Jira Data Center Microsoft Graph コネクタを使用すると、organizationで Jira Data Center の問題と関連データのインデックスを作成できるため、Microsoft 365 エコシステム内で簡単に検出および実行可能になります。
この記事は、Jira Data Center Microsoft Graph コネクタの構成、実行、監視を担当する Microsoft 365 管理者を対象としています。 これは、Microsoft 365 管理センターでの Microsoft Graph コネクタのセットアップに関するページに記載されている一般的な手順を補完します。
注:
Jira Data Center コネクタはパブリック プレビュー段階です。 アクセスして試したい場合は、管理 アカウントの対象リリース リングを有効にする必要があります。
機能
強化された Copilot 機能: ユーザーは、Microsoft 365 Copilotの Jira の問題とプロジェクト データに関する自然言語の質問を行うことができます。 例:
「プロジェクト アルファの未解決の問題を要約します。
「今週提出されたすべての優先度の高いバグを表示してください。
セマンティック検索のサポート: ユーザーは、Microsoft Search 内で自然言語クエリを入力して、Jira の問題やプロジェクトに関する関連性の高いコンテキストリッチな応答を取得できます。
注:
Jira Data Center バージョン 8.14 以降とのみ互換性があります。
Jira Data Center Microsoft Graph コネクタを使用することで、チームは、強力な Microsoft Search と Copilot の機能を利用しながら、Jira 環境をオンプレミスに保ち、重要な問題とプロジェクトの詳細をすぐに検出して実用的にすることができます。
前提条件
1. Microsoft Graph コネクタ エージェント (GCA) をインストールする
Jira Data Center コンテンツのインデックスを作成するには、Jira Data Center サイトと同じネットワーク内の Windows マシンに GCA をインストールする必要があります。 「Microsoft Graph コネクタ エージェントをインストールする」を参照してください。 organizationの Microsoft 365 テナントの管理者であり、organizationの Jira サイトの管理者である必要があります。
注:
以前に GCA をインストールしている場合は、バージョン 3.1.3.0 以降に更新されていることを確認してください。
2. Jira Data Center プラグインをインストールする
Microsoft Graph Connector for Jira Data Center から Jira Data Center プラグインをインストールする |Atlassian Marketplace のインストール 手順に従います。
はじめに
1. 表示名
表示名は、ユーザーが Copilot 内の関連付けられているファイルまたはアイテムを簡単に認識し、信頼できるコンテンツを示すのに役立ちます。 表示名は、 コンテンツ ソース フィルターとしても使用されます。 このフィールドには既定値が存在しますが、organizationのユーザーが認識する名前にカスタマイズできます。
2. Jira Data Center の URL
Jira Data Center データに接続するには、organizationの Jira Data Center インスタンス URL (通常はhttps://<your-organization-domain>.com形式) を使用します。
3. Graph コネクタ エージェント (GCA)
グラフ コネクタ エージェントは、Jira Data Center インスタンスとコネクタ API の間のブリッジとして機能し、安全で効率的なデータ転送を可能にします。 この手順では、コネクタに使用するエージェント構成を選択します。 「Microsoft Graph コネクタ エージェントをインストールする」を参照してください。
4. 認証の種類
現在、OAuth 2.0 は接続セットアップでサポートされています。 接続セットアップでクライアント ID とクライアント シークレットを入力するには、以下の手順を参照して取得します。
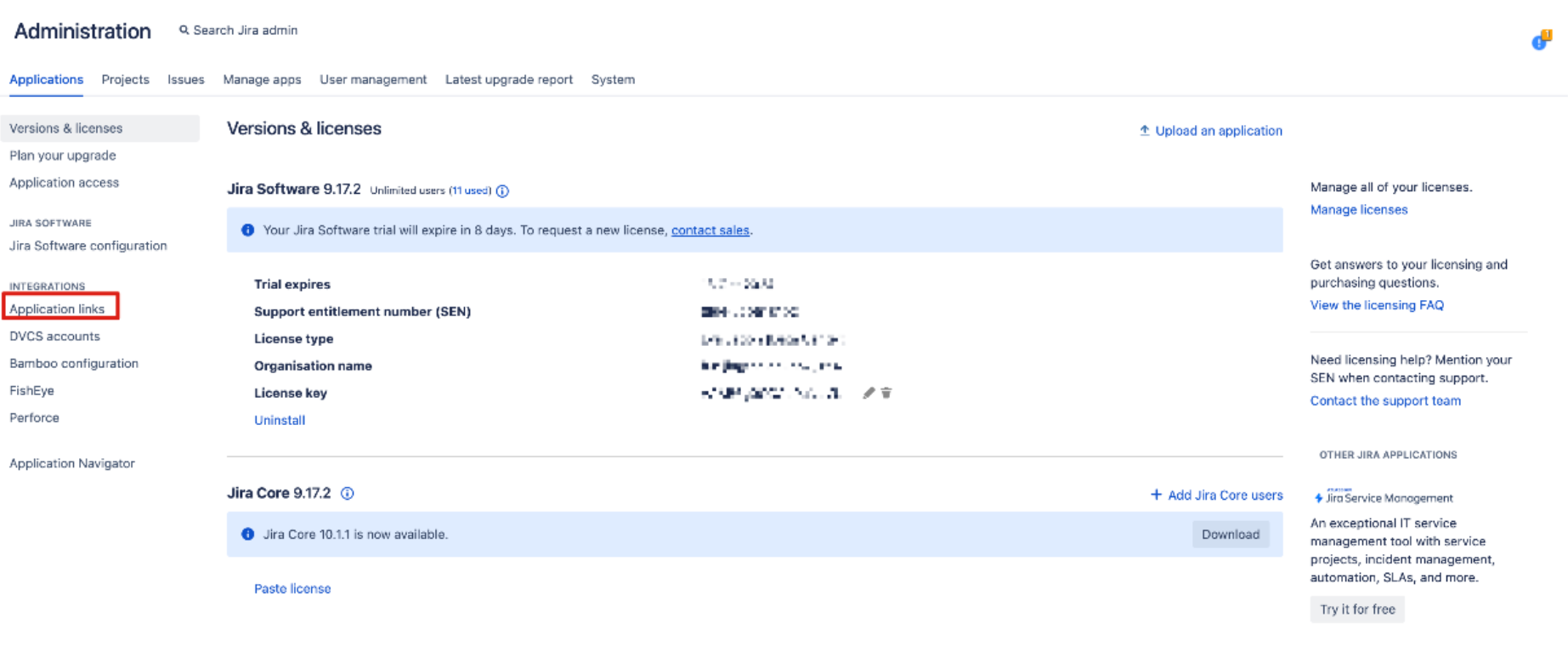
Jira データ センターにログインします。
[設定] アイコン -> [アプリケーションをクリック] -> [アプリケーション リンクをクリック] をクリックします。
![[アプリケーションのクリック] のスクリーンショット。](media/jira-data-center-gc-screenshot-1.png)
[ 作成] リンクを選択します。
![{[作成] リンクの選択のスクリーンショット。}](media/jira-data-center-gc-screenshot-3.png)
[ 外部アプリケーション ] を選択し、方向として [ 受信 ] を選択します。
![{[外部アプリケーションの選択] のスクリーンショット。方向として [受信] を選択します。](media/jira-data-center-gc-screenshot-4.png)
[受信リンクの構成] フォームに入力します。
- リダイレクト URL: M365 Enterprise の場合は、
https://gcs.office.com/v1.0/admin/oauth/callback。 - スコープ: 管理
![{[受信リンクの構成] フォームの入力のスクリーンショット。}](media/jira-data-center-gc-screenshot-5.png)
- リダイレクト URL: M365 Enterprise の場合は、
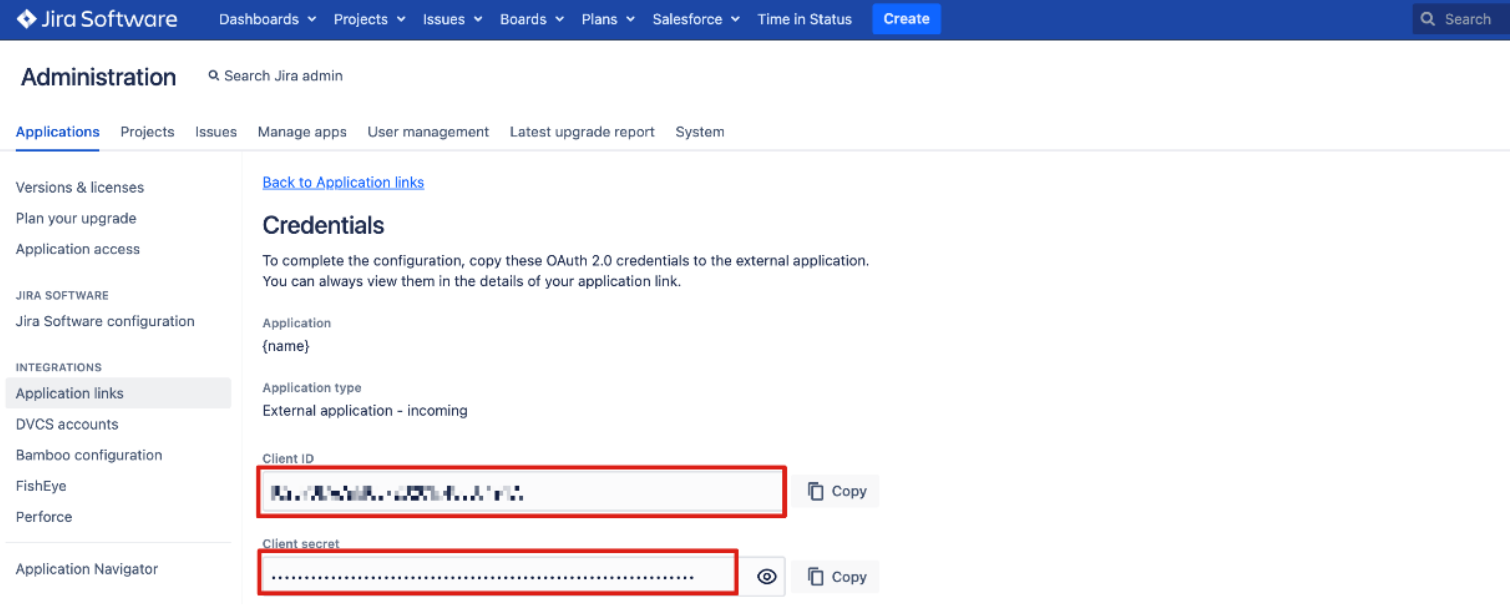
[資格情報] ページで指定したクライアント ID とシークレットをコピーし、Jira Data Center 接続セットアップ ページの対応するフィールドに貼り付けます。
![[アプリケーションのクリック] のスクリーンショット。](media/jira-data-center-gc-screenshot-1.png#lightbox)

![{[作成] リンクの選択のスクリーンショット。}](media/jira-data-center-gc-screenshot-3.png#lightbox)
![{[外部アプリケーションの選択] のスクリーンショット。方向として [受信] を選択します。](media/jira-data-center-gc-screenshot-4.png#lightbox)
![{[受信リンクの構成] フォームの入力のスクリーンショット。}](media/jira-data-center-gc-screenshot-5.png#lightbox)

5. 限定対象ユーザーへのロールアウト
ロールアウトを広範な対象ユーザーに展開する前に、Copilot やその他の Search サーフェスで検証する場合は、制限付きユーザー ベースにこの接続をデプロイします。 制限付きロールアウトの詳細については、 こちらをクリックしてください。
この時点で、Jira Data Center の接続を作成する準備ができました。 通知を確認し、[ 作成 ] ボタンをクリックすると、Microsoft Graph コネクタが Jira Data Center サイトからのデータのインデックス作成を開始します。
その他の設定では、Jira Data Center データで最適に動作するものに基づいて既定値を設定します。 既定値は次のとおりです。
| Page | 設定 | 既定値 |
|---|---|---|
| ユーザー | アクセス許可 | このデータ ソースにアクセスできるユーザーのみ。 |
| ユーザー | ID のマップ | Microsoft Entra ID を使用してマップされたデータ ソース ID。 |
| コンテンツ | Filter | すべてのプロジェクト |
| コンテンツ | プロパティの管理 | 既定のプロパティとそのスキーマをチェックするには、ここをクリックします。 |
| 同期 | 増分クロール | 頻度: 15 分ごと |
| 同期 | フル クロール | 頻度: 毎日 |
これらの値のいずれかを編集する場合は、[ カスタム セットアップ] オプションを選択する必要があります。
カスタム セットアップ
カスタム セットアップを使用すると、管理者は上記の既定値を編集できます。 [カスタム セットアップ] オプションをクリックすると、[ユーザー]、[コンテンツ]、[同期] の 3 つのタブが表示されます。
ユーザー
アクセス許可
Jira Data Center Microsoft Graph コネクタでは、このデータ ソース (推奨) または Everyone へのアクセス権を持つユーザーのみが表示できるデータがサポートされています。 [すべてのユーザー] を選択すると、すべてのユーザーの検索結果にインデックス付きデータが表示されます。
[このデータ ソースへのアクセス権を持つユーザーのみ] を選択した場合は、Jira Data Center にプロビジョニングされたユーザーと AAD 以外のユーザー Microsoft Entra IDするかどうかをさらに選択する必要があります。
organizationに適したオプションを特定するには:
Jira Data Center ユーザーの電子メール ID が、Microsoft Entra IDのユーザーの UserPrincipalName (UPN) と同じである場合は、Microsoft Entra ID オプションを選択します。
Confluence ユーザーのメール ID が、Microsoft Entra IDのユーザーの UserPrincipalName (UPN) と異なる場合は、AAD 以外のオプションを選択します。
重要
- id ソースの種類としてMicrosoft Entra IDを選択した場合、コネクタは、Jira Data Center から直接取得したユーザーの電子メール ID を、Microsoft Entra IDから UPN プロパティにマップします。
- ID の種類に "非 AAD" を選択した場合は、ID のマッピング手順については、「Azure 以外の AD ID をマップする」を参照してください。 このオプションを使用して、メール ID から UPN へのマッピング正規表現を指定できます。
- アクセス許可を管理するユーザーまたはグループへのUpdatesは、フル クロールでのみ同期されます。 増分クロールでは、現在、アクセス許可に対する更新プログラムの処理はサポートされていません。
Content
プロジェクトの選択とデータのフィルター処理
[JiraDataCenter サイト全体] を選択すると、現在および将来のすべてのプロジェクトにインデックスが作成されます。 [一部のプロジェクトのみ] を選択すると、選択したプロジェクトのみがインデックス付けされます。
データをフィルター処理する
作成または最終更新のタイムスタンプに基づいて JiraDataCenter の問題をフィルター処理して、最近のコンテンツにのみインデックスを付けることができます。 高度なフィルターの場合は、 JQL 文字列も追加できます。
プロパティの管理
このセクションでは、接続のスキーマを定義します。 スキーマは、インデックス付き Jira コンテンツを Graph コネクタ内で取り込んで処理する方法を決定します。 プロパティを追加または変更して、データ構造が Copilot と検索エクスペリエンスの組織のニーズと一致するようにすることができます。 Jira Data Center からカスタム フィールドをプロパティとして追加することもできます。 詳細情報 を参照してください。
| Source プロパティ (ADO MD) | セマンティック ラベル | Schema |
|---|---|---|
| AssigneeEmailId | クエリ、取得、検索 | |
| AssigneeName | クエリ、取得、検索 | |
| ブロック | ブロック | クエリ、取得 |
| 作成済み | 作成日時 | 取り戻す |
| DueDate | 取り戻す | |
| IssueDescription | 検索 | |
| IssueIconUrl | IconUrl | 取り戻す |
| IssueId | 取り戻す | |
| IssueKey | クエリ、取得、検索 | |
| IssueLink | Url | クエリ、取得、検索 |
| IssuePriority | クエリ、取得、検索 | |
| IssueStatus | クエリ、取得 | |
| IssueSummary | 検索 | |
| IssueType | クエリ、取得 | |
| ラベル | クエリ、取得 | |
| ProjectName | クエリ、取得 | |
| ReporterEmailId | 作成者 | クエリ、取得、検索 |
| ReporterName | クエリ、取得、検索 | |
| タイトル | タイトル | クエリ、取得、検索 |
| 更新あり | 最終更新日時 | クエリ、取得 |
データのプレビュー プレビュー結果ボタンを使用して、選択したプロパティとフィルターを確認します。
同期
更新間隔は、データ ソースと Graph コネクタ インデックスの間でデータを同期する頻度を決定します。 更新間隔には、フル クロールと増分クロールの 2 種類があります。 詳細については、こちらをクリック してください。
接続を確認してテストする
テストでは、 限定された対象ユーザーに発行を選択できます。
インデックス付きコンテンツとアクセス許可を検索し、 インデックス ブラウザーを使用して検証します。
よくある質問に対する回答については、「 FAQ」セクションを参照してください。
MS Search の場合、検索結果ページをカスタマイズする必要がある場合。 検索結果のカスタマイズについては、「検索結果 のカスタマイズ」ページを参照してください。
トラブルシューティング
接続を公開したら、管理センターの [データ ソース] タブの状態を確認できます。 更新と削除を行う方法については、「接続を監視する」をご覧ください。
問題がある場合、またはフィードバックを提供する場合は、Microsoft Graph にお問い合わせください |サポート。