このチュートリアルでは、Microsoft Fabric の Synapse Data Science ワークフローのエンド ツー エンドの例を示します。 このシナリオでは、銀行の顧客離れを予測するモデルを構築します。 離反率(離反率)には、銀行の顧客が銀行との取引を終了するレートが含まれます。
このチュートリアルでは、次の手順について説明します。
- カスタム ライブラリをインストールする
- データを読み込む
- 探索的データ分析を通じてデータを理解して処理する
- scikit-learn と LightGBM を使用して機械学習モデルをトレーニングする
- 最終的な機械学習モデルを評価して保存する
- Power BI の視覚エフェクトを使用してモデルのパフォーマンスを表示する
前提 条件
Microsoft Fabric サブスクリプションを取得します。 または、無料の Microsoft Fabric 試用版にサインアップします。
Microsoft Fabricにサインインする。
ホーム ページの左下にあるエクスペリエンス スイッチャーを使用して、Fabric に切り替えます。
- 必要に応じて、「Microsoft Fabric でレイクハウスを作成する」に記載されている説明に従って、Microsoft Fabric のレイクハウスを作成します。
ノートブックで作業を進める
次のいずれかのオプションを選択してノートブックで作業を進めることができます。
- Synapse Data Science エクスペリエンスで組み込みのノートブックを開いて実行します。
- GitHub から Synapse Data Science エクスペリエンスにノートブックをアップロードします。
組み込みのノートブックを開く
サンプルの顧客離反ノートブックは、このチュートリアルに付属しています。
このチュートリアルのサンプルノートブックを開くには、「データサイエンス用にシステムを準備する」の手順に従ってください。
コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
GitHub からノートブックをインポートする
このチュートリアルには、AIsample - R Bank Customer Churn.ipynb ノートブックが付属しています。
このチュートリアルの付属のノートブックを開くには、「データ サイエンス用にシステムを準備する」の手順に従って、ノートブックをワークスペースにインポート します。
このページからコードをコピーして貼り付ける場合は、新しいノートブックを作成できます。
コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
手順 1: カスタム ライブラリをインストールする
機械学習モデルの開発やアドホック データ分析の場合は、Apache Spark セッション用のカスタム ライブラリをすばやくインストールすることが必要になる場合があります。 ライブラリをインストールするには、2 つのオプションがあります。
- 現在のノートブックにのみインストールするには、インライン インストール リソース (
install.packagesやdevtools::install_versionなど) を使用します。 - または、ファブリック環境を作成したり、パブリック ソースからライブラリをインストールしたり、カスタム ライブラリをアップロードしたりして、ワークスペース管理者がワークスペースの既定として環境をアタッチすることもできます。 その後、環境内のすべてのライブラリが、ワークスペース内のすべてのノートブックと Spark ジョブ定義で使用できるようになります。 環境の詳細については、「Microsoft Fabric で環境作成、構成、および使用する」を参照してください。
このチュートリアルでは、install.packages() を使用して、imbalance ライブラリと randomForest ライブラリをインストールします。 出力をより簡潔にするには、quiet を TRUE に設定します。
# Install imbalance for SMOTE
install.packages("imbalance", quiet = TRUE)
# Install the random forest algorithm
install.packages("randomForest", quiet=TRUE)
手順 2: データを読み込む
churn.csv のデータセットには、10,000 人の顧客のチャーン状態と、次を含む 14 個の属性が含まれています。
- クレジット スコア
- 地理的な場所 (ドイツ、フランス、スペイン)
- 性別 (男性、女性)
- 年齢
- 在任期間 (その人がその銀行の顧客であった年数)
- 口座残高
- 推定給与
- 顧客が銀行を通じて購入した製品の数
- クレジット カードの状態 (顧客がクレジット カードを持っているかどうか)
- アクティブなメンバーの状態 (アクティブな銀行のお客様かどうか)
データセットには、行番号、顧客 ID、顧客姓の列も含まれます。 これらの列の値は、銀行を離れるという顧客の決定に影響を与えるべきではありません。
顧客の銀行口座が閉鎖されると、その顧客の離脱が定義されます。 データセット Exited 列は、顧客の離脱を示しています。 これらの属性に関するコンテキストはほとんどないため、データセットに関する背景情報は必要ありません。 これらの属性が Exited の状態にどのように影響するかを理解する必要があります。
10,000 人の顧客のうち、銀行から出た顧客は 2037 人 (約 20%) に過ぎません。 クラスの不均衡率のため、合成データ生成を生成することをお勧めします。
次の表に、churn.csv データのプレビュー サンプルを示します。
| 顧客ID | 名字 | クレジットスコア | 地理学 | ジェンダー | 年齢 | 任期 | Balance | NumOfProducts | HasCrCard | IsActiveMember | 推定給与 | Exited |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | ハーグレイヴ | 619 | フランス | 女性 | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Hill | 608 | スペイン | 女性 | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
データセットをダウンロードして lakehouse にアップロードする
重要
実行する前に、ノートブックにレイクハウス を追加します。 これを行わないと、エラーが発生します。
このコードは、一般公開されているバージョンのデータセットをダウンロードし、そのデータを Fabric Lakehouse に格納します。
library(fs)
library(httr)
remote_url <- "https://sdkstorerta.blob.core.windows.net/churnblob"
file_list <- c("churn.csv")
download_path <- "/lakehouse/default/Files/churn/raw"
if (!dir_exists("/lakehouse/default")) {
stop("Default lakehouse not found, please add a lakehouse and restart the session.")
}
dir_create(download_path, recurse= TRUE)
for (fname in file_list) {
if (!file_exists(paste0(download_path, "/", fname))) {
r <- GET(paste0(remote_url, "/", fname), timeout(30))
writeBin(content(r, "raw"), paste0(download_path, "/", fname))
}
}
print("Downloaded demo data files into lakehouse.")
このノートブックの実行に必要な時間の記録を開始します。
# Record the notebook running time
ts <- as.numeric(Sys.time())
レイクハウスから日付の生データを読み取る
このコードは、lakehouse の Files セクションから生データを読み取ります。
fname <- "churn.csv"
download_path <- "/lakehouse/default/Files/churn/raw"
rdf <- readr::read_csv(paste0(download_path, "/", fname))
手順 3: 探索的データ分析を実行する
生データを表示する
head() または str() コマンドを使用して、生データの予備的な探索を実行します。
head(rdf)
初期データクリーニングを実行する
R DataFrame を Spark DataFrame に変換する必要があります。 Spark DataFrame に対する次の操作により、生のデータセットがクリーンアップされます。
- すべての列にデータが不足している行を削除する
- 列
RowNumberとCustomerIdの間で重複する行を削除する - 列
RowNumber、CustomerId、およびSurnameを削除します
# Transform the R DataFrame to a Spark DataFrame
df <- as.DataFrame(rdf)
clean_data <- function(df) {
sdf <- df %>%
# Drop rows that have missing data across all columns
na.omit() %>%
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
dropDuplicates(c("RowNumber", "CustomerId")) %>%
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
SparkR::select("CreditScore", "Geography", "Gender", "Age", "Tenure", "Balance", "NumOfProducts", "HasCrCard", "IsActiveMember", "EstimatedSalary", "Exited")
return(sdf)
}
df_clean <- clean_data(df)
display コマンドを使用して Spark DataFrame を探索します。
display(df_clean)
このコードは、カテゴリ、数値、およびターゲットの属性を決定します。
# Determine the dependent (target) attribute
dependent_variable_name <- "Exited"
print(dependent_variable_name)
# Obtain the distinct values for each column
exprs = lapply(names(df_clean), function(x) alias(countDistinct(df_clean[[x]]), x))
# Use do.call to splice the aggregation expressions to aggregate function
distinct_value_number <- SparkR::collect(do.call(agg, c(x = df_clean, exprs)))
# Determine the categorical attributes
categorical_variables <- names(df_clean)[sapply(names(df_clean), function(col) col %in% c("0") || distinct_value_number[[col]] <= 5 && !(col %in% c(dependent_variable_name)))]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables <- names(df_clean)[sapply(names(df_clean), function(col) coltypes(SparkR::select(df_clean, col)) == "numeric" && distinct_value_number[[col]] > 5)]
print(numeric_variables)
処理と視覚化を容易にするには、クリーニングされた Spark DataFrame を R DataFrame に変換します。
# Transform the Spark DataFrame to an R DataFrame
rdf_clean <- SparkR::collect(df_clean)
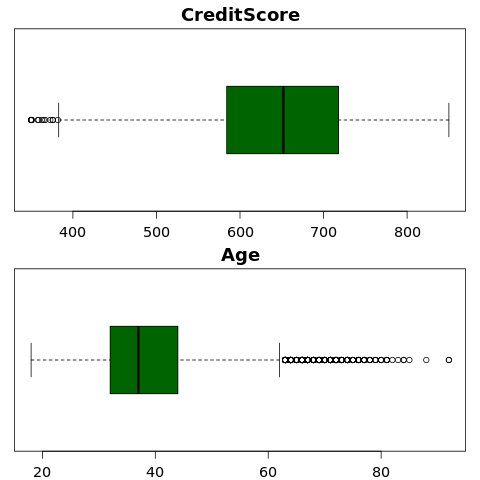
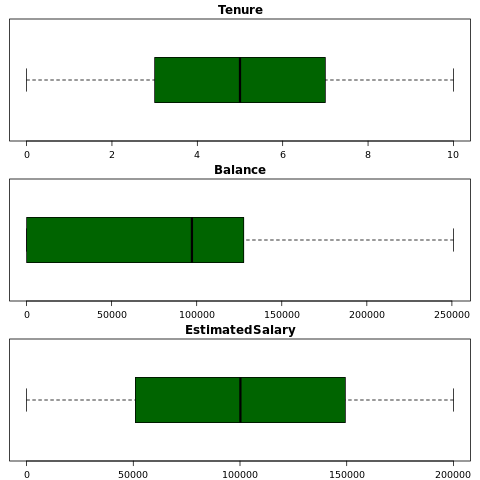
5 つの数値の概要を表示する
ボックス プロットを使用して、数値属性の 5 つの数値の概要 (最小スコア、最初の四分位数、中央値、3 番目の四分位数、最大スコア) を表示します。
# Set the overall layout of the graphics window
par(mfrow = c(2, 1),
mar = c(2, 1, 2, 1)) # Margin size
for(item in numeric_variables[1:2]){
# Create a box plot
boxplot(rdf_clean[, item],
main = item,
col = "darkgreen",
cex.main = 1.5, # Title size
cex.lab = 1.3, # Axis label size
cex.axis = 1.2,
horizontal = TRUE) # Axis size
}
# Set the overall layout of the graphics window
par(mfrow = c(3, 1),
mar = c(2, 1, 2, 1)) # Margin size
for(item in numeric_variables[3:5]){
# Create a box plot
boxplot(rdf_clean[, item],
main = item,
col = "darkgreen",
cex.main = 1.5, # Title size
cex.lab = 1.3, # Axis label size
cex.axis = 1.2,
horizontal = TRUE) # Axis size
}
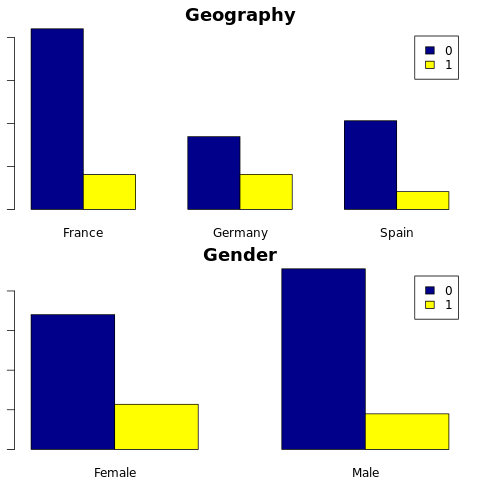
終了した顧客と未終了の顧客の分布を表示する
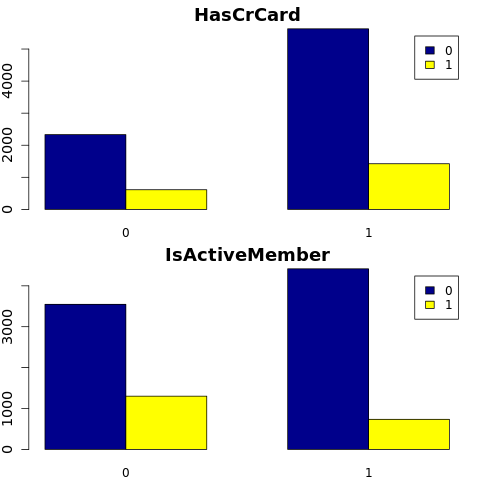
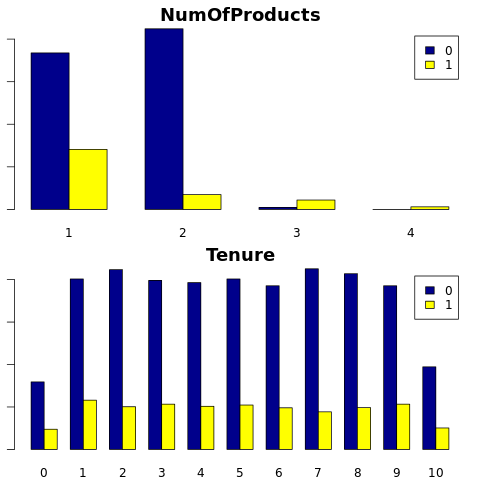
カテゴリ属性にわたる、終了した顧客と未終了の顧客の分布を表示します。
attr_list <- c('Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure')
par(mfrow = c(2, 1),
mar = c(2, 1, 2, 1)) # Margin size
for (item in attr_list[1:2]) {
counts <- table(rdf_clean$Exited, rdf_clean[,item])
barplot(counts, main=item, col=c("darkblue","yellow"),
cex.main = 1.5, # Title size
cex.axis = 1.2,
legend = rownames(counts), beside=TRUE)
}
par(mfrow = c(2, 1),
mar = c(2, 2, 2, 1)) # Margin size
for (item in attr_list[3:4]) {
counts <- table(rdf_clean$Exited, rdf_clean[,item])
barplot(counts, main=item, col=c("darkblue","yellow"),
cex.main = 1.5, # Title size
cex.axis = 1.2,
legend = rownames(counts), beside=TRUE)
}
par(mfrow = c(2, 1),
mar = c(2, 1, 2, 1)) # Margin size
for (item in attr_list[5:6]) {
counts <- table(rdf_clean$Exited, rdf_clean[,item])
barplot(counts, main=item, col=c("darkblue","yellow"),
cex.main = 1.5, # Title size
cex.axis = 1.2,
legend = rownames(counts), beside=TRUE)
}
数値属性の分布を表示する
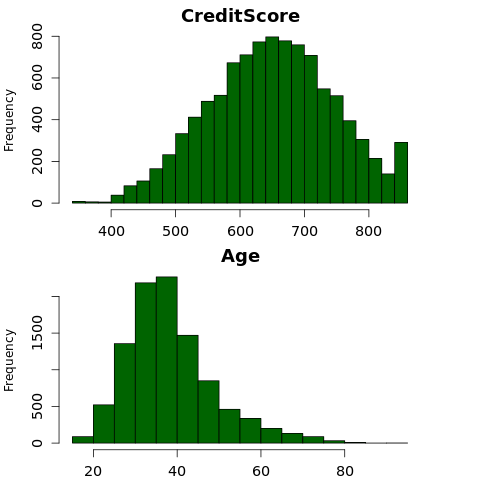
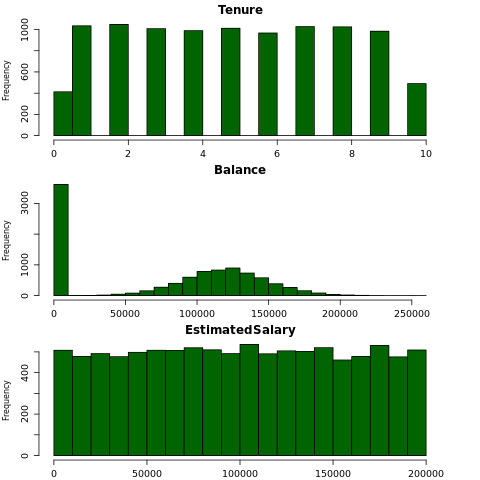
ヒストグラムを使用して、数値属性の頻度分布を表示します。
# Set the overall layout of the graphics window
par(mfrow = c(2, 1),
mar = c(2, 4, 2, 4) + 0.1) # Margin size
# Create a histogram
for (item in numeric_variables[1:2]) {
hist(rdf_clean[, item],
main = item,
col = "darkgreen",
xlab = item,
cex.main = 1.5, # Title size
cex.axis = 1.2,
breaks = 20) # Number of bins
}
# Set the overall layout of the graphics window
par(mfrow = c(3, 1),
mar = c(2, 4, 2, 4) + 0.1) # Margin size
# Create a histogram
for (item in numeric_variables[3:5]) {
hist(rdf_clean[, item],
main = item,
col = "darkgreen",
xlab = item,
cex.main = 1.5, # Title size
cex.axis = 1.2,
breaks = 20) # Number of bins
}
特徴エンジニアリングを実行する
この特徴エンジニアリングでは、現在の属性に基づいて新しい属性が生成されます。
rdf_clean$NewTenure <- rdf_clean$Tenure / rdf_clean$Age
rdf_clean$NewCreditsScore <- as.numeric(cut(rdf_clean$CreditScore, breaks=quantile(rdf_clean$CreditScore, probs=seq(0, 1, by=1/6)), include.lowest=TRUE, labels=c(1, 2, 3, 4, 5, 6)))
rdf_clean$NewAgeScore <- as.numeric(cut(rdf_clean$Age, breaks=quantile(rdf_clean$Age, probs=seq(0, 1, by=1/8)), include.lowest=TRUE, labels=c(1, 2, 3, 4, 5, 6, 7, 8)))
rdf_clean$NewBalanceScore <- as.numeric(cut(rank(rdf_clean$Balance), breaks=quantile(rank(rdf_clean$Balance, ties.method = "first"), probs=seq(0, 1, by=1/5)), include.lowest=TRUE, labels=c(1, 2, 3, 4, 5)))
rdf_clean$NewEstSalaryScore <- as.numeric(cut(rdf_clean$EstimatedSalary, breaks=quantile(rdf_clean$EstimatedSalary, probs=seq(0, 1, by=1/10)), include.lowest=TRUE, labels=c(1:10)))
ワンホット エンコードを実行する
ワンホット エンコードを使用してカテゴリ属性を数値属性に変換し、それらを機械学習モデルにフィードします。
rdf_clean <- cbind(rdf_clean, model.matrix(~Geography+Gender-1, data=rdf_clean))
rdf_clean <- subset(rdf_clean, select = - c(Geography, Gender))
デルタ テーブルを作成して Power BI レポートを生成する
table_name <- "rdf_clean"
# Create a Spark DataFrame from an R DataFrame
sparkDF <- as.DataFrame(rdf_clean)
write.df(sparkDF, paste0("Tables/", table_name), source = "delta", mode = "overwrite")
cat(paste0("Spark DataFrame saved to delta table: ", table_name))
探索的データ分析からの観測の概要
- ほとんどのお客様はフランス出身です。 スペインは、フランスとドイツに比べてチャーン率が最も低い。
- ほとんどのお客様はクレジット カードを持っています
- 一部のお客様はどちらも 60 歳以上で、クレジット スコアが 400 未満です。 ただし、外れ値と見なすことはできません
- 銀行製品が 2 つ以上あるお客様は少ない
- 非アクティブな顧客の離反率が高い
- 性別と在職年数は、銀行口座を閉鎖する顧客の決定にほとんど影響しません
手順 4: モデル トレーニングを実行する
データが配置された状態で、モデルを定義できるようになりました。 ランダム フォレストモデルと LightGBM モデルを適用します。 randomForest と LightGBM を使用して、数行のコードでモデルを実装します。
レイクハウスからデルタ テーブルを読み込みます。 レイクハウスをソースと見なす他のデルタ テーブルを使用できます。
SEED <- 12345
rdf_clean <- read.df("Tables/rdf_clean", source = "delta")
df_clean <- as.data.frame(rdf_clean)
randomForest と LightGBM をインポートします。
library(randomForest)
library(lightgbm)
トレーニング データセットとテスト データセットを準備します。
set.seed(SEED)
y <- factor(df_clean$Exited)
X <- df_clean[, !(colnames(df_clean) %in% c("Exited"))]
split <- base::sample(c(TRUE, FALSE), nrow(df_clean), replace = TRUE, prob = c(0.8, 0.2))
X_train <- X[split,]
X_test <- X[!split,]
y_train <- y[split]
y_test <- y[!split]
train_df <- cbind(X_train, y_train)
トレーニング データセットに SMOTE を適用する
モデルが決定境界を効果的に学習するには少数派クラスの例が少なすぎるため、不均衡な分類には問題があります。 これを処理するために、合成少数派オーバーサンプリング手法 (SMOTE) は、少数派クラスの新しいサンプルを合成するために最も広く使用されている手法です。 手順 1 でインストールした imblearn ライブラリを使用して SMOTE にアクセスします。
トレーニング データセットにのみ SMOTE を適用します。 元のデータに対するモデル のパフォーマンスの有効な近似値を取得するには、テスト データセットを元の不均衡な分布のままにしておく必要があります。 この実験は、運用環境の状況を表します。
まず、データセット内のクラスの分布を示して、どのクラスが少数派クラスであるかを学習します。 少数派クラスとマジョリティ クラスの比率は、imbalance ライブラリで imbalance Ratio として定義されます。
original_ratio <- imbalance::imbalanceRatio(train_df, classAttr = "y_train")
message(sprintf("Original imbalance ratio is %.2f%% as {Size of minority class}/{Size of majority class}.", original_ratio * 100))
message(sprintf("Positive class(Exited) takes %.2f%% of the dataset.", round(sum(train_df$y_train == 1)/nrow(train_df) * 100, 2)))
message(sprintf("Negative class(Non-Exited) takes %.2f%% of the dataset.", round(sum(train_df$y_train == 0)/nrow(train_df) * 100, 2)))
トレーニング データセットで次の手順を実行します。
Positive class(Exited)は少数派クラスを参照します。これは、データセットの 20.34% を受け取ります。Negative class(Non-Exited)は、データセットの 79.66% を受け取るマジョリティ クラスを参照します。
次のセルは、バランスの取れたデータセットを生成するために、imbalance ライブラリのオーバーサンプル関数を書き換えます。
binary_oversample <- function(train_df, X_train, y_train, class_Attr = "Class"){
negative_num <- sum(y_train == 0) # Compute the number of the negative class
positive_num <- sum(y_train == 1) # Compute the number of the positive class
difference_num <- abs(negative_num - positive_num) # Compute the difference between the negative and positive classes
originalShape <- imbalance:::datasetStructure(train_df, class_Attr) # Get the original dataset schema
new_samples <- smotefamily::SMOTE(X_train, y_train, dup_size = ceiling(max(negative_num, positive_num)/min(negative_num, positive_num))) # Use SMOTE to oversample
new_samples <- new_samples$syn_data # Get the synthetic data
new_samples <- new_samples[base::sample(1:nrow(new_samples), size = difference_num), ] # Sample and shuffle the synthetic data
new_samples <- new_samples[, -ncol(new_samples)] # Remove the class column
new_samples <- imbalance:::normalizeNewSamples(originalShape, new_samples) # Normalize the synthetic data
new_train_df <- rbind(train_df, new_samples) # Concatenate original and synthetic data by row
new_train_df <- new_train_df[base::sample(nrow(new_train_df)), ] # Shuffle the training dataset
new_train_df
}
SMOTE の詳細については、CRAN Web サイトの「パッケージ imbalance」と「不均衡なデータセットを扱う リソース」を参照してください。
トレーニング データセットのオーバーサンプリング
新しく定義されたオーバーサンプル関数を使用して、トレーニング データセットに対してオーバーサンプリングを実行します。
library(dplyr)
new_train_df <- binary_oversample(train_df, X_train, y_train, class_Attr="y_train")
smote_ratio <- imbalance::imbalanceRatio(new_train_df, classAttr = "y_train")
message(sprintf("Imbalance ratio after using smote is %.2f%%\n", smote_ratio * 100))
モデルをトレーニングする
ランダム フォレストを使用してモデルをトレーニングします。次の 4 つの特徴があります。
set.seed(1)
rfc1_sm <- randomForest(y_train ~ ., data = new_train_df, ntree = 500, mtry = 4, nodesize = 3)
y_pred <- predict(rfc1_sm, X_test, type = "response")
cr_rfc1_sm <- caret::confusionMatrix(y_pred, y_test)
cm_rfc1_sm <- table(y_pred, y_test)
roc_auc_rfc1_sm <- pROC::auc(pROC::roc(as.numeric(y_test), as.numeric(y_pred)))
print(paste0("The auc is ", roc_auc_rfc1_sm))
ランダム フォレストを使用して、次の 6 つの特徴を持つモデルをトレーニングします。
rfc2_sm <- randomForest(y_train ~ ., data = new_train_df, ntree = 500, mtry = 6, nodesize = 3)
y_pred <- predict(rfc2_sm, X_test, type = "response")
cr_rfc2_sm <- caret::confusionMatrix(y_pred, y_test)
cm_rfc2_sm <- table(y_pred, y_test)
roc_auc_rfc2_sm <- pROC::auc(pROC::roc(as.numeric(y_test), as.numeric(y_pred)))
print(paste0("The auc is ", roc_auc_rfc2_sm))
LightGBM を使用してモデルをトレーニングします。
set.seed(42)
X_train <- new_train_df[, !(colnames(new_train_df) %in% c("y_train"))]
y_train <- as.numeric(as.character(new_train_df$y_train))
y_test <- as.numeric(as.character(y_test))
lgbm_sm_model <- lgb.train(list(objective = "binary", learning_rate = 0.1, max_delta_step = 2, nrounds = 100, max_depth = 10, eval_metric = "logloss"), lgb.Dataset(as.matrix(X_train), label = as.vector(y_train)), valids = list(test = lgb.Dataset(as.matrix(X_test), label = as.vector(as.numeric(y_test)))))
y_pred <- as.numeric(predict(lgbm_sm_model, as.matrix(X_test)) > 0.5)
accuracy <- mean(y_pred == as.vector(y_test))
cr_lgbm_sm <- caret::confusionMatrix(as.factor(y_pred), as.factor(as.vector(y_test)))
cm_lgbm_sm <- table(y_pred, as.vector(y_test))
roc_auc_lgbm_sm <- pROC::auc(pROC::roc(as.vector(y_test), y_pred))
print(paste0("The auc is ", roc_auc_lgbm_sm))
手順 5: 最終的な機械学習モデルを評価して保存する
テスト データセットで保存されたモデルのパフォーマンスを評価します。
ypred_rfc1_sm <- predict(rfc1_sm, X_test, type = "response")
ypred_rfc2_sm <- predict(rfc2_sm, X_test, type = "response")
ypred_lgbm1_sm <- as.numeric(predict(lgbm_sm_model, as.matrix(X_test)) > 0.5)
混同行列を使用して、真陽性、真陰性、偽陽性、偽陰性を表示します。 混同行列をプロットするスクリプトを開発し、分類の精度を評価します。
plot_confusion_matrix <- function(cm, classes, normalize=FALSE, title='Confusion matrix', cmap=heat.colors(10)) {
if (normalize) {
cm <- cm / rowSums(cm)
}
op <- par(mar = c(6,6,3,1))
image(1:nrow(cm), 1:ncol(cm), t(cm[nrow(cm):1,]), col = cmap, xaxt = 'n', yaxt = 'n', main = title, xlab = "Prediction", ylab = "Reference")
axis(1, at = 1:nrow(cm), labels = classes, las = 2)
axis(2, at = 1:ncol(cm), labels = rev(classes))
for (i in seq_len(nrow(cm))) {
for (j in seq_len(ncol(cm))) {
text(i, ncol(cm) - j + 1, cm[j,i], cex = 0.8)
}
}
par(op)
}
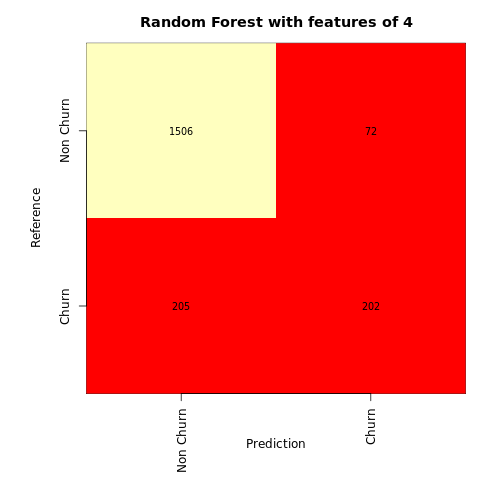
ランダム フォレスト分類子の混同行列を作成します。次の 4 つの特徴があります。
cfm <- table(y_test, ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=c('Non Churn','Churn'), title='Random Forest with features of 4')
tn <- cfm[1,1]
fp <- cfm[1,2]
fn <- cfm[2,1]
tp <- cfm[2,2]
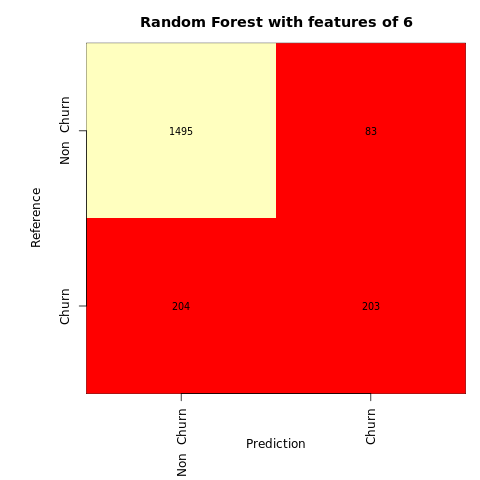
ランダム フォレスト分類子の混同行列を作成します。次の 6 つの特徴があります。
cfm <- table(y_test, ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=c('Non Churn','Churn'), title='Random Forest with features of 6')
tn <- cfm[1,1]
fp <- cfm[1,2]
fn <- cfm[2,1]
tp <- cfm[2,2]
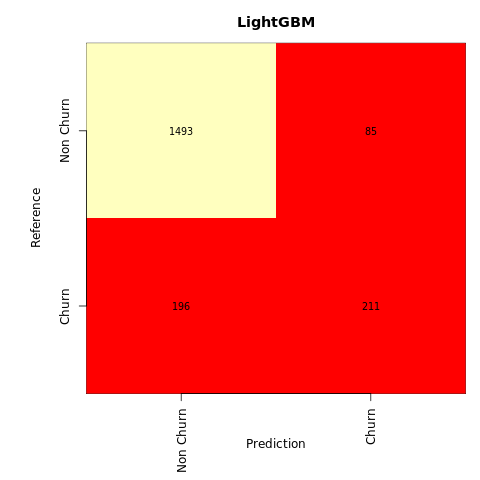
LightGBM の混同行列を作成します。
cfm <- table(y_test, ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=c('Non Churn','Churn'), title='LightGBM')
tn <- cfm[1,1]
fp <- cfm[1,2]
fn <- cfm[2,1]
tp <- cfm[2,2]
Power BI の結果を保存する
モデルの予測結果を Power BI 視覚化に移動するには、デルタ フレームを lakehouse に保存します。
df_pred <- X_test
df_pred$y_test <- y_test
df_pred$ypred_rfc1_sm <- ypred_rfc1_sm
df_pred$ypred_rfc2_sm <- ypred_rfc2_sm
df_pred$ypred_lgbm1_sm <- ypred_lgbm1_sm
table_name <- "df_pred_results"
sparkDF <- as.DataFrame(df_pred)
write.df(sparkDF, paste0("Tables/", table_name), source = "delta", mode = "overwrite", overwriteSchema = "true")
cat(paste0("Spark DataFrame saved to delta table: ", table_name))
手順 6: Power BI で視覚エフェクトにアクセスする
Power BI で保存したテーブルにアクセスします。
- 左側で OneLake データ ハブ を選択します
- このノートブックに追加したレイクハウスを選択します
- [このレイクハウスを開く] セクションで [開く] を選択します
- リボンで、新しいセマンティックモデルを選択します。 [
df_pred_results] を選択し、[続行] 選択して、予測にリンクされた新しい Power BI セマンティック モデルを作成します - データセット ページの上部にあるツールで、[新しいレポート 選択して、Power BI レポートの作成ページを開きます。
次のスクリーンショットは、視覚化の例を示しています。 データ パネルには、テーブルから選択するデルタ テーブルと列が表示されます。 適切なカテゴリ (x) 軸と値 (y) 軸を選択したら、フィルターと関数を選択できます。 たとえば、テーブル列の合計または平均を選択できます。
手記
スクリーンショットは、Power BI で保存された予測結果の分析を示す図の例です。 顧客離れの実際のユース ケースでは、プラットフォーム ユーザーは、主題の専門知識と、組織とビジネス分析チームと企業がメトリックとして標準化したものの両方に基づいて、視覚化をより徹底的に作成する必要がある場合があります。
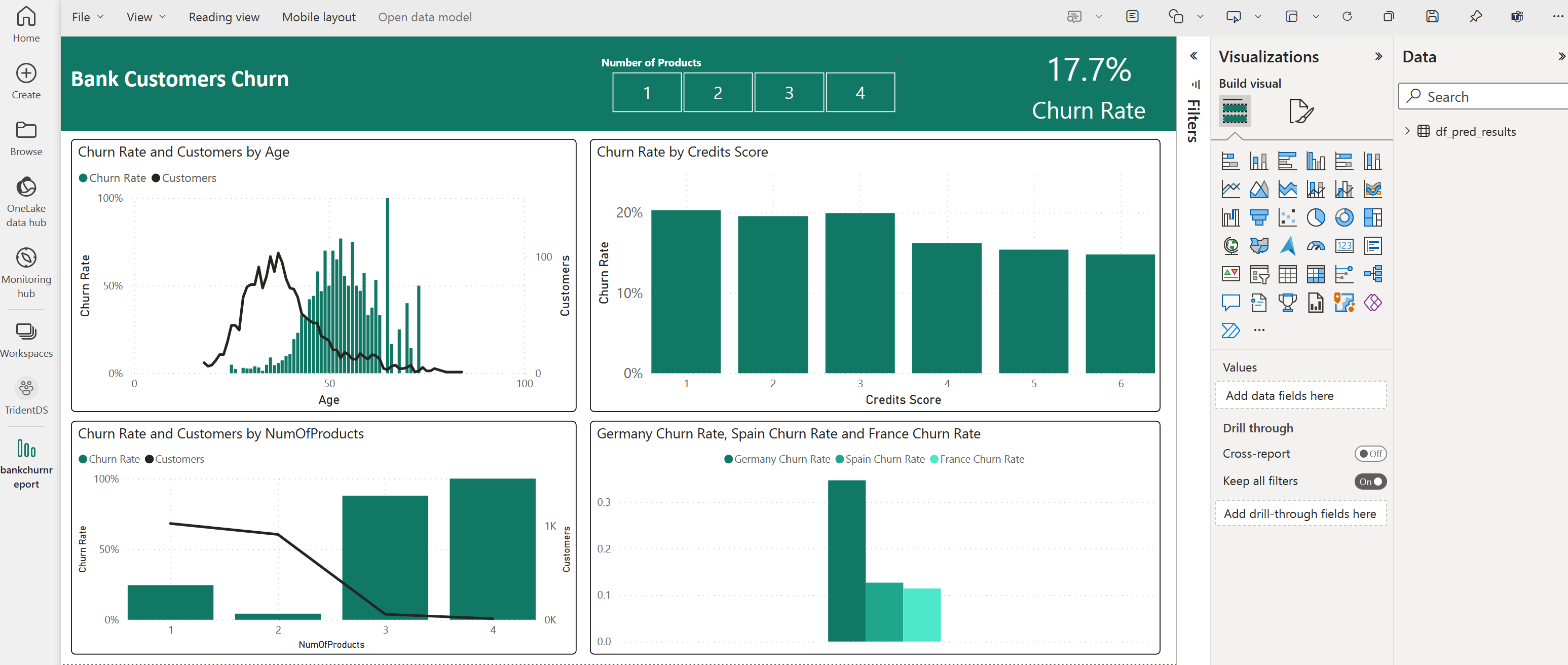
Power BI レポートには、2 つ以上の銀行製品を使用している顧客の離反率が高いことを示しています。 ただし、2 つ以上の製品を持つ顧客はほとんどいませんでした。 (左下のパネルのプロットを参照してください)。銀行はより多くのデータを収集するだけでなく、より多くの製品と関連する他の機能も調査する必要があります。
ドイツの銀行顧客は、フランスとスペインの顧客に比べて離反率が高くなります。 (右下のパネルのプロットを参照してください)。レポートの結果に基づいて、顧客の退出を促した要因の調査が役立つ可能性があります。
中年のお客様が増えています (25 ~ 45)。 45歳から60歳までの顧客は、退会する傾向があります。
最後に、信用スコアが低い顧客は、他の金融機関のために銀行を離れる可能性が最も高くなります。 銀行は、低いクレジット スコアと口座残高を持つ顧客が銀行に留まるよう奨励する方法を検討する必要があります。
# Determine the entire runtime
cat(paste0("Full run cost ", as.integer(Sys.time() - ts), " seconds.\n"))