Power BI Desktop の複合モデルのガイダンス
この記事は、Power BI の複合モデルを開発するデータ モデラーを対象としています。 複合モデルのユース ケースについて説明し、設計ガイダンスを示します。 具体的には、ご自分のソリューションに複合モデルが適切かどうかを判断するのに役立つガイダンスです。 該当する場合、この記事は最適な複合モデルおよびレポートの設計にも役立ちます。
注意
この記事では、複合モデルの概要については説明しません。 複合モデルをよく理解していない場合は、まず「Power BI Desktop で複合モデルを使用する」の記事を読むことをお勧めします。
複合モデルは少なくとも 1 つの DirectQuery ソースで構成されるため、モデルのリレーションシップ、DirectQuery モデル、および DirectQuery モデルの設計ガイダンスをよく理解していることも重要です。
複合モデルのユース ケース
定義上、複合モデルは複数の "ソース グループ" を結合します。 ソース グループは、インポートされたデータまたは DirectQuery ソースへの接続を表すことができます。 DirectQuery ソースには、リレーショナル データベースまたは別の表形式モデルを使用できます。これは、Power BI セマンティック モデルでも、 Analysis Services テーブル モデルでもかまいません。 表形式モデルが別の表形式モデルに接続した場合、それは "チェーン" と呼ばれます。 詳しくは、Power BI セマンティック モデルと Analysis Services に DirectQuery を使用する方法に関するページをご覧ください。
Note
モデルが表形式モデルに接続しても、追加のデータを使用してそれを拡張しない場合、それは複合モデルではありません。 この場合は、これはリモート モデルに接続する DirectQuery モデルであるため、1 つのソース グループだけで構成されます。 この種類のモデルを作成して、テーブル名、列の並べ替え順序、書式文字列などのソース モデル オブジェクトのプロパティを変更できます。
表形式モデルへの接続は、"エンタープライズ セマンティック モデル" を拡張するとき (Power BI セマンティック モデルまたは Analysis Services モデルの場合) に特に関連します。 エンタープライズ セマンティック モデルは、データ ウェアハウスの開発および運用の基盤となるものです。 これにより、ビジネス定義と用語を表すために、データ ウェアハウスでのデータに対して抽象化レイヤーが提供されます。 一般的にこれは、物理データ モデルと Power BI などのレポート ツール間のリンクとして使用されます。 ほとんどの組織では、中心的なチームによって管理されます。これが、"エンタープライズ" と表現される理由です。 詳細については、エンタープライズ BI という使用シナリオのページを参照してください。
複合モデルの開発は、次の状況で検討できます。
- モデルを DirectQuery モデルにすることもできますが、パフォーマンスを向上させる必要があります。 複合モデルでは、パフォーマンスを向上させるには、各テーブルに適切なストレージをセットアップします。 ユーザー定義集計を追加することもできます。 これら両方の最適化については、この記事で後述します。
- DirectQuery モデルと追加のデータを結合し、モデルにインポートする必要があります。 インポートされたデータは、別のデータ ソースまたは計算テーブルから読み込むことができます。
- 複数の DirectQuery データ ソースを 1 つのモデルに結合する必要があります。 これらのソースは、リレーショナル データベースまたはその他の表形式モデルになります。
注意
複合モデルには、特定の外部の分析データベースへの接続を含めることはできません。 これらのデータベースには、SAP HANA を多次元ソースとして扱う場合、SAP Business Warehouse や SAP HANA が含まれます。
その他のモデル設計オプションを評価する
Power BI 複合モデルは特定の設計上の課題を解決できますが、パフォーマンスが低下する可能性があります。 また、状況によっては、予期しない計算結果が発生する可能性があります (この記事で後述します)。 このような理由から、他のモデル設計オプションが存在する場合、それらを評価してください。
可能な限り、インポート モードでモデルを開発することをお勧めします。 このモードを使うと、最大限のデザインの柔軟性と最高のパフォーマンスが得られます。
