カスタム Spark プールを使用して、Fabric のワークロードに合わせてコンピューティングを調整します。 ノード サイズの選択、自動スケール動作の構成、動的な Executor の割り当てを有効にすることができます。
カスタム プールは、ワークロードの需要に合わせてスケーリング制限を設定できるようにすることで、パフォーマンスとコストのバランスを取るのに役立ちます。
注
カスタム Spark プールは、ライブラリの発行にフル モードを使用する環境で カスタム ライブ プール として構成されている場合、約 5 秒のセッション開始を実現できます。 ライブ プールの構成がない場合、カスタム Spark プールの起動には約 3 分かかります。
スターター プールを既に使用している場合、特定のワークロードのサイズ設定とスケーリング動作をより細かく制御する必要がある場合、カスタム プールは補完的なオプションです。 起動と既定の設定を高速に行うためにスターター プールを使用し、ワークロード固有のコンピューティング チューニングが必要な場合はカスタム プールに移動します。 スターター プールの詳細については、「 Fabric でスターター プールを構成する」を参照してください。
[前提条件]
カスタム Spark プールを作成するには:
- ワークスペースに 管理者 ロールが必要です。
- 容量管理者は、容量の Spark コンピューティング設定でカスタマイズされたワークスペース プールを有効にする必要があります。
詳細については、「 Fabric 容量のデータ エンジニアリングとデータ サイエンスの設定を構成および管理する」を参照してください。
カスタム Spark プールを作成する
ワークスペースに関連付けられている Spark プールを作成または管理するには:
ワークスペースに移動し、[ワークスペースの 設定] を選択します。
![[ワークスペースの設定] メニューで [データ エンジニアリング] を選択する場所を示すスクリーンショット。](media/configure-starter-pools/data-engineering-menu.png)
データ エンジニアリング/サイエンス オプションを選択してメニューを展開し、Spark 設定を選択します。
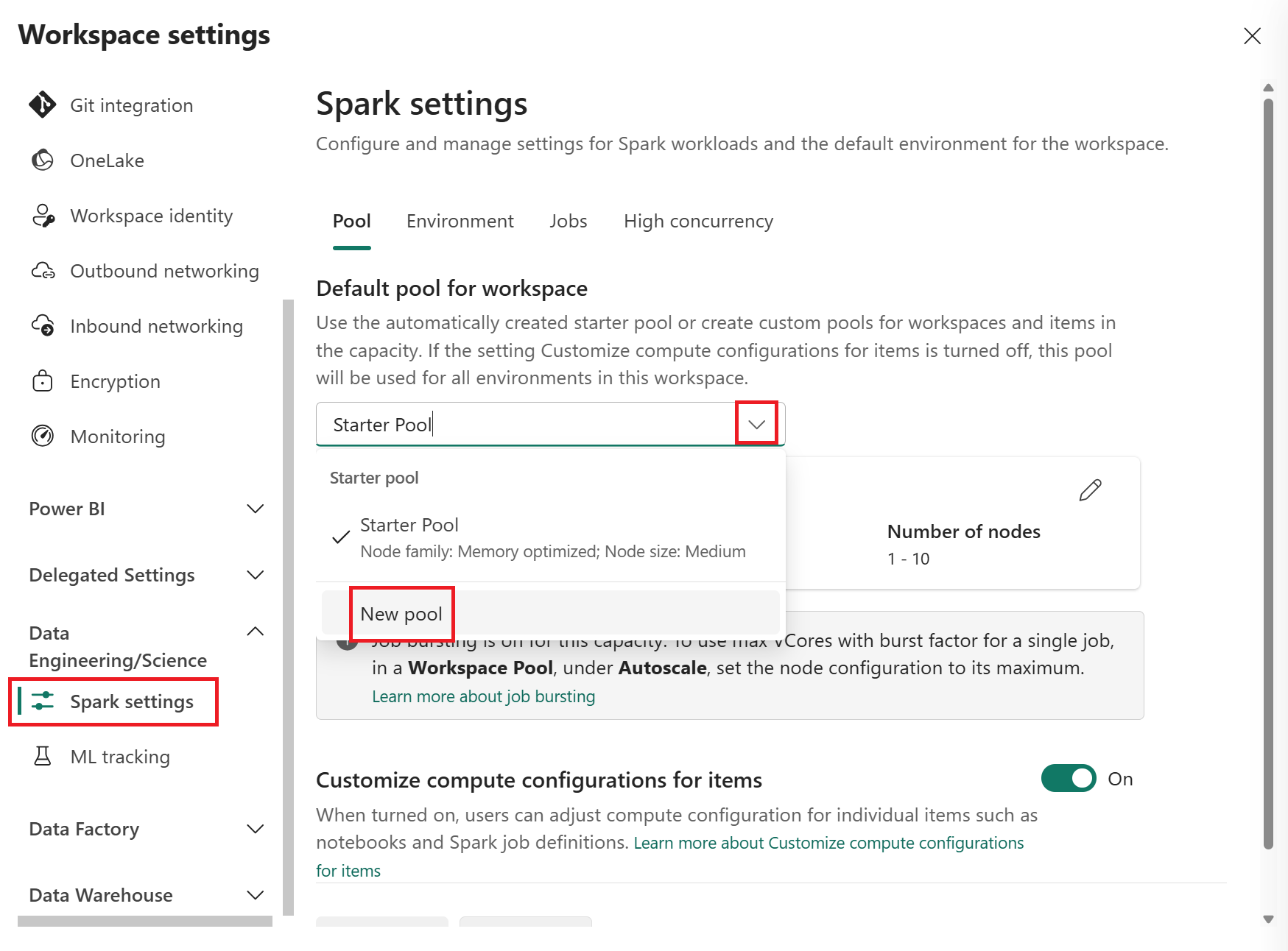
[ワークスペースの既定のプール] ドロップダウンから [新しいプール] を選択して、新しいカスタム Spark プールを作成します。 複数のカスタム プールを作成し、ワークスペースの既定のプールとしていずれかを選択できます。
[ 新しいプールの作成 ] ページで、プール名を入力します。 ワークロードの要件に基づいて 、ノード ファミリ ( メモリ最適化など) と ノード サイズ を選択します。 ノード サイズの詳細については、以下の 「ノード サイズ オプション 」セクションを参照してください。
ヒント
ノード サイズは、各ノードに割り当てられたコンピューティング容量を表す容量 ユニット (CU) によって決まります。
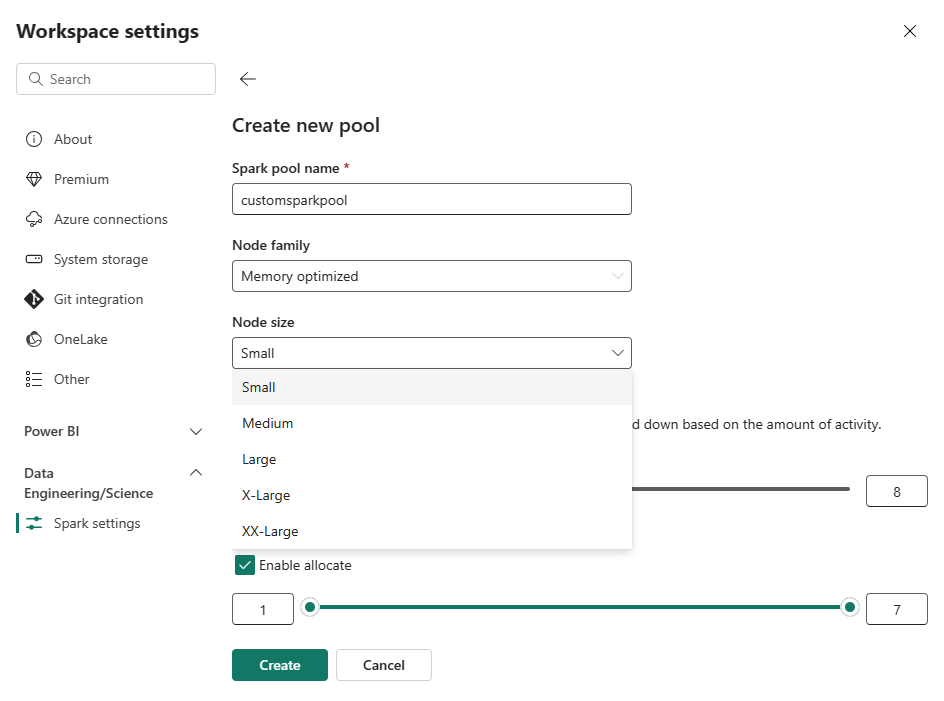
編集ビューで、 自動スケール を構成し、 Executor を動的に割り当てます。

スライダーを使用して、ワークロードのニーズに基づいて各設定を増減します。
自動スケールが有効になっている場合、プールは、アクティビティに基づいて構成された最小ノード値と最大ノード値の間でスケーリングされます。
Executor を動的に割り当てるが有効になっている場合、Fabric は構成された境界内のワークロードの需要に基づいて Executor の割り当てを調整します。
を選択してを作成します。
![[ワークスペースの設定] メニューで [データ エンジニアリング] を選択する場所を示すスクリーンショット。](media/configure-starter-pools/data-engineering-menu.png#lightbox)



ヒント
カスタム Spark プールを作成した後、ライブラリのデプロイのタイミングは、アタッチされた環境の発行モードによって異なります。 クイック モードでは、約 5 秒で発行され、セッション開始時にライブラリがインストールされます。 フル モードでは、セッションの起動の一環としてライブラリを発行してデプロイするのに 3 ~ 6 分かかります (1 ~ 3 分)。 最速のエクスペリエンスを得るには、約 5 秒のセッション開始を実現するために、フル モードの カスタム ライブ プール としてプールを構成します。
カスタム プールには、非アクティブ状態から 2 分後の既定の自動一時停止期間があります。自動一時停止に達すると、セッションの有効期限が切れ、クラスターの割り当てが解除されます。 課金は、コンピューティングがアクティブに使用されている間にのみ適用されます。 Microsoft Fabricのカスタム Spark プールでは現在、ノードの上限 200 がサポートされているため、自動スケールの最小値と最大値がこの制限内に留まるようにしてください。
ノード サイズ オプション
カスタム Spark プールを設定するときは、次のノード サイズから選択します。
| ノード サイズ | vCores | メモリ (GB) | 説明 |
|---|---|---|---|
| 小さい | 4 | 32 | 軽量な開発およびテスト作業のために。 |
| ミディアム | 8 | 64 | 一般的なワークロードや通常の操作の場合。 |
| 大きい | 16 | 128 | メモリを集中的に使用するタスクまたは大規模なデータ処理ジョブの場合。 |
| X-Large | 32 | 256 | 重要なリソースを必要とする最も要求の厳しい Spark ワークロードの場合。 |
| XXLサイズ | 64 | 512 | ノードあたり最高のコンピューティングとメモリを必要とする最大の Spark ワークロードの場合。 |
関連コンテンツ
- 詳細については、Apache Spark パブリック ドキュメントを参照してください。
- Microsoft Fabric での Spark ワークスペース管理設定を始めよう。
- Fabric 環境でライブラリを管理する