SpeechRecognition API は、メディア ファイルやデバイス マイクなどのオーディオ ソースから、Web サイトまたはブラウザー拡張機能の JavaScript コードから直接音声をテキストに変換できる標準の Web API です。 この記事では、Microsoft Edge に組み込まれているデバイス上 (またはローカル) の音声認識モデルで SpeechRecognition API を使用することに重点を置いています。
API の詳細については、 MDN の Web Speech API に関するページを参照してください。
詳細な内容:
- ローカル音声認識モデルの可用性
- ローカル音声認識モデルの利点
- Microsoft Edge でローカル音声認識を有効にする
- 動作する例を見る
- Web サイトでローカル認識で SpeechRecognition API を使用する
- フィードバック送信
- 関連項目
ローカル音声認識モデルの可用性
ローカル音声認識モデルは、Microsoft Edge Canary または Dev (バージョン 150.0.4076 以降) で使用できます。 「Microsoft Edge Insider になる」を参照してください。
ローカル音声認識モデルの利点
Microsoft Edge のローカル モデルで SpeechRecognition API を使用する場合、音声認識は、音声がキャプチャされたのと同じデバイスで行われます。 このアプローチには、クラウドベースのソリューションと比較して次の利点があります。
コストの削減: クラウド認識サービスの使用に関連するコストはありません。
ネットワークの独立性: 最初のモデルのダウンロード以外に、この API を使用して音声を変換する場合のネットワーク待機時間はなく、デバイスがオフラインのときに API を使用することもできます。
プライバシーの強化: モデルへの音声入力はデバイスから離れることはなく、AI モデルをトレーニングするために収集されません。
モデルの可用性
Web サイトが SpeechRecognition API でローカル音声認識モデルを初めて使用する場合は、モデルの初回ダウンロードが必要です。
SpeechRecognition API install() メソッドによって返される promise を使用して、モデルのダウンロードを監視できます。 以下の「 ローカル モデルが既にインストールされているかどうかを確認する」を参照してください。
Microsoft Edge でローカル音声認識を有効にする
SpeechRecognition API でローカル音声認識モデルを使用するには、Microsoft Edge Canary または Dev で機能を有効にする必要があります。 デバイス上のモデルを使用して音声認識を有効にするには:
Microsoft Edge Canary または Dev (バージョン 150.0.4076 以降) を使用していることを確認します。 「Microsoft Edge Insider になる」を参照してください。
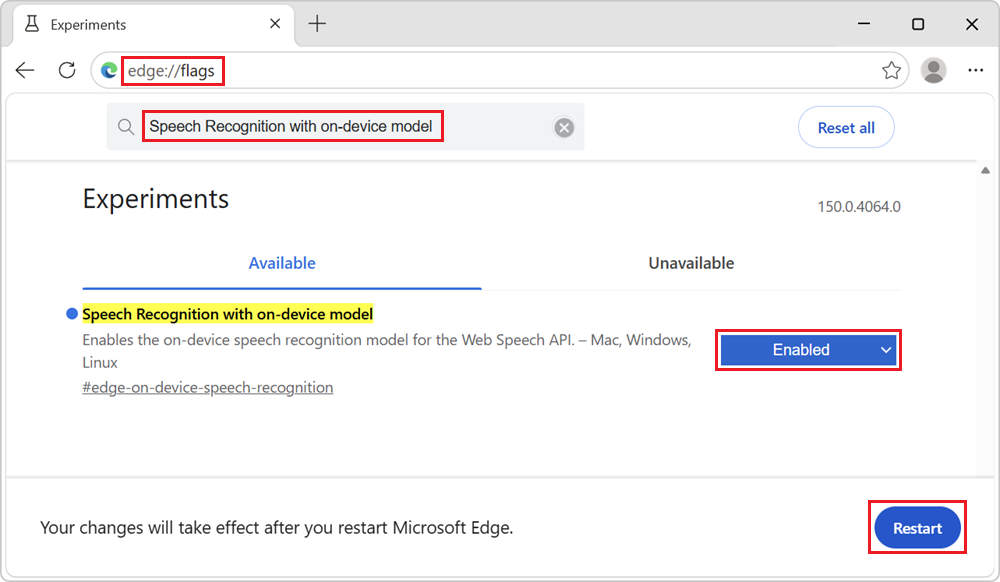
Microsoft Edge Canary または Dev で、新しいタブまたはウィンドウを開き、
