Fabric でのミラーリング は、複雑な ETL (抽出、変換、読み込み) プロセスを回避し、既存の Google BigQuery ウェアハウス データを Fabric の残りのデータとシームレスに統合する簡単な方法を提供します。 Google BigQuery データを Fabric の OneLake に直接継続的にレプリケートできます。 Fabric では、ビジネス インテリジェンス、AI、データ エンジニアリング、データ サイエンス、データ共有に対する強力な機能を利用できます。
Fabric でミラーリング用に Google BigQuery データベースを構成する方法のチュートリアルについては、「Tutorial: Google BigQuery からミラー化されたデータベースMicrosoft Fabric構成するを参照してください。
Important
Google BigQuery のミラーリングが プレビュー段階になりました。 運用環境のワークロードは、プレビュー期間中はサポートされません。
Fabric でミラーリングを使用する理由
Microsoft Fabricでミラーリングすると、さまざまなプロバイダーからツールを結合する複雑さが排除されます。 データを移行する必要はありません。 Fabric の分析ツールの配列を使用するには、ほぼリアルタイムで Google BigQuery データに接続します。 Fabric は、Microsoft 製品、Google BigQuery、およびオープンソースの Delta Lake テーブル形式をサポートする幅広いテクノロジとシームレスに連携します。
どのような分析エクスペリエンスが組み込まれていますか?
ミラーリングでは、Fabric ワークスペースに次の 2 つの項目が作成されます。
- ミラー化されたデータベース項目。 ミラーリングでは、 データの OneLake へのレプリケーションと Parquet への変換が、分析対応形式で管理されます。 ミラーリングにより、データ エンジニアリング、データ サイエンスなどのダウンストリーム シナリオが可能になります。 ミラー化されたデータベースは、ウェアハウスおよび SQL 分析エンドポイント項目とは異なります。
- SQL 分析エンドポイント
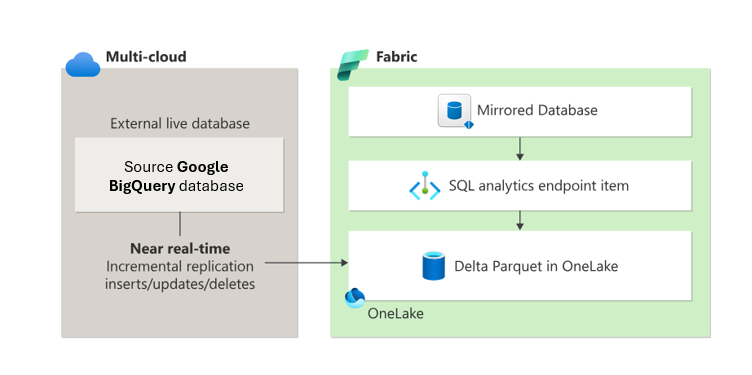
各ミラー化されたデータベースから、 SQL 分析エンドポイント は、ミラーリング中に作成された Delta テーブルの上に読み取り専用の分析エクスペリエンスを提供します。 このエンドポイントでは、データ オブジェクトを定義およびクエリするための T-SQL 構文がサポートされていますが、データが読み取り専用であるため、直接データの変更は許可されません。
SQL 分析エンドポイントを使用すると、次のことができます。
- BigQuery からミラー化された Delta Lake データを参照するテーブルを参照します。
- コードなしのクエリとビューを作成し、データを視覚的に探索します。SQL は必要ありません。
- SQL ビュー、インライン テーブル値関数 (TVF)、ストアド プロシージャを作成して、T-SQL を使用してビジネス ロジックを階層化します。
- オブジェクトのアクセス許可を設定および管理します。
- 同じワークスペース内の他のウェアハウスと Lakehouse のデータに対してクエリを実行します。
SQL クエリ エディターに加えてSQL Server Management Studio (SSMS)、 Visual Studio Code 用の MSSQL 拡張機能、さらには GitHub Copilot など、SQL 分析エンドポイントに対してクエリを実行できるツールの広範なエコシステムがあります。
セキュリティに関する考慮事項
ファブリック ミラーリングを有効にするには、特定の ユーザーアクセス許可要件 があります。
Fabric には、Microsoft Fabric内のアクセスを管理するためのデータ保護機能も用意されています。 詳細については、 データ保護機能に関するドキュメントを参照してください。
ミラー化された BigQuery のコストに関する考慮事項
データを Fabric OneLake にレプリケートするために使用される Fabric コンピューティングは無料です。 ミラーリング ストレージのコストは、容量に基づいて上限まで解放されます。 SQL、Power BI、または Spark を使用してデータを照会するためのコンピューティングは、通常の料金で課金されます。
ファブリックでは、ミラーリング用の OneLake へのネットワーク データイングレス料金は課金されません。
データがミラー化されている場合、Google BigQuery コンピューティングとクラウド クエリのコストがあります。BigQuery Change Data Capture (CDC) は、行の変更に BigQuery コンピューティングを利用し、データ インジェスト用のストレージ書き込み API、すべてのコストが発生するデータ ストレージ用の BigQuery ストレージを利用します。
Google BigQuery のミラーリングのコストの詳細については、 説明されている価格を参照してください。