ただし、大量のデータに関連する課題や、ほぼリアルタイムのデータに関するレポートは、インポート モデルで常に解決できるとは限りません。 このいずれのケースでも、DirectQuery モードでサポートされる単一のデータ ソースにデータが格納されている場合は、DirectQuery モデルを検討できます。 詳細情報については、「Power BI Desktop での DirectQuery モデル」を参照してください。
ヒント
目標が既存の表形式モデルを追加のデータで拡張することのみである場合は、可能な限り、そのデータを既存のデータ ソースに追加します。
テーブル ストレージ モード
複合モデルでは、(計算テーブルを除く) 各テーブルのストレージ モードを設定できます。
- DirectQuery: 大量のデータを示すテーブル、または準リアルタイムの結果を提供する必要があるテーブルの場合は、このモードを設定することをお勧めします。 データがこれらのテーブルにインポートされることはありません。 通常、これらのテーブルはファクト型テーブル (集計されるテーブル) になります。
- インポート: DirectQuery モードかハイブリッド モードでファクト テーブルのフィルター処理やグループ化に使用しないテーブルの場合は、このモードを設定することをお勧めします。 また、DirectQuery モードでサポートされていないソースに基づくテーブルの場合は、これが唯一の選択肢です。 計算テーブルは、常にインポート テーブルです。
- デュアル: ディメンション型テーブルで、同じソースの DirectQuery ファクト型テーブルと共にクエリが実行される可能性がある場合は、このモードを設定することをお勧めします。
- ハイブリッド: 最新のデータ変更をリアルタイムで含める場合、またはインポート パーティションを通じて最も頻繁に使用するデータへの高速アクセスを実現する一方、使用頻度の低いデータの大部分をデータ ウェアハウスに残す場合は、インポート パーティションと 1 つの DirectQuery パーティションをファクト テーブルに追加して、このモードを設定することをお勧めします。
Power BI で複合モデルにクエリを実行する場合は、いくつかのシナリオが考えられます。
- インポート テーブルまたはデュアル テーブルに対してのみクエリを実行する: Power BI ですべてのデータはモデル キャッシュから取得されます。 可能な限り最速のパフォーマンスを達成できます。 このシナリオは、フィルターまたはスライサー ビジュアルによってクエリが行われるディメンション型テーブルの場合に一般的です。
- 同じソースのデュアル テーブルまたは DirectQuery テーブルに対してクエリを実行する: 1 つ以上のネイティブ クエリを DirectQuery ソースに送信することで、すべてのデータを取得します。 特にソース テーブルに適切なインデックスが存在する場合に、優れたパフォーマンスを達成できます。 このシナリオは、デュアル ディメンション型テーブルと DirectQuery ファクト型テーブルを関連付けるクエリの場合に一般的です。 これらのクエリは "ソース グループ内" なので、1 対 1 または 1 対多の関係はすべて標準リレーションシップとして評価されます。
- 同じソースのデュアル テーブルまたはハイブリッド テーブルに対してクエリを実行する: このシナリオは、前の 2 つのシナリオを組み合わせたものです。 インポート パーティションで使用できる場合はモデル キャッシュから、それ以外の場合は 1 つ以上のネイティブ クエリを DirectQuery ソースに送信することで、データは取得されます。 データ ウェアハウス内のデータのスライスに対してのみクエリが実行されるため、特にソース テーブルに適切なインデックスが存在する場合に、可能な限り最速のパフォーマンスを達成できます。 デュアル ディメンション型テーブルと DirectQuery ファクト型テーブルについては、これらのクエリはソース グループ内にあるので、一対一または一対多のすべてのリレーションシップが通常のリレーションシップとして評価されます。
- 他のすべてのクエリ:これらのクエリには、ソース グループ間のリレーションシップが含まれます。 これは、インポート テーブルが DirectQuery テーブルと関係しているか、デュアル テーブルが異なるソースの DirectQuery テーブルと関係している (この場合はインポート テーブルとして動作します) ためです。 すべてのリレーションシップは制限付きリレーションシップとして評価されます。 また、非 DirectQuery テーブルに適用されるグループ化は、具体化されたサブクエリ (仮想テーブル) として DirectQuery ソースに送信される必要があることも意味します。 この場合、特に大規模なグループ化セットの場合、ネイティブ クエリは非効率的です。
まとめると、推奨事項は次のとおりです。
- 複合モデルが適切なソリューションであることを慎重に検討します。異なるデータ ソースをモデルレベルで統合できますが、結果として設計が複雑になるという影響もあります (この記事で後述します)。
- テーブルが大量のデータを格納するファクト型テーブルである場合、または準リアルタイムの結果を提供する必要がある場合は、ストレージ モードを DirectQuery に設定します。
- 増分更新ポリシーとリアルタイム データを定義するか、TOM、TMSL、またはサードパーティ製のツールを使ってファクト テーブルをパーティション分割することで、ハイブリッド モードを使うことを検討してください。 詳細については、「セマンティック モデルの増分更新とリアルタイム データ」および「高度なデータ モデル管理」使用シナリオを参照してください。
- テーブルがディメンション型テーブルの場合は、ストレージ モードをデュアルに設定します。これにより、同じソース グループ内にある DirectQuery またはハイブリッド ファクト型テーブルと共にクエリが実行されます。
- デュアル テーブルとハイブリッド テーブル (および依存するすべての計算テーブル) のモデル キャッシュとソース データベースとの同期を維持するように、適切な更新頻度を設定します。
- ソース グループ (モデル キャッシュを含む) 間のデータの整合性を確保します。これは、関連する列の値が一致しない場合に制限付きリレーションシップによってクエリ結果の行が削除されるためです。
- 可能な場合は、効率的な結合、フィルター処理、グループ化のために適切なインデックスを使用して DirectQuery データ ソースを最適化します。
ユーザー定義集計
ユーザー定義集計を DirectQuery テーブルに追加することができます。 その目的は、"より高い粒度" のクエリのパフォーマンスを向上させることです。
集計は、モデルにキャッシュされるとき、インポート テーブルとして動作します (ただし、モデル テーブルのように使用することはできません)。 インポート集計を DirectQuery モデルに追加すると、複合モデルになります。
注意
一部のパーティションはインポート モードで動作するため、ハイブリッド テーブルでは集計がサポートされません。 個々の DirectQuery パーティションのレベルで集計を追加することはできません。
次の基本的な規則に従う集計にすることをお勧めします。その行数は、基になるテーブルよりも少なくとも 10 倍小さくする必要があります。 たとえば、基となるテーブルに 10 億行が格納されている場合、集計テーブルは 1 億行を超えないようにします。 この規則により、集計の作成と保守のコストに対して適切なパフォーマンスの向上が保証されます。
ソース グループ間リレーションシップ
モデルのリレーションシップが複数のソース グループをまたがる場合、これは "ソース グループ間リレーションシップ" と呼ばれます。 ソース グループ間リレーションシップは、保証された "一" 側が存在しないため、"制限付き" とも呼ばれます。 詳細については、「リレーションシップの評価」を参照してください。
注意
場合によっては、ソース グループ間リレーションシップの作成を回避できます。 この記事で後述する「同期スライサーの使用」を参照してください。
ソース グループ間リレーションシップを定義するときは、次の推奨事項を考慮します。
- 低カーディナリティ リレーションシップ列を使う: 最適なパフォーマンスを得られるように、リレーションシップ列のカーディナリティを低くすることをお勧めします。つまり、格納するのは、50,000 個未満の一意の値にする必要があります。 この推奨事項は、表形式モデルを組み合わせる場合で、テキスト以外の列の場合に特に当てはまります。
- 大きなテキストのリレーションシップ列の使用を回避する: リレーションシップ内のテキスト列を使う必要がある場合、カーディナリティにテキスト列の平均の長さを掛けて、フィルターの予想されるテキスト長を計算します。 可能なテキスト長として、1,000,000 文字を超えないようにしてください。
- リレーションシップの粒度を上げる: 可能な限り、高い粒度レベルでリレーションシップを作成します。 たとえば、ある日付テーブルをその日付キー上で関連付けるのではなく、その月キーを代わりに使用します。 この設計アプローチでは、関連テーブルに月キー列が含まれている必要があり、レポートでは日次ファクトを表示できなくなります。
- 単純なリレーションシップ設計を目指す: 必要な場合にのみソース グループ間リレーションシップを作成し、リレーションシップ パス内のテーブルの数を制限してみます。 この設計アプローチは、パフォーマンスの向上や、あいまいなリレーションシップ パスの回避に役立ちます。
警告
Power BI Desktop はソース グループ間リレーションシップを十分に検証しないため、あいまいなリレーションシップが作成される可能性があります。
ソース グループ間リレーションシップ シナリオ 1
複雑なリレーションシップ設計のシナリオと、それによってどのように異なる (が有効な) 結果が出るかを考えてみましょう。
このシナリオでは、ソース グループ A の Region テーブルには、ソース グループ B の Date テーブルと Sales テーブルとのリレーションシップがあります。Region テーブルと Date テーブルの間のリレーションシップはアクティブですが、Region テーブルと Sales テーブルの間のリレーションシップは非アクティブです。 また、Region テーブルと Sales テーブルの間にはアクティブなリレーションシップがあり、どちらもソース グループ B にあります。Sales テーブルには TotalSales という名前のメジャーが含まれており、Region テーブルには RegionalSales と RegionalSalesDirect という名前の 2 つのメジャーが含まれています。
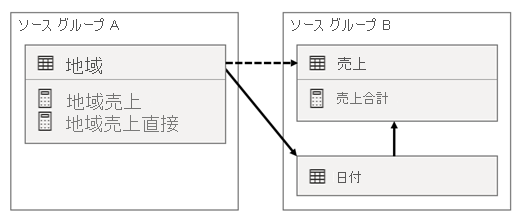
メジャーの定義を次に示します。
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSales メジャーでは TotalSales メジャーが参照される一方で、RegionalSalesDirect メジャーでは参照されないことに注意してください。 代わりに、RegionalSalesDirect メジャーでは、TotalSales メジャーの式である式 SUM(Sales[Sales]) が使用されます。
結果の違いはほんのわずかです。 Power BI によって RegionalSales メジャーが評価されると、Region テーブルのフィルターが Sales テーブルと Date テーブルの両方に適用されます。 したがって、フィルターは Date テーブルから Sales テーブルにも反映されます。 これに対し、Power BI によって RegionalSalesDirect メジャーが評価されると、フィルターは Region テーブルから Sales テーブルにのみ反映されます。 式が意味的に同等であっても、RegionalSales メジャーと RegionalSalesDirect メジャーによって返される結果は異なる場合があります。
重要
リモート ソース グループ内の 1 つのメジャーである式で CALCULATE 関数を使用する場合は常に、計算結果を十分にテストしてください。
ソース グループ間リレーションシップ シナリオ 2
ソース グループ間リレーションシップに高いカーディナリティのリレーションシップ列がある場合のシナリオを考えてみます。
このシナリオでは、Date テーブルは、DateKey 列で Sales テーブルに関連付けられます。 DateKey 列のデータ型は整数で、yyyymmdd 形式を使用する整数を格納します。 テーブルはさまざまなソース グループに属しています。 さらに、Date テーブルの最も古い日付は 1900 年 1 月 1 日で、最新の日付は 2100 年 12 月 31 日であるため (テーブル内の行数は合計 73,414 行 (1900 から 2100 の期間の日付ごとに 1 行))、これは高カーディナリティ リレーションシップです。
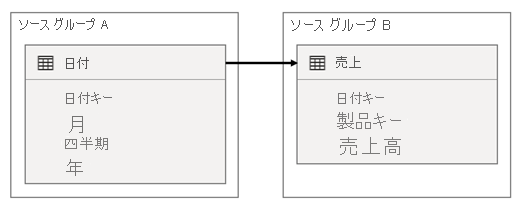
懸念されるケースは 2 つあります。
まず、Date テーブル列をフィルターとして使用すると、フィルター伝達によって Sales テーブルの DateKey 列がフィルター処理され、メジャーが評価されます。 2022 年のように 1 年でフィルター処理すると、DAX クエリには Sales[DateKey] IN { 20220101, 20220102, …20221231 } のようなフィルター式が含まれます。 フィルター式の値の数が多かったり、フィルター値が長い文字列の場合など非常に大きくなる場合用にクエリのテキスト サイズを拡張できます。 Power BI で長いクエリを生成し、データ ソースでクエリを実行するのにはコストがかかります。
次に、Date テーブルの列 (Year、Quarter、Month など) をグループ化列として使用すると、年、四半期、月 "と" DateKey 列値のすべての一意の組み合わせを含むフィルターが生成されます。 グループ化列とリレーションシップ列のフィルターを含むクエリの文字列サイズは、非常に大きくなる可能性があります。 これは、グループ化列の数や結合列 (DateKey 列) のカーディナリティが大きい場合に特に当てはまります。
パフォーマンスの問題に対処するには、次の手順を実行します。
- Date テーブルをデータ ソースに追加すると、1 つのソース グループ モデルが作成されます (つまり、複合モデルではなくなります)。
- リレーションシップの粒度を上げます。 たとえば、MonthKey 列を両方のテーブルに追加し、それらの列にリレーションシップを作成できます。 ただし、リレーションシップの粒度を上げることで、毎日の営業活動をレポートする機能が失われます (Sales テーブルの DateKey 列を使用しない限り)。
ソース グループ間リレーションシップ シナリオ 3
ソース グループ間リレーションシップ内のテーブル間で値が一致しないシナリオを考えてみましょう。
このシナリオでは、ソース グループ B の Date テーブルには、そのソース グループの Sales テーブルと、ソース グループ A の Target テーブルとのリレーションシップがあります。すべてのリレーションシップは、Year 列に関連する Date テーブルの 1 対多です。 Sales テーブルには売上金額を格納する SalesAmount 列が含まれますが、Target テーブルには目標金額を格納する TargetAmount 列が含まれます。
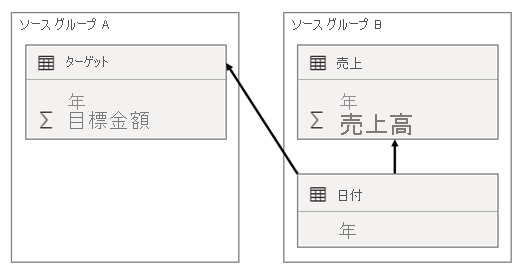
Date テーブルには、2021 年と 2022 年が格納されます。 Sales テーブルには、2021 年 (100) と 2022 年 (200) の売上金額が格納され、Target テーブルには 2021 (100)、2022 (200)、"および 2023 (300)" (未来の年) の目標金額が格納されます。
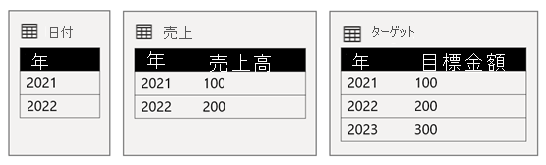
Power BI テーブルの視覚化で、Date テーブルの Year 列でのグループ化と、SalesAmount 列と TargetAmount 列を合計することにより複合モデルに対してクエリを実行する場合、2023 の目標金額は表示されません。 これは、ソース グループ間リレーションシップは限られたリレーションシップであるため、両側に一致する値がない行を削除する INNER JOIN セマンティクスが使用されるためです。 ただし、Date テーブル フィルターはその評価に適用されないため、正しい目標金額合計 (600) が生成されます。

Date テーブルと Target テーブル間のリレーションシップがソース グループ内のリレーションシップである場合 (Target テーブルがソース グループ B に属していたと仮定した場合)、視覚化には 2023 (およびその他の不一致の年) の目標金額を示す "(空白)" 年が含まれます。
重要
誤ったレポートを回避するために、ディメンション テーブルとファクト テーブルが異なるソース グループに存在する場合に、リレーションシップ列に一致する値があることを確認します。
制限付きリレーションシップの詳細については、「リレーションシップの評価」を参照してください。
計算
計算列と計算グループを複合モデルに追加する場合は、特定の制限事項を考慮する必要があります。
計算列
Microsoft SQL Server などのリレーショナル データベースからそのデータを取得する DirectQuery テーブルに追加された計算列は、一度に 1 行に対して動作する式に制限されます。 これらの式では、SUMX のような DAX 反復子関数や、CALCULATE のようなフィルター コンテキスト変更関数を使用することはできません。
注意
チェーンされた表形式モデルに依存する計算列や計算テーブルを追加することはできません。
リモート DirectQuery テーブルの計算列式は、行内評価のみに制限されます。 ただし、このような式を作成することはできますが、視覚化で使用するとエラーが発生します。 たとえば、式 [Product Sales] / SUM (DimProduct[ProductSales]) を使用して DimProduct という名前のリモート DirectQuery テーブルに計算列を追加すると、モデルに式を正常に保存できます。 ただし、行内評価の制限に違反するため、視覚化で使用するとエラーが発生します。
これに対し、表形式モデルであるリモート DirectQuery テーブルに追加された計算列 (Power BI セマンティック モデルまたは Analysis Services モデル) の方がより柔軟性が高くなります。 この場合、式はソース表形式モデル内で評価されるため、すべての DAX 関数が許可されます。
多くの式では、計算列をグループまたはフィルターとして使用したり集計したりする前に、Power BI で計算列を具体化する必要があります。 計算列が大きなテーブルに具体化されると、計算列が依存する列のカーディナリティに応じて、CPU とメモリの観点からコストがかかる場合があります。 この場合は、これらの計算列をソース モデルに追加することをお勧めします。
注意
複合モデルに計算列を追加する場合は、必ずすべてのモデル計算をテストしてください。 アップストリームの計算は、フィルター コンテキストへの影響が考慮されないため、正しく機能しない可能性があります。
計算グループ
Power BI セマンティック モデルまたは Analysis Services モデルに接続するソース グループに計算グループが存在する場合、Power BI は予期しない結果を返す可能性があります。 詳細については、「計算グループ、クエリとメジャーの評価」を参照してください。
モデルの設計
スター スキーマ設計を採用することで、常に Power BI モデルを最適化する必要があります。
ヒント
詳細については、「スター スキーマと Power BI での重要性を理解する」を参照してください。
Power BI で結合を正しく解釈し、効率的なクエリ プランを生成できるように、ファクト テーブルとは別のディメンション テーブルを作成してください。 このガイダンスはすべての Power BI モデルに当てはまりますが、特に、複合モデルのソース グループになると認識されるモデルに当てはまります。 これにより、ダウンストリーム モデル内の他のテーブルをよりシンプルかつ効率的に統合できます。
可能な限り、異なるソース グループ内のファクト テーブルに関連するディメンション テーブルを 1 つのソース グループに含めないようにしてください。 これは、ソース グループ "間" リレーションシップよりも、ソース グループ "内" リレーションシップを持つ方が良いためです (特にカーディナリティの高いリレーションシップ列の場合)。 前述のように、ソース グループ間リレーションシップは、リレーションシップ列に一致する値を持つことに依存します。そうでない場合、予期しない結果がレポートの視覚エフェクトに表示されることがあります。
行レベルのセキュリティ
モデルにユーザー定義集計、インポート テーブルの計算列、または計算テーブルが含まれる場合は、すべての行レベル セキュリティ (RLS) が正しく設定され、テストされていることを確認します。
複合モデルが他の表形式モデルに接続する場合、RLS ルールは、それらが定義されているソース グループ (ローカル モデル) にのみ適用されます。 その他のソース グループ (リモート モデル) には適用されません。 また、別のソース グループのテーブルに RLS ルールを定義したり、別のソース グループとのリレーションシップを持つローカル テーブルに RLS ルールを定義したりすることはできません。
レポート デザイン
状況によっては、最適化されたレポート レイアウトを設計することで、複合モデルのパフォーマンスを向上させることができます。
単一のソース グループの視覚化
可能な限り、1 つのソース グループからのフィールドを使用する視覚化を作成します。 これは、結果が 1 つのソース グループから取得されると、視覚化によって生成されるクエリのパフォーマンスが向上するためです。 2 つの異なるソース グループからデータを取得する 2 つの視覚化を並べて配置することを検討してください。
同期スライサーの使用
状況によっては、同期スライサーを設定して、モデルでのソース グループ間リレーションシップの作成を回避できます。 これにより、パフォーマンスを向上させることができるソース グループを "視覚的に" 結合できます。
モデルに 2 つのソース グループがある場合のシナリオを考えてみましょう。 各ソース グループには、リセラーとインターネット販売をフィルター処理するために使用される製品ディメンション テーブルがあります。
このシナリオでは、ソース グループ A に ResellerSales テーブルに関連する Product テーブルが含まれています。 ソース グループ B に InternetSales テーブルに関連する Product2 テーブルが含まれています。 ソース グループ間リレーションシップはありません。
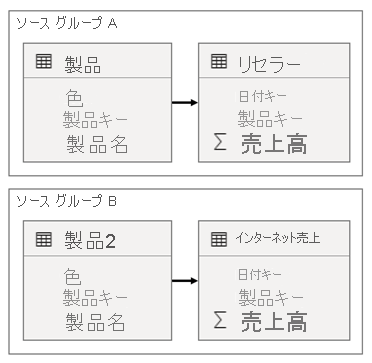
レポートでは、Product テーブルの Color 列を使用してページをフィルター処理するスライサーを追加します。 既定では、スライサーは ResellerSales テーブルをフィルター処理しますが、InternetSales テーブルはフィルター処理しません。 次に、Product2 テーブルの Color 列を使用して、非表示のスライサーを追加します。 同じグループ名 (同期スライサーの詳細オプションにある) を設定すると、表示されているスライサーに適用されたフィルターが、非表示のスライサーに自動的に反映されます。
注意
同期スライサーを使用すると、ソース グループ間リレーションシップを作成せずに済む一方で、モデル設計の複雑さが増します。 重複するディメンション テーブルを使用してモデルを設計した理由について、他のユーザーを教育してください。 他のユーザーに使用させたくないディメンション テーブルを非表示にすることで、混乱を回避できます。 非表示のテーブルに説明テキストを追加して、目的を文書化することもできます。
詳細については、「個別のスライサーを同期する」を参照してください。
その他のガイダンス
複合モデルの設計と保守に役立つその他のガイダンスを次に示します。
- パフォーマンスとスケール: 以前にレポートが Power BI セマンティック モデルまたは Analysis Services モデルにライブ接続されていた場合、Power BI サービスでレポート間視覚化キャッシュを再利用できます。 ライブ接続を変換してローカル DirectQuery モデルを作成した後、レポートはこれらのキャッシュの利点を得られなくなります。 その結果、パフォーマンスが低下したり、更新エラーが発生したりする可能性があります。 また、Power BI サービスのワークロードが増加するため、容量をスケールアップしたり、他の容量にワークロードを分散させたりする必要がある場合があります。 データの更新とキャッシュの詳細については、「Power BI でのデータ更新」を参照してください。
- 名前の変更: 複合モデルで使用されるセマンティック モデルの名前を変更したり、ワークスペースの名前を変更したりすることはお勧めしません。 これは、複合モデルは、ワークスペースとセマンティック モデル名 (内部の一意識別子ではなく) を使用して Power BI セマンティック モデルに接続するためです。 セマンティック モデルまたはワークスペースの名前を変更すると、複合モデルで使用される接続が切断される可能性があります。
- ガバナンス: "信頼できる唯一のバージョン" モデルを複合モデルにすることはお勧めしません。 これは、それが他のデータ ソースまたはモデルに依存するためです。更新されると、複合モデルが破損する可能性があります。 代わりに、エンタープライズ セマンティック モデルを信頼できる唯一のバージョンとしてパブリッシュすることをお勧めします。 このモデルは信頼性の高い基盤であると考えてください。 その後、他のデータ モデラーは、基本モデルを拡張して特殊なモデルを作成する複合モデルを作成できます。
- データ系列: 複合モデルの変更をパブリッシュする前に、データ系列とセマンティック モデルの影響分析機能を使用します。 これらの機能は、Power BI サービスで使用でき、セマンティック モデルがどのように関係し、使用されているかを理解するのに役立ちます。 系列ビューに表示されていても、実際には別のワークスペースに配置されている外部セマンティック モデルに対して影響分析を実行することはできないことを理解することが重要です。 外部セマンティック モデルの影響分析を実行するには、ソース ワークスペースに移動する必要があります。
- スキーマの更新: アップストリーム データ ソースにスキーマの変更が加えられた場合は、Power BI Desktop で複合モデルを更新する必要があります。 その後、モデルを Power BI サービスに再パブリッシュする必要があります。 計算と依存レポートを十分にテストするようにしてください。
関連するコンテンツ
この記事に関する詳細については、次のリソースを参照してください。
- Power BI Desktop で複合モデルを使用する
- Power BI Desktop でのモデル リレーションシップ
- Power BI Desktop での DirectQuery モデル
- Power BI Desktop で DirectQuery を使用する
- Power BI セマンティック モデルと Analysis Services に DirectQuery を使用する
- Power BI Desktop のストレージ モード
- ユーザー定義集計
- わからないことがある場合は、 Power BI コミュニティで質問してみてください。
- Power BI チームへのご提案は、 Power BI を改善するためのアイデアをお寄せください