ヒント
このコンテンツは、Azure 用のクラウド ネイティブ .NET アプリケーションの設計に関する電子ブックからの抜粋であり、.NET Docs またはオフラインで読み取ることができる無料のダウンロード可能な PDF として入手できます。

アプリケーション内のコードのレイアウトを支援するパターンが開発されたのと同様に、信頼性の高い方法でアプリケーションを運用するためのパターンがあります。 アプリケーションを維持する上で便利な 3 つのパターンとして、 ログ記録、 監視、 アラートの 3 つが登場しました。
ログ記録を使用するタイミング
どんなに慎重であっても、アプリケーションは運用環境で予期しない動作をする場合がほとんどです。 ユーザーがアプリケーションに関する問題を報告する場合は、問題が発生したときにアプリで何が起こっていたかを確認できると便利です。 実行中にアプリケーションが何をしているかに関する情報をキャプチャする最も試行された真の方法の 1 つは、アプリケーションに実行内容を書き留めしてもらう方法です。 このプロセスはログ記録と呼ばれます。 運用環境で障害や問題が発生するたびに、非運用環境で障害が発生した条件を再現することが目標です。 適切なログ記録を行うと、テストと実験が可能な環境で問題を複製するために、開発者が従うロードマップが提供されます。
クラウドネイティブ アプリケーションでログを記録するときの課題
従来のアプリケーションでは、ログ ファイルは通常、ローカル コンピューターに格納されます。 実際、Unix に似たオペレーティング システムでは、ログを保持するように定義されたフォルダー構造があります(通常は /var/log)。
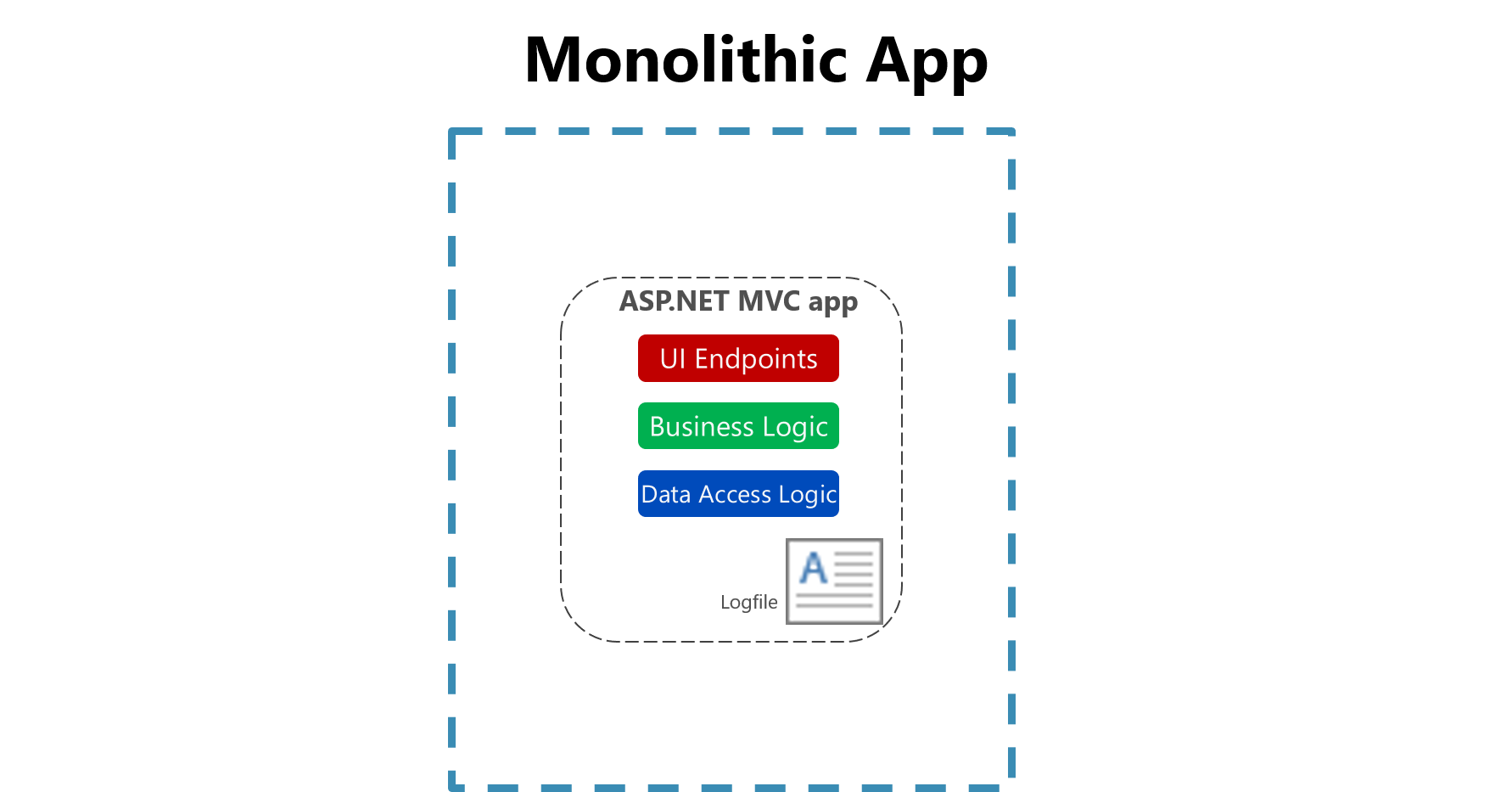 図 7-1。 モノリシック アプリでファイルにログを記録する。
図 7-1。 モノリシック アプリでファイルにログを記録する。
1 台のコンピューター上のフラット ファイルへのログ記録の有用性は、クラウド環境では大幅に削減されます。 ログを生成するアプリケーションがローカル ディスクにアクセスできない場合や、コンテナーが物理マシンの周囲でシャッフルされるため、ローカル ディスクが非常に一時的である可能性があります。 複数のノード間でモノリシック アプリケーションを簡単にスケールアップしても、適切なファイル ベースのログ ファイルを見つけるのが困難になる場合があります。
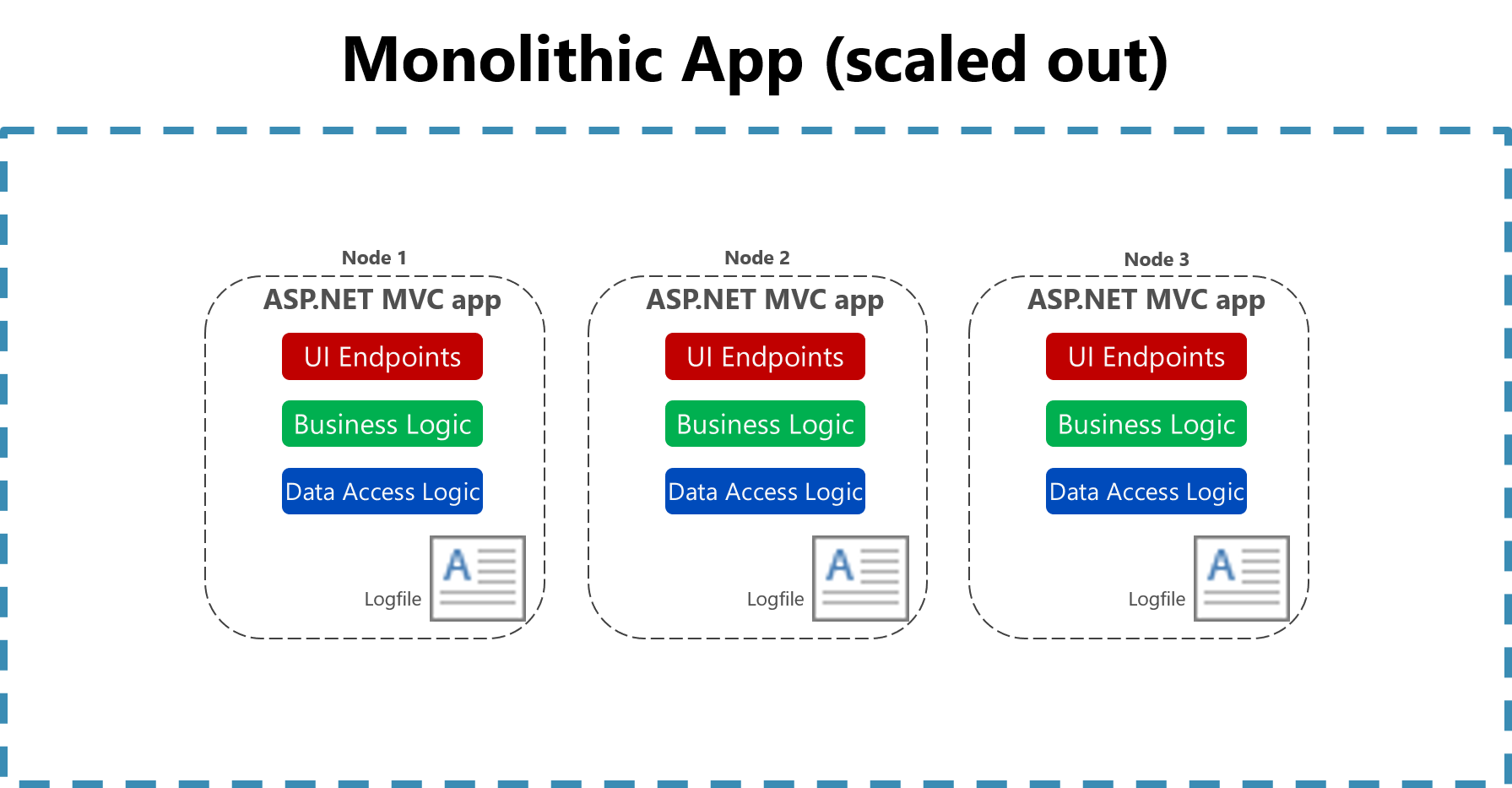 図 7-2 スケーリングされたモノリシック アプリでファイルにログを記録する。
図 7-2 スケーリングされたモノリシック アプリでファイルにログを記録する。
マイクロサービス アーキテクチャを使用して開発されたクラウドネイティブ アプリケーションは、ファイル ベースのロガーにもいくつかの課題があります。 ユーザー要求は、異なるマシンで実行される複数のサービスにまたがる場合があり、ローカル ファイル システムにまったくアクセスできないサーバーレス関数が含まれる場合があります。 これらの多くのサービスとマシン間でユーザーまたはセッションからのログを関連付けるのは非常に困難です。
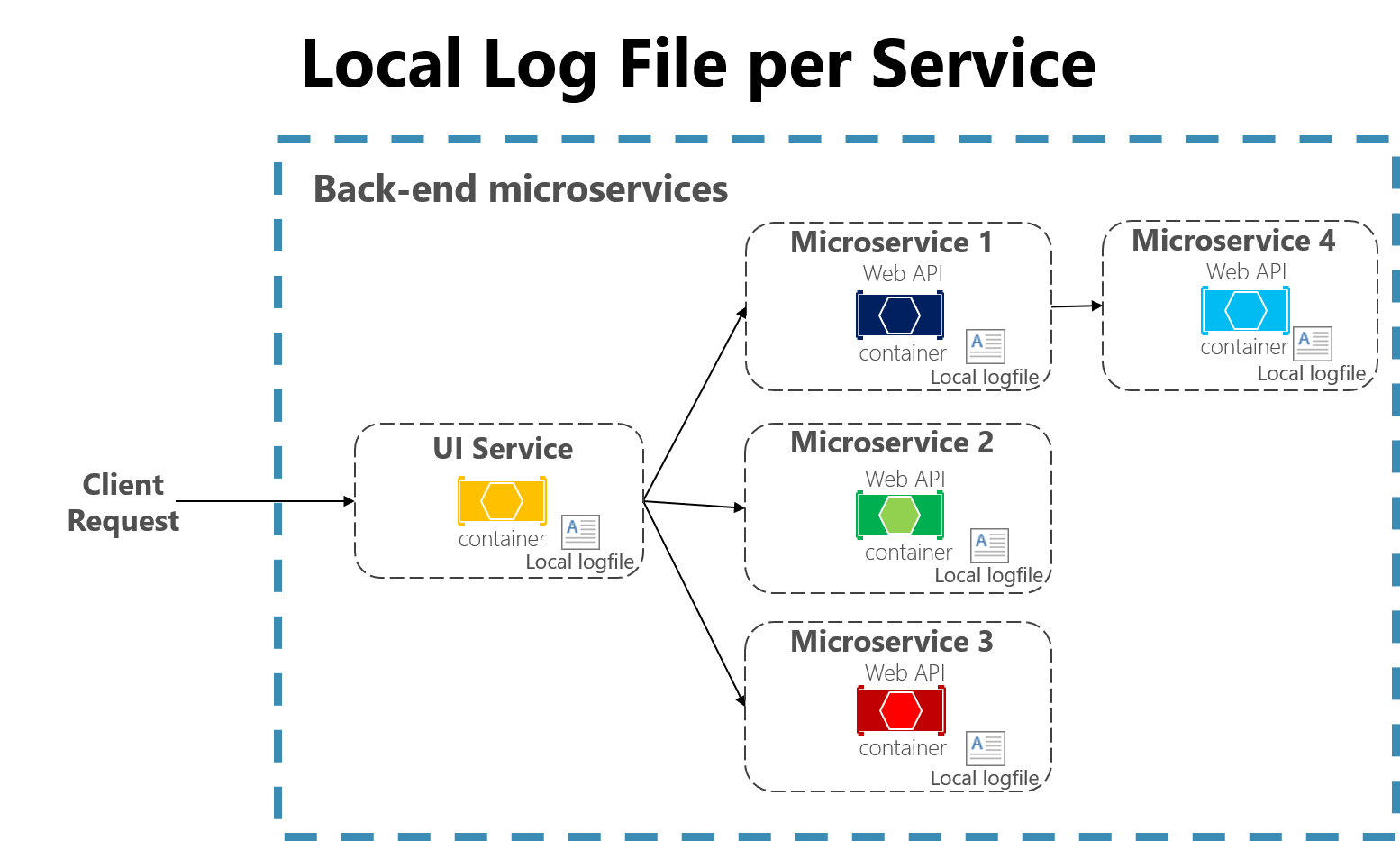 図 7-3 マイクロサービス アプリ内のローカル ファイルへのログ記録。
図 7-3 マイクロサービス アプリ内のローカル ファイルへのログ記録。
最後に、一部のクラウドネイティブ アプリケーションのユーザー数が多くなっています。 アプリケーションにログインすると、各ユーザーが 100 行のログ メッセージを生成するとします。 分離して管理できますが、100,000 人を超えるユーザーとログのボリュームが十分に大きくなり、ログの効果的な使用をサポートするために特殊なツールが必要になります。
クラウドネイティブ アプリケーションでのログ記録
すべてのプログラミング言語には、ログの書き込みを許可するツールがあり、通常、これらのログを書き込むためのオーバーヘッドは低くなります。 ログ ライブラリの多くは、実行時にチューニングできるさまざまな種類の重要度のログ記録を提供します。 たとえば、 Serilog ライブラリ は、次のログ レベルを提供する .NET 用の一般的な構造化ログ ライブラリです。
- 詳細
- デバッグ
- 情報
- Warnung
- エラー
- 致死
これらの異なるログ レベルにより、ログ記録の粒度が提供されます。 運用環境でアプリケーションが正常に機能している場合は、重要なメッセージのみをログに記録するように構成できます。 アプリケーションの動作が間違っている場合は、ログ レベルを上げて、より詳細なログを収集できます。 これにより、パフォーマンスとデバッグの容易さのバランスが取られます。
ログ ツールのパフォーマンスが高く、詳細度のチューニング性が高いため、開発者は頻繁にログを記録することをお勧めします。 多くは、各メソッドの入退出をログに記録するパターンを好みます。 この方法は過剰に聞こえるかもしれませんが、開発者がログ記録を減らすことを望む頻度は低くなります。 実際、問題のある方法に関するログ記録を追加するためだけにデプロイを実行することは珍しくありません。 ログは多すぎてもいけませんが、少なすぎるよりはましです。 一部のツールは、この種のログ記録を自動的に提供するために使用できます。
クラウド ネイティブ アプリでのファイル ベースのログの使用に関連する課題があるため、一元化されたログをお勧めします。 ログはアプリケーションによって収集され、ログのインデックス作成と格納を行う中央ログ アプリケーションに配布されます。 このクラスのシステムでは、毎日数十ギガバイトのログを取り込むことができます。
また、多くのサービスにまたがるログ記録を構築するときに、いくつかの標準的なプラクティスに従うと便利です。 たとえば、長い対話の開始時に関連付け ID を生成し、その相互作用に関連する各メッセージに記録すると、関連するすべてのメッセージを簡単に検索できます。 関連付け ID を抽出して関連するすべてのメッセージを見つけるには、1 つのメッセージを検索するだけで済みます。 もう 1 つの例は、使用する言語やログ ライブラリに関係なく、すべてのサービスでログ形式が同じであることを確認することです。 この標準化により、ログの読み取りがはるかに簡単になります。 図 7-4 は、マイクロサービス アーキテクチャがワークフローの一部として集中ログを活用する方法を示しています。
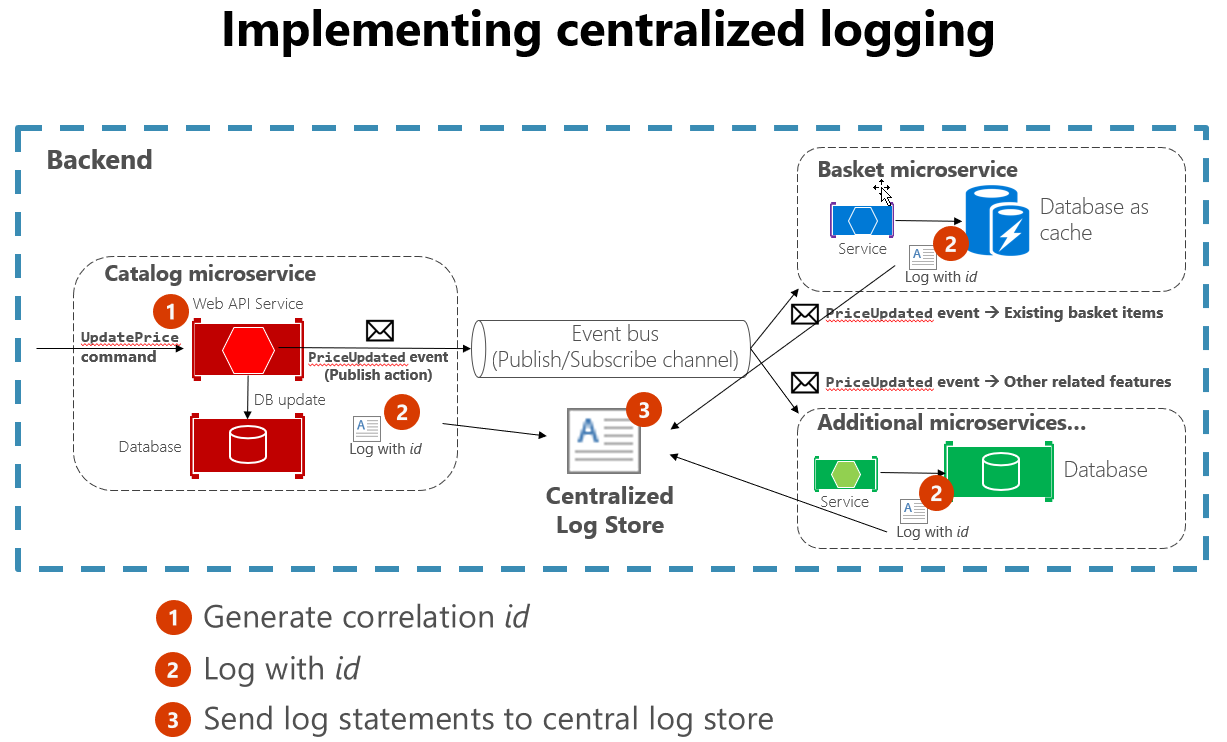 図 7-4 さまざまなソースからのログは、一元化されたログ ストアに取り込まれます。
図 7-4 さまざまなソースからのログは、一元化されたログ ストアに取り込まれます。
アプリの正常性に関する潜在的な問題の検出と対応に関する課題
一部のアプリケーションはミッション クリティカルではありません。 おそらく、これらは内部でのみ使用され、問題が発生した場合、ユーザーは担当チームに連絡でき、アプリケーションを再起動できます。 ただし、多くの場合、お客様は、使用するアプリケーションに対してより高い期待を持っています。 ユーザーが通知する前またはユーザーから通知される 前に 、アプリケーションで問題が発生したタイミングを把握しておく必要があります。 それ以外の場合、問題に気づく最初のきっかけは、アプリケーションや組織を批判する怒りのソーシャルメディア投稿が次々とされることかもしれません。
考慮する必要があるシナリオには、次のようなものがあります。
- アプリケーション内の 1 つのサービスが失敗して再起動し続け、断続的に応答が遅くなります。
- 1 日のある時点で、アプリケーションの応答時間が遅くなります。
- 最近のデプロイ後、データベースの負荷が 3 倍になりました。
監視を適切に実装すると、問題につながる条件を知らせることができ、ユーザーに大きな影響を与える前に基になる条件に対処できます。
クラウドネイティブ アプリの監視
一部の集中ログ システムでは、純粋なログの外部でテレメトリを収集する追加の役割を担います。 データベース クエリの実行時間、Web サーバーからの平均応答時間、オペレーティング システムによって報告された CPU 負荷の平均やメモリ負荷などのメトリックを収集できます。 これらのシステムは、ログと組み合わせて、システムとアプリケーション全体のノードの正常性の全体像を提供できます。
監視ツールのメトリック収集機能は、アプリケーション内から手動で供給することもできます。 新規ユーザーのサインアップや注文など、特に関心のあるビジネス フローは、中央監視システムでカウンターをインクリメントするようにインストルメント化される場合があります。 この側面により、監視ツールのロックが解除され、アプリケーションの正常性だけでなく、ビジネスの正常性も監視されます。
クエリは、ログ集計ツールで作成して、特定の統計またはパターンを検索し、それをグラフィカルな形式でカスタム ダッシュボードに表示できます。 多くの場合、チームは、アプリケーションに関連する統計情報をローテーションする、壁に取り付けられた大型ディスプレイに投資します。 この方法では、問題が発生した時点で簡単に確認できます。
クラウドネイティブの監視ツールは、単一プロセスモノリシック アプリケーションか分散マイクロサービス アーキテクチャかに関係なく、アプリに対するリアルタイムのテレメトリと分析情報を提供します。 これには、アプリからのデータの収集を可能にするツールや、アプリの正常性に関する情報を照会および表示するためのツールが含まれています。
クラウドネイティブ アプリでの重大な問題への対応に関する課題
アプリケーションの問題に対応する必要がある場合は、適切な担当者に警告する何らかの方法が必要です。 これは 3 番目のクラウドネイティブ アプリケーション監視パターンであり、ログ記録と監視に依存します。 問題の診断を可能にし、場合によっては監視ツールにフィードするために、アプリケーションにログが記録されている必要があります。 アプリケーション メトリックと正常性データを 1 か所で集計するには、監視が必要です。 これが確立されると、特定のメトリックが許容レベル外になったときにアラートをトリガーするルールを作成できます。
一般に、アラートは監視の上に重ねられているので、特定の条件によって適切なアラートがトリガーされ、チーム メンバーに緊急の問題が通知されます。 アラートが必要になるシナリオには、次のようなものがあります。
- アプリケーションのサービスの 1 つが、ダウンタイムの 1 分後に応答しない。
- アプリケーションから、1% を超える要求に失敗した HTTP 応答が返されます。
- キー エンドポイントに対するアプリケーションの平均応答時間が 2000 ミリ秒を超えています。
クラウドネイティブ アプリのアラート
監視ツールに対するクエリを作成して、既知の障害状態を探すことができます。 たとえば、クエリは受信ログを検索して、Web サーバー上の問題を示す HTTP 状態コード 500 を示すことができます。 これらのいずれかが検出されるとすぐに、調査を開始できる元のサービスの所有者に電子メールまたは SMS が送信される可能性があります。
ただし、通常、1 つの 500 エラーでは、問題が発生したことを判断するには不十分です。 これは、ユーザーが自分のパスワードを誤って入力したか、形式が正しくないデータを入力したことを意味する可能性があります。 アラート クエリは、平均 500 件を超えるエラーが検出された場合にのみ発生するように作成できます。
アラートの最も有害なパターンの 1 つは、人間が調査するには多すぎるアラートを発生させる方法です。 サービス所有者は、以前に調査し、無害であることが判明したエラーに急速に気が付かなくなります。 その後本物のエラーが発生しても、何百もの偽陽性のノイズに紛れてしまいます。 オオカミを泣かした少年のたとえは、この非常に危険を警告するように子供たちに頻繁に言われます。 発生するアラートが実際の問題を示していることを確認することが重要です。
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET