このチュートリアルでは、Microsoft Fabric の Synapse Data Science ワークフローのエンド ツー エンドの例を示します。 このシナリオでは、銀行の顧客離れを予測するモデルを構築します。 離反率(離反率)には、銀行の顧客が銀行との取引を終了するレートが含まれます。
このチュートリアルでは、次の手順について説明します。
- カスタム ライブラリをインストールする
- データを読み込む
- 探索的データ分析を通じてデータを理解して処理し、Fabric Data Wrangler 機能の使用を示す
- scikit-learn と LightGBM を使用して機械学習モデルをトレーニングし、MLflow と Fabric の自動ログ機能を使用して実験を追跡する
- 最終的な機械学習モデルを評価して保存する
- Power BI の視覚エフェクトを使用してモデルのパフォーマンスを表示する
前提 条件
Microsoft Fabric サブスクリプションを取得します。 または、無料の Microsoft Fabric 試用版 にサインアップする。
Microsoft Fabric にサインインします。
ホーム ページの左下にあるエクスペリエンス スイッチャーを使用して、Fabric に切り替えます。
- 必要に応じて、「Microsoft Fabric でレイクハウスを作成する」の説明に従って、Microsoft Fabric レイクハウスを作成します。
ノートブックで作業を進める
ノートブックで使うためのオプションとして、次のいずれかを選択できます。
- 組み込みのノートブックを開いて実行します。
- GitHub からノートブックをアップロードします。
組み込みのノートブックを開く
サンプルの Customer churn ノートブックは、このチュートリアルに付属しています。
このチュートリアルのサンプルノートブックを開くには、「データサイエンスのチュートリアル用にシステムを準備する」の指示に従ってください。
コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
GitHub からノートブックをインポートする
このチュートリアルには、AIsample - Bank Customer Churn.ipynb ノートブックが付属しています。
このチュートリアルの付属のノートブックを開くには、「データ サイエンス用にシステムを準備する」の手順に従って、ノートブックをワークスペースにインポート します。
このページからコードをコピーして貼り付ける場合は、新しいノートブックを作成することができます。
コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
手順 1: カスタム ライブラリをインストールする
機械学習モデルの開発やアドホック データ分析の場合は、Apache Spark セッション用のカスタム ライブラリをすばやくインストールすることが必要になる場合があります。 ライブラリをインストールするには、2 つのオプションがあります。
- ノートブックのインライン インストール機能 (
%pipまたは%conda) を使用して、現在のノートブックにのみライブラリをインストールします。 - または、ファブリック環境を作成したり、パブリック ソースからライブラリをインストールしたり、カスタム ライブラリをアップロードしたりして、ワークスペース管理者がワークスペースの既定として環境をアタッチすることもできます。 その後、環境内のすべてのライブラリが、ワークスペース内のすべてのノートブックと Spark ジョブ定義で使用できるようになります。 環境の詳細については、「Microsoft Fabric で環境作成、構成、および使用する」を参照してください。
このチュートリアルでは、%pip install を使用して imblearn ライブラリをノートブックにインストールします。
手記
PySpark カーネルは、%pip install の実行後に再起動します。 他のセルを実行する前に、必要なライブラリをインストールします。
# Use pip to install libraries
%pip install imblearn
手順 2: データを読み込む
churn.csv のデータセットには、10,000 人の顧客のチャーン状態と、次を含む 14 個の属性が含まれています。
- クレジット スコア
- 地理的な場所 (ドイツ、フランス、スペイン)
- 性別 (男性、女性)
- 年齢
- 在任期間 (その人がその銀行の顧客であった年数)
- 口座残高
- 推定給与
- 顧客が銀行を通じて購入した製品の数
- クレジット カードの状態 (顧客がクレジット カードを持っているかどうか)
- アクティブなメンバーの状態 (アクティブな銀行のお客様かどうか)
データセットには、行番号、顧客 ID、顧客姓の列も含まれます。 これらの列の値は、銀行を離れるという顧客の決定に影響を与えるべきではありません。
顧客の銀行口座が閉鎖されることによって、その顧客の離脱が定義されます。 データセット Exited 列は、顧客の離脱を示しています。 これらの属性に関するコンテキストはほとんどないため、データセットに関する背景情報は必要ありません。 これらの属性が Exited の状態にどのように影響するかを理解する必要があります。
この 10,000 人の顧客のうち、銀行を出たのは 2037 人 (約 20%) のみです。 クラスの不均衡率のため、合成データの生成をお勧めします。 混同行列の精度は、不均衡な分類に関連しない可能性があります。 Precision-Recall 曲線下面積 (AUPRC) を使用して精度を測定したい場合があります。
- 次の表に、
churn.csvデータのプレビューを示します。
| 顧客ID | 名字 | クレジットスコア | 地理学 | ジェンダー | 年齢 | 任期 | Balance | NumOfProducts | HasCrCard | IsActiveMember | 推定給与 | Exited |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | ハーグレイヴ | 619 | フランス | 女性 | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Hill | 608 | スペイン | 女性 | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
データセットをダウンロードして lakehouse にアップロードする
さまざまなデータセットでこのノートブックを使用できるように、これらのパラメーターを定義します。
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
このコードは、一般公開されているバージョンのデータセットをダウンロードし、そのデータセットを Fabric Lakehouse に格納します。
重要
実行する前に、ノートブックにレイクハウス を追加します。 これを行わないと、エラーが発生します。
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
ノートブックの実行に必要な時間の記録を開始します。
# Record the notebook running time
import time
ts = time.time()
レイクハウスから生データを読み取る
このコードを実行すると、レイクハウスの [ファイル] セクションから生データが読み取られるとともに、さまざまなデータ要素に列が追加されます。 パーティション分割されたデルタ テーブルの作成では、この情報が使用されます。
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
データセットから pandas DataFrame を作成する
このコードは、処理と視覚化を容易にするために、Spark DataFrame を pandas DataFrame に変換します。
df = df.toPandas()
手順 3: 探索的データ分析を実行する
生データを表示する
displayを使用して生データを探索し、いくつかの基本的な統計情報を計算し、グラフ ビューを表示します。 最初に、データ視覚化に必要なライブラリをインポートする必要があります (たとえば、seaborn)。 Seaborn は Python データ視覚化ライブラリであり、データフレームと配列にビジュアルを構築するための高度なインターフェイスを提供します。
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Data Wrangler を使用して初期データ クリーニングを実行する
ノートブックから直接 Data Wrangler を起動して、pandas データフレームを探索して変換します。 水平ツールバーから [Data Wrangler] ドロップダウンを選択して、編集に使用できるアクティブ化された pandas DataFrames を参照します。 Data Wrangler で開く DataFrame を選択します。
手記
ノートブック カーネルがビジー状態の間は、データ ラングラーを開くことができません。 Data Wrangler を起動する前に、セルの実行を完了する必要があります。 Data Wranglerの詳細を確認します。

Data Wrangler が起動すると、次の図に示すように、データ パネルの説明的な概要が生成されます。 概要には、DataFrame のディメンション、欠損値などに関する情報が含まれています。Data Wrangler を使用すると、欠損値の行、重複する行、および特定の名前の列を削除するスクリプトを生成できます。 その後、スクリプトをセルにコピーできます。 次のセルには、コピーしたスクリプトが表示されます。


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
属性を決定する
このコードは、カテゴリ、数値、およびターゲットの属性を決定します。
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
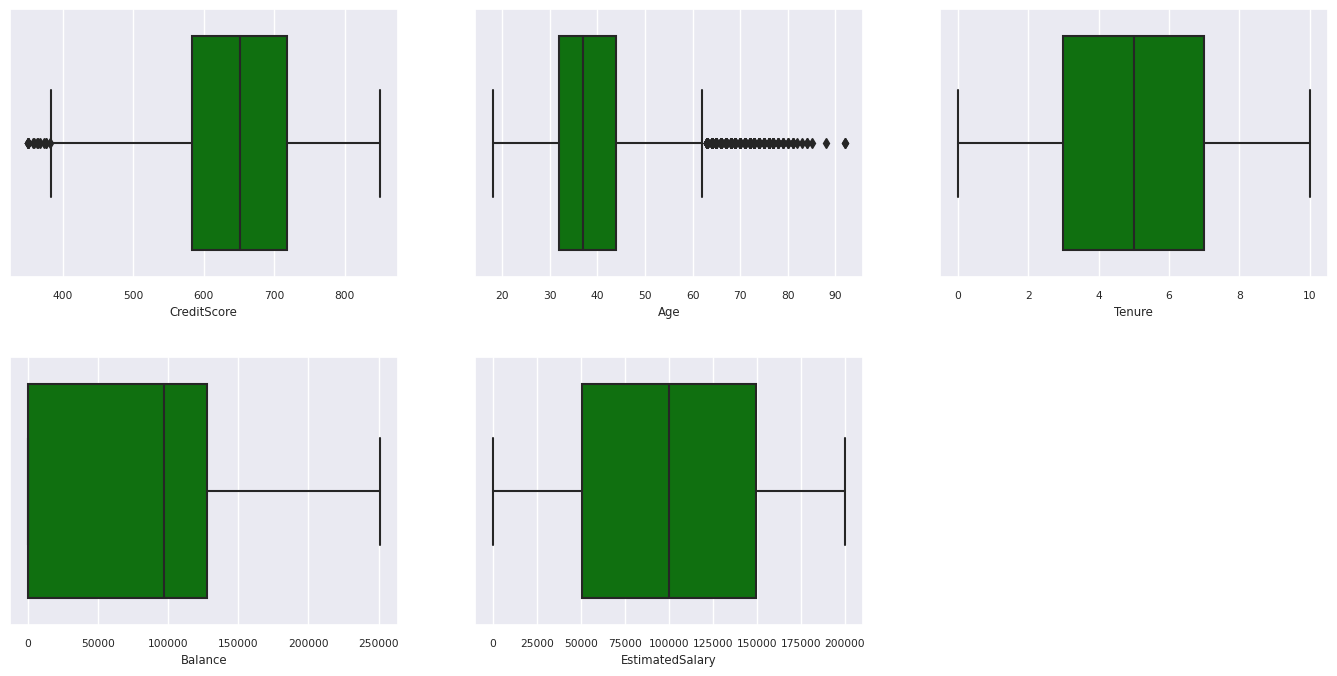
5 つの数値の概要を表示する
ボックス プロットを使用して 5 つの数値の概要を表示する
- 最低スコア
- 第 1 四分位数
- 中央値
- 第 3 四分位数
- 最大スコア
上記は、数値属性の場合です。
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
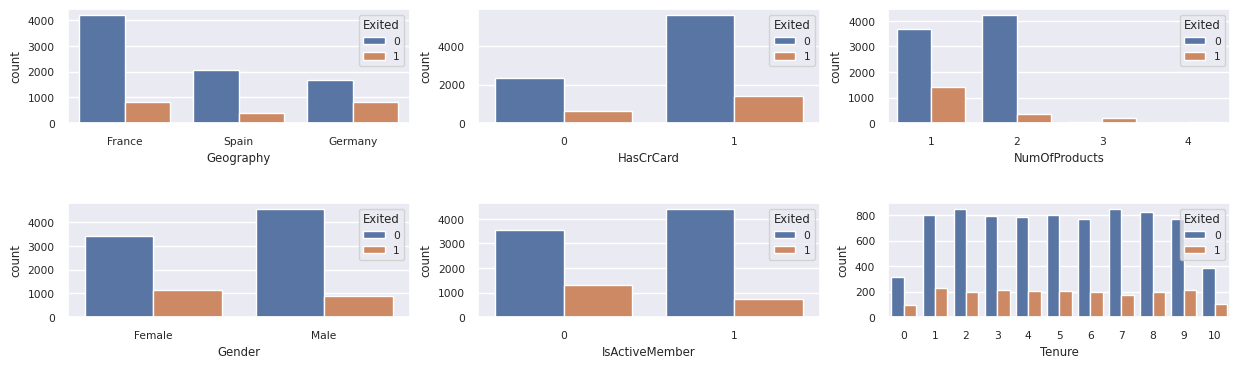
終了した顧客と未終了の顧客の分布を表示する
カテゴリ別の属性における、終了した顧客と終了していない顧客の分布を表示します。
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
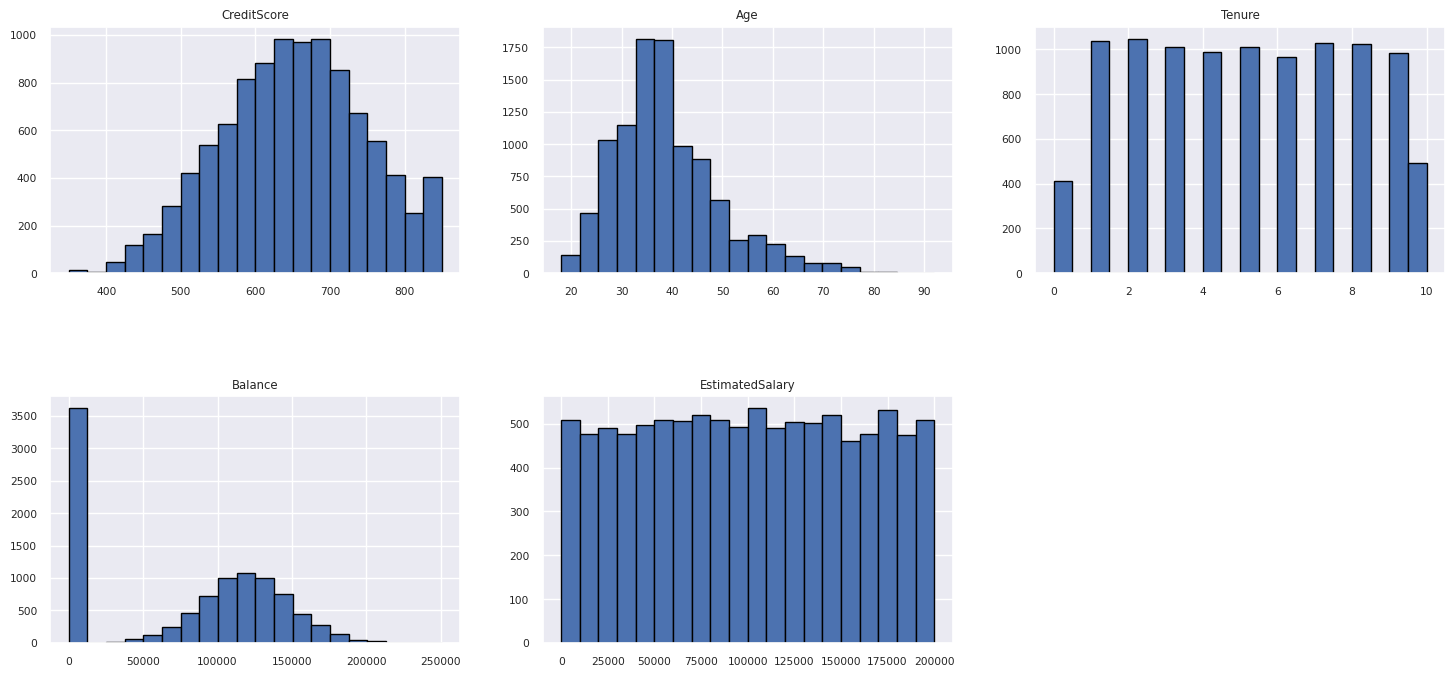
数値属性の分布を表示する
ヒストグラムを使用して、数値属性の頻度分布を表示します。
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
フィーチャーエンジニアリングを実行する
この特徴エンジニアリングでは、現在の属性に基づいて新しい属性が生成されます。
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Data Wrangler を使用してワンホット エンコードを実行する
前に説明したように、Data Wrangler を起動するのと同じ手順で、Data Wrangler を使用してワンホット エンコードを実行します。 このセルには、1 ホット エンコード用にコピーされた生成されたスクリプトが表示されます。


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
デルタ テーブルを作成して Power BI レポートを生成する
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
探索的データ分析からの観測の概要
- ほとんどのお客様はフランス出身です。 スペインは、フランスとドイツに比べてチャーン率が最も低い。
- ほとんどのお客様はクレジット カードを持っています
- 一部のお客様はどちらも 60 歳以上で、クレジット スコアが 400 未満です。 ただし、外れ値と見なすことはできません
- 2 つ以上の銀行製品を持つ顧客はごくわずかです
- 非アクティブな顧客の離反率が高い
- 性別と在職年数は、銀行口座を閉鎖する顧客の決定にほとんど影響しません
手順 4: モデルのトレーニングと追跡を実行する
データが配置された状態で、モデルを定義できるようになりました。 このノートブックでランダム フォレストと LightGBM モデルを適用します。
scikit-learn ライブラリと LightGBM ライブラリを使用して、数行のコードでモデルを実装します。 さらに、MLfLow と Fabric の自動ログ記録を使用して実験を追跡します。
このコード サンプルでは、lakehouse からデルタ テーブルを読み込みます。 レイクハウスをソースとして使用している他のデルタ テーブルを使用することができます。
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
MLflow を使用してモデルを追跡およびログ記録するための実験を生成する
このセクションでは、実験を生成する方法を示し、モデルとトレーニングのパラメーターとスコア付けメトリックを指定します。 さらに、後で使用するために、モデルをトレーニングし、ログに記録し、トレーニング済みのモデルを保存する方法も示します。
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
自動ログでは、入力パラメーターの値と機械学習モデルの出力メトリックの両方が、そのモデルのトレーニング時に自動的にキャプチャされます。 その後、この情報がワークスペースに記録され、MLflow API またはワークスペース内の対応する実験がアクセスして視覚化できます。
完了すると、実験は次の画像のようになります。

それぞれの名前を持つすべての実験がログに記録され、パラメーターとパフォーマンス メトリックを追跡できます。 自動ログ記録の詳細については、「Microsoft Fabric での自動ログ記録の」を参照してください。
実験と自動ログの仕様を設定する
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
scikit-learn と LightGBM をインポートする
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
トレーニング データセットとテスト データセットを準備する
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
トレーニング データに SMOTE を適用する
モデルが決定境界を効果的に学習するには少数派クラスの例が少なすぎるため、不均衡な分類には問題があります。 これを処理するために、合成少数派オーバーサンプリング手法 (SMOTE) は、少数派クラスの新しいサンプルを合成するために最も広く使用されている手法です。 手順 1 でインストールした imblearn ライブラリを使用して SMOTE にアクセスします。
トレーニング データセットにのみ SMOTE を適用します。 元のデータに対するモデル のパフォーマンスの有効な近似値を取得するには、テスト データセットを元の不均衡な分布のままにしておく必要があります。 この実験は、運用環境の状況を表します。
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
詳細については、SMOTE に関するページと「ランダム オーバーサンプリングから SMOTE と ADASYN へ」を参照してください。 不均衡な Learn Web サイトは、これらのリソースをホストします。
モデルをトレーニングする
ランダム フォレストを使用してモデルをトレーニングします。最大深度は 4 で、特徴は 4 つです。
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
ランダム フォレストを使用してモデルをトレーニングします。最大深度は 8 で、特徴は 6 つです。
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
LightGBM を使用してモデルをトレーニングします。
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
実験成果物を表示してモデルのパフォーマンスを追跡する
実験の実行は、実験成果物に自動的に保存されます。 ワークスペースでその成果物を見つけることができます。 アーティファクト名は、実験の設定に使用される名前に基づいています。 トレーニングされたすべてのモデル、実行、パフォーマンス メトリック、モデル パラメーターが実験ページに記録されます。
あなたの実験を表示するには:
- 左側のパネルで、ワークスペースを選択します。
- この場合は、実験名「sample-bank-churn-experiment」を見つけて選択します。
手順 5: 最終的な機械学習モデルを評価して保存する
ワークスペースから保存した実験を開き、最適なモデルを選択して保存します。
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
テスト データセットで保存されたモデルのパフォーマンスを評価する
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
混同行列を使用して真または偽の陽性/陰性を表示する
分類の精度を評価するには、混同行列をプロットするスクリプトを作成します。 不正検出のサンプルに示すように、SynapseML ツールを使用して混同行列をプロットすることもできます。
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
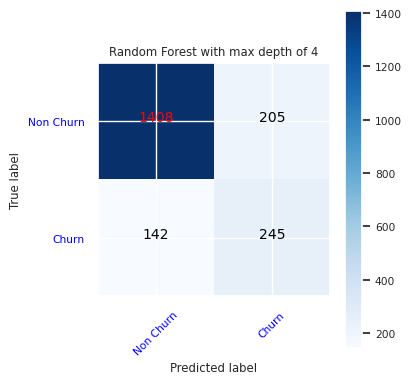
ランダム フォレスト分類子の混同行列を作成します。最大深度は 4 で、次の 4 つの特徴があります。
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
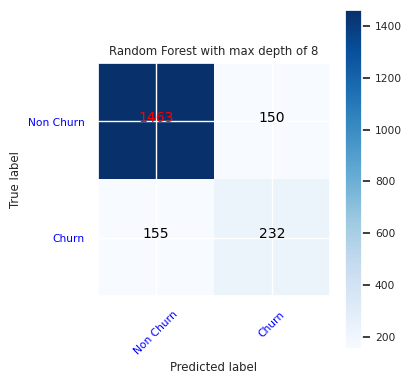
最大深度が 8 で、次の 6 つの特徴を持つランダム フォレスト分類子の混同行列を作成します。
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
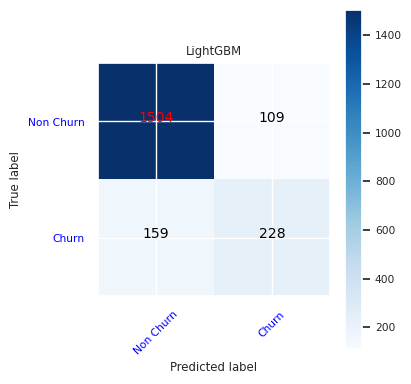
LightGBM の混同行列を作成します。
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Power BI の結果を保存する
モデルの予測結果を Power BI 視覚化に移動するには、デルタ フレームを lakehouse に保存します。
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
手順 6: Power BI で視覚エフェクトにアクセスする
Power BI で保存したテーブルにアクセスします。
- 左側で OneLakeを選択します。
- このノートブックに追加したレイクハウスを選択します。
- [このレイクハウスを開く] セクションで [開く] を選択します。
- リボンで、[新しいセマンティックモデル] を選択します。
df_pred_resultsを選択し、確認 を選択して、予測にリンクされた新しい Power BI セマンティック モデルを作成します。 - 新しいセマンティック モデルを開きます。 OneLake で見つけることができます。
- [セマンティック モデル] ページの上部にあるツールから [新しいレポート の作成] 選択して、Power BI レポートの作成ページを開きます。
次のスクリーンショットは、視覚化の例を示しています。 データ パネルには、テーブルから選択するデルタ テーブルと列が表示されます。 適切なカテゴリ (x) 軸と値 (y) 軸を選択したら、フィルターと関数 (テーブル列の合計や平均など) を選択できます。
手記
このスクリーンショットでは、Power BI で保存された予測結果の分析の例を示します。

ただし、実際の顧客離反のユース ケースでは、ユーザーは、主題の専門知識に基づいて視覚化のより完全な一連の要件を作成し、企業とビジネス分析チームと企業がメトリックとして標準化したものが必要になる場合があります。
Power BI レポートには、2 つ以上の銀行製品を使用している顧客の離反率が高いことを示しています。 ただし、2 つ以上の製品を持つ顧客はほとんどいませんでした。 (左下のパネルのプロットを参照してください)。銀行はより多くのデータを収集する必要がありますが、より多くの製品と関連する他の機能も調査する必要があります。
ドイツの銀行顧客は、フランスとスペインの顧客に比べて離反率が高くなります。 (右下のパネルのプロットを参照してください)。 レポートの結果に基づいて、顧客の退出を促した要因の調査が役立つ可能性があります。
中年のお客様が増えています (25 ~ 45)。 45歳から60歳の顧客の中には、離れる傾向が高いです。
最後に、信用スコアが低い顧客は、他の金融機関のために銀行を離れる可能性が最も高くなります。 銀行は、低いクレジット スコアと口座残高を持つ顧客が銀行に留まるよう奨励する方法を検討する必要があります。
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")