コラボレーションとコミュニケーションアクティビティは、Microsoft 365 で大量の豊富なデータを生成します。 Microsoft Graph Data Connect を使用すると、organizationに関する分析情報を得ることができます。 Data Connect テンプレートを使用すると、データ分析情報を取得するために必要な時間を短縮し、独自のデータを使用してそれらの分析情報を強化できます。
Microsoft Graph Data Connect テンプレートは、Microsoft 365 データで可能性を実現し、付加価値を得る時間を短縮するのに役立ちます。 各テンプレートには、さまざまなユース ケースとビジネス シナリオに固有のリソースが含まれています。 これらのテンプレートを使用すると、次の作業を開始できます。
- エンティティセンチメント分析
- Outlook と Teams のデータからエンティティを抽出します。 次に、それらのエンティティに対するユーザーの気持ちを分析します。
- Synapse ワークスペース、Apache Spark プール、Azure Data Lake Storage アカウント、および Azure Cognitive Services リソースを設定します。
- 組織ネットワークの分析
- 組織が実際のビジネスの機敏性を達成するために重要なコラボレーションとコミュニケーション パターンを特定します。
- Synapse ワークスペース、Apache Spark プール、Azure Data Lake Storage アカウント リソースを設定します。
- 情報の過剰共有
- Microsoft 365 データの情報の過剰共有と詐欺のパターンを特定して、ビジネスをセキュリティで保護します。
- Synapse ワークスペース、Apache Spark プール、Azure Data Lake Storage アカウント リソースを設定します。
テンプレートは、Azure リソースをすばやくプロビジョニングし、すぐに価値を実現するために使用できるデータ パイプラインとサンプルを提供するのに役立ちます。
Microsoft Graph Data Connect テンプレートの詳細と使用を開始するには、 Data Connect ソリューション GitHub リポジトリを参照してください。
クイック スタート テンプレート
クイック スタート テンプレートを使用すると、Microsoft Graph Data Connect データセットを抽出するためのパイプラインを Azure リソースと共に簡単に設定してデプロイできます。 登録されたアプリケーションの詳細を使用して効率を高めるため、データ パイプラインの構成が高速になります。 現時点では、クイック スタート テンプレートでは、プラットフォームとしてのAzure Data Factoryとアクティビティの種類としてのコピー アクティビティのみがサポートされています。
前提条件
クイック スタート テンプレートを使用するには、次の前提条件が必要です。
- 構成された Microsoft Graph Data Connect アプリケーション。 Microsoft Graph Data Connect アプリケーションを作成する方法の詳細については、「 最初の Data Connect アプリケーションをビルドする」を参照してください。
- Microsoft Graph Data Connect アプリケーションの登録中に使用されるMicrosoft Entra アプリケーションのアプリケーション シークレット。 詳細については、「Microsoft Entra アプリケーションを設定する」を参照してください。
- データを書き込む Azure Storage コンテナー。 詳細については、「 Azure Storage リソースを設定する」を参照してください。
クイック スタート テンプレートを使用してパイプラインを設定する
パイプラインを設定するには:
- Azure Portal の Microsoft Graph Data Connect のホーム ページからアプリケーションを開き、[ クイック スタート テンプレート ] タブに移動します。
![Azure Portal の Microsoft Graph Data Connect 拡張機能の [クイック スタート テンプレート] タブの選択を示すスクリーンショット。](images/data-connect-templates-quickstart-1.png)
- [クイック パイプラインのセットアップ] テンプレートで、[開始] を選択します。
![Azure Portal の Microsoft Graph Data Connect 拡張機能の [クイック スタート テンプレート] タブ内のクイック パイプライン Set-Up テンプレートを示すスクリーンショット。](images/data-connect-templates-quickstart-2.png)
- 事前設定されたカスタム デプロイ フォームに残りの値を入力します。
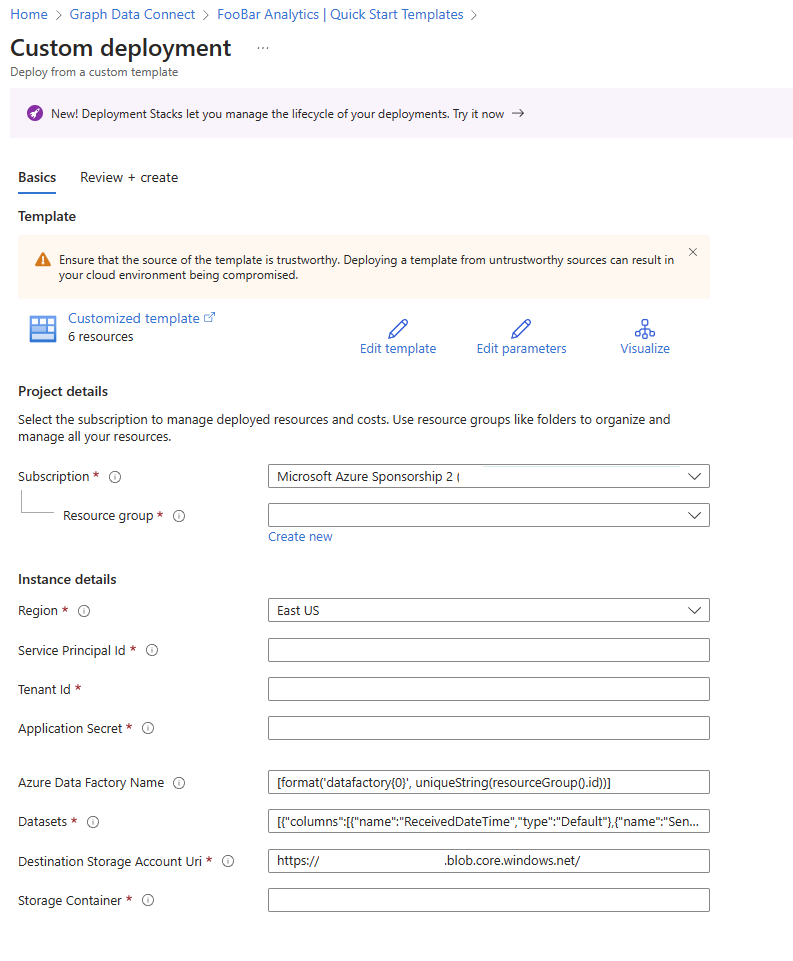
フォームには、次のフィールドが含まれています。
- リソース グループ: Azure Storage アカウントがあるリソース グループ。 同じ構成は、Azure Data Factoryの場所にも適用されます。
- サービス プリンシパル ID: Microsoft Graph Data Connect を使用してアプリケーションを作成するために使用されるMicrosoft Entra アプリケーション ID を示す事前設定されたフィールド。
- テナント ID: データが抽出されるテナントを示す事前設定されたフィールド。
- アプリケーション シークレット: 登録中に使用されるMicrosoft Entra アプリケーションのシークレット値。
- Azure Data Factory名: このフィールドは、リソース グループ ID に関連付けられている一意の文字列をデータファクトリに連結することによって事前設定されます。 既存のAzure Data Factory リソースを指定したり、新しいAzure Data Factory リソースの新しい一意の名前を入力したりすることもできます。
- データセット: 事前設定されたフィールド。 データセットごとに 1 つのパイプラインが生成されます。
- 宛先ストレージ アカウント URI: 事前設定されたフィールド。 登録済みアプリケーションに基づいて使用する URI (分散ファイル システム (DFS) または BLOB)。
- ストレージ コンテナー: データの書き込み先である Azure Storage の保存先のルート コンテナー。
- [ 確認と作成 ] タブを選択して、設定を確認します。 すべての詳細が正しいことを確認したら、[ 作成 ] ボタンを選択してデプロイを開始します。 デプロイの状態画面が表示され、リソースの作成が監視されます。
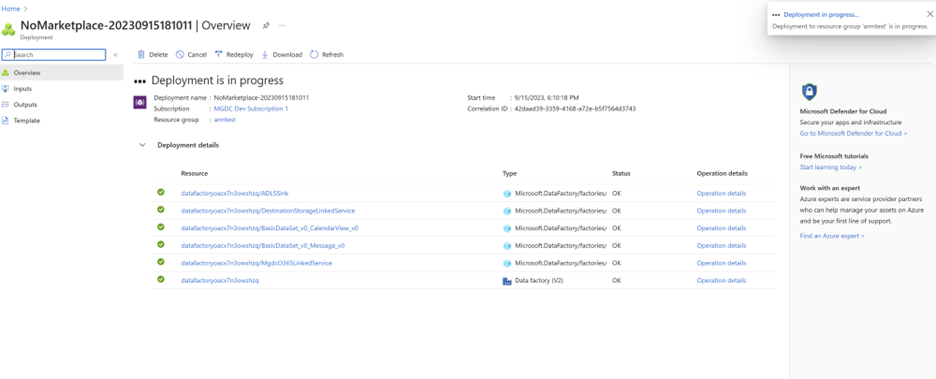
- 選択したリソース グループ内のAzure Data Factory リソースに移動します。 デプロイ中に新しいAzure Data Factory リソースが作成された場合は、[デプロイの詳細] セクションからリソース名を選択できます。
![[デプロイの詳細] セクション内のAzure Data Factory リソースの選択を示すスクリーンショット。](images/data-connect-templates-quickstart-6.png)
- パイプラインのコピー アクティビティ内でデータセットを選択し、抽出用のデータ フィルターを構成します。
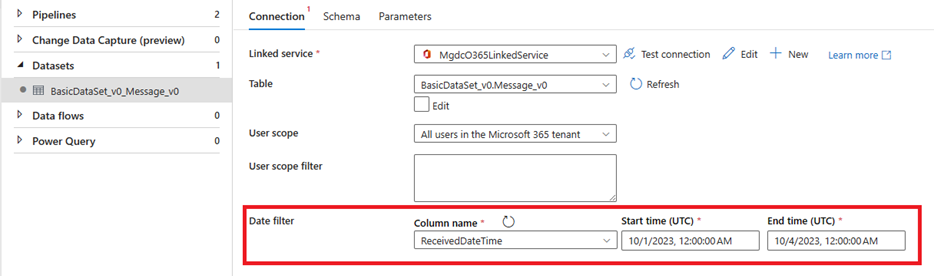
パイプラインをトリガーする前に、各コピー アクティビティを選択して、各データセットに適用可能なフィルターを構成します。 列フィルターの詳細については、「 Microsoft Graph Data Connect でのユーザーの選択とフィルター機能」を参照してください。
- [ トリガーの追加] ボタンを使用してパイプラインをトリガーします。
![Azure Data Factory パイプラインの [トリガーの追加] ボタンを強調表示したスクリーンショット。](images/data-connect-templates-quickstart-7.png)