Scott Allen
公開日: 2010 年 5 月
はじめに
このホワイト ペーパーでは、ADO.NET Entity Framework 4.0 と Visual Studio 2010 を使用して、テスト可能なコードを記述する方法について説明し、説明します。 このホワイト ペーパーでは、テスト駆動設計 (TDD) や動作駆動設計 (BDD) など、特定のテスト手法に焦点を当てようとしていません。 代わりに、このホワイト ペーパーでは、ADO.NET Entity Framework を使用するコードを記述する方法に焦点を当てますが、自動化された方法で分離してテストするのは簡単です。 データ アクセス シナリオでのテストを容易にする一般的な設計パターンを見て、フレームワークを使用するときにそれらのパターンを適用する方法を確認します。 また、フレームワークの特定の機能を見て、それらの機能がテスト可能なコードでどのように機能するかを確認します。
Testable Code とは
自動単体テストを使用してソフトウェアの一部を検証する機能には、多くの望ましい利点があります。 誰もが良いテストは、アプリケーションのソフトウェア欠陥の数を減らし、アプリケーションの品質を向上させるだろうことを知っていますが、単体テストを実施することは、バグを見つけるだけではありません。
優れた単体テスト スイートを使用すると、開発チームは時間を節約し、作成したソフトウェアを制御できます。 チームは、既存のコードに変更を加え、新しい要件を満たすようにソフトウェアをリファクタリング、再設計、および再構築し、テスト スイートがアプリケーションの動作を検証できることを知りながら、新しいコンポーネントをアプリケーションに追加することができます。 単体テストは、変更を容易にし、複雑さが増すにつれてソフトウェアの保守性を維持するための迅速なフィードバック サイクルの一部です。
ただし、単体テストには価格が付属しています。 チームは、単体テストの作成と保守に時間を費やす必要があります。 これらのテストを作成するために必要な作業量は、基になるソフトウェアの テスト可能性 に直接関係します。 ソフトウェアのテストはどのくらい簡単ですか? テスト可能性を念頭に置いてソフトウェアを設計するチームは、テスト不可能なソフトウェアを使用するチームよりも迅速に効果的なテストを作成します。
Microsoft では、テスト可能性を念頭に置いて、ADO.NET Entity Framework 4.0 (EF4) を設計しました。 これは、開発者がフレームワーク コード自体に対して単体テストを記述することを意味するものではありません。 代わりに、EF4 のテスト容易性の目標により、フレームワーク上に構築されるテスト可能なコードを簡単に作成できます。 具体的な例を見る前に、テスト可能なコードの品質を理解する価値があります。
テスト可能なコードの品質
テストが簡単なコードは、常に少なくとも 2 つの特徴を示します。 まず、テスト可能なコードは簡単に 観察できます。 いくつかの入力セットを考えると、コードの出力を簡単に観察できます。 たとえば、メソッドは計算の結果を直接返すので、次のメソッドのテストは簡単です。
public int Add(int x, int y) {
return x + y;
}
メソッドのテストは、計算された値をネットワーク ソケット、データベース テーブル、または次のコードのようなファイルに書き込む場合は困難です。 テストでは、値を取得するために追加の作業を実行する必要があります。
public void AddAndSaveToFile(int x, int y) {
var results = string.Format("The answer is {0}", x + y);
File.WriteAllText("results.txt", results);
}
第 2 に、テスト可能なコードは簡単に 分離できます。 テスト可能なコードの不適切な例として、次の擬似コードを使用してみましょう。
public int ComputePolicyValue(InsurancePolicy policy) {
using (var connection = new SqlConnection("dbConnection"))
using (var command = new SqlCommand(query, connection)) {
// business calculations omitted ...
if (totalValue > notificationThreshold) {
var message = new MailMessage();
message.Subject = "Warning!";
var client = new SmtpClient();
client.Send(message);
}
}
return totalValue;
}
この方法は簡単に観察できます。保険証券を渡し、戻り値が予想される結果と一致することを確認できます。 ただし、メソッドをテストするには、正しいスキーマを使用してデータベースをインストールし、メソッドが電子メールを送信しようとした場合に備えて SMTP サーバーを構成する必要があります。
単体テストでは、メソッド内の計算ロジックのみを確認する必要がありますが、電子メール サーバーがオフラインであるか、データベース サーバーが移動したためにテストが失敗する可能性があります。 どちらのエラーも、テストで検証する必要がある動作とは無関係です。 この動作を分離することは困難です。
テスト可能なコードを記述するソフトウェア開発者は、多くの場合、記述するコードで懸念事項の分離を維持するよう努めています。 上記の方法では、ビジネス計算に焦点を当て、データベースと電子メールの実装の詳細を他のコンポーネントに委任する必要があります。 ロバート・C・マーティンはこれを単一責任原則と呼ぶ。 オブジェクトは、ポリシーの値の計算など、1 つの狭い責任をカプセル化する必要があります。 他のすべてのデータベースと通知の作業は、他のオブジェクトの責任である必要があります。 この方法で記述されたコードは、1 つのタスクに重点を置いているため、分離が容易になります。
.NET には、単一責任の原則に従い、分離を実現するために必要な抽象化があります。 インターフェイス定義を使用し、具象型ではなくインターフェイス抽象化を使用するようにコードに強制することができます。 このホワイト ペーパーの後半では、上記の不適切な例のようなメソッドが、データベースと通信するように 見 えるインターフェイスで動作する方法について説明します。 ただし、テスト時には、データベースと通信せず、代わりにデータをメモリに保持するダミーの実装を置き換えることができます。 このダミー実装は、データ アクセス コードまたはデータベース構成の関連のない問題からコードを分離します。
分離には追加の利点があります。 最後のメソッドのビジネス計算の実行には数ミリ秒しかかからなくなりますが、コードがネットワークを飛び回り、さまざまなサーバーと通信するため、テスト自体が数秒間実行される可能性があります。 単体テストは、小さな変更を容易にするために高速に実行する必要があります。 単体テストは繰り返し可能で、テストに関係のないコンポーネントに問題があるため、失敗しないようにする必要があります。 観察しやすく分離しやすいコードを記述すると、開発者はコードのテストを簡単に記述でき、テストの実行を待つ時間が短くなり、さらに重要なことに、存在しないバグの追跡に費やす時間が短縮されます。
テストの利点を理解し、テスト可能なコードが示す品質を理解できることを願っています。 EF4 と連携してデータをデータベースに保存し、監視可能で分離しやすいままでコードを記述する方法について説明しますが、まず、データ アクセスのテスト可能な設計について説明するために焦点を絞ります。
データ永続化の設計パターン
前に示した悪い例の両方に、あまりにも多くの責任がありました。 最初の悪い例は、計算を実行 して ファイルに書き込む必要がありました。 2 つ目の不適切な例では、データベースからデータを読み取 り、 ビジネス計算を実行して電子メールを送信 する 必要がありました。 懸念事項を分離し、他のコンポーネントに責任を委任する小さなメソッドを設計することで、テスト可能なコードの記述に向けて大きな進歩を遂げます。 目標は、小規模で焦点を絞った抽象化からアクションを作成して機能を構築することです。
データの永続化に関しては、探している小規模で焦点を絞った抽象化は、設計パターンとして文書化されているのが非常に一般的です。 Martin Fowler の書籍『エンタープライズ アプリケーション アーキテクチャのパターン』は、印刷でこれらのパターンを記述する最初の作品でした。 これらの ADO.NET Entity Framework がこれらのパターンを実装して使用する方法を示す前に、以下のセクションでこれらのパターンについて簡単に説明します。
リポジトリ パターン
Fowler は、リポジトリが 「ドメイン オブジェクトにアクセスするためのコレクションのようなインターフェイスを使用して、ドメインとデータ マッピング レイヤーの間を仲介する」と述べています。 リポジトリ パターンの目的は、データ アクセスの最小値からコードを分離することです。前に説明したように、分離はテスト容易性に必要な特性です。
分離の鍵となるのは、リポジトリがコレクションのようなインターフェイスを使用してオブジェクトを公開する方法です。 リポジトリを使用するように記述するロジックでは、要求したオブジェクトがリポジトリでどのように具体化されるかが分かりません。 リポジトリはデータベースと通信する場合もあれば、メモリ内コレクションからオブジェクトを返す場合もあります。 コードで知る必要があるのは、コレクションを維持するためにリポジトリが表示され、コレクションからオブジェクトを取得、追加、および削除できることです。
既存の .NET アプリケーションでは、具象リポジトリは、多くの場合、次のような汎用インターフェイスから継承されます。
public interface IRepository<T> {
IEnumerable<T> FindAll();
IEnumerable<T> FindBy(Expression<Func\<T, bool>> predicate);
T FindById(int id);
void Add(T newEntity);
void Remove(T entity);
}
EF4 の実装を提供するときに、インターフェイス定義にいくつかの変更を加えますが、基本的な概念は変わりません。 コードでは、このインターフェイスを実装する具象リポジトリを使用して、主キー値でエンティティを取得したり、述語の評価に基づいてエンティティのコレクションを取得したり、使用可能なすべてのエンティティを単に取得したりできます。 コードでは、リポジトリ インターフェイスを使用してエンティティを追加および削除することもできます。
Employee オブジェクトの IRepository を指定すると、コードは次の操作を実行できます。
var employeesNamedScott =
repository
.FindBy(e => e.Name == "Scott")
.OrderBy(e => e.HireDate);
var firstEmployee = repository.FindById(1);
var newEmployee = new Employee() {/*... */};
repository.Add(newEmployee);
コードはインターフェイス (Employee の IRepository) を使用しているため、インターフェイスのさまざまな実装をコードに提供できます。 実装の 1 つは、EF4 によってサポートされ、Microsoft SQL Server データベースにオブジェクトを永続化する実装です。 別の実装 (テスト中に使用するもの) は、メモリ内の Employee オブジェクトのリストによってサポートされる場合があります。 インターフェイスは、コードで分離を実現するのに役立ちます。
IRepository<T> インターフェイスで保存操作が公開されていないことに注意してください。 既存のオブジェクトを更新する方法 保存操作を含む IRepository 定義に遭遇する場合があり、これらのリポジトリの実装では、オブジェクトをデータベースに直ちに永続化する必要があります。 ただし、多くのアプリケーションでは、オブジェクトを個別に永続化する必要はありません。 代わりに、おそらく異なるリポジトリからオブジェクトを実現し、それらのオブジェクトをビジネス アクティビティの一部として変更し、すべてのオブジェクトを単一のアトミック操作の一部として保持したいと考えています。 幸いにも、この種の動作を許可するパターンがあります。
作業単位パターン
Fowler は、作業単位が "ビジネス トランザクションの影響を受けるオブジェクトの一覧を保持し、変更の書き込みとコンカレンシーの問題の解決を調整する" と述べています。 作業単位には、リポジトリから取り出して管理するオブジェクトへの変更を追跡し、変更をコミットする指示を受けた際に、それらの変更を永続化する責任があります。 また、すべてのリポジトリに追加した新しいオブジェクトを取得し、オブジェクトをデータベースに挿入し、削除を管理することも、作業単位の役割です。
ADO.NET データセットで作業を行ったことがある場合は、作業の単位パターンに既に慣れているでしょう。 ADO.NET データセットには、DataRow オブジェクトの更新、削除、挿入を追跡する機能があり、(TableAdapter の助けを借りて) データベースに対するすべての変更を調整できます。 ただし、DataSet オブジェクトは、基になるデータベースの切断されたサブセットをモデル化します。 作業単位パターンは同じ動作を示しますが、データ アクセス コードから分離され、データベースを認識できないビジネス オブジェクトとドメイン オブジェクトで動作します。
.NET コードで作業単位をモデル化するための抽象化は、次のようになります。
public interface IUnitOfWork {
IRepository<Employee> Employees { get; }
IRepository<Order> Orders { get; }
IRepository<Customer> Customers { get; }
void Commit();
}
作業単位からリポジトリ参照を公開することで、1 つの作業単位オブジェクトで、ビジネス トランザクション中に具体化されたすべてのエンティティを追跡する機能を確保できます。 実際の作業単位に対する Commit メソッドの実装では、メモリ内の変更をデータベースと調整するためにすべてのマジックが行われます。
IUnitOfWork 参照を指定すると、コードは 1 つ以上のリポジトリから取得したビジネス オブジェクトに変更を加え、アトミックコミット操作を使用してすべての変更を保存できます。
var firstEmployee = unitofWork.Employees.FindById(1);
var firstCustomer = unitofWork.Customers.FindById(1);
firstEmployee.Name = "Alex";
firstCustomer.Name = "Christopher";
unitofWork.Commit();
遅延読み込みパターン
Fowler は、「レイジーロード」という名前を使って、「必要なすべてのデータが含まれていないが、取得方法を知っているオブジェクト」を説明します。 透過的な遅延読み込みは、テスト可能なビジネス コードを記述し、リレーショナル データベースを操作するときに必要な重要な機能です。 例として、次のコードを考えてみましょう。
var employee = repository.FindById(id);
// ... and later ...
foreach(var timeCard in employee.TimeCards) {
// .. manipulate the timeCard
}
TimeCards コレクションはどのように入力されますか? 考えられる答えは 2 つあります。 1 つの答えは、従業員リポジトリが従業員をフェッチするように求められたら、従業員と従業員の関連するタイムカード情報の両方を取得するためのクエリを発行することです。 リレーショナル データベースでは、通常、これは JOIN 句を含むクエリを必要とし、アプリケーションのニーズよりも多くの情報を取得する可能性があります。 アプリケーションが TimeCards プロパティに触れる必要がない場合はどうしますか?
2 つ目の答えは、TimeCards プロパティを "オンデマンド" で読み込む方法です。 この遅延読み込みは、コードがタイム カード情報を取得するための特別な API を呼び出さないので、ビジネス ロジックに対して暗黙的かつ透過的です。 このコードでは、必要に応じタイム カード情報が存在することを前提としています。 遅延読み込みには、一般的にメソッド呼び出しの実行時インターセプトを伴うマジックがいくつかあります。 インターセプト コードは、ビジネス ロジックを自由にビジネス ロジックのままにしたまま、データベースと通信し、タイム カード情報を取得する役割を担います。 この遅延読み込みマジックにより、ビジネス コードはデータ取得操作から自分自身を分離し、テスト可能なコードになります。
遅延読み込みの欠点は、アプリケーションが本当にタイムカード情報を必要とする場合、コードが追加のクエリを実行することです。 これは多くのアプリケーションにとって問題ではありませんが、パフォーマンスに影響を受けやすいアプリケーションやアプリケーションが多数の従業員オブジェクトをループ処理し、ループの各イテレーション中にタイム カードを取得するクエリを実行する場合 (多くの場合、N+1 クエリの問題と呼ばれる問題)、遅延読み込みはドラッグです。 このようなシナリオでは、アプリケーションは、可能な限り最も効率的な方法でタイム カード情報を熱心に読み込むことができます。
幸いなことに、EF4 が暗黙的な遅延読み込みと効率的な一括読み込みの両方をサポートする方法について説明します。次のセクションに進み、これらのパターンを実装します。
Entity Framework を使用したパターンの実装
良いニュースは、前のセクションで説明したすべての設計パターンは、EF4 で簡単に実装できるということです。 デモンストレーションを行うために、単純な ASP.NET MVC アプリケーションを使用して、Employees とそれに関連付けられているタイム カード情報を編集して表示します。 まず、以下の「古典的な CLR オブジェクト」(POCOs)を使用します。
public class Employee {
public int Id { get; set; }
public string Name { get; set; }
public DateTime HireDate { get; set; }
public ICollection<TimeCard> TimeCards { get; set; }
}
public class TimeCard {
public int Id { get; set; }
public int Hours { get; set; }
public DateTime EffectiveDate { get; set; }
}
EF4 のさまざまなアプローチと機能を調べると、これらのクラス定義は若干変更されますが、これらのクラスは可能な限り永続化無知 (PI) として保持することが目的です。 PI オブジェクトは、保持している状態がデータベース内に存在するかどうか、または存在しているかどうかを知りません。 PI と POCO は、テスト可能なソフトウェアと連携します。 POCO アプローチを使用するオブジェクトは、制約が少なく、柔軟性が高く、テストが簡単です。データベースがなくても動作できるためです。
POCO を配置すると、Visual Studio でエンティティ データ モデル (EDM) を作成できます (図 1 を参照)。 エンティティのコードを生成するために EDM を使用しません。 代わりに、手作業で愛情を込めて作成したエンティティを使用したいと考えています。 EDM のみを使用してデータベース スキーマを生成し、EF4 がオブジェクトをデータベースにマップするために必要なメタデータを提供します。
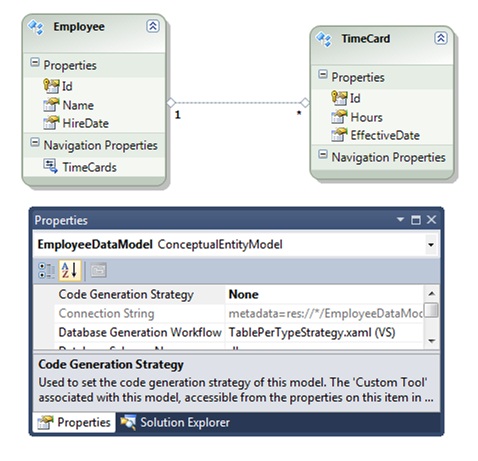
図 1
注: 最初に EDM モデルを開発する場合は、EDM からクリーンな POCO コードを生成できます。 これは、データ プログラミング チームが提供する Visual Studio 2010 拡張機能を使用して行うことができます。 拡張機能をダウンロードするには、Visual Studio の [ツール] メニューから拡張機能マネージャーを起動し、テンプレートのオンライン ギャラリーで "POCO" を検索します (図 2 を参照)。 EF で使用できる POCO テンプレートがいくつかあります。 テンプレートの使用方法の詳細については、「 チュートリアル: Entity Framework の POCO テンプレート」を参照してください。
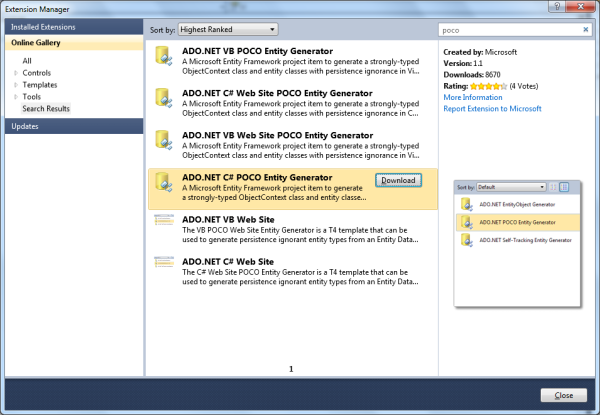
図 2
この POCO の開始点から、テスト可能なコードに対する 2 つの異なるアプローチについて説明します。 最初のアプローチは、Entity Framework API からの抽象化を利用して作業単位とリポジトリを実装するため、EF アプローチと呼びます。 2 番目のアプローチでは、独自のカスタム リポジトリの抽象化を作成し、各アプローチの長所と短所を確認します。 まず、EF のアプローチについて説明します。
EF 中心の実装
ASP.NET MVC プロジェクトの次のコントローラー アクションについて考えてみましょう。 このアクションは Employee オブジェクトを取得し、結果を返して従業員の詳細ビューを表示します。
public ViewResult Details(int id) {
var employee = _unitOfWork.Employees
.Single(e => e.Id == id);
return View(employee);
}
コードはテスト可能ですか? アクションの動作を確認するために必要なテストが少なくとも 2 つあります。 まず、アクションが正しいビュー (簡単なテスト) を返すかどうかを確認します。 また、アクションが正しい従業員を取得することを確認するテストを記述したいと考えています。データベースにクエリを実行するコードを実行せずにこれを行いたいと考えています。 テスト対象のコードを分離する必要があります。 分離により、データ アクセス コードまたはデータベース構成のバグが原因でテストが失敗しないようにします。 テストが失敗した場合は、いくつかの下位レベルのシステム コンポーネントではなく、コントローラー ロジックにバグがあることがわかります。
分離を実現するには、リポジトリと作業単位について前に示したインターフェイスのような抽象化が必要になります。 リポジトリ パターンは、ドメイン オブジェクトとデータ マッピング レイヤーの間で仲介するように設計されていることを思い出してください。 このシナリオでは、EF4 は データ マッピング レイヤーであり、(System.Data.Objects 名前空間から) IObjectSet<T> という名前のリポジトリのような抽象化を既に提供しています。 インターフェイス定義は次のようになります。
public interface IObjectSet<TEntity> :
IQueryable<TEntity>,
IEnumerable<TEntity>,
IQueryable,
IEnumerable
where TEntity : class
{
void AddObject(TEntity entity);
void Attach(TEntity entity);
void DeleteObject(TEntity entity);
void Detach(TEntity entity);
}
IObjectSet<T> は、(IEnumerable <T> を介して) オブジェクトのコレクションに似ているため、リポジトリの要件を満たし、シミュレートされたコレクションからオブジェクトを追加および削除するメソッドを提供します。 Attach メソッドと Detach メソッドは、EF4 API の追加機能を公開します。 リポジトリのインターフェイスとして IObjectSet<T> を使用するには、リポジトリをバインドするための作業単位の抽象化が必要です。
public interface IUnitOfWork {
IObjectSet<Employee> Employees { get; }
IObjectSet<TimeCard> TimeCards { get; }
void Commit();
}
このインターフェイスの具体的な実装の 1 つは SQL Server と通信し、EF4 の ObjectContext クラスを使用して簡単に作成できます。 ObjectContext クラスは、EF4 API の実際の作業単位です。
public class SqlUnitOfWork : IUnitOfWork {
public SqlUnitOfWork() {
var connectionString =
ConfigurationManager
.ConnectionStrings[ConnectionStringName]
.ConnectionString;
_context = new ObjectContext(connectionString);
}
public IObjectSet<Employee> Employees {
get { return _context.CreateObjectSet<Employee>(); }
}
public IObjectSet<TimeCard> TimeCards {
get { return _context.CreateObjectSet<TimeCard>(); }
}
public void Commit() {
_context.SaveChanges();
}
readonly ObjectContext _context;
const string ConnectionStringName = "EmployeeDataModelContainer";
}
IObjectSet<T> を有効にするには、ObjectContext オブジェクトの CreateObjectSet メソッドを呼び出すのと同じくらい簡単です。 バックグラウンドでは、フレームワークは EDM で提供したメタデータを使用して、具象 ObjectSet<T> を生成します。 IObjectSet<T> インターフェイスの返しは、クライアント コードのテスト可能性を維持するのに役立つため、引き続き使用します。
この具体的な実装は運用環境で役立ちますが、IUnitOfWork 抽象化を使用してテストを容易にする方法に焦点を当てる必要があります。
テストダブル
コントローラー アクションを分離するには、実際の作業単位 (ObjectContext によってサポートされる) とテストの double または "fake" の作業単位 (メモリ内操作の実行) を切り替える機能が必要です。 この種類の切り替えを実行する一般的な方法は、MVC コントローラーが作業単位をインスタンス化するのではなく、コンストラクター パラメーターとしてコントローラーに作業単位を渡すことです。
class EmployeeController : Controller {
publicEmployeeController(IUnitOfWork unitOfWork) {
_unitOfWork = unitOfWork;
}
...
}
上記のコードは、依存関係の挿入の例です。 コントローラーが依存関係 (作業単位) を作成することを許可せず、依存関係をコントローラーに挿入します。 MVC プロジェクトでは、カスタム コントローラー ファクトリを制御の反転 (IoC) コンテナーと組み合わせて使用して依存関係の挿入を自動化するのが一般的です。 これらのトピックは、この記事の範囲を超えていますが、この記事の最後のリファレンスに従って詳細を確認できます。
テストに使用できる偽の作業単位の実装は、次のようになります。
public class InMemoryUnitOfWork : IUnitOfWork {
public InMemoryUnitOfWork() {
Committed = false;
}
public IObjectSet<Employee> Employees {
get;
set;
}
public IObjectSet<TimeCard> TimeCards {
get;
set;
}
public bool Committed { get; set; }
public void Commit() {
Committed = true;
}
}
偽の作業単位が Commited プロパティを公開していることに注意してください。 テストを容易にする偽のクラスに機能を追加すると便利な場合があります。 この場合、Commited プロパティを調べて、コードが作業単位をコミットするかどうかを簡単に確認できます。
Employee オブジェクトと TimeCard オブジェクトをメモリに保持するには、偽の IObjectSet<T> も必要です。 ジェネリックを使用して 1 つの実装を提供できます。
public class InMemoryObjectSet<T> : IObjectSet<T> where T : class
public InMemoryObjectSet()
: this(Enumerable.Empty<T>()) {
}
public InMemoryObjectSet(IEnumerable<T> entities) {
_set = new HashSet<T>();
foreach (var entity in entities) {
_set.Add(entity);
}
_queryableSet = _set.AsQueryable();
}
public void AddObject(T entity) {
_set.Add(entity);
}
public void Attach(T entity) {
_set.Add(entity);
}
public void DeleteObject(T entity) {
_set.Remove(entity);
}
public void Detach(T entity) {
_set.Remove(entity);
}
public Type ElementType {
get { return _queryableSet.ElementType; }
}
public Expression Expression {
get { return _queryableSet.Expression; }
}
public IQueryProvider Provider {
get { return _queryableSet.Provider; }
}
public IEnumerator<T> GetEnumerator() {
return _set.GetEnumerator();
}
IEnumerator IEnumerable.GetEnumerator() {
return GetEnumerator();
}
readonly HashSet<T> _set;
readonly IQueryable<T> _queryableSet;
}
このテストは、その作業の大部分を基になる HashSet<T> オブジェクトに二重に委任します。 IObjectSet<T> には、T をクラス (参照型) として適用するジェネリック制約が必要であり、IQueryable<T> を実装する必要があることに注意してください。 標準の LINQ 演算子 AsQueryable を使用して、メモリ内コレクションを IQueryable<T> として表示するのは簡単です。
テスト
従来の単体テストでは、1 つのテスト クラスを使用して、1 つの MVC コントローラー内のすべてのアクションのすべてのテストを保持します。 作成したメモリ内の偽物を使用して、これらのテストまたは任意の種類の単体テストを記述できます。 ただし、この記事ではモノリシック テスト クラスのアプローチを回避し、代わりに特定の機能に焦点を当てるテストをグループ化します。 たとえば、"新しい従業員の作成" はテストする機能であるため、1 つのテスト クラスを使用して、新しい従業員の作成を担当する単一のコントローラー アクションを確認します。
これらすべてのきめ細かいテスト クラスに必要な一般的なセットアップ コードがいくつかあります。 たとえば、メモリ内リポジトリと偽の作業単位を常に作成する必要があります。 また、偽の作業単位が挿入された従業員コントローラーのインスタンスも必要です。 この一般的なセットアップ コードは、基本クラスを使用してテスト クラス間で共有します。
public class EmployeeControllerTestBase {
public EmployeeControllerTestBase() {
_employeeData = EmployeeObjectMother.CreateEmployees()
.ToList();
_repository = new InMemoryObjectSet<Employee>(_employeeData);
_unitOfWork = new InMemoryUnitOfWork();
_unitOfWork.Employees = _repository;
_controller = new EmployeeController(_unitOfWork);
}
protected IList<Employee> _employeeData;
protected EmployeeController _controller;
protected InMemoryObjectSet<Employee> _repository;
protected InMemoryUnitOfWork _unitOfWork;
}
基底クラスで使用する "object mother" は、テスト データを作成するための一般的なパターンの 1 つです。 オブジェクトの母には、複数のテスト フィクスチャで使用するためにテスト エンティティをインスタンス化するファクトリ メソッドが含まれています。
public static class EmployeeObjectMother {
public static IEnumerable<Employee> CreateEmployees() {
yield return new Employee() {
Id = 1, Name = "Scott", HireDate=new DateTime(2002, 1, 1)
};
yield return new Employee() {
Id = 2, Name = "Poonam", HireDate=new DateTime(2001, 1, 1)
};
yield return new Employee() {
Id = 3, Name = "Simon", HireDate=new DateTime(2008, 1, 1)
};
}
// ... more fake data for different scenarios
}
EmployeeControllerTestBase は、多数のテスト フィクスチャの基本クラスとして使用できます (図 3 を参照)。 各テスト フィクスチャは、特定のコントローラー アクションをテストします。 たとえば、1 つのテスト フィクスチャは、HTTP GET 要求中に使用される Create アクションのテストに重点を置きます (従業員を作成するためのビューを表示するため)。別のフィクスチャは、HTTP POST 要求で使用される作成アクション (従業員を作成するためにユーザーによって送信された情報を取得するため) に焦点を当てます。 各派生クラスは、特定のコンテキストで必要なセットアップと、その特定のテスト コンテキストの結果を検証するために必要なアサーションを提供することのみを担当します。
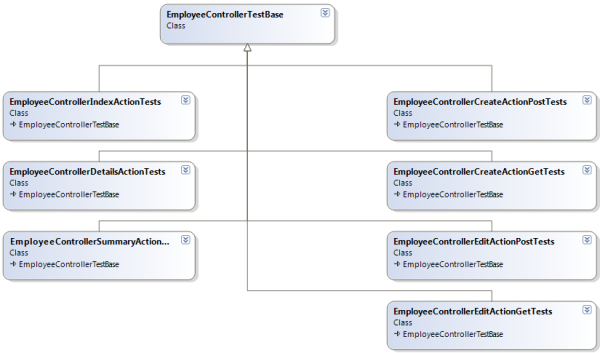
図 3
ここで示す名前付け規則とテスト スタイルは、テスト可能なコードには必要ありません。これは 1 つのアプローチにすぎません。 図 4 は、Visual Studio 2010 の Jet Brains Resharper テスト ランナー プラグインで実行されているテストを示しています。
図 4
共有セットアップ コードを処理する基本クラスでは、各コントローラー アクションの単体テストは小さく、簡単に記述できます。 (メモリ内操作を実行しているため) テストは迅速に実行されます。また、関連のないインフラストラクチャや環境上の問題 (テスト対象のユニットを分離したため) が原因で失敗しないようにする必要があります。
[TestClass]
public class EmployeeControllerCreateActionPostTests
: EmployeeControllerTestBase {
[TestMethod]
public void ShouldAddNewEmployeeToRepository() {
_controller.Create(_newEmployee);
Assert.IsTrue(_repository.Contains(_newEmployee));
}
[TestMethod]
public void ShouldCommitUnitOfWork() {
_controller.Create(_newEmployee);
Assert.IsTrue(_unitOfWork.Committed);
}
// ... more tests
Employee _newEmployee = new Employee() {
Name = "NEW EMPLOYEE",
HireDate = new System.DateTime(2010, 1, 1)
};
}
これらのテストでは、基本クラスがほとんどのセットアップ作業を行います。 基底クラスのコンストラクターは、インメモリ リポジトリ、偽の作業単位、EmployeeController クラスのインスタンスを作成することを思い出してください。 テスト クラスは、この基底クラスから派生し、Create メソッドのテストの詳細に焦点を当てます。 この場合、詳細は、単体テストの手順で確認できる "配置、操作、アサート" の手順にまで及ぶことになります。
- newEmployee オブジェクトを作成して、受信データをシミュレートします。
- EmployeeController の Create アクションを呼び出し、newEmployee を渡します。
- [作成] アクションで期待される結果が生成されていることを確認します (従業員がリポジトリに表示されます)。
作成した内容を使用すると、EmployeeController アクションのいずれかをテストできます。 たとえば、Employee コントローラーの Index アクションのテストを記述する場合、テストの基本クラスから継承して、テストに対して同じ基本セットアップを確立できます。 ここでも、基底クラスはインメモリ リポジトリ、偽の作業単位、EmployeeController のインスタンスを作成します。 Index アクションのテストでは、Index アクションの呼び出しと、アクションが返すモデルの品質のテストにのみ集中する必要があります。
[TestClass]
public class EmployeeControllerIndexActionTests
: EmployeeControllerTestBase {
[TestMethod]
public void ShouldBuildModelWithAllEmployees() {
var result = _controller.Index();
var model = result.ViewData.Model
as IEnumerable<Employee>;
Assert.IsTrue(model.Count() == _employeeData.Count);
}
[TestMethod]
public void ShouldOrderModelByHiredateAscending() {
var result = _controller.Index();
var model = result.ViewData.Model
as IEnumerable<Employee>;
Assert.IsTrue(model.SequenceEqual(
_employeeData.OrderBy(e => e.HireDate)));
}
// ...
}
メモリ内の偽物を使用して作成するテストは、ソフトウェアの 状態 のテストに向けられます。 たとえば、作成アクションをテストする場合、作成アクションの実行後にリポジトリの状態を検査する必要があります。リポジトリは新しい従業員を保持しますか?
[TestMethod]
public void ShouldAddNewEmployeeToRepository() {
_controller.Create(_newEmployee);
Assert.IsTrue(_repository.Contains(_newEmployee));
}
後で、対話ベースのテストについて説明します。 対話ベースのテストでは、テスト対象のコードがオブジェクトに対して適切なメソッドを呼び出し、正しいパラメーターを渡したかどうかを確認します。 とりあえず、別のデザインパターンである遅延読み込みに進みます。
アクティブローディングとレイジーローディング
ASP.NET MVC Web アプリケーションのある時点で、従業員の情報を表示し、従業員の関連するタイム カードを含めることができます。 たとえば、従業員の名前とシステム内のタイム カードの合計数を示すタイム カードの概要表示があるとします。 この機能を実装するには、いくつかの方法があります。
プロジェクション
概要を作成する簡単な方法の 1 つは、ビューに表示する情報専用のモデルを構築することです。 このシナリオでは、モデルは次のようになります。
public class EmployeeSummaryViewModel {
public string Name { get; set; }
public int TotalTimeCards { get; set; }
}
EmployeeSummaryViewModel はエンティティではないことに注意してください。つまり、データベースに保持するものではありません。 このクラスを使用して、厳密に型指定された方法でビューにデータをシャッフルするだけです。 ビュー モデルは、動作 (メソッドなし) が含まれているので、データ転送オブジェクト (DTO) に似ています。プロパティのみが含まれます。 プロパティには、移動する必要があるデータが保持されます。 LINQ の標準プロジェクション演算子である Select 演算子を使用して、このビュー モデルを簡単にインスタンス化できます。
public ViewResult Summary(int id) {
var model = _unitOfWork.Employees
.Where(e => e.Id == id)
.Select(e => new EmployeeSummaryViewModel
{
Name = e.Name,
TotalTimeCards = e.TimeCards.Count()
})
.Single();
return View(model);
}
上記のコードには、2 つの注目すべき機能があります。 1 つ目のコードは、観察と分離が簡単であるため、簡単にテストできます。 Select 演算子は、実際の作業単位に対しても同様に、メモリ内の偽物に対しても同様に機能します。
[TestClass]
public class EmployeeControllerSummaryActionTests
: EmployeeControllerTestBase {
[TestMethod]
public void ShouldBuildModelWithCorrectEmployeeSummary() {
var id = 1;
var result = _controller.Summary(id);
var model = result.ViewData.Model as EmployeeSummaryViewModel;
Assert.IsTrue(model.TotalTimeCards == 3);
}
// ...
}
2 つ目の注目すべき機能は、EF4 が従業員とタイム カードの情報を組み合わせて 1 つの効率的なクエリを生成できるようにする方法です。 特別な API を使用せずに、従業員情報とタイム カード情報を同じオブジェクトに読み込んだ。 このコードでは、メモリ内のデータ ソースとリモート データ ソースに対して機能する標準の LINQ 演算子を使用して必要な情報を表現するだけです。 EF4 では、LINQ クエリと C# コンパイラによって生成された式ツリーを、1 つの効率的な T-SQL クエリに変換できました。
SELECT
[Limit1].[Id] AS [Id],
[Limit1].[Name] AS [Name],
[Limit1].[C1] AS [C1]
FROM (SELECT TOP (2)
[Project1].[Id] AS [Id],
[Project1].[Name] AS [Name],
[Project1].[C1] AS [C1]
FROM (SELECT
[Extent1].[Id] AS [Id],
[Extent1].[Name] AS [Name],
(SELECT COUNT(1) AS [A1]
FROM [dbo].[TimeCards] AS [Extent2]
WHERE [Extent1].[Id] =
[Extent2].[EmployeeTimeCard_TimeCard_Id]) AS [C1]
FROM [dbo].[Employees] AS [Extent1]
WHERE [Extent1].[Id] = @p__linq__0
) AS [Project1]
) AS [Limit1]
ビュー モデルや DTO オブジェクトではなく、実際のエンティティを操作する必要がある場合もあります。 従業員 と 従業員のタイム カードが必要であることがわかっている場合は、目立たない効率的な方法で関連データを熱心に読み込むことができます。
明示的な一括読み込み
関連するエンティティ情報を熱心に読み込むには、ビジネス ロジック (またはこのシナリオではコントローラー アクション ロジック) がリポジトリへの要望を表現するためのメカニズムが必要です。 EF4 ObjectQuery<T> クラスは、クエリ中に取得する関連オブジェクトを指定する Include メソッドを定義します。 EF4 ObjectContext は、ObjectQuery<T> から継承する具象 ObjectSet<T> クラスを介してエンティティを公開することを思い出してください。 コントローラー アクションで ObjectSet<T> 参照を使用していた場合は、次のコードを記述して、各従業員のタイム カード情報の一括読み込みを指定できます。
_employees.Include("TimeCards")
.Where(e => e.HireDate.Year > 2009);
ただし、コードをテスト可能な状態に保つために、実際の作業単位の外部から ObjectSet<T> を公開していません。 代わりに、IObjectSet<T> インターフェイスに依存します。これは偽装が容易ですが、IObjectSet<T> では Include メソッドは定義されません。 LINQ の美しさは、独自の Include 演算子を作成できることです。
public static class QueryableExtensions {
public static IQueryable<T> Include<T>
(this IQueryable<T> sequence, string path) {
var objectQuery = sequence as ObjectQuery<T>;
if(objectQuery != null)
{
return objectQuery.Include(path);
}
return sequence;
}
}
この Include 演算子は、IObjectSet<T> の代わりに IQueryable<T> の拡張メソッドとして定義されていることに注意してください。 これにより、IQueryable<T>、IObjectSet<T>、ObjectQuery<T>、ObjectSet<T> など、さまざまな種類のメソッドを使用できます。 基になるシーケンスが正規の EF4 ObjectQuery<T> でない場合、害はなく、Include 演算子は no-opです。 基になるシーケンス が ObjectQuery<T> (または ObjectQuery<T> から派生した) の場合、EF4 には追加データの要件が表示され、適切な SQL クエリが作成されます。
この新しい演算子を配置することで、リポジトリからタイム カード情報の一括読み込みを明示的に要求できます。
public ViewResult Index() {
var model = _unitOfWork.Employees
.Include("TimeCards")
.OrderBy(e => e.HireDate);
return View(model);
}
実際の ObjectContext に対して実行すると、コードによって次の 1 つのクエリが生成されます。 このクエリは、従業員オブジェクトを具体化し、TimeCards プロパティを完全に設定するために、1 回の乗車でデータベースから十分な情報を収集します。
SELECT
[Project1].[Id] AS [Id],
[Project1].[Name] AS [Name],
[Project1].[HireDate] AS [HireDate],
[Project1].[C1] AS [C1],
[Project1].[Id1] AS [Id1],
[Project1].[Hours] AS [Hours],
[Project1].[EffectiveDate] AS [EffectiveDate],
[Project1].[EmployeeTimeCard_TimeCard_Id] AS [EmployeeTimeCard_TimeCard_Id]
FROM ( SELECT
[Extent1].[Id] AS [Id],
[Extent1].[Name] AS [Name],
[Extent1].[HireDate] AS [HireDate],
[Extent2].[Id] AS [Id1],
[Extent2].[Hours] AS [Hours],
[Extent2].[EffectiveDate] AS [EffectiveDate],
[Extent2].[EmployeeTimeCard_TimeCard_Id] AS
[EmployeeTimeCard_TimeCard_Id],
CASE WHEN ([Extent2].[Id] IS NULL) THEN CAST(NULL AS int)
ELSE 1 END AS [C1]
FROM [dbo].[Employees] AS [Extent1]
LEFT OUTER JOIN [dbo].[TimeCards] AS [Extent2] ON [Extent1].[Id] = [Extent2].[EmployeeTimeCard_TimeCard_Id]
) AS [Project1]
ORDER BY [Project1].[HireDate] ASC,
[Project1].[Id] ASC, [Project1].[C1] ASC
すばらしいニュースは、アクション メソッド内のコードが完全にテスト可能なままである点です。 Include 演算子をサポートするために、偽物に追加の機能を提供する必要はありません。 問題点は、私たちが永続性を意識しないようにしたいコード内で Include 演算子を使用しなければならなかったことです。 これは、テスト可能なコードをビルドするときに評価する必要があるトレードオフの種類の主要な例です。 パフォーマンスの目標を達成するために、永続化に関する懸念がリポジトリの抽象化の外部に漏れ出す必要がある場合があります。
一括読み込みの代わりに、遅延読み込みがあります。 遅延読み込みとは、ビジネスコードが関連データの要件を明示的に要求する必要がないことを意味します。 代わりに、アプリケーションでエンティティを使用し、追加のデータが必要な場合、Entity Framework はオンデマンドでデータを読み込みます。
遅延読み込み
ビジネス ロジックに必要なデータがわからないシナリオは、簡単に想像できます。 ロジックに従業員オブジェクトが必要であることがわかっているかもしれませんが、それらのパスの一部に従業員からのタイム カード情報が必要で、そうでないものがあるさまざまな実行パスに分岐する場合があります。 このようなシナリオは、データが必要に応じて魔法のように表示されるため、暗黙的な遅延読み込みに最適です。
遅延読み込み (遅延読み込みとも呼ばれます) は、エンティティ オブジェクトにいくつかの要件を設定します。 真の永続性無視を持つ POCO は永続化レイヤーからの要件に直面しませんが、真の永続化の無視を実現することは事実上不可能です。 代わりに、永続的な無知を相対的な程度で測定します。 永続化指向の基底クラスから継承する必要がある場合や、特殊なコレクションを使用して POCO での遅延読み込みを実現する必要がある場合は、残念です。 幸いなことに、EF4 は侵入度の低いソリューションを提供しています。
仮想的に検出できない
POCO オブジェクトを使用する場合、EF4 はエンティティのランタイム プロキシを動的に生成できます。 これらのプロキシは、具体化されたPOCOを目に見えないほどラップし、各プロパティの取得および設定操作をインターセプトして追加の処理を実行することで、追加のサービスを提供します。 そのようなサービスの 1 つは、探している遅延読み込み機能です。 もう 1 つのサービスは、プログラムがエンティティのプロパティ値を変更したときに記録できる効率的な変更追跡メカニズムです。 変更の一覧は、Update コマンドを使用して変更されたエンティティを保持するために、SaveChanges メソッドの間に ObjectContext によって使用されます。
ただし、これらのプロキシを機能させるには、エンティティに対するプロパティの取得操作と設定操作にフックする方法が必要であり、プロキシは仮想メンバーをオーバーライドすることでこの目標を達成します。 したがって、暗黙的な遅延読み込みと効率的な変更追跡を行う場合は、POCO クラス定義に戻り、プロパティを仮想としてマークする必要があります。
public class Employee {
public virtual int Id { get; set; }
public virtual string Name { get; set; }
public virtual DateTime HireDate { get; set; }
public virtual ICollection<TimeCard> TimeCards { get; set; }
}
Employee エンティティは、ほとんど永続性を無視していると言えます。 唯一の要件は仮想メンバーを使用することであり、コードのテスト可能性には影響しません。 特別な基底クラスから派生したり、遅延読み込み専用の特別なコレクションを使用したりする必要はありません。 コードが示すように、ICollection<T> を実装するすべてのクラスを使用して、関連エンティティを保持できます。
また、作業単位内で行う必要がある小さな変更も 1 つあります。 ObjectContext オブジェクトを直接操作する場合、遅延読み込みは既定で オフ になります。 遅延読み込みを有効にするために ContextOptions プロパティに設定できるプロパティがあり、どこでも遅延読み込みを有効にする場合は、実際の作業単位内でこのプロパティを設定できます。
public class SqlUnitOfWork : IUnitOfWork {
public SqlUnitOfWork() {
// ...
_context = new ObjectContext(connectionString);
_context.ContextOptions.LazyLoadingEnabled = true;
}
// ...
}
暗黙的な遅延読み込みを有効にすると、アプリケーション コードでは、EF が追加データを読み込むのに必要な作業を知らずに、従業員と従業員の関連付けられているタイム カードを使用できます。
var employee = _unitOfWork.Employees
.Single(e => e.Id == id);
foreach (var card in employee.TimeCards) {
// ...
}
遅延読み込みにより、アプリケーション コードの記述が容易になり、プロキシ マジックにより、コードは完全にテスト可能なままになります。 作業単位のメモリ内の偽物は、テスト中に必要なときに、関連するデータを持つ偽のエンティティをプリロードするだけです。
この時点で、IObjectSet<T> を使用してリポジトリを構築する方法に注目し永続化フレームワークのすべての兆候を隠すために抽象化を見ていきます。
カスタム リポジトリ
この記事で最初に作業単位の設計パターンを示したとき、作業単位の外観に関するいくつかのサンプル コードを提供しました。 これまで取り組んできた従業員と従業員のタイム カードのシナリオを使用して、この元のアイデアを再提示しましょう。
public interface IUnitOfWork {
IRepository<Employee> Employees { get; }
IRepository<TimeCard> TimeCards { get; }
void Commit();
}
この作業単位と前のセクションで作成した作業単位の主な違いは、この作業単位が EF4 フレームワークからの抽象化を使用しない方法です (IObjectSet<T>はありません)。 IObjectSet<T> はリポジトリ インターフェイスと同様に機能しますが、公開される API はアプリケーションのニーズと完全には一致しない可能性があります。 この今後のアプローチでは、カスタム IRepository<T> 抽象化を使用してリポジトリを表します。
テスト駆動型の設計、動作駆動型の設計、ドメイン駆動型の手法の設計に従う多くの開発者は、いくつかの理由から IRepository<T> アプローチを好みます。 まず、IRepository<T> インターフェイスは、"破損防止" レイヤーを表します。 Eric Evans がドメイン 駆動設計ブックで説明したように、破損防止レイヤーにより、永続化 API などのインフラストラクチャ API からドメイン コードが保護されます。 第 2 に、開発者は、(テストの記述中に検出された) アプリケーションの正確なニーズを満たすメソッドをリポジトリにビルドできます。 たとえば、ID 値を使用して 1 つのエンティティを検索することが頻繁に必要になる場合があるため、リポジトリ インターフェイスに FindById メソッドを追加できます。 IRepository<T> 定義は次のようになります。
public interface IRepository<T>
where T : class, IEntity {
IQueryable<T> FindAll();
IQueryable<T> FindWhere(Expression<Func\<T, bool>> predicate);
T FindById(int id);
void Add(T newEntity);
void Remove(T entity);
}
エンティティ コレクションを公開するために、IQueryable<T> インターフェイスの使用に立ち戻ります。 IQueryable<T> を使用すると、LINQ 式ツリーを EF4 プロバイダーにフローさせ、プロバイダーにクエリの全体像を提供できます。 2 つ目のオプションは、IEnumerable<T> を返す方法です。つまり、EF4 LINQ プロバイダーはリポジトリ内に構築された式のみを表示します。 リポジトリの外部で実行されるグループ化、順序付け、およびプロジェクションは、データベースに送信される SQL コマンドに構成されないため、パフォーマンスが低下する可能性があります。 一方、IEnumerable<T> 結果のみを返すリポジトリでは、新しい SQL コマンドで驚くことはありません。 どちらの方法も機能し、両方のアプローチをテスト可能なままです。
ジェネリックと EF4 ObjectContext API を使用して、IRepository<T> インターフェイスの単一の実装を簡単に提供できます。
public class SqlRepository<T> : IRepository<T>
where T : class, IEntity {
public SqlRepository(ObjectContext context) {
_objectSet = context.CreateObjectSet<T>();
}
public IQueryable<T> FindAll() {
return _objectSet;
}
public IQueryable<T> FindWhere(
Expression<Func\<T, bool>> predicate) {
return _objectSet.Where(predicate);
}
public T FindById(int id) {
return _objectSet.Single(o => o.Id == id);
}
public void Add(T newEntity) {
_objectSet.AddObject(newEntity);
}
public void Remove(T entity) {
_objectSet.DeleteObject(entity);
}
protected ObjectSet<T> _objectSet;
}
IRepository<T> アプローチを使用すると、クライアントがエンティティに到達するためにメソッドを呼び出す必要があるため、クエリをさらに制御できます。 メソッド内では、アプリケーションの制約を適用するための追加のチェックと LINQ 演算子を提供できます。 インターフェイスにはジェネリック型パラメーターに対する 2 つの制約があることに注意してください。 1 つ目の制約は ObjectSet<T> で必要なクラスの短所です。2 番目の制約では、アプリケーション用に作成された抽象化である IEntity をエンティティに強制的に実装します。 IEntity インターフェイスは、エンティティに読み取り可能な ID プロパティを強制的に設定し、FindById メソッドでこのプロパティを使用できます。 IEntity は、次のコードで定義されます。
public interface IEntity {
int Id { get; }
}
エンティティがこのインターフェイスを実装する必要があるため、IEntity は永続性の無視という考え方に対する小さな違反と見なされる可能性があります。 永続化を意識しない設計はトレードオフの問題であり、多くの場合、FindById機能がインターフェースによる制約を上回る重要性を持ちます。 インターフェイスは、テスト容易性に影響しません。
ライブ IRepository<T> をインスタンス化するには EF4 ObjectContext が必要であるため、具体的な作業単位の実装でインスタンス化を管理する必要があります。
public class SqlUnitOfWork : IUnitOfWork {
public SqlUnitOfWork() {
var connectionString =
ConfigurationManager
.ConnectionStrings[ConnectionStringName]
.ConnectionString;
_context = new ObjectContext(connectionString);
_context.ContextOptions.LazyLoadingEnabled = true;
}
public IRepository<Employee> Employees {
get {
if (_employees == null) {
_employees = new SqlRepository<Employee>(_context);
}
return _employees;
}
}
public IRepository<TimeCard> TimeCards {
get {
if (_timeCards == null) {
_timeCards = new SqlRepository<TimeCard>(_context);
}
return _timeCards;
}
}
public void Commit() {
_context.SaveChanges();
}
SqlRepository<Employee> _employees = null;
SqlRepository<TimeCard> _timeCards = null;
readonly ObjectContext _context;
const string ConnectionStringName = "EmployeeDataModelContainer";
}
カスタム リポジトリの使用
カスタム リポジトリの使用は、IObjectSet<T> に基づくリポジトリの使用と大きく変わっていません。 LINQ 演算子をプロパティに直接適用する代わりに、最初にリポジトリのメソッドを呼び出して IQueryable<T> 参照を取得する必要があります。
public ViewResult Index() {
var model = _repository.FindAll()
.Include("TimeCards")
.OrderBy(e => e.HireDate);
return View(model);
}
前に実装したカスタム Include 演算子は変更なしで動作します。 リポジトリの FindById メソッドは、1 つのエンティティを取得しようとしているアクションから重複したロジックを削除します。
public ViewResult Details(int id) {
var model = _repository.FindById(id);
return View(model);
}
調査した 2 つのアプローチのテスト可能性に大きな違いはありません。 前のセクションで行ったように、HashSet<Employee> によってサポートされる具象クラスを構築することで、IRepository<T> の偽の実装を提供できます。 ただし、一部の開発者は、偽物を構築する代わりにモック オブジェクトとモック オブジェクト フレームワークを使用することを好みます。 モックを使用して実装をテストし、次のセクションでモックと偽物の違いについて説明します。
モックを使用したテスト
Martin Fowler が "テスト ダブル" と呼ぶものを構築するには、さまざまな方法があります。 テスト ダブル (映画スタント ダブルなど) は、テスト中に実際の実稼働オブジェクトに対して "スタンドイン" するために構築するオブジェクトです。 作成したメモリ内リポジトリは、SQL Server と通信するリポジトリのテスト ダブルです。 単体テスト中にこれらの test-doubles を使用してコードを分離し、テストを高速に実行し続ける方法を見てきました。
構築したテストダブルには、実際に動作する実装があります。 バックグラウンドでは、それぞれがオブジェクトの具体的なコレクションを格納し、テスト中にリポジトリを操作する際に、このコレクションのオブジェクトを追加および削除します。 一部の開発者は、実際のコードと動作する実装を使用して、テストをこのように 2 倍にしたいと考えています。 これらのテストダブルは、我々が フェイクと呼ぶものです. 実際の実装はありますが、運用環境で使用するのに十分ではありません。 偽のリポジトリは、実際にはデータベースに書き込まれません。 偽の SMTP サーバーは、実際にはネットワーク経由で電子メール メッセージを送信しません。
モックとフェイク
モックと呼ばれる別の種類のテスト ダブルがあります。 偽物は動作する実装を持ちますが、モックには実装はありません。 モック オブジェクト フレームワークの助けを借りて、実行時にこれらのモック オブジェクトを構築し、それらをテスト ダブルとして使用します。 このセクションでは、オープン ソースのモック フレームワーク Moq を使用します。 Moq を使用して従業員リポジトリのテスト ダブルを動的に作成する簡単な例を次に示します。
Mock<IRepository<Employee>> mock =
new Mock<IRepository<Employee>>();
IRepository<Employee> repository = mock.Object;
repository.Add(new Employee());
var employee = repository.FindById(1);
Moq に IRepository<Employee> 実装を依頼し、動的にビルドします。 Mock<T> オブジェクトの Object プロパティにアクセスすることで、IRepository<Employee> を実装するオブジェクトにアクセスできます。 これはコントローラーに渡すことができるこの内部オブジェクトであり、これがテスト ダブルか実際のリポジトリかわかりません。 実際の実装を使用してオブジェクトのメソッドを呼び出すのと同様に、オブジェクトのメソッドを呼び出すことができます。
Add メソッドを呼び出すときにモック リポジトリが何をするのか疑問に思う必要があります。 モック オブジェクトの背後には実装がないため、Add では何も行われません。 私たちが書いた偽物と同じように、背後には具体的なコレクションがないので、従業員は破棄されます。 FindById の戻り値はどうですか? この場合、モック オブジェクトは実行できる唯一の処理を実行します。これは既定値を返します。 参照型 (Employee) を返しているため、戻り値は null 値です。
モックは無価値に聞こえるかもしれません。ただし、まだ説明していないモックには、さらに 2 つの機能があります。 まず、Moq フレームワークはモック オブジェクトに対して行われたすべての呼び出しを記録します。 コードの後半で、誰かが Add メソッドを呼び出したかどうか、または誰かが FindById メソッドを呼び出したかどうかを Moq に尋ねることができます。 この "ブラック ボックス" 記録機能をテストで使用する方法については、後で説明します。
2 つ目の優れた機能は、Moq を使用して期待に応じてモック オブジェクトをプログラムする方法 です。 期待値は、特定の相互作用に応答する方法をモック オブジェクトに指示します。 たとえば、モックに期待値をプログラムし、誰かが FindById を呼び出したときに従業員オブジェクトを返すように指示できます。 Moq フレームワークでは、Setup API とラムダ式を使用して、これらの期待値をプログラムします。
[TestMethod]
public void MockSample() {
Mock<IRepository<Employee>> mock =
new Mock<IRepository<Employee>>();
mock.Setup(m => m.FindById(5))
.Returns(new Employee {Id = 5});
IRepository<Employee> repository = mock.Object;
var employee = repository.FindById(5);
Assert.IsTrue(employee.Id == 5);
}
このサンプルでは、Moq にリポジトリを動的に構築するよう依頼し、期待に応じてリポジトリをプログラミングします。 この期待値は、値 5 を渡す FindById メソッドを呼び出したときに ID 値が 5 の新しい従業員オブジェクトを返すようにモック オブジェクトに指示します。 このテストは成功し、偽の IRepository<T> への完全な実装を構築する必要はありませんでした。
前に記述したテストを見直し、偽物の代わりにモックを使用するように作り直しましょう。 前と同様に、基本クラスを使用して、すべてのコントローラーのテストに必要なインフラストラクチャの一般的な部分を設定します。
public class EmployeeControllerTestBase {
public EmployeeControllerTestBase() {
_employeeData = EmployeeObjectMother.CreateEmployees()
.AsQueryable();
_repository = new Mock<IRepository<Employee>>();
_unitOfWork = new Mock<IUnitOfWork>();
_unitOfWork.Setup(u => u.Employees)
.Returns(_repository.Object);
_controller = new EmployeeController(_unitOfWork.Object);
}
protected IQueryable<Employee> _employeeData;
protected Mock<IUnitOfWork> _unitOfWork;
protected EmployeeController _controller;
protected Mock<IRepository<Employee>> _repository;
}
セットアップ コードはほとんど同じです。 偽物を使用する代わりに、Moq を使用してモック オブジェクトを作成します。 基本クラスは、コードが Employees プロパティを呼び出すときにモック リポジトリを返すようにモック作業単位を配置します。 モックセットアップの残りの部分は、各特定のシナリオ専用のテストフィクスチャ内で行われます。 たとえば、Index アクションのテスト フィクスチャは、アクションがモック リポジトリの FindAll メソッドを呼び出すときに従業員のリストを返すようにモック リポジトリを設定します。
[TestClass]
public class EmployeeControllerIndexActionTests
: EmployeeControllerTestBase {
public EmployeeControllerIndexActionTests() {
_repository.Setup(r => r.FindAll())
.Returns(_employeeData);
}
// .. tests
[TestMethod]
public void ShouldBuildModelWithAllEmployees() {
var result = _controller.Index();
var model = result.ViewData.Model
as IEnumerable<Employee>;
Assert.IsTrue(model.Count() == _employeeData.Count());
}
// .. and more tests
}
期待を除いて、テストは以前のテストと似ています。 ただし、モック フレームワークの記録機能を使用すると、別の角度からテストにアプローチできます。 この新しいパースペクティブは、次のセクションで見ていきます。
状態と相互作用のテスト
モック オブジェクトを使用してソフトウェアをテストするために使用できるさまざまな手法があります。 1 つのアプローチは、状態ベースのテストを使用することです。これは、このホワイト ペーパーでこれまでに行ってきたものです。 状態ベースのテストでは、ソフトウェアの状態に関するアサーションが作成されます。 最後のテストでは、コントローラーでアクション メソッドを呼び出し、構築する必要があるモデルに関するアサーションを作成しました。 状態のテストの他の例を次に示します。
- Create の実行後に、リポジトリに新しい従業員オブジェクトが含まれていることを確認します。
- インデックスの実行後に、モデルにすべての従業員の一覧が保持されていることを確認します。
- Delete の実行後に、リポジトリに特定の従業員が含まれていないかどうかを確認します。
モックオブジェクトで見られる別のアプローチは、相互作用を検証することです。 状態ベースのテストではオブジェクトの状態に関するアサーションが作成されますが、相互作用ベースのテストでは、オブジェクトの相互作用に関するアサーションが作成されます。 例えば次が挙げられます。
- Create の実行時に、コントローラーによってリポジトリの Add メソッドが呼び出されることを確認します。
- インデックスの実行時に、コントローラーがリポジトリの FindAll メソッドを呼び出すかどうかを確認します。
- コントローラーが作業単位の Commit メソッドを呼び出して、編集の実行時に変更を保存することを確認します。
多くの場合、相互作用テストでは、コレクション内を突いてカウントを確認しないため、必要なテスト データが少なくなります。 たとえば、Details アクションが正しい値でリポジトリの FindById メソッドを呼び出すことがわかっている場合、アクションはおそらく正しく動作しています。 FindById から返されるテスト データを設定しなくても、この動作を確認できます。
[TestClass]
public class EmployeeControllerDetailsActionTests
: EmployeeControllerTestBase {
// ...
[TestMethod]
public void ShouldInvokeRepositoryToFindEmployee() {
var result = _controller.Details(_detailsId);
_repository.Verify(r => r.FindById(_detailsId));
}
int _detailsId = 1;
}
上記のテスト フィクスチャで必要なセットアップは、基底クラスによって提供されるセットアップのみです。 コントローラー アクションを呼び出すと、Moq はモック リポジトリとの対話を記録します。 Moq の Verify API を使用して、コントローラーが適切な ID 値で FindById を呼び出したかどうかを Moq に確認できます。 コントローラーがメソッドを呼び出さなかった場合、または予期しないパラメーター値を使用してメソッドを呼び出した場合、Verify メソッドは例外をスローし、テストは失敗します。
作成アクションが現在の作業単位で Commit を呼び出すのを確認する別の例を次に示します。
[TestMethod]
public void ShouldCommitUnitOfWork() {
_controller.Create(_newEmployee);
_unitOfWork.Verify(u => u.Commit());
}
相互作用テストの危険の 1 つは、相互作用を指定し過ぎる傾向です。 モック オブジェクトがモック オブジェクトとのすべての相互作用を記録および検証する機能は、テストですべての操作を検証しようとする必要があることを意味するわけではありません。 一部の相互作用は実装の詳細であり、現在のテストを満たすために 必要な 相互作用のみを確認する必要があります。
モックまたは偽物の選択は、テストするシステムと個人 (またはチーム) の好みによって大きく異なります。 モックオブジェクトを使用すると、テストダブルを実装するために必要なコードの量を大幅に減らすことができますが、誰もが期待値を設定してやり取りを検証できるわけではありません。
まとめ
このホワイト ペーパーでは、データの永続化に ADO.NET Entity Framework を使用しながら、テスト可能なコードを作成するためのいくつかの方法を示しました。 IObjectSet<T> などの組み込みの抽象化を利用したり、IRepository<T> などの独自の抽象化を作成したりすることもできます。 どちらの場合も、ADO.NET Entity Framework 4.0 の POCO サポートにより、これらの抽象化の利用者はデータ永続化に関する無知を保ち、テスト容易性が高くなります。 暗黙的な遅延読み込みなどの追加の EF4 機能を使用すると、リレーショナル データ ストアの詳細を気にすることなく、ビジネス およびアプリケーション サービス コードを機能できます。 最後に、作成する抽象化は単体テスト内で簡単にモックまたは偽物を作成でき、これらのテスト ダブルを使用して、高速実行、高度に分離された、信頼性の高いテストを実現できます。
その他のリソース
- Martin Fowler、エンタープライズ アプリケーション アーキテクチャのパターンからパターンのカタログ
- グリフィン・カプリオ、「依存性注入」
- データ プログラミング ブログ「 チュートリアル: Entity Framework 4.0 を使用したテスト 駆動開発」。
- データ プログラミング ブログ「 Entity Framework 4.0 でのリポジトリと作業単位パターンの使用」
- アーロン・ジェンセン「 機械仕様の紹介」
- Eric Lee、" BDD with MSTest"
- Eric Evans、" ドメイン駆動設計"
- Martin Fowler、" モックはスタブではありません"
- Martin Fowler、" Test Double"
- Moq
伝記
Scott Allen は Pluralsight の技術スタッフのメンバーであり、OdeToCode.com の創設者です。 15年間の商用ソフトウェア開発において、Scottは8ビットの組み込みデバイスから拡張性の高い ASP.NET Webアプリケーションまで、あらゆるソリューションに取り組んでいます。 Scott は、OdeToCode のブログ、または Twitter の https://twitter.com/OdeToCode でアクセスできます。
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET