適用対象: ✓ すべてのカスタム モデル |✓すべての事前構築済みモデル
Microsoft Syntexでは、ドキュメント処理はモデルから始まります。これは、SharePoint ドキュメント ライブラリに格納されているドキュメントの識別、分類、抽出に役立つ強力なツールです。 これらのモデルは、非構造化コンテンツを構造化された使用可能なデータに変換するための基盤です。
SharePoint ライブラリにモデルを適用すると、抽出される情報の構造を定義するコンテンツ タイプにリンクされます。 抽出されたデータを格納するための列を含むこのコンテンツ タイプは、SharePoint コンテンツ タイプ ギャラリーに保存されます。 ニーズに合わせてカスタマイズされた新しいコンテンツ タイプを作成したり、既存のコンテンツ タイプを使用してスキーマを再利用したり、organization全体で一貫性を維持したりできます。
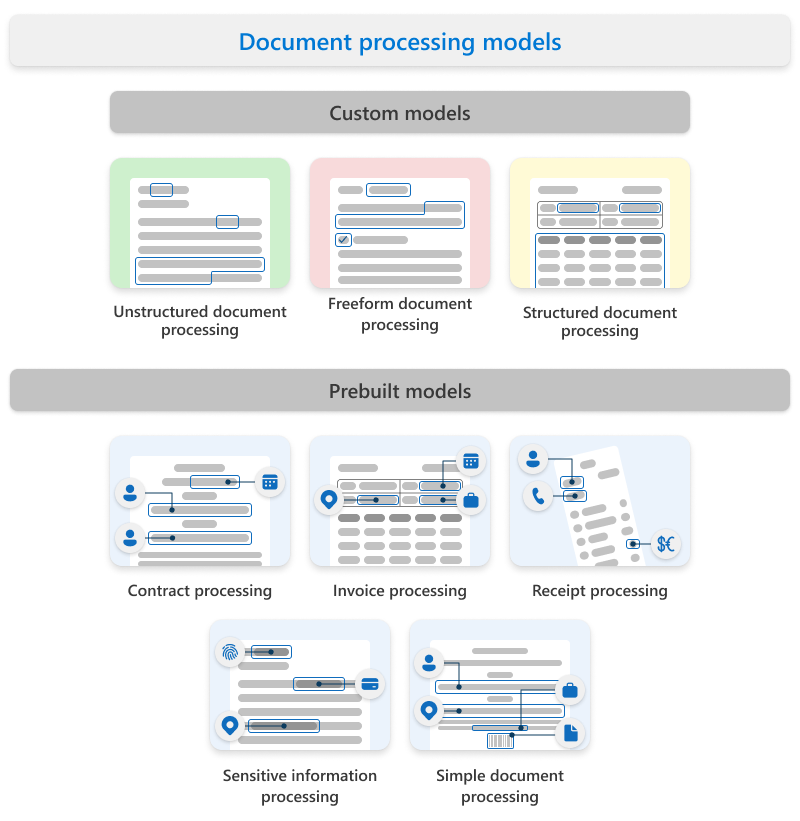
Microsoft Syntexでは、カスタム モデルと事前構築済みモデルが使用されます。
モデルは、ニーズと管理する場所に応じて 2 つの方法で作成できます。 エンタープライズ モデルは コンテンツ センターで作成および管理されるため、複数の SharePoint サイト間で再利用できます。 一方、ローカル モデルはサイト上の SharePoint ドキュメント ライブラリ内に直接作成され、その特定のライブラリにスコープが設定されます。 これにより、一元的な制御とローカライズされたカスタマイズのどちらを必要とするかに基づいて、適切なモデルの種類を柔軟に選択できます。
カスタム モデル
選択するカスタム モデルの種類は、操作するファイルの種類、それらのファイルの構造と形式、およびモデルを適用する SharePoint の場所によって異なります。
カスタム モデルには、次のものが含まれます。
カスタム モデルのサイド バイ サイドの違いを表示するには、「カスタム モデルの 比較」を参照してください。
非構造化ドキュメント処理
一貫性のあるレイアウトに従わないが、識別可能なフレーズやパターンを含む文字やコントラクトなどのドキュメントを操作する場合は、非構造化ドキュメント処理モデルを使用します。 このモデルでは、ドキュメントが自動的に分類され、テキスト パターンに基づいて関連情報が抽出されます。
たとえば、契約更新レターの形式は異なる場合がありますが、一貫して "サービスの開始日" などの語句の後に日付が含まれます。 モデルでは、このようなパターンを使用して、ドキュメントの種類 (分類) と抽出するデータ (抽出元) の両方を決定します。
- 最適: 認識可能なテキスト パターンを持つ非構造化ドキュメント。
- ファイルのサポート: ファイルの種類の範囲が最も広い。
- 言語のサポート: 40 を超える言語。
- セットアップ: [単一クラス モデル ] オプションを使用します。
詳細については、「 非構造化ドキュメント処理の概要」を参照してください。
フリーフォームドキュメント処理
フリーフォーム ドキュメント処理モデルは、スキャンされた文字、FAX、PDF など、任意の場所にデータを表示できるドキュメントから情報を抽出するのに最適です。 非構造化モデルとは異なり、フリーフォーム モデルはドキュメントの種類を分類しません。データの抽出のみに焦点を当てています。
これらのモデルは、Microsoft Power Apps AI Builder を使用して構築されており、さまざまなソースから大量の受信ドキュメントを処理する場合に特に便利です。
- 最適な対象: 分類が必要ない PDF またはイメージ ファイル。
- ファイルのサポート: PDF 形式と画像形式。
- 言語のサポート: 40 を超える言語。
- セットアップ: フリーフォーム抽出モデル オプションを使用します。
- 可用性: リージョンによって異なります。
詳細については、「 構造化および自由形式のドキュメント処理の概要」を参照してください。
構造化ドキュメント処理
フォームや請求書など、一貫性のあるレイアウトのドキュメントの構造化ドキュメント処理モデルを選択します。 このモデルは、ドキュメント内の固定位置に基づいてフィールドとテーブルの値を識別します。
Microsoft Power Apps AI Builder を使用して構築された構造化モデルは、サンプル ドキュメントから学習し、将来のファイル内の同様の場所からデータを抽出します。 たとえば、税務フォームでは、社会保障番号が常に同じ場所に配置される場合があります。
- 最適: フォームなどの構造化ドキュメントまたは半構造化ドキュメント。
- ファイルのサポート: 一貫性のあるレイアウトでForms。
- 言語のサポート: サポートされている言語の範囲が最も広い。
- セットアップ: 構造化抽出モデル オプションを使用します。
詳細については、「 構造化および自由形式のドキュメント処理の概要」を参照してください。
事前構築済みモデル
カスタム モデルに加えて、Microsoft Syntexには、一般的なビジネス ドキュメントから構造化された情報を抽出するためのすぐに使用できる一連の事前構築済みモデルが用意されています。 これらのモデルは手動トレーニングまたは構成の必要性を除去することによって時間および労力を節約するように設計されている。
事前構築済みモデルには、次のものが含まれます。
契約処理
コントラクト処理モデルは、コントラクト ドキュメントから重要な情報を分析および抽出するように設計されています。 さまざまな形式で機能し、次のような重要なコントラクトの詳細を識別します。
- クライアントまたはパーティー名
- 請求先住所
- 管轄
- 有効期限
このモデルは、大量の契約を管理する法務チーム、調達チーム、または運用チームに最適です。
詳細については、「 事前構築済みモデルを使用してコントラクトから情報を抽出する」を参照してください。
請求書処理
請求書処理モデルは、売上請求書から重要なデータを抽出し、買掛金勘定ワークフローを合理化するのに役立ちます。 次のような情報を識別できます。
- 顧客名
- 請求先住所
- 期限
- 支払期日の金額
このモデルは、請求書の取り込みを自動化し、手動データ入力を減らすための財務チームに特に役立ちます。
詳細については、「 事前構築済みモデルを使用して請求書から情報を抽出する」を参照してください。
領収書処理
レシート処理モデルでは、印刷されたレシートと手書きのレシートの両方が処理され、次のような重要なトランザクションの詳細が抽出されます。
- マーチャント名
- 販売者の電話番号
- トランザクションの日付
- 税金と合計金額
このモデルは、経費報告および払い戻しワークフローに適しています。
詳細については、「 事前構築済みモデルを使用して領収書から情報を抽出する」を参照してください。
機密情報の処理
機密情報処理モデルは、ドキュメントから個人データと機密データを特定して抽出するのに役立ちます。 次のような情報を検出できます。
- 社会保障番号
- 財務勘定番号
- 運転免許証 ID
- その他の個人を特定できる情報 (PII)
このモデルは、organization全体のコンプライアンスとデータ保護の取り組みをサポートします。
詳細については、「 事前構築済みモデルを使用してドキュメントから機密情報を検出する」を参照してください。
簡単なドキュメント処理
シンプルなドキュメント処理モデルは、次のような情報を抽出するための柔軟で事前にトレーニングされたソリューションを提供します。
- キーと値のペア
- 選択マーク (チェック ボックスなど)
- 名前付きエンティティ
- バーコード
- 言語検出
固定スキーマを持つ他の事前構築済みモデルとは異なり、このモデルはさまざまな構造化ドキュメントに適応し、カスタム ラベル付けが実現できない場合に最適な代替手段です。
詳細については、「 事前構築済みモデルを使用してドキュメントから機密情報を検出する」を参照してください。