適用対象: ✅ Microsoft Fabric の SQL 分析エンドポイントと Warehouse
カスタム SQL プールを使用すると、管理者は要求を処理するためにリソースを割り当てる方法をより詳細に制御できます。 このクイックスタートでは、カスタム SQL プールを構成し、Fabric REST API を使用して分類子の値を観察します。
ワークスペース管理者は、接続文字列のアプリケーション名 (またはプログラム名) を使用して、要求を別のコンピューティング プールにルーティングできます。 ワークスペース管理者は、ワークスペース容量のバースト可能なスケール制限に基づいて、各コンピューティング SQL プールがアクセスできるリソースの割合を制御することもできます。
Fabric REST API は、操作用の統合エンドポイントを定義します。
前提条件
- ワークスペース内の Warehouse アイテムへのアクセス。 管理者ロールのメンバーである必要があります。
現在の構成を取得します
現在の構成を取得するには、次の API を使用します。
Fabric Notebook の例
Fabric Spark ノートブックで次の Python コード例を実行できます。
- このコードは、カスタム SQL プール構成 API に
GET要求を送信し、ワークスペースのカスタム SQL プール構成を返します。 -
workspace_idフィールドは、mssparkutils.runtime.contextを使用して、ノートブックが実行されているワークスペース GUID を取得します。 別のワークスペースでカスタム SQL プールを構成するには、カスタム SQL プールを構成するワークスペースの GUID にworkspace_idを更新します。
import requests
import json
from notebookutils import mssparkutils
# This will get the workspace_id where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspaceId = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='get', url=url, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print(json.dumps(response.json(), indent=4))
else:
print(response.text)
カスタム SQL プールを構成する
次の Python の例では、カスタム SQL プールを有効にして構成します。 この Python コードは、Fabric Spark ノートブックで実行できます。
- カスタム SQL プールの構成は、
customSQLPoolsEnabled属性が true に設定されている場合にのみアクティブになります。customSQLPoolsオブジェクト定義でペイロードを定義できますが、customSQLPoolsEnabled を true に設定しない場合、ペイロードは無視され、自律的なワークロード管理が使用されます。 - このコードは、
ContosoSQLPoolとAdhocPoolの 2 つのカスタム SQL プールを構成します。-
ContosoSQLPoolは、使用可能なリソースの 70% を受信するように設定されています。 アプリケーション名分類子には、MyContosoAppの値があります。 -
MyContosoAppアプリケーション名を指定する接続文字列から取得されるすべての SQL クエリは、ContosoSQLPoolカスタム SQL プールに分類され、バースト可能な容量の合計ノードの 70% にアクセスできます。 - 接続文字列のアプリケーション名に
MyContosoAppが含まれていないすべての SQL クエリは、既定のプールとして定義されているAdhocカスタム SQL プールに送信されます。 これらの要求は、バースト可能な容量の合計ノードの 30% にアクセスできます。
-
- すべてのカスタム SQL プール構成には、
isDefault属性を true に設定して識別される既定の SQL プールが 1 つ必要です。 - すべての
maxResourcePercentage値の合計は、100%以下である必要があります。 -
workspace_idフィールドは、mssparkutils.runtime.contextを使用して、ノートブックが実行されているワークスペース GUID を取得します。 別のワークスペースでカスタム SQL プールを構成するには、カスタム SQL プールを構成するワークスペースの GUID にworkspace_idを更新します。
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": True,
"customSQLPools": [
{
"name": "ContosoSQLPool",
"isDefault": False,
"maxResourcePercentage": 70,
"optimizeForReads": False,
"classifier": {
"type": "Application Name",
"value": [
"MyContosoApp"
]
}
},
{
"name": "AdhocPool",
"isDefault": True,
"maxResourcePercentage": 30,
"optimizeForReads": True
}
]
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools configured successfully.")
else:
print(response.text)
ヒント
Fabric からのトラフィックには、次の便利な アプリケーション名 (正規表現) 分類子値を使用します。
- Fabric パイプラインからクエリを分類するには、
^Data Integration-to[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$を使用します。 - Power BI からクエリを分類するには、
^(PowerBIPremium-DirectQuery|Mashup Engine(?: \(PowerBIPremium-Import\))?)を使用します。 -
Fabric portal SQL クエリ エディターからクエリを分類するには、
DMS_userを使用します。
SQL Server Management Studio (SSMS) でアプリケーション名を設定する
カスタム SQL プールの分類子は、共通接続文字列のアプリケーション名またはプログラム名パラメーターを使用します。
SQL Server Management Studio (SSMS) で 、ウェアハウスのサーバー名を 指定し、認証を提供します。 Microsoft Entra MFA をお勧めします。
[ 詳細設定 ] ボタンを選択します。
[ 詳細プロパティ ] ページの [ コンテキスト] で、[ アプリケーション名] の値を
MyContosoAppに変更します。![アプリケーション名 = MyContosoApp の [詳細なプロパティ] ページの SQL Server Management Studio のスクリーンショット。](media/configure-custom-sql-pools-api/advanced-properties-application-name.png)
[OK] を選択.
接続を選択します。
サンプル アクティビティを生成するには、SSMS でこの接続を使用して、次のような単純なクエリをウェアハウスで実行します。
SELECT * FROM dbo.DimDate;
![アプリケーション名 = MyContosoApp の [詳細なプロパティ] ページの SQL Server Management Studio のスクリーンショット。](media/configure-custom-sql-pools-api/advanced-properties-application-name.png#lightbox)
カスタム SQL プールのクエリ分析情報を観察する
sys.dm_exec_sessions動的管理ビューを確認して、MyContosoAppが SSMS から SQL エンジンに渡されたアプリケーション名として認識されていることを確認します。SELECT session_id, program_name FROM sys.dm_exec_sessions WHERE program_name = 'MyContosoApp';例えば次が挙げられます。
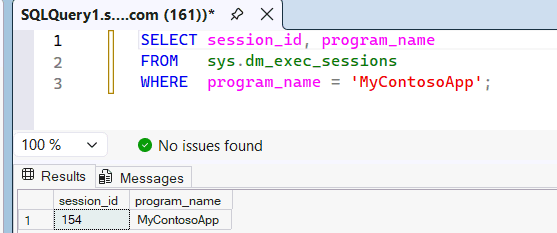
program_nameは、MyContosoAppカスタム SQL プール内のアプリケーション名と一致するため、このクエリはそのプール内のリソースを使用します。 クエリで使用されたカスタム SQL プールを証明するには、 queryinsights.exec_requests_history システム ビューに対してクエリを実行します。 クエリ分析情報が設定されるまで 10 ~ 15 分待ってから、次のクエリを実行します。SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE program_name = 'MyContosoApp';また、ステートメント ID でクエリのプールを識別することもできます。 Fabric ポータルの SQL クエリ エディターで、ウェアハウスまたは SQL 分析エンドポイントに対してクエリを実行します。
SELECT * FROM dbo.DimDate;[ メッセージ ] タブを選択し、クエリ実行の ステートメント ID を 記録します。 SQL クエリ エディターでは、
program_nameがDMS_userとなっており、以前にカスタム SQL プールMyContosoAppを使用するように設定しました。クエリの分析情報が表示されるまで 10 ~ 15 分待ってください。
sql_pool_nameおよびその他の情報を取得して、適切なカスタム SQL プールが使用されたことを確認します。SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE distributed_statement_id = '<Statement ID>';
カスタム SQL プールの構成を元に戻す
ワークスペースを元の状態に戻すには、 customSQLPoolsEnabled プロパティを False に変更します。 カスタム SQL プール構成を保持する場合は、 customSQLPools 一覧のように各プール名を渡す必要があります。
この Python コード例では、カスタム SQL プールを無効にし、 SELECT プールと非SELECT プールの自律ワークロード管理構成に戻します。
PATCH要求は、customSQLPoolsEnabled プロパティを False に設定して呼び出されます。
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": False,
"customSQLPools": []
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools successfully disabled.")
else:
print(response.text)