適用対象: Microsoft Fabric の✅ Warehouse
この記事では、Azure Synapse Analytics 専用 SQL プールのデータ ウェアハウスを Microsoft Fabric Warehouse に移行する方法について詳しく説明します。
ヒント
移行の戦略と計画の詳細については、移行の計画:Azure Synapse Analytics 専用 SQL プールから Fabric Data Warehouse に関するページを参照してください。
Data Warehouse 用 Fabric Migration Assistant を使用して、Azure Synapse Analytics 専用 SQL プールからの移行用の自動化されたエクスペリエンスを利用できます。 この記事の残りの部分では、より手作業が必要な移行手順について説明しています。
次の表は、データ スキーマ (DDL)、データベース コード (DML)、データの移行方法に関する情報をまとめたものです。 各シナリオについては、この記事の後半でさらに詳しく説明します ("オプション" 列にリンクが記載されています)。
| オプション番号 | 選択肢 | その機能 | スキルまたは好み | シナリオ |
|---|---|---|---|---|
| 1 | Data Factory | スキーマ (データ定義言語DDL) 変換 データ抽出 データ インジェスト |
ADF またはパイプライン | スキーマ (DDL) とデータ移行をオールインワンに簡略化しました。 ディメンション テーブル に推奨されます。 |
| 2 | Data Factory (パーティションあり) | スキーマ (データ定義言語DDL) 変換 データ抽出 データ インジェスト |
ADF またはパイプライン | パーティション分割オプションを使用して読み取り/書き込みの並列処理を向上させると、スループットがオプション 1 の 10 倍になります。これはファクト テーブルに推奨されます。 |
| 3 | Data Factory で高速コードを使用する | スキーマ (データ定義言語DDL) 変換 | ADF またはパイプライン | スキーマ (DDL) をまず最初に変換して移行してから、CETAS を使用して抽出し、COPY または Data Factory を使用してデータを取り込むことで、全体的なインジェスト パフォーマンスを最適化します。 |
| 4 | ストアド プロシージャの高速コード | スキーマ (データ定義言語DDL) 変換 データ抽出 コード評価 |
T-SQL | IDE を使用する SQL ユーザーは、どのタスクに着手するかをより細かく制御できます。 COPY または Data Factory を使用してデータを取り込みます。 |
| 5 | Azure Data Studio の SQL データベース プロジェクトの拡張機能 | スキーマ (データ定義言語DDL) 変換 データ抽出 コード評価 |
SQL プロジェクト | SQL Database プロジェクトをデプロイに使用し、オプション 4 を統合します。 COPY または Data Factory を使用してデータを取り込みます。 |
| 6 | SELECT として外部テーブルを作成する (CETAS) | データ抽出 | T-SQL | Azure Data Lake Storage (ADLS) Gen2 へのコスト効率とパフォーマンスの高いデータ抽出。 COPY または Data Factory を使用してデータを取り込みます。 |
| 7 | dbt を使用した移行 | スキーマ (データ定義言語DDL) 変換 データベース コード (DML) 変換 |
dbt | dbt を既に使用しているユーザーは、dbt Fabric アダプターを使用して DDL と DML を変換できます。 その後、この表にある他のオプションを使用してデータを移行する必要があります。 |
最初に移行するワークロードを選択する
Synapse 専用 SQL プールから Fabric Warehouse への移行プロジェクトの開始地点を決めるときは、次に掲げる条件を満たすワークロード領域を選んでください。
- 新しい環境の利点を迅速に実感でき、Fabric Warehouse への移行が可能であることを証明できるもの。 複数の小規模な移行の準備をするなど、小規模でシンプルなところから始めます。
- 他の領域に移行するときに使用するプロセスとツールについて、社内の技術スタッフがそれに関連する経験を積む時間を確保します。
- ソース Synapse 環境に特化した、今後に使える移行テンプレートと、役立つツールやプロセスを作成します。
ヒント
移行する必要があるオブジェクトのインベントリを作成し、移行プロセスを最初から最後まで文書化することで、他の専用 SQL プールまたはワークロードでも同じように繰り返すことができるようにします。
初期移行で移行するデータの量は、Fabric Warehouse 環境の機能と利点を示すために十分な大きさにしつつ、価値をすばやく実感できるよう、大きすぎないようにする必要があります。 1 から 10 テラバイトの範囲のサイズが一般的です。
Fabric Data Factory を使用した移行
このセクションでは、Azure Data Factory と Synapse Pipeline に慣れているローコードまたはコードなしのペルソナ向けの、Data Factory を使用するオプションについて説明します。 ドラッグ アンド ドロップで操作できる UI を用いたこのオプションを使用すると、簡単な手順で DDL を変換してデータを移行することができます。
Fabric Data Factory では、次のタスクを実行できます。
- スキーマ (DDL) を Fabric Warehouse 構文に変換します。
- Fabric Warehouse でスキーマ (DDL) を作成します。
- データを Fabric Warehouse に移行します。
オプション 1。 スキーマまたはデータの移行 - コピー ウィザードと ForEach Copy アクティビティ
このメソッドでは Data Factory のコピー アシスタントを使用してソース専用 SQL プールに接続し、専用 SQL プールの DDL 構文を Fabric に変換してから、データを Fabric Warehouse にコピーします。 1 つ以上のターゲット テーブルを選択できます (TPC-DS データセットには 22 個のテーブルがあります)。 UI で選択したテーブルの一覧をループ処理する ForEach を生成し、22 個の並列する Copy アクティビティ スレッドが生成されます。
- 22 個の SELECT クエリ (選択したテーブルごとに 1 つ) が生成され、専用 SQL プールで実行されました。
- 生成されたクエリを実行できる、適切な DWU とリソース クラスがあることを確認します。 今回のケースでは、送信された 22 個のクエリを最大 32 個のクエリで処理できるようにするために、
staticrc10を持つ DWU1000 が少なくとも 32 個必要です。 - Data Factory で専用 SQL プールから Fabric Warehouse にデータを直接コピーするには、ステージングが必要です。 インジェスト プロセスは、2 つのフェーズで構成されています。
- 最初のフェーズはステージングと呼ばれ、専用 SQL プールから ADLS にデータを抽出します。
- 2 番目のフェーズは、ステージングから Fabric Warehouse にデータを取り込むことです。 データ インジェストが行われるのは、ほとんどがステージング フェーズ中です。 つまり、ステージングは、インジェストのパフォーマンスに大きな影響を与えます。
推奨される使用方法
コピー ウィザードを使用して ForEach を生成すると、シンプルな UI で DDL を変換し、選択したテーブルをワンステップで専用 SQL プールから Fabric Warehouse に取り込むことができます。
ただし、全体的なスループットは最適ではありません。 ステージングを使用しないといけない点、および "ソースからステージへ" のステップにおいて読み取りと書き込みを並列化する必要がある点が、パフォーマンス遅延の主な要因です。 このオプションは、ディメンション テーブルにのみ使用することをお勧めします。
オプション 2。 DDL またはデータ移行 - パーティション オプションを使用したデータ パイプライン
Fabric データ パイプラインを使用してより大きなファクト テーブルの読み込みスループットを向上させるには、パーティション オプションを使用する各ファクト テーブルに対して Copy アクティビティを使用することをお勧めします。 これにより、Copy アクティビティのパフォーマンスを最適化できます。
ソース テーブルの物理パーティション分割を使用することもできます (使用可能な場合)。 テーブルに物理パーティション分割がない場合は、パーティション列を指定し、動的パーティション分割を使用するための最小値と最大値を指定する必要があります。 次のスクリーンショットでは、データ パイプラインの "ソース" オプションによって、ws_sold_date_sk 列に基づくパーティションの動的範囲を指定しています。
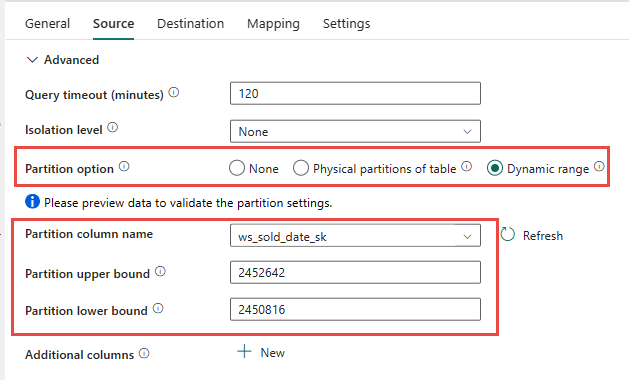
パーティションを使用するとステージング フェーズのスループットを向上させることができますが、適切な調整を行うには、考慮すべき事項があります。
- パーティションの範囲によっては、専用 SQL プールで 128 を超えるクエリが生成される可能性があるため、すべてのコンカレンシー スロットが使用される可能性があります。
- すべてのクエリを実行できるようにするには、最低でも DWU6000 にスケーリングする必要があります。
- たとえば、TPC-DS
web_salesテーブルの場合、163 個のクエリが専用 SQL プールに送信されています。 DWU6000 では、128 個のクエリが実行され、35 個のクエリがキューに登録されました。 - 動的パーティションを使用すると、範囲パーティションが自動的に選択されます。 今回のケースでは、専用 SQL プールに送信された SELECT クエリごとに 11 日間という範囲です。 例えば:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
推奨される使用方法
ファクト テーブルの場合は、Data Factory のパーティション分割オプションを使用してスループットを向上することをお勧めします。
ただし、並列処理する読み取りの数が増えるため、抽出クエリを実行できるようにするには、専用 SQL プールを上位の DWU にスケーリングする必要があります。 パーティション分割を利用すると、パーティション オプションを使用しない場合と比べて速度が 10 倍に向上します。 DWU を上げてコンピューティング リソース側からスループットを向上させることもできますが、専用 SQL プールで許可されるアクティブなクエリの数は、最大 128 個です。
Synapse DWU から Fabric へのマッピングの詳細については、「 ブログ: Azure Synapse 専用 SQL プールを ファブリック データ ウェアハウス コンピューティングにマッピングする」を参照してください。
オプション 3。 DDL 移行 - コピー ウィザードの ForEach Copy アクティビティ
上記の 2 つのオプションは、"小規模" なデータベースに適したデータ移行オプションです。 しかし、より高いスループットが必要な場合は、別のオプションをお勧めします。
- 専用 SQL プールから ADLS にデータを抽出することで、ステージ パフォーマンスのオーバーヘッドを軽減します。
- Data Factory または COPY コマンドを使用して、Fabric Warehouse にデータを取り込みます。
推奨される使用方法
スキーマ (DDL) の変換には、Data Factory を引き続き使用できます。 コピー ウィザードを使用すると、特定のテーブルまたはすべてのテーブルを選択できます。 設計上、これはスキーマとデータをワンステップで移行し、クエリ ステートメントの TOP 0 という false 条件を使用することで行のないスキーマを抽出します。
次のコード サンプルでは、Data Factory を使用したスキーマ (DDL) の移行について説明します。
コード例: Data Factory を使用したスキーマ (DDL) の移行
Fabric Data Pipelines を使用すると、任意のソース Azure SQL Database または専用 SQL プールからテーブル オブジェクトの DDL (スキーマ) を簡単に移行できます。 このデータ パイプラインは、ソース専用 SQL プール テーブルのスキーマ (DDL) を介して Fabric Warehouse に移行します。
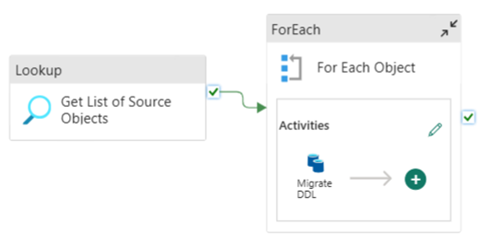
パイプラインの設計: パラメーター
このデータ パイプラインでは、移行するスキーマを指定できるパラメーター SchemaName を使用できます。 既定値は、dbo スキーマです。
"既定値" フィールドに、移行するスキーマを示すテーブル スキーマの一覧をコンマ区切りで入力します。2 つのスキーマ 'dbo','tpch' と dbo を指定する場合は、tpch のようにします。
![データ パイプラインの [パラメーター] タブを示す Data Factory のスクリーンショット。 [名前] フィールドに「SchemaName」と入力します。[既定値] フィールド 'dbo','tpch' で、これら 2 つのスキーマを移行する必要があることを示します。](media/migration-synapse-dedicated-sql-pool-methods/fabric-data-factory-parameters-schemaname.png)
パイプラインの設計: 検索アクティビティ
Lookup アクティビティを作成し、ソース データベースをポイントするように接続を設定します。
[設定] タブで、次のようにします。
"データ ストアの種類" を [外部] に設定します。
接続は、Azure Synapse 専用の SQL プールです。 "接続の種類" は、[Azure Synapse Analytics] です。
[クエリの使用] は、[クエリ] に設定されています。
"クエリ" フィールドは動的な式を使用して作成する必要があります。これにより、ターゲット ソース テーブルの一覧を返すクエリで SchemaName パラメーターを使用できるようになります。 [クエリ] を選択してから、[動的コンテンツの追加] を選択します。
LookUp アクティビティに含まれるこの式により、システム ビューにクエリを実行してスキーマとテーブルの一覧を取得する SQL ステートメントが生成されます。 SQL スキーマでフィルター処理できるように SchemaName パラメーターを参照します。 出力は、ForEach アクティビティへの入力として使用される SQL スキーマとテーブルの配列です。
次のコードを使用して、すべてのユーザー テーブルとそのスキーマ名を含むリストを返します。
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
![データ パイプラインの [設定] タブを示す Data Factory のスクリーンショット。[クエリ] ボタンが選択され、[クエリ] フィールドにコードが貼り付けられます。](media/migration-synapse-dedicated-sql-pool-methods/fabric-data-factory-query-dynamic-content.png)
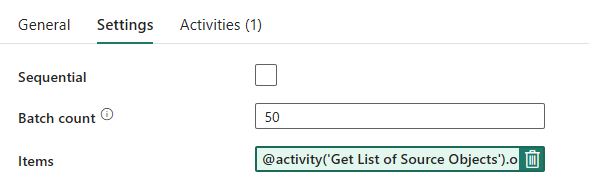
パイプラインの設計: ForEach ループ
ForEach ループについては、[設定] タブで次のオプションを構成します。
- "順次" をオフにして、複数のイテレーションを同時に実行できるようにします。
- "バッチ カウント" を
50に設定して、同時実行するイテレーションの最大数を制限します。 - "項目" フィールドでは、動的コンテンツを使用して LookUp アクティビティの出力を参照する必要があります。 次のコード スニペットを追加します:
@activity('Get List of Source Objects').output.value
パイプラインの設計: ForEach ループ内の Copy アクティビティ
ForEach アクティビティ内に Copy アクティビティを追加します。 このメソッドでは、データ パイプライン内で動的な式言語を使用して、データのないスキーマのみを Fabric Warehouse に移行するための SELECT TOP 0 * FROM <TABLE> を構築します。
[ソース] タブで:
- "データ ストアの種類" を [外部] に設定します。
- 接続は、Azure Synapse 専用の SQL プールです。 "接続の種類" は、[Azure Synapse Analytics] です。
- [クエリの使用] を [クエリ] に設定します。
- "クエリ" フィールドに動的なコンテンツ クエリを貼り付け、次の式を使用します。この式を使用すると、行は返されず、テーブル スキーマ
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)のみが返されます。
![ForEach ループ内のコピー アクティビティの [ソース] タブを示す Data Factory のスクリーンショット。](media/migration-synapse-dedicated-sql-pool-methods/fabric-data-factory-foreach-copy-activity-source.png#lightbox)
[送信先] タブで、次の手順を実行します。
- "データ ストアの種類" を [ワークスペース] に設定します。
- "ワークスペースのデータ ストアの種類"は [Data Warehouse] にし、"データ ウェアハウス" は Fabric Warehouse に設定します。
- 送信先テーブルのスキーマとテーブル名は、動的コンテンツを使用して定義されます。
- スキーマは、現在のイテレーションのフィールド SchemaName を、スニペット
@item().SchemaNameを使用して参照します。 - テーブルは、スニペット
@item().TableNameを使用して TableName を参照しています。
- スキーマは、現在のイテレーションのフィールド SchemaName を、スニペット
![各 ForEach ループ内のコピー アクティビティの [配信先] タブを示す Data Factory のスクリーンショット。](media/migration-synapse-dedicated-sql-pool-methods/fabric-data-factory-foreach-copy-activity-destination.png#lightbox)
パイプラインの設計: シンク
シンクについては、ウェアハウスをポイントし、ソース スキーマとテーブル名を参照します。
このパイプラインを実行すると、ソース内の各テーブルが適切なスキーマとともにデータウェアハウスに入力されます。
Synapse 専用 SQL プールのストアド プロシージャを使用して移行する
このオプションでは、ストアド プロシージャを使用して Fabric への移行を実行します。
コード サンプルは、microsoft/fabric-migration on GitHub.com で入手できます。 このコードはオープン ソースとして公開されているため、ぜひ貢献してコミュニティを支援してください。
移行ストアド プロシージャで実行できることは以下のとおりです。
- スキーマ (DDL) を Fabric Warehouse 構文に変換します。
- Fabric Warehouse でスキーマ (DDL) を作成します。
- Synapse 専用 SQL プールから ADLS にデータを抽出します。
- T-SQL コードでサポートされていない Fabric 構文 (ストアド プロシージャ、関数、ビュー) にフラグを設定します。
推奨される使用方法
これは、次のようなユーザーに最適なオプションです。
- T-SQLに慣れています。
- SQL Server Management Studio (SSMS) などの統合開発環境を使用する場合。
- 作業するタスクをより細かく制御する必要がある場合。
スキーマ (DDL) 変換、データ抽出、または T-SQL コード評価用の特定のストアド プロシージャを実行できます。
データ移行については、COPY INTO または Data Factory を使用して、Fabric Warehouse にデータを取り込む必要があります。
SQL データベース プロジェクトを使用して移行する
Microsoft Fabric Data Warehouse は、Azure Data Studio と Visual Studio Code 内で使用できる SQL Database Projects 拡張機能でサポートされています。
この拡張機能は、Azure Data Studio と Visual Studio Code 内で使用できます。 この機能により、ソース管理、データベース テスト、スキーマ検証の機能が有効になります。
Git 統合パイプラインや展開パイプラインなど、Microsoft Fabric の倉庫のソース管理の詳細については、「Warehouse を使用したソース管理」を参照してください。
推奨される使用方法
これは、デプロイに SQL Database Project を使用したい場合に最適なオプションです。 このオプションは、基本的に Fabric 移行のストアド プロシージャを SQL Database プロジェクトに統合することで、シームレスな移行エクスペリエンスを提供するものです。
SQL Database Project を使用すると、以下を行うことができます。
- スキーマ (DDL) を Fabric Warehouse 構文に変換します。
- Fabric Warehouse でスキーマ (DDL) を作成します。
- Synapse 専用 SQL プールから ADLS にデータを抽出します。
- T-SQL コードでサポートされていない構文 (ストアド プロシージャ、関数、ビュー) にフラグを設定します。
データ移行については、その後に COPY INTO または Data Factory を使用して、Fabric Warehouse にデータを取り込みます。
Microsoft Fabric で Azure Data Studio を利用できるようになることに加え、Microsoft Fabric CAT チームは、SQL Database プロジェクトでスキーマ (DDL) とデータベース コード (DML) の抽出、作成、デプロイを処理できるようにする、一連の PowerShell スクリプトを提供しました。 便利な PowerShell スクリプトを使用して SQL Database プロジェクトを使用するチュートリアルについては、GitHub.com の microsoft/fabric-migration を参照してください。
SQL Database プロジェクトの詳細については、「SQL Database プロジェクトの拡張機能をお使いになる前に」および「プロジェクトをビルドして公開する」を参照してください。
CETAS を使用してデータを移行する
T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) コマンドは、Synapse 専用 SQL プールから Azure Data Lake Storage (ADLS) Gen2 にデータを抽出するための、最もコスト効率が良い最適な方法を提供します。
CETAS でできることは以下のとおりです。
- ADLS にデータを抽出します。
- このオプションを使用するには、データを取り込む前に、Fabric Warehouse でスキーマ (DDL) を作成する必要があります。 スキーマ (DDL) を移行するには、この記事のオプションを検討してください。
このオプションの利点は次のとおりです。
- ソース Synapse 専用 SQL プールに対して送信されるクエリは、テーブルごとに 1 つだけです。 これによってコンカレンシー スロットが使い切られることがなくなるため、同時実行している顧客運用の ETL やクエリがブロックされることがありません。
- テーブルごとに使用されるコンカレンシー スロットの数は 1 つのみであるため、DWU6000 へのスケーリングは必要ありません。そのため、ユーザーは低い DWU を使用することができます。
- 抽出はすべてのコンピューティング ノードで並列に実行されるため、これがパフォーマンス向上の鍵となっています。
推奨される使用方法
CETAS を使用して、Parquet ファイルとしてデータを ADLS に抽出します。 Parquet ファイルは列圧縮による効率的なデータ ストレージが可能なため、ネットワーク間の送受信に必要な帯域幅が少なくなるという利点があります。 さらに、Fabric のデータは Delta Parquet 形式として格納されるため、インジェスト中に Delta 形式に変換するためのオーバーヘッドがかからず、データ インジェストにかかる時間はテキスト ファイル形式に比べて 2.5 倍高速になります。
CETAS スループットを向上させるには、以下のようにします。
- 並列 CETAS 操作を追加することで、コンカレンシー スロットの使用を増やしつつ、スループットを向上させます。
- Synapse 専用 SQL プールの DWU をスケーリングします。
dbt を使用して移行する
このセクションでは、現在使用している Synapse 専用 SQL プール環境で既に dbt を使用しているユーザー向けの dbt オプションについて説明します。
dbt でできることは以下のとおりです。
- スキーマ (DDL) を Fabric Warehouse 構文に変換します。
- Fabric Warehouse でスキーマ (DDL) を作成します。
- データベース コード (DML) を Fabric 構文に変換します。
dbt フレームワークを使用することで、実行のたびに DDL と DML (SQL スクリプト) を即座に生成できます。 SELECT ステートメントで表されるモデル ファイルの場合、プロファイル (接続文字列) とアダプターの型を変更することで、DDL/DML を任意のターゲット プラットフォームに即座に変換できます。
推奨される使用方法
dbt フレームワークは、コードファースト アプローチです。 データは、CETAS や COPY または Data Factory など、このドキュメントに記載されているオプションを使用して移行する必要があります。
Microsoft Fabric Data Warehouse 用の dbt アダプターを使用すると、Synapse 専用 SQL プール、Snowflake、Databricks、Google Big Query、Amazon Redshift などのさまざまなプラットフォームを対象とした既存の dbt プロジェクトを、簡単な構成変更で Fabric Warehouse に移行できます。
Fabric Warehouse を対象とする dbt プロジェクトを開始するには、「チュートリアル: dbt を Fabric Data Warehouse 用に設定する」を参照してください。 このドキュメントでは、異なるウェアハウスやプラットフォーム間を移動するオプションも示します。
Fabric Warehouse へのデータ インジェスト
Fabric Warehouse へのインジェストには、好みに応じて COPY INTO または Fabric Data Factory を使用します。 どちらの方法も、ファイルが既に Azure Data Lake Storage (ADLS) Gen2 に抽出されているという前提条件があれば、パフォーマンス スループットは同程度であるため、推奨される最適なオプションです。
プロセスを設計する際、パフォーマンスを最大限に高めるには、次のいくつかの要因に注意してください。
- Fabric では、ADLS から Fabric Warehouse に複数のテーブルを同時に読み込んでも、リソース競合は発生しません。 結果として、並列スレッドを読み込んでも、パフォーマンスが低下しません。 最大インジェスト スループットが制限されるのは、Fabric の容量のコンピューティング能力によってのみです。
- Fabric のワークロード管理では、負荷とクエリに割り当てるリソースは分離されます。 クエリとデータの読み込みが同時に実行されても、リソースの競合は発生しません。