edge://flagsに移動します。ページの上部にある検索ボックスに、「 デバイス上のモデルを使用した音声認識」と入力します。
[ デバイス上のモデルを使用した音声認識 ] ドロップダウン リストで、[ 有効] を選択し、右下の [再起動 ] ボタンをクリックします。
動作する例を見る
SpeechRecognition API の動作を確認し、デモ コードを表示するには:
上記のように、Microsoft Edge でローカル音声認識を有効にします。
Microsoft Edge Canary または Dev で、タブまたはウィンドウを開き、 SpeechRecognition API プレイグラウンドに移動します。
上部の情報バナーで、状態をチェックします。最初は SpeechRecognition API の準備完了と読み取ります。[開始] をクリックして開始します。
[ 入力言語 ] ドロップダウン リストで、音声認識に使用する言語を選択します。
[ オーディオ ソース ] ドロップダウン リストで、音声認識用のオーディオ ソースを選択します。
- [ マイク ] を選択して、オーディオ ソースとしてデバイス マイクを使用します。
- [ ファイル] を 選択して、デバイスのオーディオ ファイルまたはビデオ ファイルをオーディオ ソースとして使用します。
オーディオ ソースとして [ファイル ] を選択した場合は、[ メディア ファイル ] セクションが表示されます。 [ ファイルの選択 ] ボタンをクリックし、デバイスからオーディオまたはビデオ ファイルを選択します。
[スタート] ボタンをクリックします。
選択した言語のローカル音声認識モデルをまだダウンロードしていない場合は、ダウンロードが開始され、情報バナーに en-US 用のデバイス上のモデルのインストールが読み込まれます。
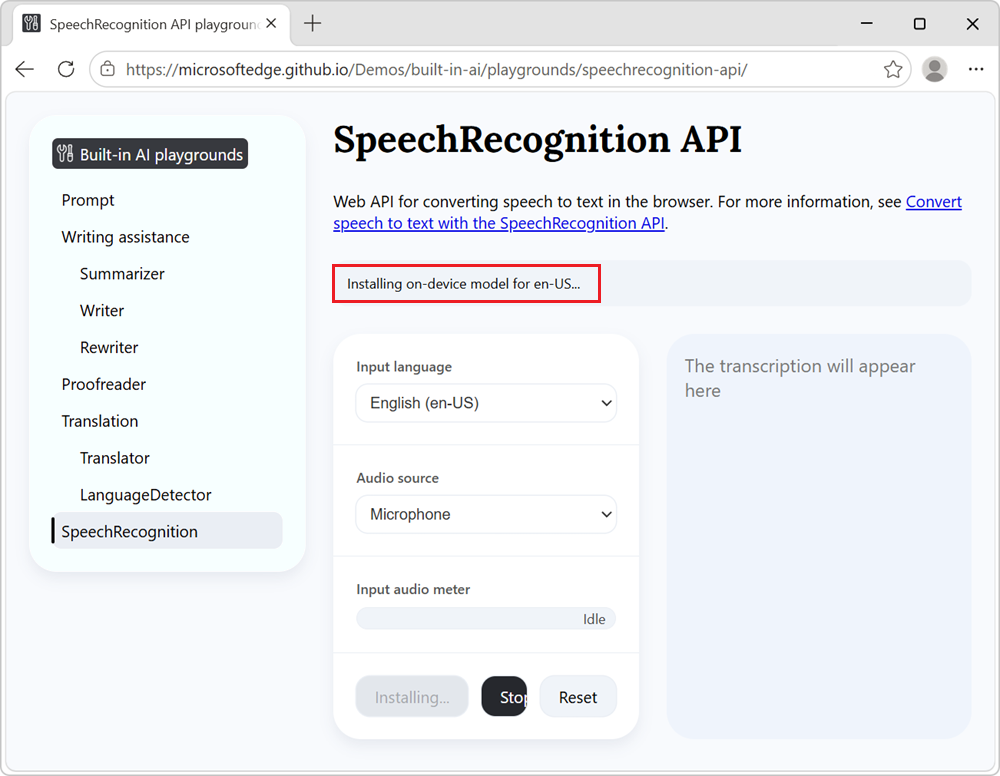
モデルがインストールされると、テキスト文字起こしがページに表示されます。
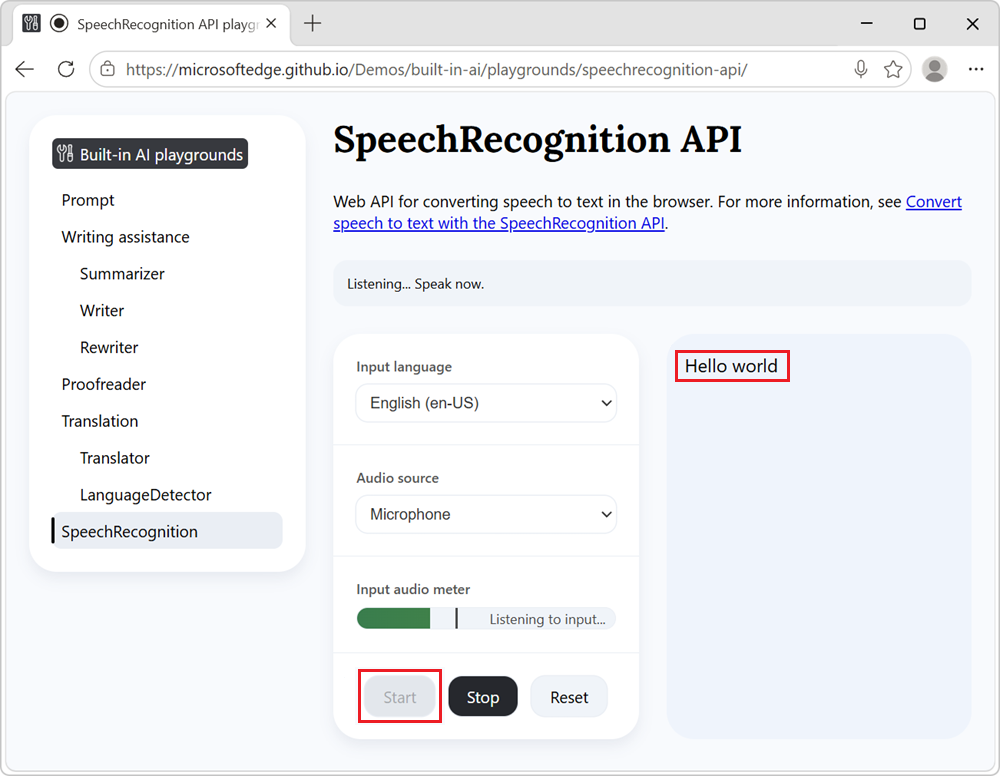
音声のテキストへの変換を停止するには、いつでも [停止 ] ボタンをクリックします。
文字起こしは、入力オーディオで長時間無音の後に自動的に停止する場合もあります。
関連項目:
- /built-in-ai/playgrounds/speechrecognition-api/ - SpeechRecognition API playground デモのソース コード。
Web サイトでローカル認識で SpeechRecognition API を使用する
次のセクションでは、Web サイトのコードで、ローカル音声認識で SpeechRecognition API を使用する方法について説明します。 API 自体の詳細については、 MDN の Web Speech API に関するページを参照してください。
API がサポートされているかどうかを確認し、SpeechRecognition オブジェクトをインスタンス化する
ブラウザーで SpeechRecognition API がサポートされていることを確認するには、 SpeechRecognition オブジェクトが使用可能かどうかをテストします。
if (!window.SpeechRecognition) {
console.log("The SpeechRecognition API is not available in this browser.");
} else {
console.log("The SpeechRecognition API is available.");
}
API がサポートされている場合は、新しい SpeechRecognition インスタンスを作成して API の使用を開始します。
const recognition = new SpeechRecognition();
関連項目:
入力言語を選択し、ローカル認識にオプトインする
ローカル モデルを使用して音声認識を構成するには、入力言語を指定し、 processLocally オプションを設定します。
recognition.lang = "en-US";
recognition.processLocally = true;
Microsoft Edge 150.0.4076 の時点で、ローカル音声認識では次の入力言語がサポートされています。
- 英語 (en-US)
- ドイツ語 (de-DE)
- イタリア語 (it-IT)
- ポルトガル語 (pt-PT)
- スペイン語 (es-ES)
- 韓国語 (ko-KR)
言語のサポートは、今後のバージョンで拡張される予定です。
また、 continuous オプションと interimResults オプションを true に設定して、停止せずに長いオーディオ セッションを文字起こしし、中間結果を受け取ります。
recognition.continuous = true;
recognition.interimResults = true;
関連項目:
- SpeechRecognition: lang プロパティ(MDN)。
- SpeechRecognition: processLocally プロパティ(MDN)。
- SpeechRecognition: MDN での継続的プロパティ。
- SpeechRecognition: interimResults プロパティ(MDN)。
ローカル モデルが既にインストールされているかどうかを確認する
認識を開始する前に、SpeechRecognition.available() メソッドを使用して、選択した言語でローカル モデルを使用できるかどうかをチェックします。
モデルがまだインストールされていない場合は、 SpeechRecognition.install() メソッドを使用してインストールをトリガーし、認識を開始する前にモデルが完了するのを待ちます。
async function ensureModelReady(lang) {
// Check if the model is already available.
const availability = await SpeechRecognition.available({
langs: [lang],
processLocally: true,
});
// If the model is already available, proceed to recognition.
if (availability === "available") {
return true;
}
// If the model is not available but can be downloaded,
// trigger the installation and wait for it to complete
// before proceeding to recognition.
if (availability === "downloadable" || availability === "downloading") {
const installed = await SpeechRecognition.install({
langs: [lang],
processLocally: true,
});
if (!installed) {
throw new Error(`Failed to install local model for ${lang}.`);
}
return true;
}
return false;
}
SpeechRecognition.install()によって返される promise は、インストールが成功または失敗したときに解決されます。
関連項目:
音声認識を開始する
API とモデルの両方の準備ができたら、認識を開始するには、 start() メソッドを使用します。
パラメーターなしで呼び出されると、 start() メソッドはユーザーのマイクからのオーディオを認識します。
recognition.start();
ユーザーのマイクではなくメディア ファイルからオーディオを認識するには、 MediaStreamTrack インスタンスを引数として start() メソッドに渡します。 たとえば、WebAudio API を使用してMediaStreamDestinationNode インスタンスを作成することで、MediaStreamTrack インスタンスを作成できます。
const audioContext = new AudioContext();
const mediaStreamDestination = audioContext.createMediaStreamDestination();
recognition.start(mediaStreamDestination.stream.getAudioTracks()[0]);
関連項目:
認識を明示的に停止し、メディア側で停止する
認識を停止するには、 stop() メソッドを使用します。
recognition.stop();
また、入力として使用しているメディア要素の onended イベント ハンドラーを使用して、メディア入力の終了時に認識を停止することもできます。 たとえば、オーディオ ソースとして HTMLAudioElement または HTMLVideoElement を使用している場合は、次のようにイベント ハンドラーを設定できます。
mediaElement.onended = () => recognition.stop();
関連項目:
フィードバックの送信
次に関するご意見をお寄せください。
- ローカル音声認識モデル。
- ローカル音声認識モデルのパフォーマンス。
- ユース ケースに関して確認するその他の機能強化。
SpeechRecognition API フィードバックの問題にコメントを追加して、フィードバックを送信してください。
関連項目
マイクロソフト:
Mdn:
Github: