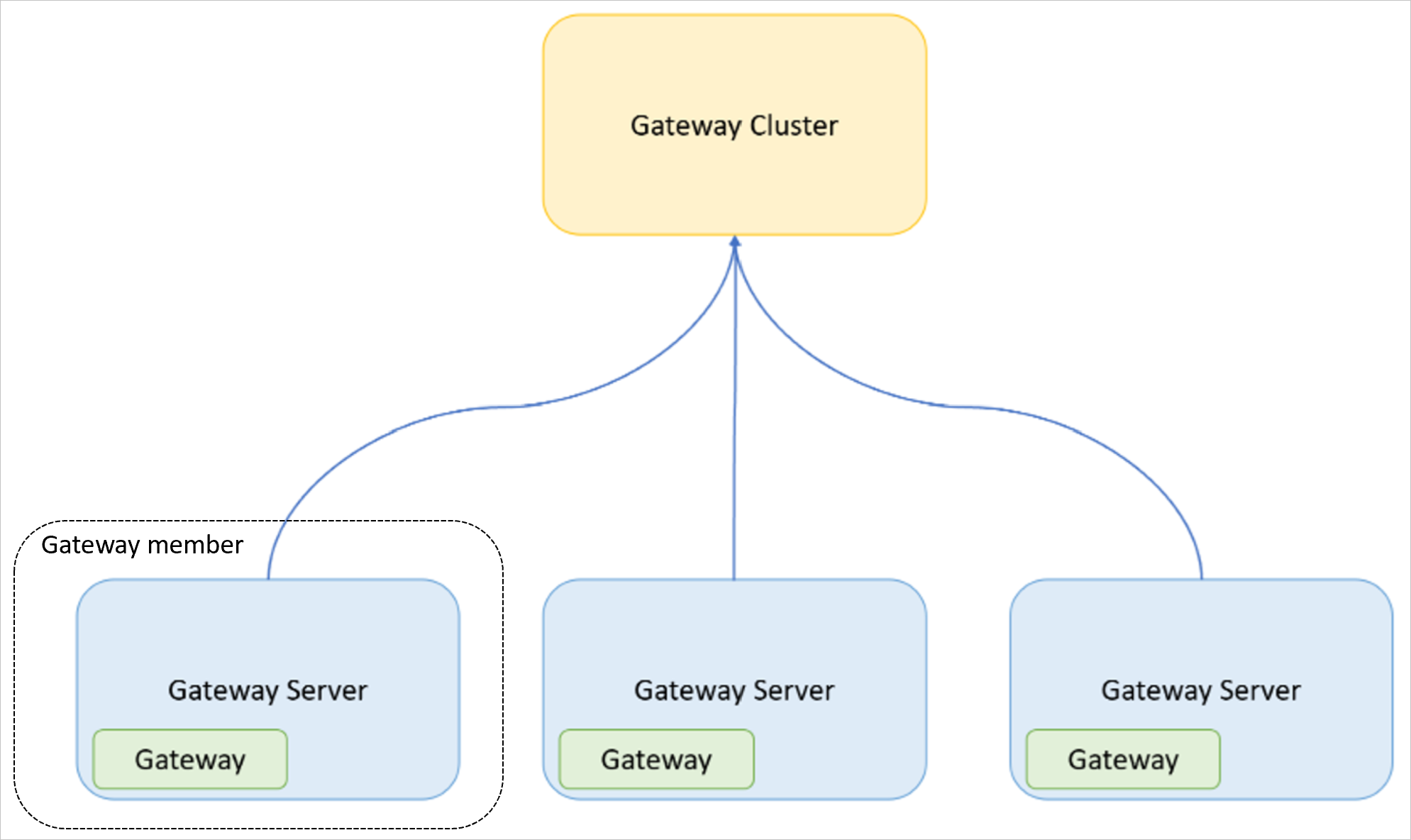
- ゲートウェイ: コンピューターにインストールされているオンプレミス データ ゲートウェイ アプリケーション。
- ゲートウェイ サーバー: オンプレミス データ ゲートウェイ アプリケーションがインストールされている Windows コンピューター (仮想マシンまたは物理コンピューター/サーバー)。
- ゲートウェイ クラスター: 連携して (負荷分散される可能性がある) 一連のゲートウェイ。
- ゲートウェイ メンバー: ゲートウェイ クラスターの一部であるゲートウェイ。
次の図は、上記で定義した概念間の関係を示しています。
ビジネス クリティカルなゲートウェイに関する推奨事項
ビジネス クリティカルなゲートウェイの場合は、高可用性、優れたパフォーマンス、保守可能なスケーラビリティを確保するために、ゲートウェイを適切にデプロイして管理する必要があります。 ゲートウェイを誤ってデプロイすると、パフォーマンスが低下し、クエリが失敗し、潜在的な問題の診断が困難になる可能性があります。 また、使用量の増加に合わせてゲートウェイをスケールアップおよびスケールアウトする機能も妨げる可能性があります。
最適なスケーラビリティ、パフォーマンス、スループットを確保するには、次のセクションの推奨事項に従ってください。
すべてのゲートウェイ回復キーを把握する
すべてのゲートウェイ回復キーが 既知であり、安全な場所に保管されていることを確認します。 回復キーがないと、ゲートウェイを復旧またはダウングレードすることはできません。 この制限は設計上の問題です。 回復キーを紛失した場合、唯一のオプションは、新しいゲートウェイを作成し、データ ソースを再作成することです。 また、復旧キーなしで新しいゲートウェイをクラスターに追加することはできません。そのため、将来のスケーラビリティが制限されます。
パスワード セーフなど、承認された管理者のみがアクセスできる管理者資格情報を格納するのと同様に、回復キーを安全な場所に格納します。
現在、すべてのゲートウェイ回復キーがわからない場合、これは 重大なビジネス リスクです。 新しいゲートウェイ クラスターをすぐに作成し、新しいゲートウェイ クラスターへのワークロードの移行を開始します。
開発ワークロードとビジネス クリティカルなワークロード
1 つ以上の開発ゲートウェイ クラスターと 1 つ以上の運用ゲートウェイ クラスターを設定することで、開発ワークロードとビジネス クリティカルなワークロードを分離します。
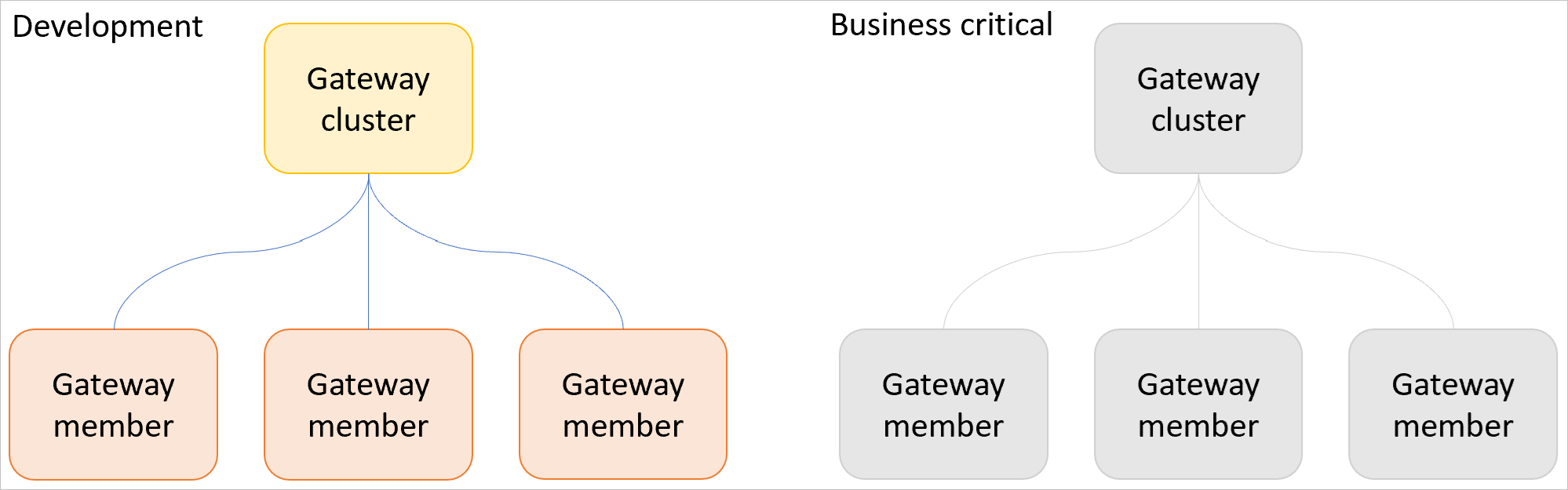
開発ゲートウェイ クラスターを使用して、新しいセマンティック モデル、レポート、クエリなどをテストします。 新しいワークロードが検証されたら、ビジネス クリティカルなゲートウェイ クラスターに移行します。 このプロセスにより、新しいワークロード、テストされていないワークロード、または試験段階のワークロードが運用環境のワークロードにパフォーマンスに影響を与えるのを防ぐことができます。
また、ビジネス クリティカルなゲートウェイ クラスターに更新プログラムを適用する前に、開発ゲートウェイ クラスターを使用して新しいゲートウェイの更新をテストします。 新しいゲートウェイの更新プログラムは、ビジネス クリティカルなゲートウェイ クラスターで使用される前に、開発ゲートウェイ クラスターに少なくとも 24 時間デプロイする必要があります。
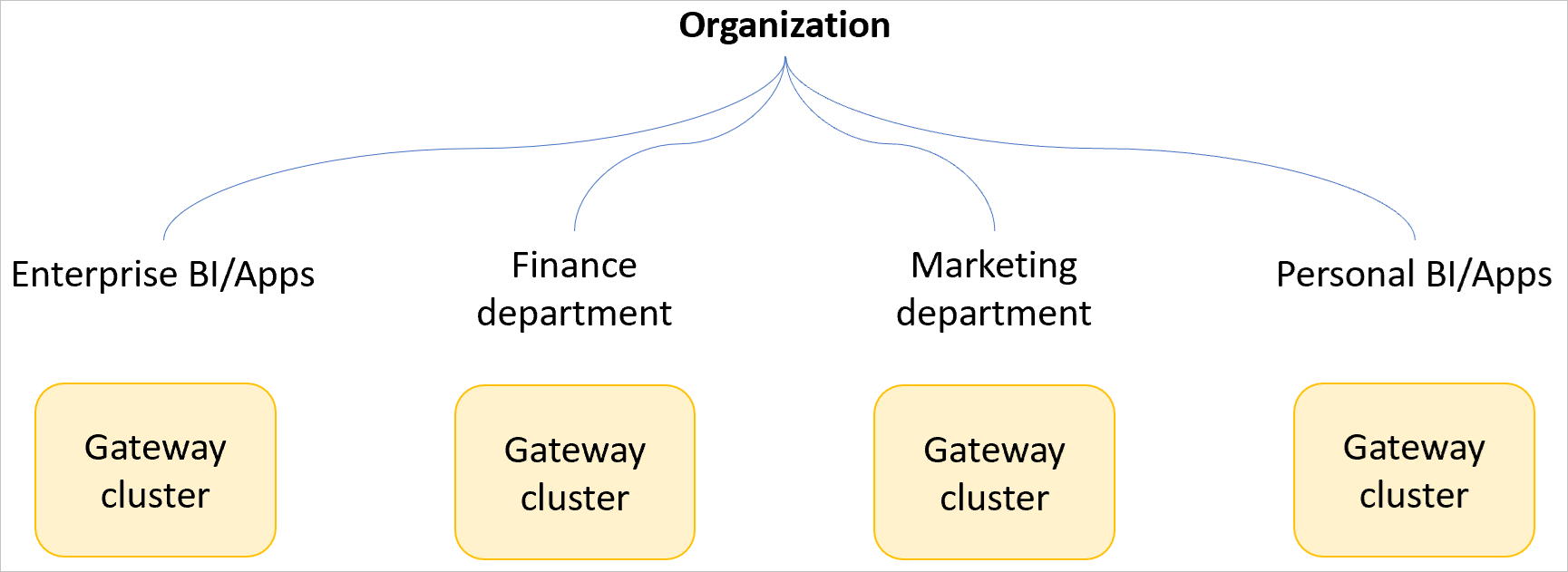
複数のゲートウェイ クラスターを使用する
組織内の多数のユーザーに対してゲートウェイ クラスターを作成する場合は、ビジネス ユニット以下に基づいて複数のゲートウェイ クラスターを作成して、潜在的なパフォーマンスへの影響を少数のユーザーに制限する必要があります。
会社全体に 1 つのビジネスクリティカルなゲートウェイ クラスターを使用することはお勧めしません (会社が小規模でない場合)。 単一のゲートウェイ クラスター シナリオでは、1 人のユーザーがクエリを送信して、ゲートウェイ全体のすべてのトラフィックに大きなパフォーマンスへの影響を与える可能性があります。 ゲートウェイが会社全体で使用されている場合、パフォーマンスへの影響が会社全体に影響する可能性があります。 また、ゲートウェイ クラスターが会社全体で使用されている場合、 ゲートウェイパフォーマンス監視 機能を使用するときにパフォーマンスの問題を引き起こしている可能性のあるクエリを特定することが困難になる可能性があります。
ゲートウェイの高可用性と負荷分散機能を使用する
ビジネス クリティカルなゲートウェイ クラスターには、 常にゲートウェイの高可用性と負荷分散機能を 使用します。
- 高可用性: 単一障害点を排除します。
- 負荷分散: クラスター内のすべてのゲートウェイ サーバーにワークロードを自動的に分散します。
何らかの理由でゲートウェイがオフラインになった場合に備え、ゲートウェイ クラスターごとに少なくとも 2 つのゲートウェイを設定します。 このセットアップにより、1 つのゲートウェイ障害によってゲートウェイ クラスター全体が失敗することはありません。 さらに、ゲートウェイで CPU、メモリ、コンカレンシーの制限を有効にして、ゲートウェイ クラスター全体に負荷を分散させることができます。
ゲートウェイ クラスターのスケーラビリティの計画と維持
推奨されるハードウェアとソフトウェアのガイドラインを使用してゲートウェイ クラスターを設定すると、クラスターが適切なパフォーマンスで実行されます。 ゲートウェイが適切にスケーリングされていないと、パフォーマンスが低下する可能性があります。 ゲートウェイ クラスターで優れたパフォーマンスを得るために考慮する必要がある要素は多数あります。
ゲートウェイ サーバーのハードウェア仕様を決定する
ゲートウェイ サーバーの仕様 (CPU、メモリ、ディスクなど) は重要な要素です。ほとんどの場合、Power Query 変換はゲートウェイ サーバー上のデータに適用されます。 そのため、ゲートウェイ サーバーには、すべてのデータ変換を処理するのに十分なリソース、メモリ、処理能力が必要です。
サーバー サイズを選択する必要がある場合は、メモリと CPU の 2 つのメトリックが最も重要です。 ゲートウェイで Power Query データ変換手順を処理するには、十分なメモリと CPU 能力の両方が必要です。 ゲートウェイ サーバーは、自分が持っている最高のワークロードを処理するのに十分な強力さであることが重要です。 ゲートウェイ サーバーがワークロードを処理できない場合、直接クエリまたはデータ更新は失敗します。 同時に実行されるクエリの数を理解することも重要です。
これらの異なるクエリ オプションは、ゲートウェイ サーバーに異なる影響を与えます。
| クエリの型 | 制限係数 |
|---|---|
| 輸入 | 記憶 |
| DirectQuery | CPU |
| LiveConnect(ライブコネクト) | CPU |
インポート中は、一連のデータ全体を照会して処理する必要があります。これはメモリ負荷の高いタスクです。 多くの場合、このインポートには時間がかかります。 DirectQueries と LiveConnections は、一般的に CPU 負荷が高いです。 ほとんどの場合、直接クエリは、データのごく一部のみを処理するために何度も実行されます。 データのごく一部のみが処理されるため、通常、これらの直接クエリはメモリ負荷の高いタスクではありません。 ただし、クエリはオンデマンドで何度も実行されるため、CPU 負荷が高くなる可能性があります。
ワークロードに応じて、メモリまたは CPU 用にゲートウェイ サーバーを最適化することを検討してください。
ゲートウェイ クラスターをスケーリングするタイミング
スケーリングは、ビジネスクリティカルなゲートウェイ クラスターの重要な側面です。 ゲートウェイ クラスターでの使用量が増えるにつれて、適切なパフォーマンスを確保するために、ゲートウェイ クラスターをスケールアップまたはスケールアウトする必要があります。 クラスター内のゲートウェイを以前にスケールアップしたことがある場合は、ゲートウェイ クラスターのスケールアウトを開始することをお勧めします。
クラスター内の個々のノード間でのトラフィック負荷のスケーリングと分散は、個々のシナリオによって異なる複雑なプロセスです。 すべてのゲートウェイ トラフィックが予測可能に処理されるようにするための明確なモデルはありませんが、次に示す制限はスケーリングの必要性を示しています。 一般に、スケールアップ (個々のノードの CPU、RAM、またはディスク領域の増加) には、スケールアウト (クラスターへのノードの追加) を優先的に行うことをお勧めします。 スケールアウトは、システム全体が余分なトラフィックを処理する能力において全体的に効果的になる傾向があります。 スケールアウトは、クラスターが処理できる合計帯域幅にもプラスの影響を与えますが、スケールアップは一般的には行いません。 1 つ以上のゲートウェイ ノードが次のしきい値に達したことを示す場合は、クラスターのスケールアウトを強く考慮する必要があります。
CPU: CPU は長期間にわたって 80% を超えますが、CPU の最大出力が異常ではない短い (5 分未満) スパイクが発生することがあります。
RAM: 利用可能なメモリが定期的に20%を下回っています。
ディスク: 空きディスク領域が 5 GB を下回る頻度で低下します。 この dip は、キャッシュまたはスプーリング ディレクトリをより戦略的に構成する必要があることを示す場合もあります。
コンカレンシー: 1 つのノードで 40 を超えるクエリを同時に実行します。
ゲートウェイ ノード間で分散される更新とクエリには大きく異なるプロファイルが存在する可能性があるため、実行時間の長いジョブやメモリを集中的に使用するジョブにも追加の調査を行うことをお勧めします。 このような場合のクエリの最適化は、個々のレポートや更新だけでなく、システム全体に対して、パフォーマンスとスケーラビリティに大きな影響を与える可能性があります。 問題の更新を 1 つの専用ゲートウェイ クラスターに分離してパフォーマンス特性を評価し、クエリ プランの診断、折りたたみインジケーター、およびその他のすべての公開されたパフォーマンスに関する推奨事項を使用して最適化を実行することをお勧めします。 この分離により、取得されるデータの量と、必要な後処理の量が最小限に抑えられます。 この分離は、組織全体の他の一般的な更新との競合を減らすために、実行時間の長い ETL ジョブを専用ゲートウェイ クラスターに分離するための長期的な戦略としても使用できます。
ゲートウェイ クラスターのスケールアップ
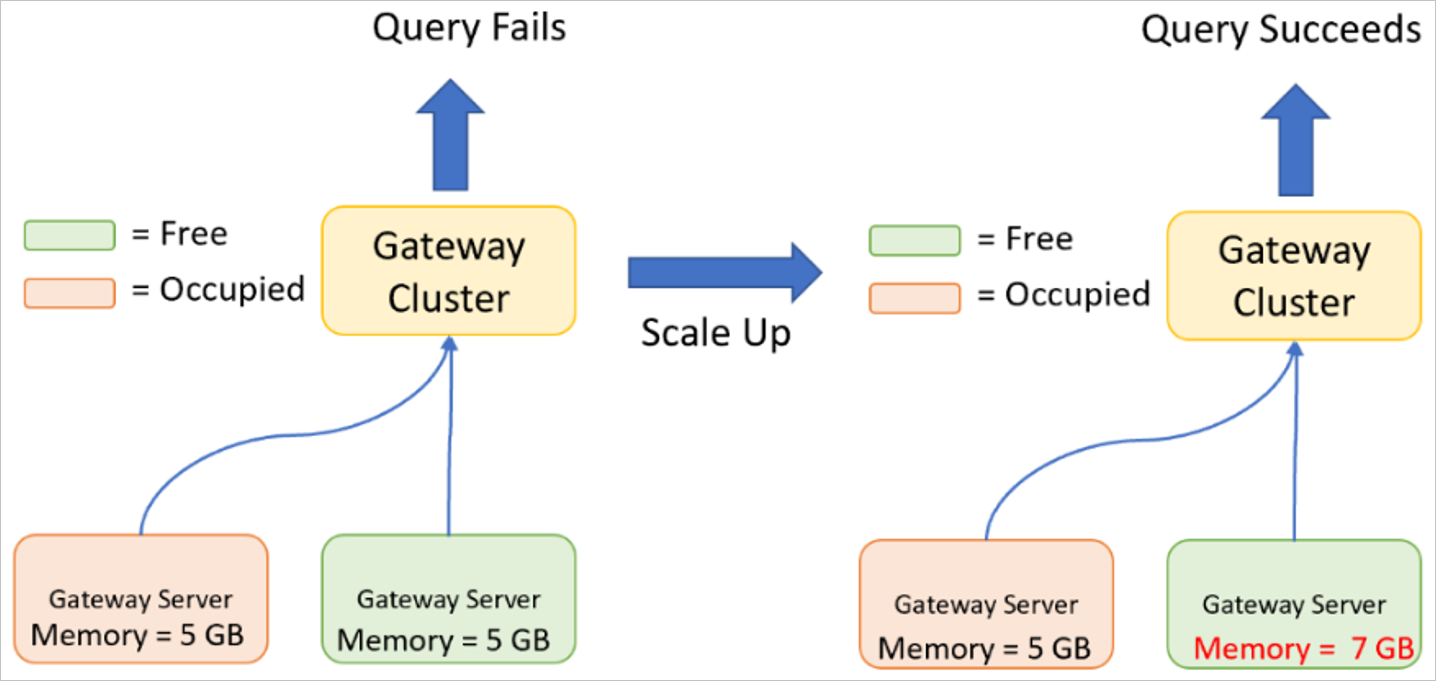
スケールアップは、ゲートウェイ サーバーの仕様 (CPU、メモリ、ディスクなど) を増やす場合です。
ゲートウェイが 1 つ以上のクエリを実行するときに最大 CPU またはメモリに達した場合は、スケールアップが必要になることがあります。 クエリは 1 つのゲートウェイ サーバーでのみ実行できます。そのため、ゲートウェイ サーバーには、クエリ全体と結果のデータを処理するための十分なリソースが必要です。
ゲートウェイ クラスターのスケールアウト
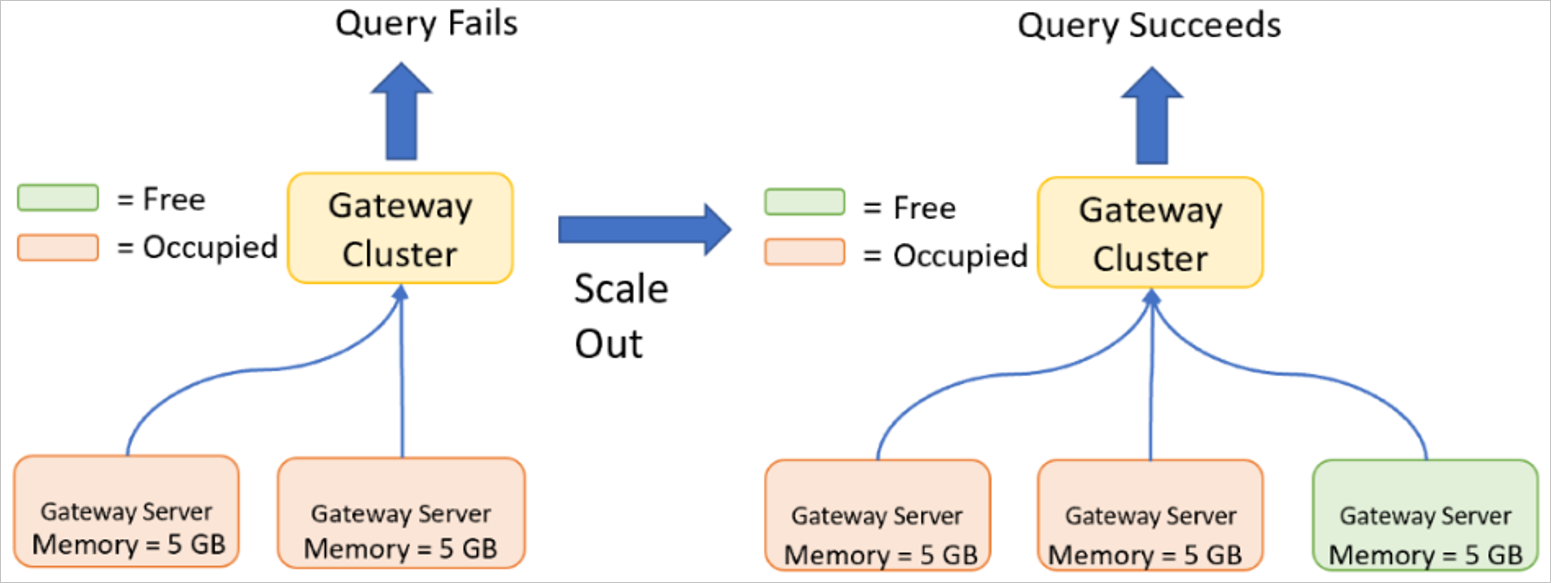
スケールアウトは、ゲートウェイ サーバーの仕様が既に高い場合 (つまり、ゲートウェイ サーバーが既にスケールアップされている)、または同時実行クエリの数が原因で単一のゲートウェイ サーバーが管理できる制限に達している場合に必要です。 ゲートウェイ メンバー セット全体にわたる広範な負荷の増加は、ノードを追加してクラスターをスケーリングすることが適切な措置であることを示しています。 ゲートウェイ クラスターをスケーリングするタイミングは、 スケーリングする時間を示す特定のしきい値を提供します。 スケールアウトの詳細については、「 ゲートウェイの高可用性と負荷分散機能を使用する」を参照してください。
新しいゲートウェイ クラスターを作成してスケーリングする
ゲートウェイ クラスターのリソース使用量が多い場合、または非常に多くのユーザーがゲートウェイ クラスターに依存している場合は、新しいゲートウェイ クラスターを作成できます。 その後、ワークロードのサブセットを新しいゲートウェイ クラスターに移行できます。 多数のユーザーが 1 つのゲートウェイ クラスターに依存している場合、ユーザーがクエリを送信してゲートウェイ クラスター全体のパフォーマンスに大きな影響を与える可能性が大幅に高くなります。
1 つのゲートウェイ クラスターに依存する非常に多くのユーザーは、新しいゲートウェイ クラスターを作成する必要があることを示しています。
ゲートウェイのパフォーマンスの監視とトラブルシューティング
ゲートウェイ パフォーマンス監視機能を使用して、ビジネス クリティカルなゲートウェイの全体的なパフォーマンスを 監視 することが重要です。 また、この機能を使用して、パフォーマンスの問題のトラブルシューティング、ボトルネックの特定、ゲートウェイの全体的なパフォーマンスに影響を与えるクエリの特定を行うこともできます。 この機能は、ゲートウェイ クラスターをスケーリングするタイミングを判断するのに役立つ重要なツールでもあります。
クエリがゲートウェイに大きな影響を与える結果、全体的なパフォーマンスが低下したと特定した場合は、クエリを書き直して効率を高め、パフォーマンスへの影響を最小限に抑えることができます。
Microsoft がゲートウェイまたはゲートウェイ関連のコンポーネント (過負荷の Power BI Premium 容量など) によって引き起こされるパフォーマンスの低下を特定した場合は、負荷のスケーリングまたは軽減によって、オーバーロードされたコンポーネントを修正する必要があります。 ゲートウェイまたはゲートウェイ関連のコンポーネントが過負荷になっている場合、パフォーマンスの低下は調査されません。