データ統合を確認する
変更の概要を確認し、統合プロファイルを作成して、結果を確認します。
顧客プロファイルを確認し、作成する
統合プロセスのこの最後の手順は、プロセスの手順の概要を示し、統合プロファイルを作成する前に変更を加える機会を提供します。
次の手順と画像は、統合プロセスを初めて実行したときのものです。 既存の統合設定を編集するには、統合設定を更新するを参照してください。

確認して変更を加えるには、データ統合手順のいずれかで編集を選択します。
選択内容に問題がなければ、顧客プロファイルの作成 を選択します。 統合された顧客プロファイルの作成中に、統合ページが表示されます。

統合アルゴリズムは完了するまでに時間がかかり、完了するまで構成を変更できません。
データ統合の結果を表示する
統合後、データ>統合ページに統合された顧客プロファイルの数が表示されます。 統合プロセスの各手順の結果は、各タイルに表示されます。 たとえば、顧客データ ではマッピングされた列の数が表示され、重複排除ルール では見つかった重複レコードの数が表示されます。
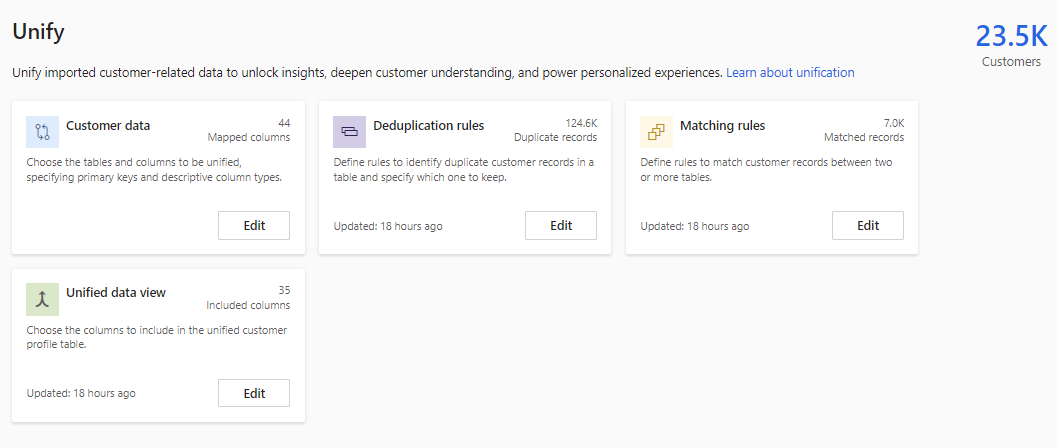
チップ
複数のテーブルが選択されている場合のみ、マッチング ルール タイルが表示されます。
結果、特に一致規則 の品質を確認し、必要に応じてそれらを調整することをお勧めします。
必要に応じて、統合設定を変更 して、統合プロファイルを再実行します。
データ統合からの出力テーブルを確認する
データ>テーブルに移動し、出力テーブルを確認します。
Customer と呼ばれる統合された顧客プロファイル テーブルは、プロファイル セクションに表示されます。 最初に成功した統合実行により、統合された Customer テーブルが作成されます。 以降のすべての実行では、そのテーブルが展開されます。
重複排除テーブルおよび合成テーブルが作成され、システム セクションに表示されます。 各ソース テーブルの重複排除テーブルは、Deduplication_DataSource_Table という名前で作成されます。 ConflationMatchPairs テーブルには、テーブル間照合の情報が含まれます。
重複排除出力テーブルには、次の情報が含まれています。
- ID/キー
- 主キーと代替 ID フィールド。 代替 ID フィールドは、レコードに対して識別されたすべての代替 ID で構成されます。
- Deduplication_GroupId フィールドには、指定された重複排除フィールドに基づいてすべての類似レコードをグループ化するテーブル内で識別されたグループまたはクラスターが表示されます。 これは、システム処理の目的で使用されます。 手動の重複排除ルールが指定されておらず、システム定義の重複排除ルールが適用されている場合、このフィールドが重複排除出力テーブルに表示されていない可能性があります。
- Deduplication_WinnerId: このフィールドには、識別されたグループまたはクラスターからの勝者 ID が含まれます。 Deduplication_WinnerId がレコードの主キー値と同じである場合、そのレコードが勝者レコードであることを意味します。
- 重複排除ルールを定義するために使用されるフィールド。
- [ルール] フィールドと [スコア] フィールドは、どの重複排除ルールが適用され、照合アルゴリズムによってスコアが返されことを示します。
予期しない統合結果を解決する
統合はエラーなしで正常に完了したものの、結果が予想通りではない場合は、次を確認してください。
- データ入力の検証: 統合プロセスに提供されたデータの正確性と完全性を再確認します。 関連するレコードと情報がすべて含まれていることを確認してください。
- データ品質の確認: 入力データの品質を評価します。 統合結果に影響を与える可能性のある異常、不整合、またはエラーがないかどうかを確認します。 信頼性の高い結果を確保するには、統合プロセスの前にデータをクリーンアップして正規化することが不可欠です。
- 統合設定を確認する: 統合プロセスに使用される構成と設定を調べます。 重複排除とプロファイル生成に指定された基準が正しく定義されており、望ましい結果と一致しているかどうかを確認してください。
- 重複排除の結果を検証します。
- テーブルとルールの優先順位を確認してください。
- 照合ルールを検証します。
- 統合システムで採用されている照合ルールを評価します。 ルールが意図した条件に基づいてレコードを正確に識別し、一致していることを確認します。 必要に応じて、照合ルールを調整します。
- 照合プロセスの一部として行われる正規化および顧客照合ステップ (存在する場合) を確認します。 たとえば、あるソース レコードでニックネームが使用され、別のソース レコードではフルネームが使用されている場合でも、ソース レコードが正しく一致するように、Mike は Michael に正規化されます。 一般的な正規化をバイパスするには、カスタム正規化ロジックを設定します。
- マージ ポリシーを確認します。
- サンプル データを使用したテスト: サンプル データのサブセットを使用してテストを実行し、統合プロセスをシミュレートします。 期待される結果と実際の結果を比較して、不一致や予期しない動作を特定します。
- 重複排除ルールと照合ルールを再実行します。 データ>統合>一致条件のみを実行に移動し、結果を比較します。 ルールが期待される結果を提供する場合は、マージを再実行して結果を比較します。 データ>統合>顧客プロファイルを統合するに移動します。
問題が解決しない場合、または未解決のままの場合は、サポート チームまたは技術チームに連絡してください。 ソース データ レコード、予想される統合顧客プロファイル レコード、その結果が予想される理由、再現手順、該当する場合はサンプル データ、関連するエラー メッセージなど、問題に関する詳細情報を提供してください。