注記
Apache Airflow ジョブは、Apache Airflow を使用しています。
このチュートリアルでは、データ パイプラインを調整するための Azure Databricks と Apache Airflow ジョブ (Apache Airflow を搭載) の統合の概要について説明します。 ジョブ オーケストレーションは、複雑なワークフローを管理し、データの精度を確保し、処理効率を最適化するために不可欠です。 Azure Databricks は Apache Spark 上に構築された強力な分析プラットフォームであるのに対し、Apache Airflow は堅牢なワークフロー管理機能を提供します。 これらのツールを組み合わせることで、データ インジェストから変換と分析まで、タスクをシームレスに調整できます。 Apache Airflow Azure Databricks 接続を使用すると、Azure Databricks によって提供される最適化された Spark エンジンを使用して、Apache Airflow のスケジュール機能を利用できます。
このチュートリアルでは、Apache Airflow DAG を構築して、Apache Airflow ジョブで Azure Databricks ジョブをトリガーします。
前提条件
開始するには、次の前提条件を満たしている必要があります。
Apache Airflow の要件を追加する
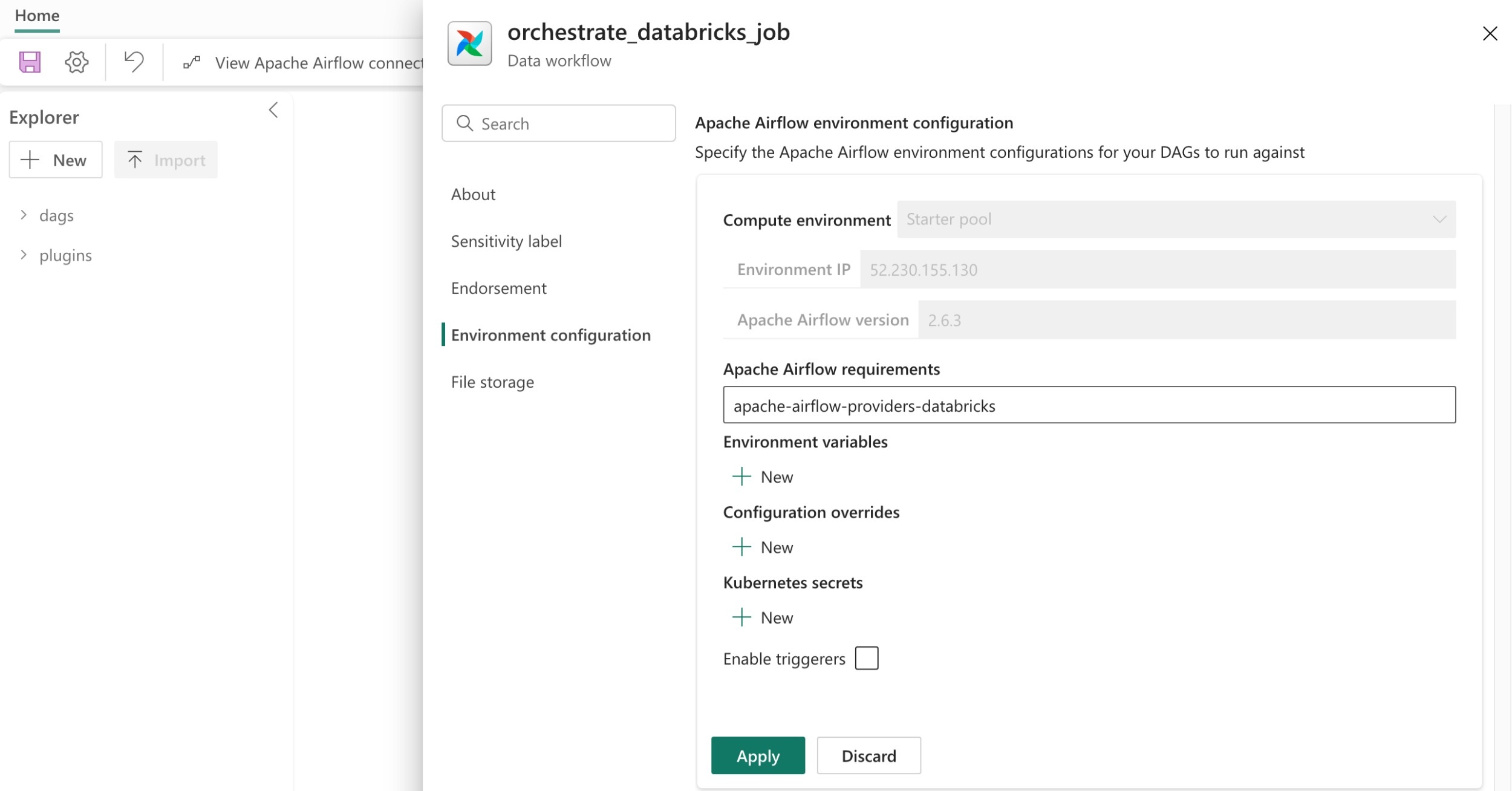
[設定] に移動し、[環境の構成] を選択します。
[Apache Airflow 要件] で、[apache-airflow-providers-databricks]を追加します。
[適用] を選択して、変更を保存します。

Apache Airflow 接続用の Azure Databricks 個人用アクセス トークンを作成する
- Azure Databricks ワークスペースの上部バーで、目的の Azure Databricks ユーザー名を選択し、次にドロップダウンから [設定] を選択します。
- [開発者モード] を選択します。
- 次に、[アクセス トークン] の横にある [管理] を選択します。
- [新しいトークンの生成] を選択します。
- (省略可能) 将来このトークンを識別するのに役立つコメントを入力し、トークンの既定の有効期間 90 日を変更します。 有効期間のないトークンを作成するには (推奨されません)、[有効期間 (日)] ボックスを空のままにします。
- 生成を選択します。
- 表示されたトークンを安全な場所にコピーし、[完了] を選択します。
Apache Airflow の接続を作成して、Azure Databricks ワークスペースに接続する
Apache Airflow ジョブ環境の要件として "apache-airflow-providers-databricks" をインストールすると、Azure Databricks に対する既定の接続が Apache Airflow の接続の一覧に既定で構成されます。 接続を更新して、既に作成した個人用アクセス トークンを使用してワークスペースに接続するには、次の手順を実行します。
[Airflow 接続の表示] を選択して、構成されているすべての接続の一覧を表示します。
[CONN ID] で databricks_default を見つけて、[レコードの編集] ボタンを選択します。
[Host] (ホスト) フィールドの値を、Azure Databricks の展開のワークスペース インスタンス名に置き換えます (例:
https://adb-123456789.cloud.databricks.com)。[Password] (パスワード) フィールドに、Azure Databricks の個人用アクセス トークンを入力します。
[保存] を選択します。

Apache Airflow DAG を作成する
まず、[新しい DAG ファイル] カードを選択します。 ファイルに名前を付け、[作成] を選択します。
作成されると、定型 DAG コードが表示されます。 ファイルを編集して、指定された内容を含めます。 引数
job_idをAzure Databricks ジョブ ID で更新します。
from airflow import DAG
from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'airflow'
}
with DAG('databricks_dag',
start_date = days_ago(2),
schedule_interval = "@hourly",
default_args = default_args
) as dag:
transform_data = DatabricksRunNowOperator(
task_id = 'transform_data',
databricks_conn_id = 'databricks_default',
job_id ="<JOB_ID>>"
)
[保存] を選んでファイルを保存します。

Apache Airflow DAG を監視し、Apache Airflow UI から実行する
保存すると、Apache Airflow UI にDAG ファイルが自動的に読み込まれます。 それらを監視するには、[Apache Airflow で監視] ボタンを選択します。