統計学者、データ サイエンティスト、データ アナリストによって広く使用されているプログラミング言語である Python は、Power BI Desktop Power Query エディターで使用できます。 この Power Query エディター への Python の統合により、Python を使用してデータ クレンジングを実行し、欠落しているデータ、予測、クラスタリングの完了など、データセットで高度なデータ 整形と分析を実行できます。 Python は強力な言語であり、 Power Query エディター でデータ モデルを準備し、レポートを作成するために使用できます。
[前提条件]
開始する前に、Python と pandas をインストールする必要があります。
Python のインストール - Power BI Desktop の Power Query エディターで Python を使用するには、ローカル コンピューターに Python をインストールする必要があります。 Python の公式ダウンロード ページや Anaconda など、さまざまな場所から Python を無料でダウンロードしてインストールできます。
Pandas をインストール する - Power Query エディターで Python を使用するには、 pandas もインストールする必要があります。 Pandas は、Power BI と Python 環境の間でデータを移動するために使用されます。
Power Query エディターで Python を使用する
Power Query エディターで Python を使用する方法を示すには、ここからダウンロードしてフォローできる CSV ファイルに基づいて、株価データセットからこの例を取ります。 この例の手順は次のとおりです。
まず、 Power BI Desktop にデータを読み込みます。 この例では、EuStockMarkets_NA.csv ファイルを読み込み、Power BI Desktop の >] リボンから [データの取得テキスト/CSV] を選択します。
![POWER BI Desktop の [データの取得] リボンのスクリーンショット。CSV が選択されています。](media/desktop-python-in-query-editor/python-in-query-editor-1.png)
ファイルを選択して [開く] を選択すると、 CSV ファイル ダイアログに CSV が表示されます。
![選択した CSV を示す [CSV ファイル] ダイアログのスクリーンショット。](media/desktop-python-in-query-editor/python-in-query-editor-2.png)
データが読み込まれると、Power BI Desktop の [フィールド] ウィンドウにデータが表示されます。
![[フィールド] ペインのスクリーンショット。読み込まれたデータが表示されています。](media/desktop-python-in-query-editor/python-in-query-editor-3.png)
Power BI Desktop の [ホーム] タブから [データの変換] を選択して、Power Query エディターを開きます。
![Power BI Desktop の Power Query エディターのスクリーンショット。[データの変換] が選択されています。](media/desktop-python-in-query-editor/python-in-query-editor-4.png)
[ 変換 ] タブで [ Python スクリプトの実行 ] を選択すると、次の手順に示すように Python スクリプトの実行 エディターが表示されます。 行 15 と行 20 は、次の図では見ることができない他の行と同様に、データが不足しています。 次の手順では、Python がそれらの行を完了する方法を示します。
![データの行を示す [変換] タブのスクリーンショット。](media/desktop-python-in-query-editor/python-in-query-editor-5.png)
この例では、次のスクリプト コードを入力します。
import pandas as pd completedData = dataset.fillna(method='backfill', inplace=False) dataset["completedValues"] = completedData["SMI missing values"]注
前のスクリプト コードが正常に動作するには、Python 環境に pandas ライブラリをインストールする必要があります。 pandas をインストールするには、Python インストールで次のコマンドを実行します。
pip install pandas[ Python スクリプトの実行 ] ダイアログに入力すると、コードは次の例のようになります。
![スクリプト コードを示す [Python スクリプトの実行] ダイアログのスクリーンショット。](media/desktop-python-in-query-editor/python-in-query-editor-5b.png)
[OK] を選択すると、Power Query エディターにデータ のプライバシーに関する警告が表示されます。

Power BI サービスで Python スクリプトが正常に機能するためには、すべてのデータ ソースを パブリックに設定する必要があります。 プライバシー設定とその影響の詳細については、「 プライバシー レベル」を参照してください。
![[プライバシー レベル] ダイアログのスクリーンショット。[パブリック] が設定されていることを示しています。](media/desktop-python-in-query-editor/python-in-query-editor-7.png)
[フィールド] ペインに completedValues という名前の新しい列があることに注意してください。 行 15 や 18 など、データ要素が不足していることに注意してください。 Python が次のセクションで処理する方法を見てみましょう。
Python スクリプトの 3 行だけで、 Power Query エディター は予測モデルで欠損値を入力しました。
Python スクリプト データからビジュアルを作成する
次の図に示すように、 pandas ライブラリを使用した Python スクリプト コードで不足値がどのように完了したかを確認するビジュアルを作成できます。
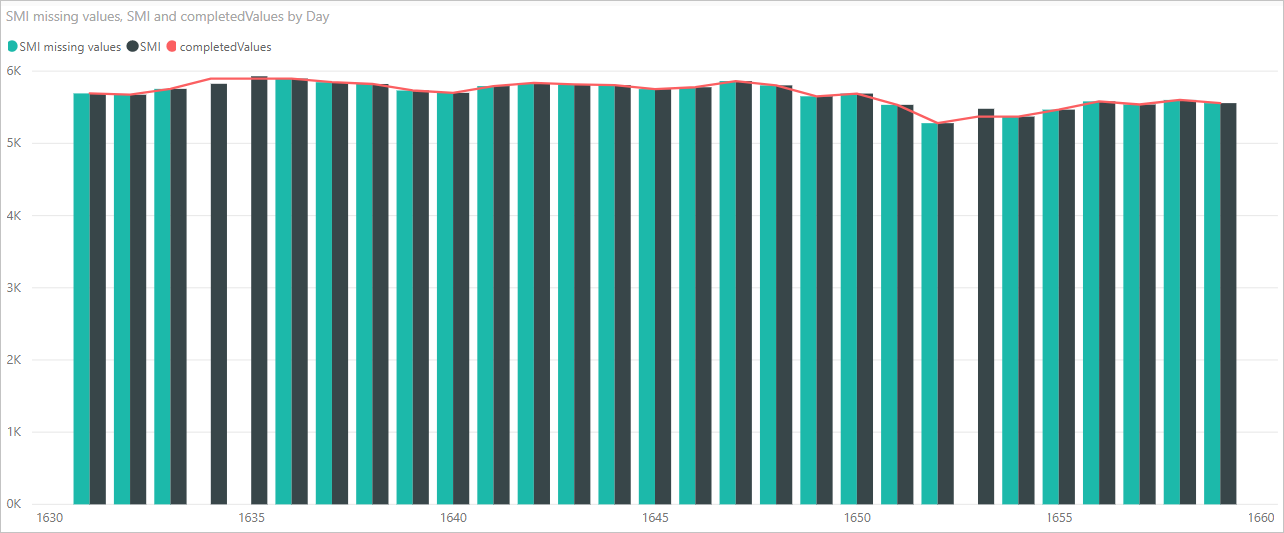
そのビジュアルが完成し、 Power BI Desktop を使用して作成するその他のビジュアルがあれば、 Power BI Desktop ファイルを保存できます。 Power BI Desktop ファイルは 、.pbix ファイル名拡張子で保存されます。 次に、Power BI サービスで、その一部である Python スクリプトを含むデータ モデルを使用します。
注
これらの手順を完了した .pbix ファイルを見てみたいですか? あなたは運が良いです。 これらの例で使用されている完成した Power BI Desktop ファイルは 、ここでダウンロードできます。
.pbix ファイルを Power BI サービスにアップロードすると、サービスでデータを更新したり、サービスでビジュアルを更新したりするために、さらにいくつかの手順が必要になります。 ビジュアルを更新するには、データから Python にアクセスする必要があります。 その他の手順は次のとおりです。
- データセットのスケジュールされた更新を有効にします。 Python スクリプトを使用してデータセットを含むブックのスケジュールされた更新を有効にするには、「 スケジュールされた更新の構成」を参照してください。これには 、Personal Gateway に関する情報も含まれています。
- Personal Gateway をインストールします。 ファイルが配置され、Python がインストールされているコンピューターに Personal Gateway がインストールされている必要があります。 Power BI サービスは、そのブックにアクセスし、更新されたビジュアルを再レンダリングする必要があります。 詳細については、「 Personal Gateway のインストールと構成」を参照してください。
考慮事項と制限事項
Power Query エディターで作成された Python スクリプトを含むクエリには、いくつかの制限があります。
すべての Python データ ソース設定を パブリックに設定し、 Power Query エディター で作成されたクエリ内の他のすべてのステップもパブリックにする必要があります。 データ ソースの設定にアクセスするには、 Power BI Desktop で [ファイル] > [オプションと設定] > [データ ソースの設定] を選択します。
![Power BI Desktop の [ファイル] メニューのスクリーンショット。[データ ソースの設定] が選択されています。](media/desktop-python-in-query-editor/python-in-query-editor-9.png)
[ データ ソースの設定] ダイアログで、データ ソースを選択し、[ アクセス許可の編集]を 選択します。[ プライバシー レベル ] が [パブリック] に設定されていることを確認します。
![[データ ソースの設定] ダイアログのスクリーンショット。[プライバシー レベル] が [パブリック] に設定されています。](media/desktop-python-in-query-editor/python-in-query-editor-10.png)
Python ビジュアルまたはデータセットのスケジュールされた更新を有効にするには、 スケジュールされた更新 を有効にし、ブックと Python インストールを格納するコンピューターに Personal Gateway をインストールする必要があります。 両方の詳細については、この記事の前のセクションを参照してください。各セクションの詳細については、リンクを参照してください。
入れ子構造のテーブル(これらは「テーブルのテーブル」)は現在サポートされていません。
Python とカスタムクエリを使用して、さまざまなことができますので、データを自分の望む通りに探索し整形できます。