スターター プールを使用すると、Fabric で Spark セッションを高速に起動できます。 各実行で完全なクラスター プロビジョニングを待つ代わりに、Spark の作業をすばやく開始できます。
スターター プールは中ノードを使用し、ワークロードの需要に基づく自動スケールをサポートします。 既定の制限と上限は、Fabric の容量 SKU によって異なります。
[前提条件]
スターター プールをカスタマイズするには、ワークスペースの 管理者 ロールが必要です。
スターター プールの設定について
ワークスペースの設定では、次のスターター プール コントロールを構成できます。
- 自動スケール: 有効にすると、Apache Spark プールはアクティビティに基づいて自動的にスケールアップおよびスケールダウンされます。
- Executor を動的に割り当てる: 有効にすると、Spark はワークロードの需要に基づいて Executor を割り当てて解放します。
どちらのオプションも既定で有効になっています。 スライダーを使用して、ワークロードに対して構成されている制限を増減します。
スターター プールの設定を構成する
ワークスペースに関連付けられているスターター プールを管理するには:
ワークスペースに移動し、[ワークスペースの 設定] を選択します。
![[ワークスペースの設定] メニューで [データ エンジニアリング] を選択する場所を示すスクリーンショット。](media/configure-starter-pools/data-engineering-menu.png)
左側のウィンドウで [データ エンジニアリング/サイエンス ] を展開し、[ Spark の設定] を選択します。
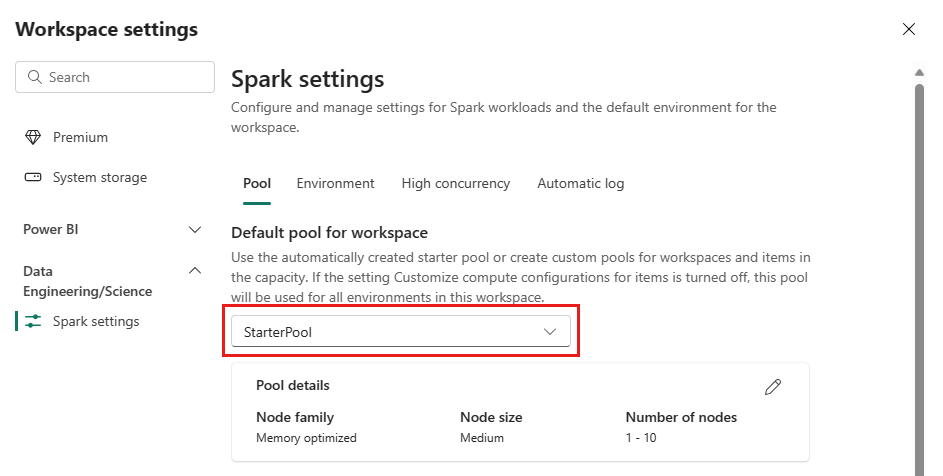
[ワークスペースの既定のプール] ドロップダウンから [StarterPool] を選択して、スターター プールの設定の概要を表示します。
[ プールの詳細 ] セクションで鉛筆アイコンを選択して、スターター プールの設定を編集します。
編集ビューで、 自動スケール を構成し、 Executor を動的に割り当てます。
スライダーを使用して、ワークロードのニーズに基づいて各設定を増減します。
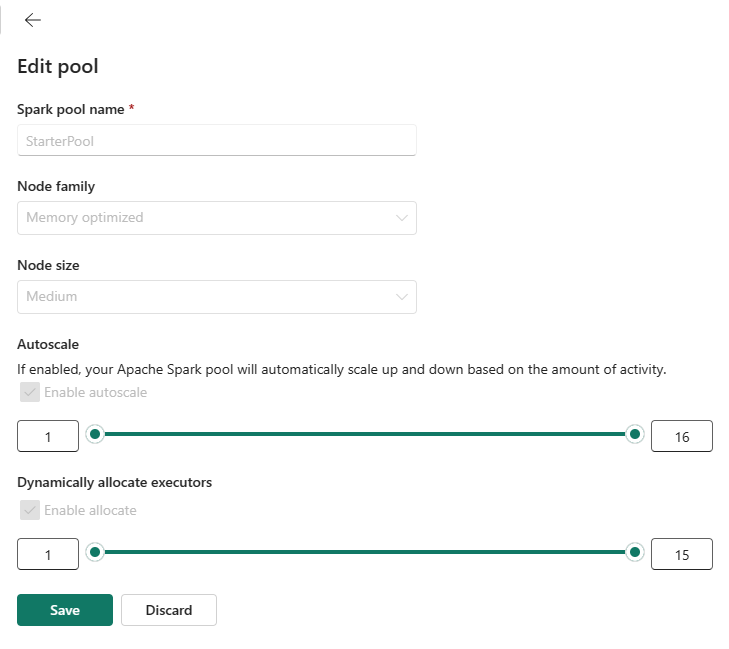
既定値をそのまま使用するか、小規模なワークロードの制限を減らすことができます。 また、SKU で許可されている最大値まで値を増やすこともできます。
変更を行った後、[ 保存] を選択してスターター プールの新しい設定を適用するか、[ 破棄 ] を選択して変更を破棄します。 それ以外の場合は、戻る矢印を選択して、変更を保存または破棄せずに終了できます。
![[ワークスペースの設定] メニューで [データ エンジニアリング] を選択する場所を示すスクリーンショット。](media/configure-starter-pools/data-engineering-menu.png#lightbox)


次の表は、SKU ごとの既定のスターター プール ノードと最大スターター プール ノードの制限を示しています。
| SKU 名 | 容量ユニット | Spark vCore | ノード サイズ | 既定の最大ノード | ノードの最大数 |
|---|---|---|---|---|---|
| F2 | 2 | 4 | ミディアム | 1 | 1 |
| F4 | 4 | 8 | ミディアム | 1 | 1 |
| F8 | 8 | 16 | ミディアム | 2 | 2 |
| F16 | 16 | 32 | ミディアム | 3 | 4 |
| F32 | 32 | 64 | ミディアム | 8 | 8 |
| F64 | 64 | 128 | ミディアム | 10 | 16 |
| (試用版の容量) | 64 | 128 | ミディアム | 10 | 16 |
| F128 | 128 | 256 | ミディアム | 10 | 32 |
| F256 | 256 | 512 | ミディアム | 10 | 64 |
| F512 | 512 | 1024 | ミディアム | 10 | 128 |
| F1024 | 1024 | 2048 | ミディアム | 10 | 200 |
| F2048 | 2048 | 4096 | ミディアム | 10 | 200 |
関連するコンテンツ
- 詳細については、Apache Spark パブリック ドキュメントを参照してください。
- Microsoft Fabric での
0>Spark ワークスペースの管理設定の概要。