プラグインは、各プロパティ* バッグのトップ レベル* スロット*を列*として処理し、bag_unpack1つの型*の列*をアンパックしますdynamic。 このプラグインは、evaluate 演算子を使用して呼び出されます。
構文
T|evaluatebag_unpack(Column [,OutputColumnPrefix ] [,columnsConflict ] [,ignoredProperties ] ) [:OutputSchema]
構文規則について詳しく知る。
パラメーター
| 件名 | タイプ | 必須 | 説明 |
|---|---|---|---|
| T | string |
✔️ | 列 Column をアンパックする表形式の入力。 |
| 列 | dynamic |
✔️ | アンパックする T の列。 |
| OutputColumnPrefix | string |
プラグインによって生成される、すべての列に追加する共通のプレフィックス。 | |
| columnsConflict | string |
列の競合解決の方向。 有効な値: error - クエリ*でエラー*が発生する (既定値*)replace_source - ソース列*が置き換えられるkeep_source - ソース列*が保持される |
|
| ignoredProperties | dynamic |
省略可能な一連のバッグ プロパティを無視します。 } | |
| OutputSchema |
bag_unpack プラグイン出力の列名と型を指定します。 構文については、「 出力スキーマの構文」を参照し、その影響を理解するには、「 パフォーマンスに関する考慮事項」を参照してください。 |
出力スキーマの構文
(
ColumnName:ColumnType [, ...])
次のように、最初のパラメーターとしてワイルドカード * を使用して、ソース テーブルのすべての列を出力に含めます。
(
*
,
ColumnName:ColumnType [, ...])
パフォーマンスに関する考慮事項
OutputSchema なしでプラグインを使用すると、大規模なデータセットでパフォーマンスに重大な影響を与える可能性があり、避ける必要があります。
OutputSchema を指定すると、入力データを解析して分析しなくても出力スキーマを判断できるため、クエリ エンジンはクエリの実行を最適化できます。 これは、入力データが大きい場合や複雑な場合に便利です。 定義された OutputSchema の有無にかかわらず、プラグインを使用した場合のパフォーマンスへの影響がある例を参照してください。
返品
bag_unpackプラグインは、表形式入力* (T) と同じ数のレコード*を含むテーブル*を返します (T)。 テーブル*のスキーマ*は、表形式入力*と同じスキーマ*に次の変更を加えたものです:
- 指定された入力*列* (Column) が削除*されます。
- 各列の名前は、各スロットの名前に対応し、必要に応じて OutputColumnPrefix でプレフィックスを付けます。
- 各列の型は、同じスロットのすべての値が同じ型を持つ場合はスロットの型か、値の種類が異なる場合は
dynamicです。 - スキーマは、 T の最上位プロパティ バッグ値に個別のスロットがある数の列で拡張されます。
注
- OutputSchema を指定しない場合、プラグインの出力スキーマは入力データの値によって異なります。 異なるデータ入力でプラグインを複数回実行すると、異なる出力スキーマが生成される可能性があります。
-
OutputSchema が指定されている場合、ワイルドカード
*を使用しない限り、プラグインは出力スキーマ構文で定義されている列のみを返します。 - 入力データのすべての列と OutputSchema で定義されている列を返すには、OutputSchema でワイルドカード
*を使用します。
表形式スキーマ規則は、入力データに適用されます。 特に次の点に違いがあります。
- 出力列名は、アンパックする列 (Column) でない限り、表形式の入力 T の既存の列と同じにすることはできません。 それ以外の場合、出力には同じ名前の 2 つの列が含まれます。
- 先頭に OutputColumnPrefix が付くスロット*名はすべて、有効な*エンティティ*名となり、識別子*の名前付けルール*に従っている必要があります。
プラグインは null 値を無視します。
例
このセクションの例では、構文を使用して作業を開始する方法を示します。
バッグを展開する:
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d)
出力
| 年齢 | 件名 |
|---|---|
| 20 | John |
| 40 | デイブ |
| 30 | ジャスミン |
バッグを展開し、 OutputColumnPrefix オプションを使用して、プレフィックス付きの列名を生成します。
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, 'Property_')
出力
| Property_Age | Property_Name |
|---|---|
| 20 | John |
| 40 | デイブ |
| 30 | ジャスミン |
バッグを展開し、 columnsConflict オプションを使用して、動的列と既存の列の間の列の競合を解決します。
datatable(Name:string, d:dynamic)
[
'Old_name', dynamic({"Name": "John", "Age":20}),
'Old_name', dynamic({"Name": "Dave", "Age":40}),
'Old_name', dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, columnsConflict='replace_source') // Use new name
出力
| 年齢 | 件名 |
|---|---|
| 20 | John |
| 40 | デイブ |
| 30 | ジャスミン |
datatable(Name:string, d:dynamic)
[
'Old_name', dynamic({"Name": "John", "Age":20}),
'Old_name', dynamic({"Name": "Dave", "Age":40}),
'Old_name', dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, columnsConflict='keep_source') // Keep old name
出力
| 年齢 | 件名 |
|---|---|
| 20 | Old_name |
| 40 | Old_name |
| 30 | Old_name |
バッグを展開し、 ignoredProperties オプションを使用して、プロパティ バッグ内のプロパティの 2 つを無視します。
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20, "Address": "Address-1" }),
dynamic({"Name": "Dave", "Age":40, "Address": "Address-2"}),
dynamic({"Name": "Jasmine", "Age":30, "Address": "Address-3"}),
]
// Ignore 'Age' and 'Address' properties
| evaluate bag_unpack(d, ignoredProperties=dynamic(['Address', 'Age']))
出力
| 件名 |
|---|
| John |
| デイブ |
| ジャスミン |
バッグを展開し、 OutputSchema オプションを使用します。
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d) : (Name:string, Age:long)
出力
| 件名 | 年齢 |
|---|---|
| John | 20 |
| デイブ | 40 |
| ジャスミン | 30 |
OutputSchema でバッグを展開し、ワイルドカード * オプションを使用します。
このクエリは、元のスロットの 説明 と OutputSchema で定義されている列を返します。
datatable(d:dynamic, Description: string)
[
dynamic({"Name": "John", "Age":20, "height":180}), "Student",
dynamic({"Name": "Dave", "Age":40, "height":160}), "Teacher",
dynamic({"Name": "Jasmine", "Age":30, "height":172}), "Student",
]
| evaluate bag_unpack(d) : (*, Name:string, Age:long)
出力
| 説明 | 件名 | 年齢 |
|---|---|---|
| 学生 | John | 20 |
| 教師 | デイブ | 40 |
| 学生 | ジャスミン | 30 |
パフォーマンスに影響を与える例
定義された OutputSchema の有無にかかわらずバッグを展開して、パフォーマンスへの影響を比較します。
この例では、 ヘルプ クラスターで一般公開されているテーブルを使用します。 ContosoSales データベースには、SalesDynamic というテーブルがあります。 テーブルには売上データが含まれており、 Customer_Propertiesという名前の動的列が含まれています。
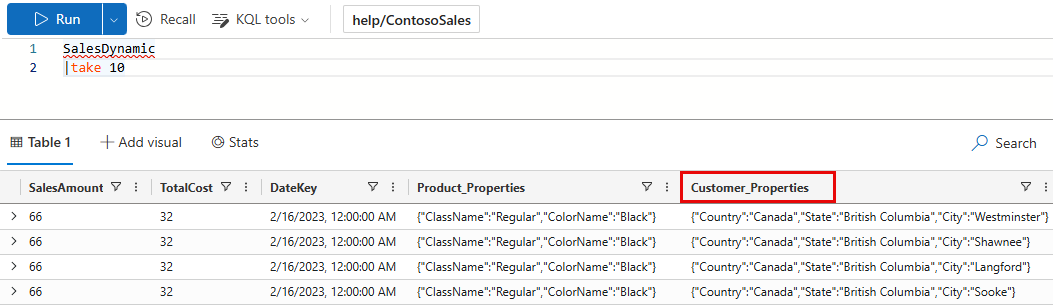
出力スキーマがない例: 最初のクエリでは OutputSchema は定義されません。 クエリの CPU 時間は 5.84 秒で、 36.39 MB のデータがスキャンされます。
SalesDynamic | evaluate bag_unpack(Customer_Properties) | summarize Sales=sum(SalesAmount) by Country, State出力スキーマの例: 2 番目のクエリでは OutputSchema が提供されます。 クエリの CPU 時間は 0.45 秒で、 19.31 MB のデータがスキャンされます。 クエリは入力テーブルを分析する必要がないため、処理時間が節約されます。
SalesDynamic | evaluate bag_unpack(Customer_Properties) : (*, Country:string, State:string, City:string) | summarize Sales=sum(SalesAmount) by Country, State
出力
出力は両方のクエリで同じです。 出力の最初の 10 行を次に示します。
| カナダ | ブリティッシュ・コロンビア州 | 56,101,083 |
|---|---|---|
| イギリス | イングランド | 77,288,747 |
| オーストラリア | ビクトリア | 31,242,423 |
| オーストラリア | クイーンズランド | 27,617,822 |
| オーストラリア | 南オーストラリア州 | 8,530,537 |
| オーストラリア | ニューサウスウェールズ州 | 54,765,786 |
| オーストラリア | タスマニア | 3,704,648 |
| カナダ | アルバータ州 | 375,061 |
| カナダ | オンタリオ | 38,282 |
| 米国 | ワシントン | 80,544,870 |
| ... | ... | ... |
関連コンテンツ
- parse_json 関数の
- mv-expand 演算子 を する