この記事では、Confluent Cloud for Apache Kafka ソースをイベントストリームに追加する方法について説明します。
Confluent Cloud for Apache Kafka は、Apache Kafka を使用した強力なデータ ストリーミングおよび処理機能を提供するストリーミング プラットフォームです。 Confluent Cloud for Apache Kafka をイベントストリーム内のソースとして統合することで、リアルタイム データ ストリームをシームレスに処理してから、Fabric 内の複数の宛先にルーティングできます。
注
このソースは、ワークスペース容量の次のリージョンではサポートされていません: 米国西部 3、スイス西部。
前提条件
- 共同作成者以上のアクセス許可を使用した Fabric 容量ライセンス モード (または試用版ライセンス モード) でのワークスペースへのアクセス。
- Apache Kafka 用 Confluent Cloud クラスターと API キー。
- Confluent Cloud for Apache Kafka クラスターは、パブリックにアクセスでき、ファイアウォールの内側に存在しないか、仮想ネットワークでセキュリティで保護されていない必要があります。
- イベントストリームがない場合は、イベントストリームを作成します。
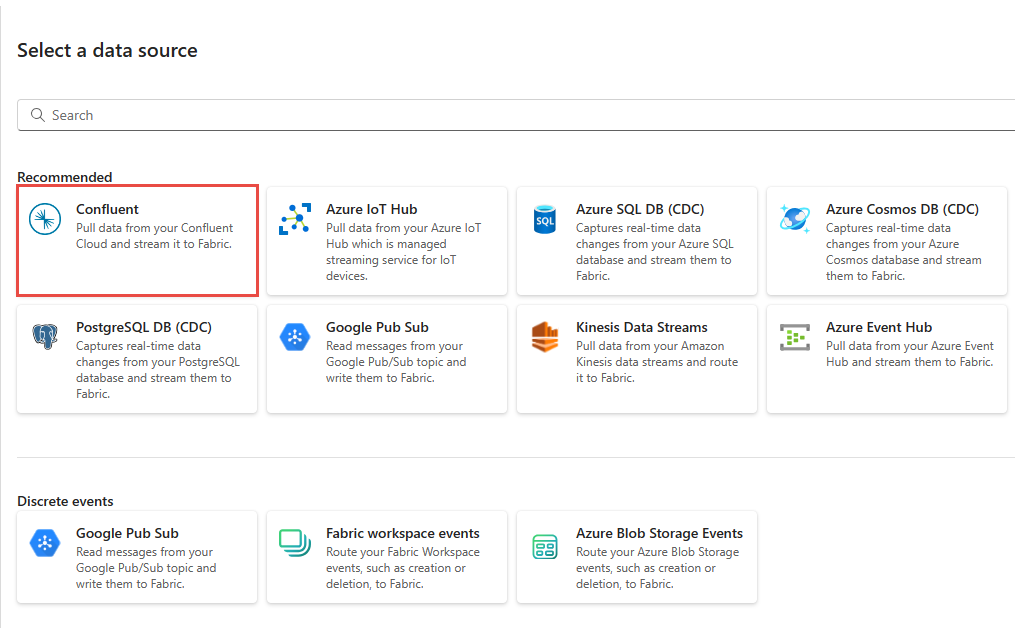
データ ソースの選択ウィザードを起動する
イベントストリームにまだソースを追加していない場合は、[外部ソースの使用] タイルを選択します。
![[外部ソースの使用] タイルの選択を示すスクリーンショット。](includes/media/select-external-source/select-use-external-source-tile.png#lightbox)
既に公開されているイベントストリームにソースを追加する場合は、編集モードに切り替え、リボンの [ソースの追加] を選択してから、[外部ソース] を選択します。
![[ソースの追加] の [外部ソース] メニューの選択を示すスクリーンショット。](includes/media/select-external-source/add-source-ribbon.png#lightbox)
Apache Kafka 用 Confluent Cloud の構成と接続
[ データ ソースの選択 ] ページで、 Confluent Cloud for Apache Kafka を選択します。
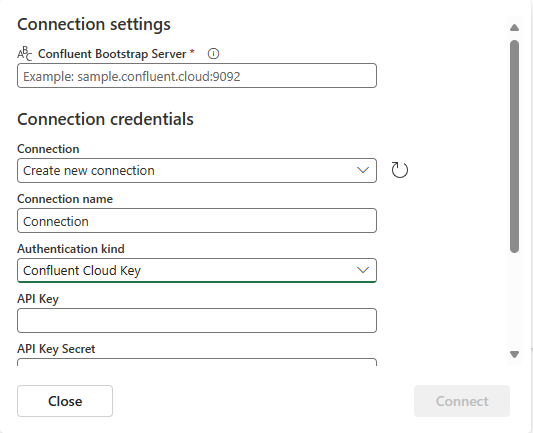
Confluent Cloud for Apache Kafka ソースへの接続を作成するには、[ 新しい接続] を選択します。
![イベントの取得ウィザードの [接続] ページで [新しい接続] リンクの選択を示すスクリーンショット。](includes/media/confluent-kafka-source-connector/new-connection-link.png)
[接続設定] セクションで、「Confluent Bootstrap Server」と入力します。 Confluent Cloud のホーム ページに移動し、[クラスター 設定] を選択し、アドレスをブートストラップ サーバーにコピーします。
[ 接続資格情報 ] セクションで、Confluent クラスターへの既存の接続がある場合は、[ 接続] のドロップダウン リストから選択します。 そうでない場合は、次の手順に従います。
- 接続名 には、接続の名前を入力します。
- [認証の種類] で、[Confluent クラウド キー] が選択されていることを確認します。
- API キーと API キー シークレットの場合:
Confluent クラウドに移動します。
サイド メニューで、[API キー] を選択します。
[追加] ボタンを選択すると、新しいルールが作成されます。
API キーとシークレットをコピーしておきます。
これらの値を [API キー] フィールドと [API キー シークレット] フィールドに貼り付けます。
[接続] を選択します
スクロールして、ページの 「 Confluent Cloud for Apache Kafka データ ソースの構成 」セクションを表示します。 Confluent データ ソースの構成を完了するための情報を入力します。
- [トピック名] に、Confluent Cloud のトピック名を入力します。 Confluent Cloud コンソールでトピックを作成または管理できます。
- コンシューマー グループの場合は、Confluent クラウドのコンシューマー グループを入力します。 Confluent Cloud クラスターからイベントを取得するための専用のコンシューマー グループが用意されています。
-
[自動オフセットのリセット] 設定で、次のいずれかの値を選択します。
最も古い – Confluent クラスターから使用可能な最も古いデータ
最新 – 利用可能な最新のデータ
なし – オフセットを自動的に設定しません。
![Confluent 接続設定の 2 番目のページ ([Confluent データ ソースの構成] ページ) を示すスクリーンショット。](includes/media/confluent-kafka-source-connector/configure-data-source.png)
[次へ] を選択します。 [確認と作成] 画面で、概要を確認し、[追加] を選択します。
Confluent Cloud for Apache Kafka ソースが 、編集モードでキャンバス上の eventstream に追加されていることがわかります。 この新しく追加された Confluent Cloud for Apache Kafka ソースを実装するには、リボンの [発行 ] を選択します。

これらの手順を完了すると、Confluent Cloud for Apache Kafka ソースを ライブ ビューで視覚化できるようになります。

制限事項
- スキーマ レジストリを使用した JSON 形式と Avro 形式の Confluent Cloud for Apache Kafka は現在サポートされていません。
- Confluent スキーマ レジストリを使用して Confluent Cloud for Apache Kafka からデータをデコードすることは現在サポートされていません。
関連するコンテンツ
その他のコネクタ。