ML.NET CLI を使用して ML.NET モデルと基礎となる C# コードを自動生成する方法について説明します。 データセットと実装する機械学習タスクを指定すると、CLI では、AutoML エンジンを使用してモデルの生成と展開のソース コードと、分類モデルが作成されます。
このチュートリアルでは、次の手順を実行します。
- 選択した機械学習タスク用にデータを準備する
- CLI から "mlnet classification" コマンドを実行する
- 品質メトリックの結果を確認する
- アプリケーションでモデルを使用するために生成された C# コードを理解する
- モデルのトレーニングに使用された生成済み C# コードを調べる
注意
このトピックは、現在プレビュー段階の ML.NET CLI ツールについて述べており、内容が変更される場合があります。 詳細については、ML.NET に関するページを参照してください。
ML.NET CLI は ML.NET の一部であり、その主な目的は、ML.NET を学習する .NET 開発者のために ML.NET を "民主化" することなので、始めるときにゼロからコードを書く必要はありません。
ML.NET CLI は任意のコマンドプロンプト (Windows、Mac、または Linux) で実行して、指定するトレーニング データセットに基づいて高品質の ML.NET モデルとソース コードを生成できます。
前提条件
- .NET Core 6 SDK 以降。
- (省略可能) Visual Studio
- ML.NET CLI
生成された C# コード プロジェクトは、Visual Studio から、または dotnet run (.NET CLI) を使用して実行できます。
データを準備する
ここでは、二項分類機械学習タスクである "感情分析" シナリオに使用されている既存のデータセットを使用します。 お持ちのデータセットを同様の方法で使用して、モデルとコードを自動的に生成することができます。
UCI Sentiment Labeled Sentences データセット zip ファイル (次の注の引用を参照してください) をダウンロードし、任意のフォルダーに展開します。
注意
このチュートリアルで使用されるデータセットでは、「From Group to Individual Labels using Deep Features」 (Kotzias 他 KDD 2015) のものであり、UCI 機械学習リポジトリ (Dua, D. and Karra Taniskidou, E.(2017)) でホストされています。 UCI 機械学習リポジトリ [http://archive.ics.uci.edu/ml ]。 カリフォルニア州アーバイン: カリフォルニア大学情報コンピュータサイエンス学部。
yelp_labelled.txtファイルを以前に作成した任意のフォルダー (/cli-testなど) にコピーします。任意のコマンド プロンプトを開き、データセット ファイルをコピーしたフォルダーに移動します。 次に例を示します。
cd /cli-testVisual Studio Code などの任意のテキスト エディターを使用して、
yelp_labelled.txtデータセット ファイルを開き、調べることができます。 次のような構造であることがわかります。このファイルにヘッダーはありません。 列のインデックスを使用します。
列は 2 つしかありません。
テキスト (列インデックス 0) ラベル (列インデックス 1) Wow...Loved this place. 1 Crust is not good. 0 Not tasty and the texture was just nasty. 0 ...その他のテキスト行... ...(1 または 0)...
データセット ファイルはエディターから必ず閉じてください。
これで、この "感情分析" シナリオに CLI を使用する準備が整いました。
注意
このチュートリアルを完了した後は、現在 ML.NET CLI プレビューでサポートされているいずれかの ML タスク ( "二項分類"、"分類"、"回帰" 、 "レコメンデーション" ) に使用する準備ができていれば、お持ちのデータセットで試すこともできます。
"mlnet classification" コマンドを実行する
次の ML.NET CLI コマンドを実行します。
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --train-time 10このコマンドによって
mlnet classificationコマンド が次のように実行されます。- "classification" の ML タスクに対して
- データセット ファイル
yelp_labelled.txtをトレーニングおよびテスト データセットとして使用します (内部的には、CLI によってクロス検証が使用されるか、トレーニング用に 1 つとテスト用に 1 つという 2 つのデータセットに分割されます)。 - この予測する目的列/ターゲット列 (一般的に "ラベル" と呼ばれます) は、インデックス 1 の列です (インデックスは 0 ベースなので、これは 2 列目です)。
- この特定のデータセット ファイルにはヘッダーがないため、列名を含むファイル ヘッダーは使用しません。
- 実験の目標探索およびトレーニング時間は 10 秒です
CLI からの出力が次のように表示されます。
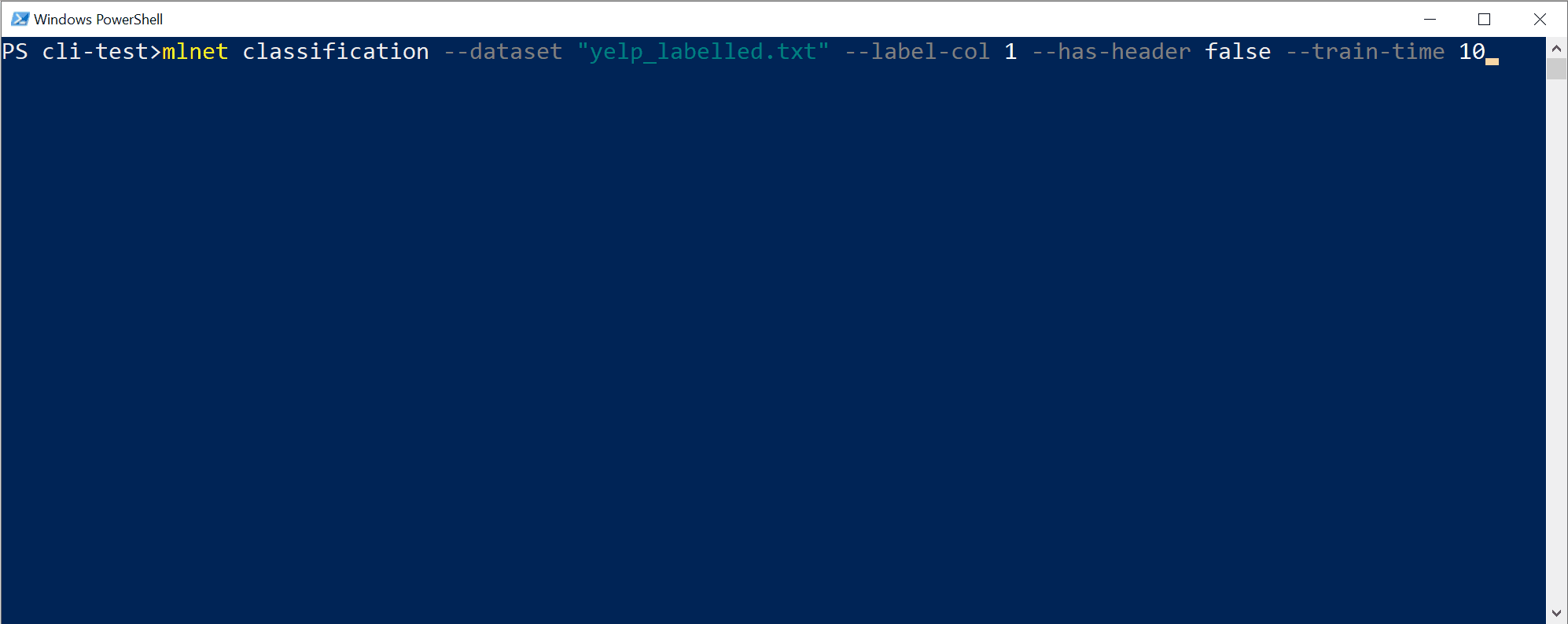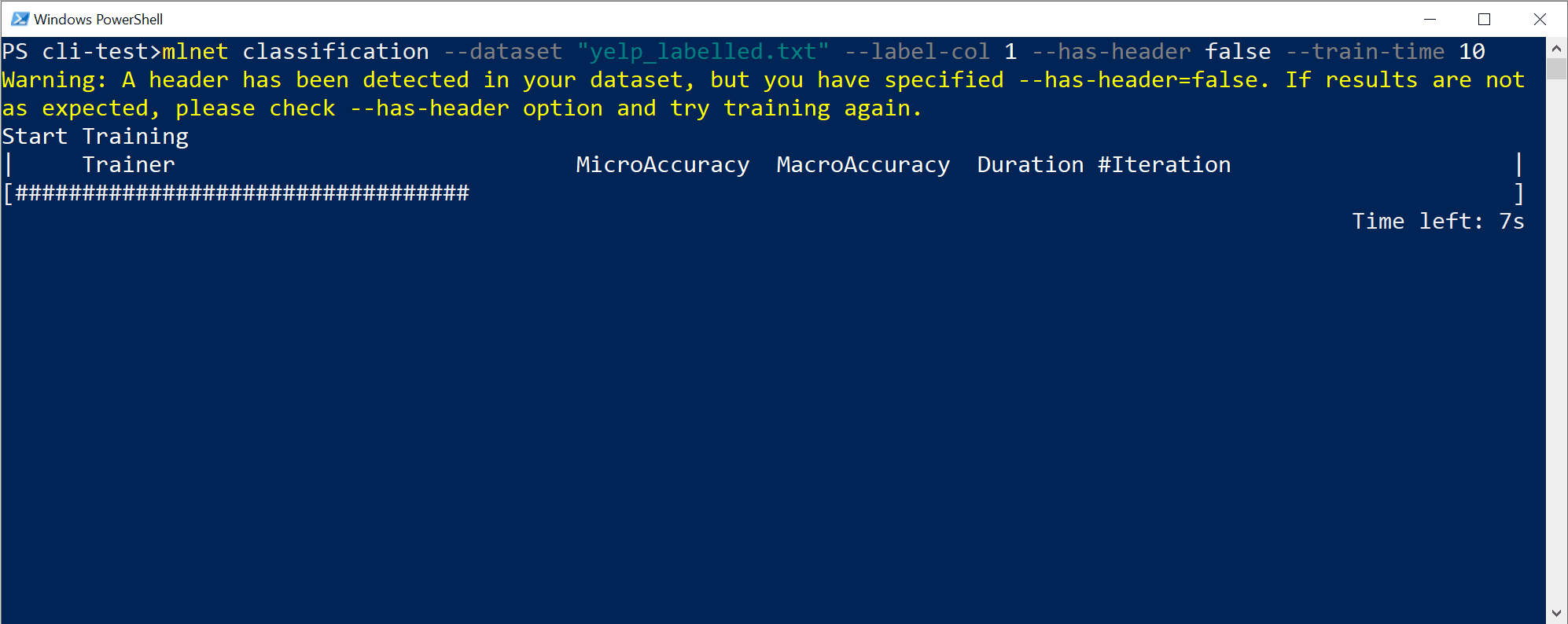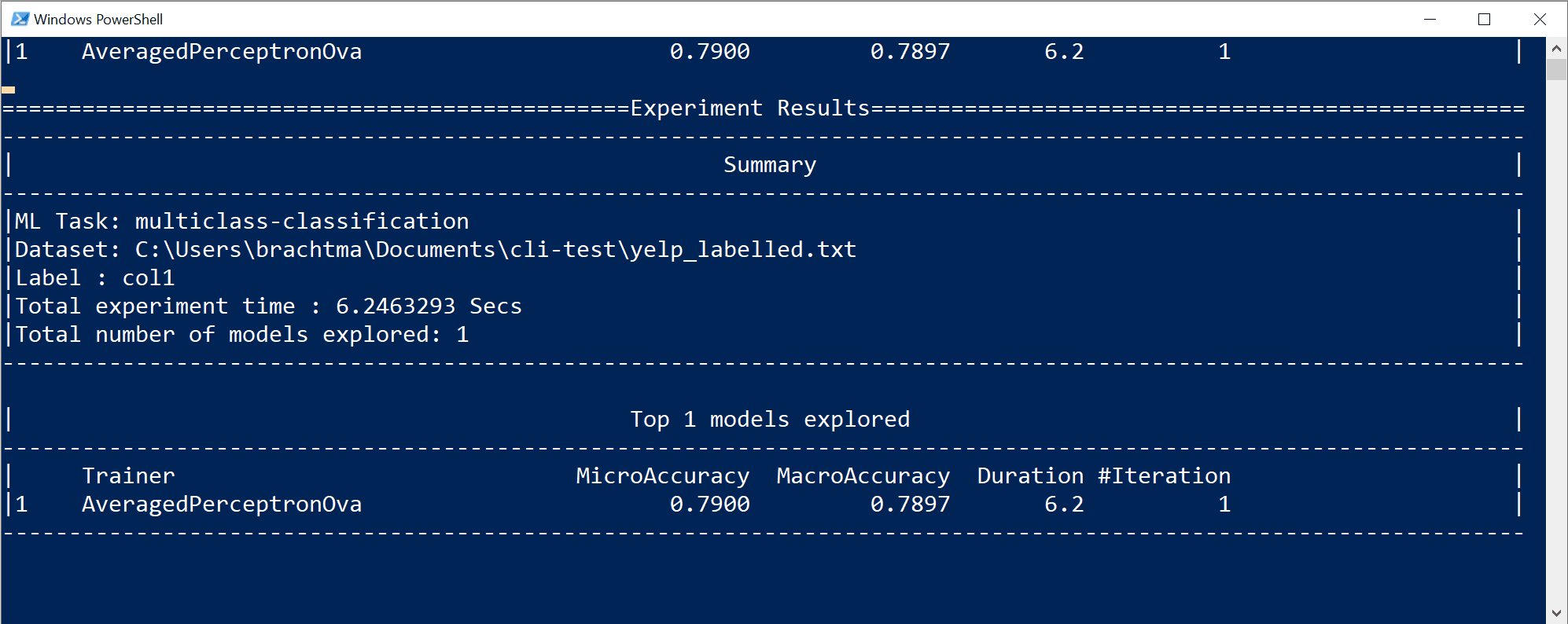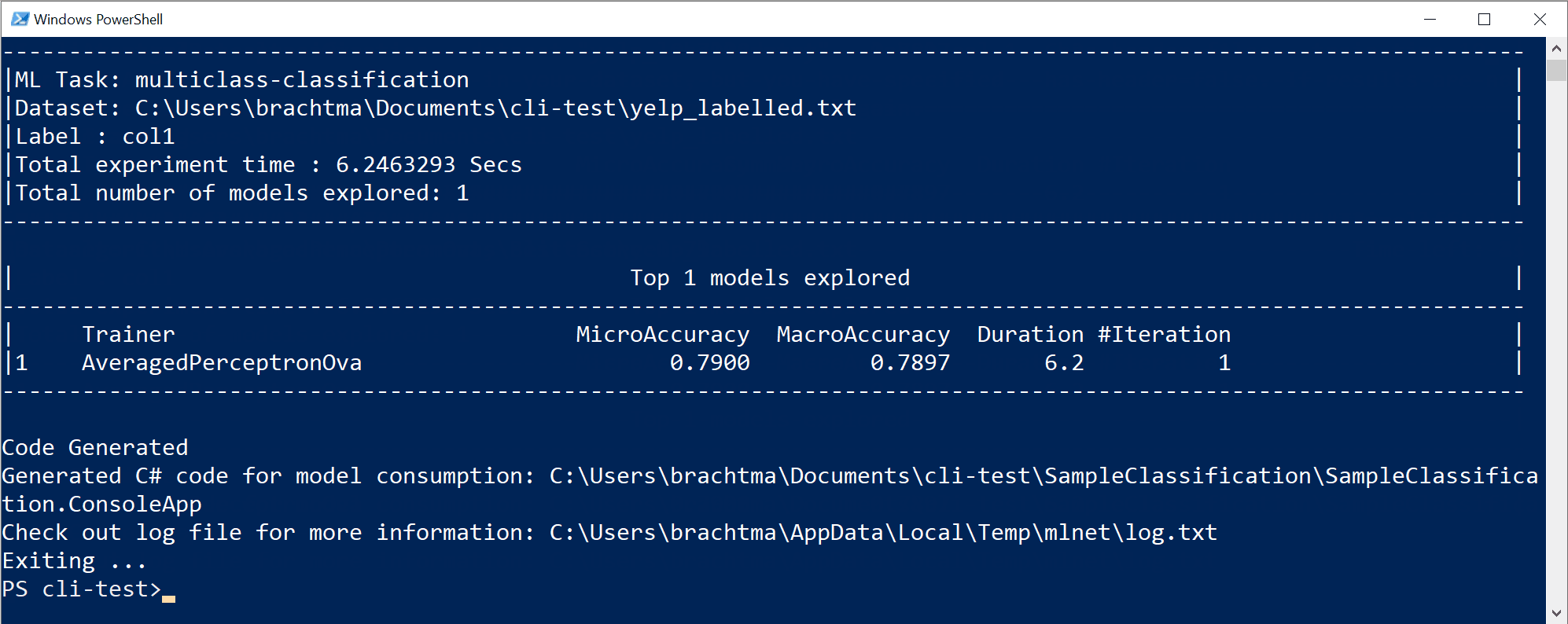
この特定のケースでは、CLI ツールでは、わずか 10 秒の間に指定した小さなデータセットに対してかなりの回数の反復処理を実行できました。つまり、内部データ変換とアルゴリズムのハイパーパラメーターが異なるさまざまなアルゴリズム/構成の組み合わせに基づいて、複数回のトレーニングを行いました。
最後に、10 秒間で検出された "最高品質" のモデルは、何らかの特定の構成を持つ特定のトレーナー/アルゴリズムを使用するモデルです。 探索時間によっては、コマンドから異なる結果が生成される可能性があります。 選択は、
Accuracyなど、表示されている複数のメトリックに基づいています。モデルの品質メトリックを理解する
二項分類モデルを評価する最初で最も簡単なメトリックは正確度です。これは簡単に理解できます。 "正確度は、テスト データ セットでの正しい予測の割合です"。 100% (1.00) に近いほど優れています。
ただし、正確度メトリックを使用して測定するだけでは不十分な場合があります。特に、テスト データセットでラベル (この場合は 0 と 1) のバランスが取れていない場合です。
追加のメトリックや、さまざまなモデルの評価に使用されるメトリックに関するより詳細な情報 (正確度、AUC、AUCPR、F1 スコアなど) については、ML.NET のメトリックの概要に関する記事をご覧ください。
注意
これと同じデータセットを試し、
--max-exploration-timeに数分間 (たとえば 180 秒を指定するので 3 分間) を指定すると、このデータセット (かなり小規模で 1,000 行) に対して、トレーニング パイプライン構成が異なる優れた "最適なモデル" が自動的に検出されます。大規模なデータセットを対象とした "運用環境対応モデル" である "最高/高品質" なモデルを見つけるには、通常、データセットのサイズに応じて、はるかに長い探索時間を指定して、CLI を使用した実験を行う必要があります。 実際のところ、多くの場合、特に行と列のデータセットが大きいと、数時間の探索時間が必要になることがあります。
前のコマンド実行により、以下の資産が生成されました。
- すぐに使用できるシリアル化されたモデル .zip ("最適なモデル")。
- その生成されたモデルを実行/スコア付けする C# コード (そのモデルを使用してエンドユーザー アプリで予測を行うため)。
- そのモデルを生成に使用される C# トレーニング コード (学習目的)。
- ハイパーパラメーターとデータ変換の組み合わせを使用して各アルゴリズムに関する具体的な詳細情報を試し、すべての反復処理が探索されたログ ファイル。
最初の 2 つの資産 (.ZIP ファイル モデルと、そのモデルを実行する C# コード) は、その生成された ML モデルを使用して予測を行うために、エンドユーザー アプリ (ASP.NET Core Web アプリ、サービス、デスクトップ アプリなど) で直接使用できます。
3 つ目の資産のトレーニング コードは、生成されたモデルをトレーニングするために CLI によって使用された ML.NET API コードを示しています。そのため、CLI によって選択された特定のトレーナー/アルゴリズムとハイパーパラメーターを調べることができます。
これらの列挙した資産については、チュートリアルの次の手順で説明します。
生成された C# コードを調べて予測するモデルの実行に使用する
Visual Studio で、元の保存先フォルダー内の
SampleClassificationという名前のフォルダーに生成されたソリューションを開きます (このチュートリアルでは/cli-testという名前でした)。 次のようなソリューションが表示されます。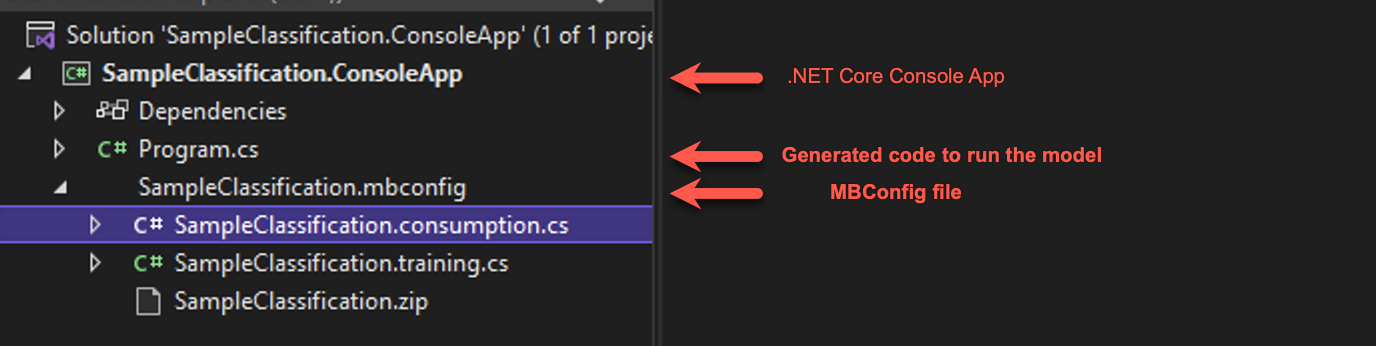
注意
このチュートリアルでは Visual Studio を使用することを推奨していますが、生成された C# コード (2 つのプロジェクト) を任意のテキスト エディターで調べ、生成されたコンソール アプリを macOS、Linux または Windows マシン上で
dotnet CLIを使用して実行することもできます。- 生成されたコンソール アプリには、確認する必要がある実行コードが含まれているので、通常、単純なコード (わずか数行) を予測を行うエンドユーザー アプリケーションに移動することで、"スコア付けコード" (予測する ML モデルを実行するコード) を再利用します。
- 生成された mbconfig ファイル は、CLI または Model Builder を使用してモデルを再トレーニングできる構成ファイルです。 これには、2 つのコード ファイルと zip ファイルも関連付けられています。
- training ファイルは、ML.NET API を使用してモデル パイプラインをビルドするコードを含みます。
- consumption ファイルは、モデルを使用するコードを含みます。
- zip ファイルは、CLI から生成されたモデルです。
mbconfig ファイル内の SampleClassification.consumption.cs ファイルを開きます。 入力および出力クラスを確認できます。 これらは、データを保持するために使用するデータ クラス (POCO クラス) です。 これらのクラスには、データセットに数十または数百の列がある場合に便利な定型コードが含まれています。
ModelInputクラスはデータセットからデータを読み取るときに使用されます。ModelOutputクラスは、予測結果 (予測データ) を取得するために使用します。
Program.cs ファイルを開き、コードを調べます。 わずか数行で、モデルを実行し、サンプル予測を行うことができます。
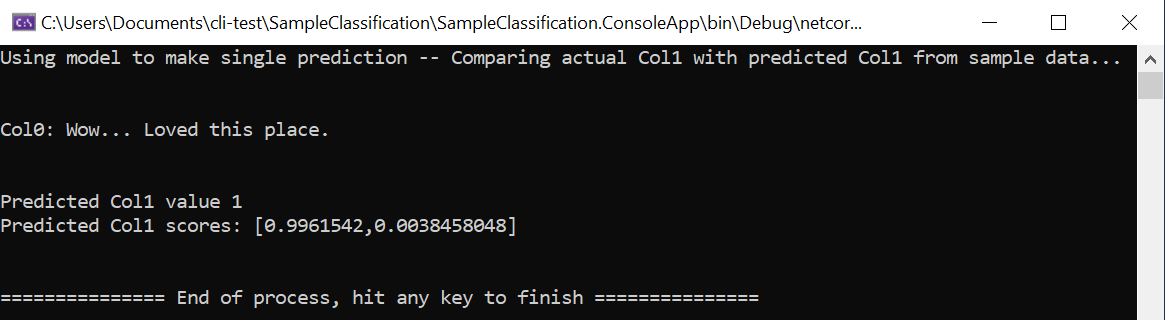
static void Main(string[] args) { // Create single instance of sample data from first line of dataset for model input ModelInput sampleData = new ModelInput() { Col0 = @"Wow... Loved this place.", }; // Make a single prediction on the sample data and print results var predictionResult = SampleClassification.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: {sampleData.Col0}"); Console.WriteLine($"\n\nPredicted Col1 value {predictionResult.PredictedLabel} \nPredicted Col1 scores: [{String.Join(",", predictionResult.Score)}]\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); }最初のコード行では、この場合は予測に使用するデータセットの最初の行に基づいて "単一のサンプル データ" が作成されます。 次のようにコードを更新して、独自の "ハードコーディングされたデータ" を作成することもできます。
ModelInput sampleData = new ModelInput() { Col0 = "The ML.NET CLI is great for getting started. Very cool!" };次のコード行では、指定の入力データ上で
SampleClassification.Predict()メソッドを使用して予測を行い、(ModelOutput.cs スキーマに基づいて) 結果を返します。最後のコード行では、サンプル データのプロパティに加え、Sentiment 予測と、肯定的なセンチメントの場合は (1)、否定的なセンチメントの場合は (2) という対応スコアが出力されます。
プロジェクトを実行するには、データセットの最初の行から読み込まれた元のサンプル データを使用するか、ハードコーディングされた独自のカスタム サンプル データを指定します。 次のような予測が得られます。
 )
)
- ハードコーディングされたサンプル データをセンチメントが異なる他の文に変更して、モデルがどのように肯定的センチメントまたは否定的センチメントを予測するかを確認してみてください。
エンドユーザー アプリケーションに ML モデルの予測を組み込む
同様の "ML モデル スコア付けコード" を使用して、エンドユーザー アプリケーションでモデルを実行し、予測することができます。
たとえば、そのコードを WPF や WinForms などの任意の Windows デスクトップ アプリケーションに直接移動して、コンソール アプリで実行したときと同じ方法でモデルを実行できます。
ただし、ML モデルを実行するこれらのコード行を実装する方法は、最適化して (つまり、モデルの .zip ファイルをキャッシュし、読み込みが 1 回になるようにして)、要求ごとに作成するのではなくシングルトン オブジェクトを持つようにします。次のセクションで説明するように、Web アプリケーションや分散サービスなど、アプリケーションをスケーラブルにする必要がある場合は特にそうです。
スケーラブルな ASP.NET Core Web アプリケーションおよびサービス (マルチスレッド アプリ) で ML.NET モデルを実行する
モデル オブジェクト (モデルの .zip ファイルから読み込まれた ITransformer) と PredictionEngine オブジェクトの作成は、最適化するようにします。特に、スケーラブルな Web アプリと分散サービスに対して実行する場合は特にそうです。 最初のケースでは、モデル オブジェクト (ITransformer) の最適化は簡単です。 ITransformer オブジェクトはスレッドセーフなので、オブジェクトをシングルトン オブジェクトまたは静的オブジェクトとしてキャッシュして、モデルの読み込みを 1 回にすることができます。
2 つ目のオブジェクトの PredictionEngine オブジェクトはそれほど簡単ではありません。PredictionEngine オブジェクトはスレッドセーフではないので、ASP.NET Core アプリでこのオブジェクトをシングルトン オブジェクトまたは静的オブジェクトとしてインスタンス化することができないからです。 このスレッド セーフとスケーラビリティの問題については、このブログ記事で詳しく説明されています。
ただし、状況はこのブログ記事で説明されているよりもはるかに簡単になりました。 Microsoft はより簡単なアプローチに取り組み、優れた ".NET Core 統合パッケージ" を作成しました。アプリケーションの DI サービス (Dependency Injection サービス) に登録することで ASP.NET Core アプリおよびサービスで簡単に使用できます。また、その後はコードから直接使用できます。 その実行方法については、次のチュートリアルと例を参照してください。
- チュートリアル: スケーラブルな ASP.NET Core Web アプリと WebAPI 上の ML.NET モデルの実行
- サンプル: ASP.NET Core WebAPI 上のスケーラブルな ML.NET モデル
"最高品質" のモデルのトレーニングに使用された生成済み C# コードを調べる
より高度な学習目的のために、生成済みモデルのトレーニングに CLI ツールによって使用された生成済み C# コードを調べることもできます。
その "トレーニング モデル コード" は、SampleClassification.training.cs という名前で生成されたカスタム クラスに生成されるので、そのトレーニング コードを調べることができます。
さらに重要な点は、この特定のシナリオ (感情分析モデル) の場合、その生成済みトレーニング コードを次のチュートリアルで説明されているコードと比較することもできることです。
チュートリアルで選択したアルゴリズムとパイプラインの構成を CLI ツールによって生成されたコードと比較するのは興味深いことです。 より良いモデルのために反復処理と検索に使う時間に応じて、選択されるアルゴリズムと、その特定のハイパーパラメーターとパイプラインの構成は変わることがあります。
このチュートリアルでは、次の作業を行う方法を学びました。
- 選択した ML タスク (解決する問題) 用のデータを準備する
- CLI ツールで "mlnet classification" コマンドを実行する
- 品質メトリックの結果を確認する
- モデルを実行するために生成された C# コード (エンドユーザー アプリで使用するコード) を理解する
- "最高品質" のモデルのトレーニングに使用された生成済み C# コードを調べる (学習目的)
関連項目
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET