この記事では、複数のバッファーで実行されるデータを読み取るのに役立つ型の概要について説明します。 これらは主に、 PipeReader オブジェクトをサポートするために使用されます。
IBufferWriter<T>
System.Buffers.IBufferWriter<T> は、同期バッファー書き込みのコントラクトです。 最下位レベルでは、インターフェイスは次のようになります。
- 基本的で使いにくいものではありません。
-
Memory<T>またはSpan<T>へのアクセスを許可します。
Memory<T>またはSpan<T>に書き込むことができるので、書き込まれたT項目の数を確認できます。
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
上記のメソッド:
-
IBufferWriter<byte>を使用して、GetSpan(5)から少なくとも 5 バイトのバッファーを要求します。 - 返された
Span<byte>に ASCII 文字列 "Hello" のバイトを書き込みます。 - バッファーに書き込まれたバイト数を示す IBufferWriter<T> を呼び出します。
この書き込み方法では、Memory<T>によって提供される/Span<T>IBufferWriter<T> バッファーを使用します。 または、 Write 拡張メソッドを使用して、既存のバッファーを IBufferWriter<T>にコピーすることもできます。
Write は必要に応じて GetSpan/Advance を呼び出す作業を行うので、書き込み後に Advance を呼び出す必要はありません。
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> は、バッキング ストアが単一の連続した配列である IBufferWriter<T> の実装です。
IBufferWriter の一般的な問題
-
GetSpanとGetMemoryは、少なくとも要求されたメモリ量を持つバッファーを返します。 正確なバッファー サイズは想定しないでください。 - 連続する呼び出しで同じバッファーまたは同じサイズのバッファーが返される保証はありません。
- データの書き込みを続行するには、
Advanceを呼び出した後に新しいバッファーを要求する必要があります。 以前に取得したバッファーは、Advanceが呼び出された後に書き込むことができません。
ReadOnlySequence<T>
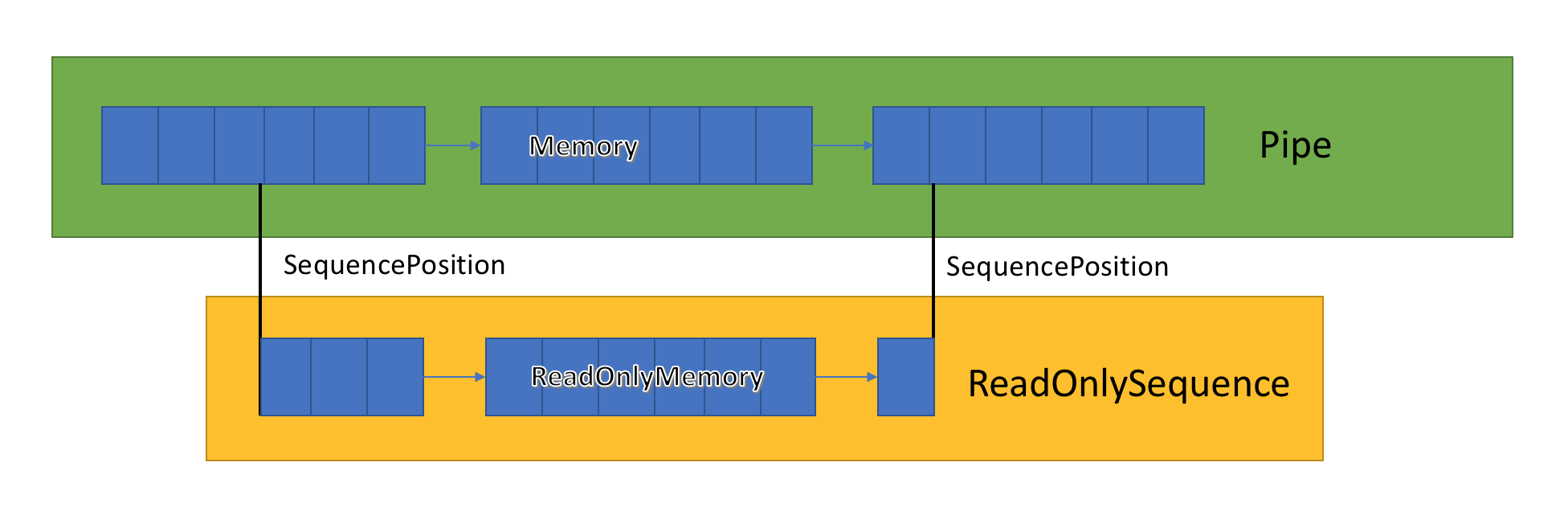
ReadOnlySequence<T> は、 Tの連続したシーケンスまたは連続しないシーケンスを表すことができる構造体です。 これは次のものから構築できます。
-
T[]。 -
ReadOnlyMemory<T>。 - シーケンスの開始位置と終了位置を表すリンク リスト ノード ReadOnlySequenceSegment<T> とインデックスのペア。
3 番目の表現は、 ReadOnlySequence<T>に対するさまざまな操作にパフォーマンスへの影響があるため、最も興味深いものです。
| 表現 | オペレーション | 複雑さ |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
この混合表現により、 ReadOnlySequence<T> は整数ではなく SequencePosition としてインデックスを公開します。
SequencePosition は:
- 元の
ReadOnlySequence<T>へのインデックスを表す不透明な値です。 - 整数とオブジェクトの 2 つの部分で構成されます。 これら 2 つの値が表すものは、
ReadOnlySequence<T>の実装に関連付けられています。
データにアクセスする
ReadOnlySequence<T>は、ReadOnlyMemory<T>の列挙可能なデータとしてデータを公開します。 各セグメントの列挙は、基本的な foreach を使用して行うことができます。
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
上記のメソッドは、各セグメントで特定のバイトを検索します。 各セグメントの SequencePositionを追跡する必要がある場合は、 ReadOnlySequence<T>.TryGet が適しています。 次のサンプルでは、上記のコードを変更して、整数ではなく SequencePosition を返します。
SequencePositionを返すには、呼び出し元が特定のインデックスでデータを取得する 2 回目のスキャンを回避できるという利点があります。
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
SequencePositionとTryGetの組み合わせは列挙子のように機能します。 位置フィールドは、各イテレーションの開始時に、 ReadOnlySequence<T>内の各セグメントの開始位置に変更されます。
上記のメソッドは、 ReadOnlySequence<T>の拡張メソッドとして存在します。
PositionOf は、上記のコードを簡略化するために使用できます。
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
ReadOnlySequence<T> の処理
データはシーケンス内の複数のセグメントに分割される可能性があるため、 ReadOnlySequence<T> の処理は困難な場合があります。 パフォーマンスを最大限に高めるには、コードを 2 つのパスに分割します。
- 単一セグメントのケースを処理する高速パス。
- セグメント間で分割されたデータを処理する低速パス。
複数セグメントのシーケンス内のデータを処理するために使用できる方法がいくつかあります。
-
SequenceReader<T>を使用します。 - セグメントごとにデータ セグメントを解析し、解析されたセグメント内の
SequencePositionとインデックスを追跡します。 これにより、不要な割り当てが回避されますが、特に小さなバッファーでは非効率的な場合があります。 -
ReadOnlySequence<T>を連続した配列にコピーし、1 つのバッファーのように扱います。-
ReadOnlySequence<T>のサイズが小さい場合は、stackalloc 演算子を使用して、スタック割り当てバッファーにデータをコピーするのが妥当な場合があります。 -
ReadOnlySequence<T>を使用して、プールされた配列にArrayPool<T>.Sharedをコピーします。 -
ReadOnlySequence<T>.ToArray()を使用してください。 これは、ヒープに新しいT[]を割り当てるので、ホット パスでは推奨されません。
-
次の例では、 ReadOnlySequence<byte>を処理するいくつかの一般的なケースを示します。
バイナリ データの処理
次の例では、 ReadOnlySequence<byte>の先頭から 4 バイトのビッグ エンディアン整数の長さを解析します。
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
テキスト データを処理する
次のような例です。
-
\r\n内の最初の改行 (ReadOnlySequence<byte>) を検索し、out 'line' パラメーターを使用して返します。 - 入力バッファーから
\r\nを除き、その行をトリミングします。
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
空のセグメント
ReadOnlySequence<T>内に空のセグメントを格納することは有効です。 セグメントを明示的に列挙しているときに、空のセグメントが発生する可能性があります。
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
上記のコードは、空のセグメントを含む ReadOnlySequence<byte> を作成し、それらの空のセグメントがさまざまな API にどのように影響するかを示しています。
-
ReadOnlySequence<T>.Slice空のセグメントを指すSequencePositionがある場合、そのセグメントは保持されます。 -
ReadOnlySequence<T>.Sliceint を指定すると、空のセグメントがスキップされます。 -
ReadOnlySequence<T>を列挙すると、空のセグメントが列挙されます。
ReadOnlySequence<T> および SequencePosition に関する潜在的な問題
ReadOnlySequence<T>
/
SequencePositionと通常のReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/intを扱うときには、いくつかの異常な結果があります。
-
SequencePositionは、絶対位置ではなく、特定のReadOnlySequence<T>の位置マーカーです。 特定のReadOnlySequence<T>に対して相対的であるため、発生元のReadOnlySequence<T>の外部で使用しても意味がありません。 -
SequencePositionがないと、ReadOnlySequence<T>に対して算術演算を実行することはできません。 つまり、position++のような基本的なことをするというのは、position = ReadOnlySequence<T>.GetPosition(1, position)と書かれているという意味です。 -
GetPosition(long)は負のインデックスをサポートしません。 つまり、すべてのセグメントをたどることなく最後から 2 番目の文字を取得することはできません。 - 2 つの
SequencePositionを比較できないため、次のことが困難になります。- ある位置が別の位置より大きいか小さいか確認します。
- いくつかの解析アルゴリズムを記述します。
-
ReadOnlySequence<T>はオブジェクト参照よりも大きく、可能な場合は in または ref で渡す必要があります。ReadOnlySequence<T>またはinでrefを渡すと、構造体のコピーが減ります。 - 空のセグメント:
-
ReadOnlySequence<T>内で有効です。 -
ReadOnlySequence<T>.TryGetメソッドを使用して反復処理を行うときに表示できます。 -
ReadOnlySequence<T>.Slice()メソッドとSequencePositionオブジェクトを使用してシーケンスをスライスしているように見えます。
-
SequenceReader<T>
-
ReadOnlySequence<T>の処理を簡略化するために .NET Core 3.0 で導入された新しい型です。 - 1 つのセグメント
ReadOnlySequence<T>と複数セグメントのReadOnlySequence<T>の違いを統一します。 - セグメント間で分割される場合と分割されないバイナリ データとテキスト データ (
byteとchar) を読み取るためのヘルパーを提供します。
バイナリ データと区切りデータの両方の処理を処理するための組み込みメソッドがあります。 次のセクションでは、 SequenceReader<T>と同じメソッドの外観を示します。
データにアクセスする
SequenceReader<T> には、 ReadOnlySequence<T> 内のデータを直接列挙するためのメソッドがあります。 次のコードは、ReadOnlySequence<byte>byteを一度に処理する例です。
while (reader.TryRead(out byte b))
{
Process(b);
}
CurrentSpanは、現在のセグメントのSpanを公開します。これは、メソッドで手動で実行されたものと似ています。
位置の使用
次のコードは、FindIndexOfを使用したSequenceReader<T>の実装例です。
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
バイナリ データの処理
次の例では、 ReadOnlySequence<byte>の先頭から 4 バイトのビッグ エンディアン整数の長さを解析します。
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
テキスト データを処理する
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
SequenceReader<T> 一般的な問題
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET