事前トレーニング済みの TensorFlow モデルを使用して画像処理用に画像を分類する分類モデルをトレーニングする方法について説明します。
TensorFlow モデルは、画像を 1000 のカテゴリに分類するようにトレーニングされました。 TensorFlow モデルは画像内のパターンを認識する方法を認識するため、ML.NET モデルはその一部をパイプラインで使用して、生の画像を特徴または入力に変換して分類モデルをトレーニングできます。
このチュートリアルでは、次の方法について説明します。
- 問題を理解する
- 事前トレーニング済みの TensorFlow モデルを ML.NET パイプラインに組み込む
- ML.NET モデルをトレーニングして評価する
- テスト 画像を分類する
このチュートリアルのソース コードは、dotnet/samples リポジトリにあります。 既定では、このチュートリアルの .NET プロジェクト構成は .NET Core 2.2 を対象とします。
前提 条件
適切な機械学習タスクを選択する
ディープ ラーニング
ディープ ラーニング は機械学習のサブセットであり、コンピューター ビジョンや音声認識などの領域に革命を起こしています。
ディープ ラーニング モデルは、多数の
- コンピューター ビジョンなどの一部のタスクでパフォーマンスが向上します。
- 膨大な量のトレーニング データが必要です。
画像分類は、画像を次のようなカテゴリに自動的に分類できる特定の分類タスクです。
- 画像内の人間の顔を検出するかどうか。
- 猫と犬の検出。
または、次の画像と同様に、画像が食品、おもちゃ、またはアプライアンスであるかどうかを判断します。



手記
上記の画像はウィキメディア・コモンズに属しており、以下の属性があります。
- "220px-Pepperoni_pizza.jpg" パブリック ドメイン, https://commons.wikimedia.org/w/index.php?curid=79505,
- "119px-Nalle_-_a_small_brown_teddy_bear.jpg" By Jonik - 自己撮影、CC BY-SA 2.0、 https://commons.wikimedia.org/w/index.php?curid=48166。
- "193px-Broodrooster.jpg" by M.Minderhoud - 自作, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=27403
画像分類 モデルをゼロからトレーニングするには、何百万ものパラメーター、ラベル付けされたトレーニング データのトン、膨大な量のコンピューティング リソース (数百 GPU 時間) を設定する必要があります。 カスタム モデルをゼロからトレーニングするほど効果的ではありませんが、事前トレーニング済みモデルを使用すると、何千ものイメージと何百万ものラベル付けされたイメージを操作してこのプロセスをショートカットし、カスタマイズされたモデルを (GPU のないマシンで 1 時間以内に) かなり迅速に構築できます。 このチュートリアルでは、12 個のトレーニング画像のみを使用して、そのプロセスをさらに縮小します。
Inception model は画像を 1000 のカテゴリに分類するようにトレーニングされていますが、このチュートリアルでは、画像をより小さなカテゴリ セットに分類し、それらのカテゴリのみに分類する必要があります。
Inception modelの機能を使用して、画像を認識し、カスタム画像分類子の新しい制限付きカテゴリに分類できます。
- 食べ物
- 玩具
- 器具
このチュートリアルでは、TensorFlow の開始 ディープ ラーニング モデルを使用します。これは、ImageNet データセットでトレーニングされた一般的な画像認識モデルです。 TensorFlow モデルは、画像全体を 1,000 個のクラス ("Umbrella"、"Jersey"、"Dishwasher" など) に分類します。
Inception model は既に何千もの異なる画像に事前トレーニングされているため、内部的には、画像識別に必要な 画像機能 含まれています。 モデルでこれらの内部イメージ機能を使用して、クラスがはるかに少ない新しいモデルをトレーニングできます。
次の図に示すように、.NET または .NET Framework アプリケーションの ML.NET NuGet パッケージへの参照を追加します。 ML.NET では、内部で、既存のトレーニング済みの TensorFlow モデル ファイルを読み込むコードを記述するためのネイティブ TensorFlow ライブラリを含み、参照しています。
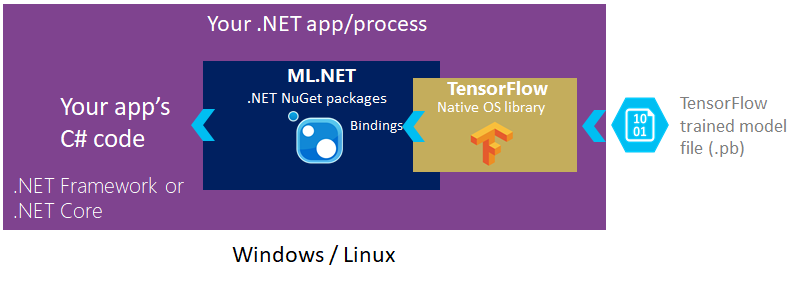
多クラス分類
TensorFlow 開始モデルを使用して、従来の機械学習アルゴリズムの入力として適した特徴を抽出した後、ML.NET 多クラス分類子を追加します。
この場合に使用される特定のトレーナーは、多項式ロジスティック回帰アルゴリズム
このトレーナーによって実装されたアルゴリズムは、画像データで動作するディープ ラーニング モデルの場合、多数の機能に関する問題に対して適切に機能します。
詳細については、「ディープ ラーニングと機械学習の
データ
.tsv ファイルとイメージ ファイルの 2 つのデータ ソースがあります。
tags.tsv ファイルには、2 つの列が含まれています。最初の列は ImagePath として定義され、2 つ目はイメージに対応する Label です。 次のサンプル ファイルにはヘッダー行がないため、次のようになります。
broccoli.jpg food
pizza.jpg food
pizza2.jpg food
teddy2.jpg toy
teddy3.jpg toy
teddy4.jpg toy
toaster.jpg appliance
toaster2.png appliance
トレーニングとテストのイメージは、zip ファイルでダウンロードするアセット フォルダーにあります。 これらの画像はウィキメディア・コモンズに属しています。
ウィキメディア・コモンズ・は、無料のメディアリポジトリです。 取得日: 2018 年 10 月 17 日 10:48 from: https://commons.wikimedia.org/wiki/Pizzahttps://commons.wikimedia.org/wiki/Toasterhttps://commons.wikimedia.org/wiki/Teddy_bear
セットアップ
プロジェクトを作成する
"TransferLearningTF" と呼ばれる C# コンソール アプリケーション を作成します。 次 ボタンをクリックします。
使用するフレームワークとして .NET 8 を選択します。 [作成] ボタンをクリックします。
Microsoft.ML NuGet パッケージをインストールします。
手記
このサンプルでは、特に明記されていない限り、記載されている最新の安定バージョンの NuGet パッケージを使用します。
- ソリューション エクスプローラーでプロジェクトを右クリックし、[NuGet パッケージの管理]
選択します。 - パッケージ ソースとして [nuget.org] を選択し、[参照] タブを選択し、Microsoft.MLを検索します。
- [インストール] ボタンを選択します。
- [変更のプレビュー] ダイアログで [OK] ボタンを選択します。
- 一覧に記載されているパッケージのライセンス条項に同意する場合は、[
ライセンス同意 ] ダイアログの [ 同意する] ボタンを選択します。 - Microsoft.ML.ImageAnalytics、SciSharp.TensorFlow.Redist、および Microsoft.ML.TensorFlowに対して手順を繰り返します。
- ソリューション エクスプローラーでプロジェクトを右クリックし、[NuGet パッケージの管理]
アセットをダウンロードする
プロジェクトアセットディレクトリのzipファイルダウンロードし、解凍します。
assetsディレクトリを TransferLearningTF プロジェクト ディレクトリにコピーします。 このディレクトリとそのサブディレクトリには、このチュートリアルに必要なデータとサポート ファイル (ダウンロードして次の手順で追加する開始モデルを除く) が含まれています。の開始モデルをダウンロードし、解凍します。
解凍した
inception5hディレクトリの内容を TransferLearningTF プロジェクトassets/inceptionディレクトリにコピーします。 このディレクトリには、次の図に示すように、このチュートリアルに必要なモデルと追加のサポート ファイルが含まれています。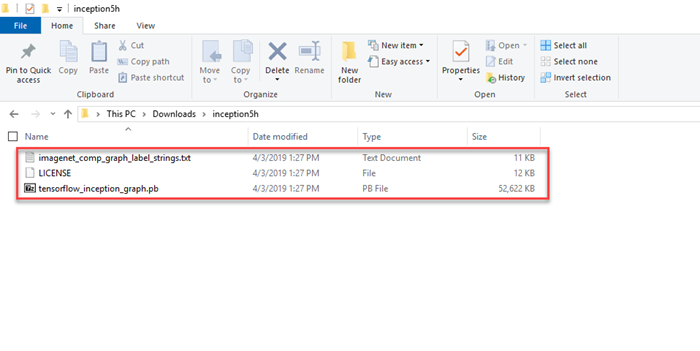
ソリューション エクスプローラーで、資産ディレクトリとサブディレクトリ内の各ファイルを右クリックし、[プロパティ]
選択します。 [詳細設定] で、[出力ディレクトリにコピー] の値を [新しい場合はコピーする] に変更します。
クラスの作成とパスの定義
usingファイルの先頭に、次の追加の ディレクティブを追加します。using Microsoft.ML; using Microsoft.ML.Data;アセット パスを指定するには、
usingディレクティブのすぐ下の行に次のコードを追加します。string _assetsPath = Path.Combine(Environment.CurrentDirectory, "assets"); string _imagesFolder = Path.Combine(_assetsPath, "images"); string _trainTagsTsv = Path.Combine(_imagesFolder, "tags.tsv"); string _testTagsTsv = Path.Combine(_imagesFolder, "test-tags.tsv"); string _predictSingleImage = Path.Combine(_imagesFolder, "toaster3.jpg"); string _inceptionTensorFlowModel = Path.Combine(_assetsPath, "inception", "tensorflow_inception_graph.pb");入力データと予測のクラスを作成します。
public class ImageData { [LoadColumn(0)] public string? ImagePath; [LoadColumn(1)] public string? Label; }ImageDataは入力イメージ データ クラスであり、次の String フィールドがあります。-
ImagePathイメージ ファイル名が含まれています。 -
Labelにはイメージラベルの値が含まれています。
-
ImagePredictionの新しいクラスをプロジェクトに追加します。public class ImagePrediction : ImageData { public float[]? Score; public string? PredictedLabelValue; }ImagePredictionは画像予測クラスであり、次のフィールドがあります。-
Scoreには、特定の画像分類の信頼度の割合が含まれます。 -
PredictedLabelValueには、予測画像分類ラベルの値が含まれています。
ImagePredictionは、モデルのトレーニング後に予測に使用されるクラスです。 イメージパスにはstring(ImagePath) が含まれています。Labelは、モデルの再利用とトレーニングに使用されます。PredictedLabelValueは、予測と評価中に使用されます。 評価には、トレーニング データ、予測値、およびモデルを含む入力が使用されます。-
変数を初期化する
mlContextの新しいインスタンスを使用して、MLContext変数を初期化します。Console.WriteLine("Hello World!")行を次のコードに置き換えます。MLContext mlContext = new MLContext();MLContext クラスは、すべての ML.NET 操作の開始点であり、
mlContextを初期化すると、モデル作成ワークフロー オブジェクト間で共有できる新しい ML.NET 環境が作成されます。 概念的には、Entity Framework でのDBContextに似ています。
開始モデル パラメーターの構造体を作成する
開始モデルには、渡す必要があるいくつかのパラメーターがあります。
mlContext変数を初期化した直後に、次のコードを使用してパラメーター値をフレンドリ名にマップする構造体を作成します。struct InceptionSettings { public const int ImageHeight = 224; public const int ImageWidth = 224; public const float Mean = 117; public const float Scale = 1; public const bool ChannelsLast = true; }
表示ユーティリティ メソッドを作成する
画像データと関連する予測を複数回表示するため、画像と予測結果の表示を処理する表示ユーティリティ メソッドを作成します。
次のコードを使用して、
DisplayResults()構造体の直後にInceptionSettingsメソッドを作成します。void DisplayResults(IEnumerable<ImagePrediction> imagePredictionData) { }DisplayResultsメソッドの本文を入力します。foreach (ImagePrediction prediction in imagePredictionData) { Console.WriteLine($"Image: {Path.GetFileName(prediction.ImagePath)} predicted as: {prediction.PredictedLabelValue} with score: {prediction.Score?.Max()} "); }
予測を行うメソッドを作成する
次のコードを使用して、
ClassifySingleImage()メソッドの直前にDisplayResults()メソッドを作成します。void ClassifySingleImage(MLContext mlContext, ITransformer model) { }1 つの
ImageDataの完全修飾パスと画像ファイル名を含むImagePathオブジェクトを作成します。ClassifySingleImage()メソッドの次の行として、次のコードを追加します。var imageData = new ImageData() { ImagePath = _predictSingleImage };ClassifySingleImageメソッドの次の行として次のコードを追加して、1 つの予測を行います。// Make prediction function (input = ImageData, output = ImagePrediction) var predictor = mlContext.Model.CreatePredictionEngine<ImageData, ImagePrediction>(model); var prediction = predictor.Predict(imageData);予測を取得するには、Predict() メソッドを使用します。 PredictionEngine は便利な API であり、データの 1 つのインスタンスに対して予測を実行できます。
PredictionEngineはスレッド セーフではありません。 シングルスレッド環境またはプロトタイプ環境で使用することは許容されます。 運用環境でのパフォーマンスとスレッド セーフを向上させるには、アプリケーション全体で使用するPredictionEnginePoolオブジェクトのObjectPoolを作成するPredictionEngineサービスを使用します。 ASP.NET Core Web API でPredictionEnginePoolを使用する方法については、こちらのガイドを参照してください。手記
PredictionEnginePoolサービス拡張機能は現在プレビュー段階です。ClassifySingleImage()メソッドの次のコード行として予測結果を表示します。Console.WriteLine($"Image: {Path.GetFileName(imageData.ImagePath)} predicted as: {prediction.PredictedLabelValue} with score: {prediction.Score?.Max()} ");
ML.NET モデル パイプラインを構築する
ML.NET モデル パイプラインは、推定器のチェーンです。 パイプラインの構築中に実行は行われません。 推定オブジェクトは作成されますが、実行されません。
モデルを生成するメソッドを追加する
この方法は、チュートリアルの中心です。 モデルのパイプラインを作成し、ML.NET モデルを生成するようにパイプラインをトレーニングします。 また、以前に見えないテスト データに対してモデルを評価します。
次のコードを使用して、
GenerateModel()構造体の直後とInceptionSettingsメソッドの直前に、DisplayResults()メソッドを作成します。ITransformer GenerateModel(MLContext mlContext) { }推定器を追加して、画像データからピクセルを読み込み、サイズ変更し、抽出します。
IEstimator<ITransformer> pipeline = mlContext.Transforms.LoadImages(outputColumnName: "input", imageFolder: _imagesFolder, inputColumnName: nameof(ImageData.ImagePath)) // The image transforms transform the images into the model's expected format. .Append(mlContext.Transforms.ResizeImages(outputColumnName: "input", imageWidth: InceptionSettings.ImageWidth, imageHeight: InceptionSettings.ImageHeight, inputColumnName: "input")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "input", interleavePixelColors: InceptionSettings.ChannelsLast, offsetImage: InceptionSettings.Mean))イメージ データは、TensorFlow モデルで想定される形式に処理する必要があります。 この場合、イメージはメモリに読み込まれ、一貫したサイズにサイズ変更され、ピクセルは数値ベクトルに抽出されます。
TensorFlow モデルを読み込むエスティメーターを追加し、スコア付けします。
Important
信頼できるソースからのみモデルを読み込みます。 信頼されていないソースからモデルを読み込むと、セキュリティ上のリスクがあります。
.Append(mlContext.Model.LoadTensorFlowModel(_inceptionTensorFlowModel). ScoreTensorFlowModel(outputColumnNames: new[] { "softmax2_pre_activation" }, inputColumnNames: new[] { "input" }, addBatchDimensionInput: true))パイプラインのこのステージでは、TensorFlow モデルをメモリに読み込み、TensorFlow モデル ネットワークを介してピクセル値のベクトルを処理します。 ディープ ラーニング モデルへの入力の適用と、モデルを使用した出力の生成は、スコアリングと呼ばれます。 モデル全体を使用すると、スコアリングによって推論または予測が行われます。
この場合は、最後のレイヤー (推論を行うレイヤー) を除くすべての TensorFlow モデルを使用します。 最後から 2 番目のレイヤーの出力には、
softmax_2_preactivationラベルが付けられます。 このレイヤーの出力は、実質的に元の入力画像を特徴付けする特徴のベクトルです。TensorFlow モデルによって生成されたこの特徴ベクトルは、ML.NET トレーニング アルゴリズムへの入力として使用されます。
推定器を追加して、トレーニング データ内の文字列ラベルを整数値にマップします。
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "LabelKey", inputColumnName: "Label"))次に追加される ML.NET トレーナーは、ラベルが任意の文字列ではなく
key形式である必要があります。 キーは、文字列値に 1 対 1 のマッピングを持つ数値です。ML.NET トレーニング アルゴリズムを追加します。
.Append(mlContext.MulticlassClassification.Trainers.LbfgsMaximumEntropy(labelColumnName: "LabelKey", featureColumnName: "softmax2_pre_activation"))予測されたキー値を文字列にマップする推定器を追加します。
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabelValue", "PredictedLabel")) .AppendCacheCheckpoint(mlContext);
モデルをトレーニングする
LoadFromTextFile ラッパーを使用してトレーニング データを読み込みます。
GenerateModel()メソッドの次の行として、次のコードを追加します。IDataView trainingData = mlContext.Data.LoadFromTextFile<ImageData>(path: _trainTagsTsv, hasHeader: false);ML.NET 内のデータは、IDataView インターフェイスとして表されます。
IDataViewは、表形式データ (数値とテキスト) を柔軟かつ効率的に記述する方法です。 データは、テキスト ファイルから、またはリアルタイムで (SQL データベースやログ ファイルなど)、IDataViewオブジェクトに読み込むことができます。上記のデータを読み込んだ状態でモデルをトレーニングします。
ITransformer model = pipeline.Fit(trainingData);Fit()メソッドは、トレーニング データセットをパイプラインに適用してモデルをトレーニングします。
モデルの精度を評価する
GenerateModelメソッドの次の行に次のコードを追加して、テスト データを読み込んで変換します。IDataView testData = mlContext.Data.LoadFromTextFile<ImageData>(path: _testTagsTsv, hasHeader: false); IDataView predictions = model.Transform(testData); // Create an IEnumerable for the predictions for displaying results IEnumerable<ImagePrediction> imagePredictionData = mlContext.Data.CreateEnumerable<ImagePrediction>(predictions, true); DisplayResults(imagePredictionData);モデルの評価に使用できるサンプル 画像がいくつかあります。 トレーニング データと同様に、モデルで変換できるように、これらのデータを
IDataViewに読み込む必要があります。モデルを評価するために、
GenerateModel()メソッドに次のコードを追加します。MulticlassClassificationMetrics metrics = mlContext.MulticlassClassification.Evaluate(predictions, labelColumnName: "LabelKey", predictedLabelColumnName: "PredictedLabel");予測を設定したら、Evaluate() メソッドを使用します。
- モデルを評価します (予測値とテスト データセットの
labelsを比較します)。 - モデルのパフォーマンス メトリックを返します。
- モデルを評価します (予測値とテスト データセットの
モデルの精度メトリックを表示する
次のコードを使用して、メトリックを表示し、結果を共有し、それらに対処します。
Console.WriteLine($"LogLoss is: {metrics.LogLoss}"); Console.WriteLine($"PerClassLogLoss is: {String.Join(" , ", metrics.PerClassLogLoss.Select(c => c.ToString()))}");画像分類では、次のメトリックが評価されます。
-
Log-loss- 「対数損失」を参照してください。 ログ損失を可能な限りゼロに近づけます。 -
Per class Log-loss。 クラスごとのログ損失を可能な限り 0 に近づけるようにします。
-
トレーニング済みのモデルを次の行として返す次のコードを追加します。
return model;
アプリケーションを実行する
GenerateModelクラスの作成後に、MLContext への呼び出しを追加します。ITransformer model = GenerateModel(mlContext);ClassifySingleImage()メソッドの呼び出しの後に、GenerateModel()メソッドへの呼び出しを追加します。ClassifySingleImage(mlContext, model);コンソール アプリを実行します (Ctrl + F5)。 結果は次の出力のようになります。 (警告が表示されたり、メッセージが処理されたりすることがありますが、わかりやすくするために、これらのメッセージは次の結果から削除されています)。
=============== Training classification model =============== Image: broccoli2.jpg predicted as: food with score: 0.8955513 Image: pizza3.jpg predicted as: food with score: 0.9667718 Image: teddy6.jpg predicted as: toy with score: 0.9797683 =============== Classification metrics =============== LogLoss is: 0.0653774699265059 PerClassLogLoss is: 0.110315812569315 , 0.0204391272836966 , 0 =============== Making single image classification =============== Image: toaster3.jpg predicted as: appliance with score: 0.9646884
おめでとうございます! これで、画像処理に事前トレーニング済みの TensorFlow を使用して画像を分類するための分類モデルを ML.NET に正常に構築できました。
このチュートリアルのソース コードは、dotnet/samples リポジトリにあります。
このチュートリアルでは、次の方法を学習しました。
- 問題を理解する
- 事前トレーニング済みの TensorFlow モデルを ML.NET パイプラインに組み込む
- ML.NET モデルをトレーニングして評価する
- テスト 画像を分類する
拡張された画像分類サンプルを調べるには、Machine Learning サンプルの GitHub リポジトリをご覧ください。
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET