Power BIの DirectQuery を使用すると、インポートするのではなく、ソースにデータを保持し、レポート時にクエリを実行できます。 この記事では、DirectQuery を使用するタイミング、その制限事項、およびハイブリッド テーブル、Direct Lake、ライブ接続などの代替手段を使用して、適切なモードを選択できるようにする方法について説明します。
この記事では、次の内容について説明します。
- Power BIデータ接続モードと DirectQuery が適合する場所
- DirectQuery とインポート、ハイブリッド テーブル、Direct Lake、またはライブ接続の利用のタイミング
- 制限事項、影響、およびパフォーマンスに関する考慮事項
- モデリングとレポートの設計に関する推奨事項
- パフォーマンスの診断と向上
注意
DirectQuery は、SQL Server Analysis Servicesの機能でもあります。 類似点はありますが、この記事では、Power BIセマンティック モデルを使用した DirectQuery に焦点を当てています。
複合モデルの詳細については、「 Power BI Desktop で複合モデルを使用するを参照してください。 Microsoftから PDF DirectQuery SQL Server 2016 Analysis Services をダウンロードします。
クイック デシジョン ガイド
次の表が、要件に基づいて考慮すべきPower BIの接続モードをまとめたものです。 これをクイック リファレンスとして使用して、インポート、DirectQuery、ハイブリッド テーブル、Direct Lake、またはライブ接続のいずれかを選択できます。
| 必要な場合 | 最初に検討する | なぜでしょうか |
|---|---|---|
| 最大の対話機能と完全な変換の柔軟性 | Import | メモリ内列エンジンと豊富なモデリング機能 |
| 最近のファクト データと履歴コンテキストに対するほぼリアルタイムの変更 | ハイブリッド テーブル (インポートと DirectQuery パーティション) | ホット データのソースを照会し、履歴データをキャッシュします。 |
| 待機時間の短い読み取りを伴う大規模なレイクハウスまたは倉庫スケール (Fabric) | Direct Lake | スケジュールされた更新をバイパスし、インポート動作を保持する |
| 完全なインジェストなしで複数の外部ソースへのフェデレーション アクセス | DirectQuery (複合モデル) | データを所定の位置に残し、ソースをブレンドします。 |
| 中央管理型エンタープライズ モデルは既に公開されています | セマンティック モデルまたは Analysis Services へのライブ接続 | キュレーションされたモデルを再利用し、重複を回避します。 |
| 実行時にソースにパラメーターをプッシュする (ユーザー主導のフィルター処理) | 動的 M パラメーターを持つ DirectQuery | スキャンされたデータを減らし、パフォーマンスを向上させます。 |
| 高コンカレンシーとリモート待機時間の課題 | DirectQuery でのインポートまたは集計 | 集計によって一般的なクエリが高速化される |
Power BI データ接続モード
Power BIは、多くのデータ ソースに接続します。
- Salesforce や Dynamics 365 などのオンライン サービス
- SQL Server、PostgreSQL、MySQL、Oracle、Snowflake、Amazon Redshift などのデータベース
- ファイル (Excel、CSV、JSON、Parquet)
- Spark や Databricks などのビッグ データと分析エンジン
- Web サイトやMicrosoft Exchangeなどのその他のソース
これらのソースからデータをインポートします。 DirectQuery をサポートするものもあります。 管理されている一覧については、「Power BI データ ソース」を参照してください。 DirectQuery 対応のソースは、通常、対話型の集計クエリ パフォーマンスを提供します。
既定ではインポートを使用します。 Power BIの高性能メモリ内エンジンを使用し、最も豊富な機能セットを提供します。 特定の制約 (待機時間、サイズ、ガバナンス、セキュリティ、またはアーキテクチャ) に必要な場合にのみ、インポートを超えて移動します。
最新の機能強化 (ハイブリッド テーブル、Direct Lake、自動集計、複合モデル、増分更新) により、純粋な DirectQuery が必要な頻度が減ります。
以降のセクションでは、インポート、DirectQuery、ライブ接続モードについて説明します。 この記事の残りの部分では、代替アプローチを確認しながら DirectQuery に焦点を当てています。
接続をインポート
データをインポートする場合:
- データの 選択を取得して、テーブル セットごとのクエリを定義します。読み込む前に、それらを整形 (フィルター、集計、結合) できます。
- これらのクエリによって定義されたすべてのデータは、セマンティック モデルのメモリ内キャッシュに読み込まれます。
- ビジュアルを構築すると、キャッシュされたデータのみがクエリされ、高速かつ完全に対話型になります。
- ビジュアルは、更新 (再インポート) するまでソースの変更を反映しません。
- 発行すると、インポートされたデータを含むセマンティック モデルがアップロードされます。 更新をスケジュールできます (頻度はライセンスによって異なります)、オンプレミスのデータ ゲートウェイが必要な場合があります。
- サービスでレポートを作成または開くと、インポートされたデータが使用されます。
- ピン留めされたダッシュボード タイルは、セマンティック モデルが更新されると更新されます。
DirectQuery の接続
DirectQuery を使用する場合:
- データを取得 すると、サポートされているソースへの接続が確立されます。 リレーショナル ソースの場合でも、テーブルまたはビューを選択できます。多次元ソース (SAP BW など) の場合は、ソース モデルを選択します。
- 読み込み時にデータはインポートされません。 各ビジュアルは、基になるソースに対して 1 つ以上のクエリをトリガーします。
- ビジュアル更新の待機時間は、基になるソースのパフォーマンス (および必要に応じてネットワーク/ゲートウェイのオーバーヘッド) に完全に依存します。
- ソース データの変更は、クエリを再実行するアクション (ナビゲーション、スライサー/フィルターの変更、手動更新) の後にのみ表示されます。
- 発行すると、インポートされたデータを含まないセマンティック モデル定義 (スキーマとメタデータ) が作成されます。
- サービス内のレポートは、ソースに対してクエリを実行します。 オンプレミスのソースにはゲートウェイが必要な場合があります。
- DirectQuery モデルに基づくダッシュボード タイルはスケジュールに基づいて更新され、ダッシュボードを高速に開くためにタイルの結果がキャッシュされます。
- ダッシュボード タイルには、手動で更新しない限り、最後にスケジュールされた更新の結果が表示されます。
ライブ接続
ライブ接続は、Power BIを既存のセマンティック モデル (Analysis Services や別の公開されたPower BIセマンティック モデルなど) に直接接続します。 DirectQuery (インポートされたデータなし) に似ていますが、セマンティクス (ロールの適用など) はアップストリーム モデルによって処理されます。 ライブ接続の場合:
- 完全な外部モデル フィールドの一覧が表示されます。クエリ定義Power Queryはありません。
- ライブ接続では、セキュリティ トリミングのために、常にユーザーの ID が Analysis Services または Power BI セマンティック モデルに渡されます。
- モデルが外部であるため、一部のモデリング アクティビティ (計算テーブルの追加など) は使用できません。
DirectQuery が新しいオプションに適合する場所
DirectQuery は、効率的にインポートできない非常に大きなデータや変化の速いデータの主なソリューションでした。 今日:
- ハイブリッド テーブル を使用すると、メモリ内パーティションと DirectQuery パーティションを 1 つのテーブルに混在させることができます (最近のテーブルと履歴)。
- Direct Lake (Fabric) を使用すると、従来の更新オーバーヘッドなしで lakehouse テーブルにほぼリアルタイムでアクセスできます。
- 自動集計 と手動集計テーブルにより、頻繁なクエリが高速化されます。
- リアルタイムでの増分更新 を使用すると、最新の時間枠はDirectQueryを介してソースに問い合わせることができ、古いデータはインポートされたまま保持されます。
完全な DirectQuery モデルを採用する前に、これらのオプションを評価します。
Microsoft Fabricでのリアルタイムで大量の時系列ワークロードの場合、一般的なパターンは、ソース側の集計と動的 M パラメーターと組み合わせてFabric KQL データベース (Real-Time インテリジェンス) への DirectQuery です。 このワークロードのガイダンスについては 、Kusto ベースのソースに関する考慮事項 を参照してください。
DirectQuery のユース ケース
DirectQuery は、次の場合に最も役立ちます。
- データの変更頻度が高すぎてインポートできません (増分更新とスケジュールされた更新の最大頻度を使用する場合でも)。待機時間を短くする必要があります。
- データ ボリュームまたはガバナンスの制約により、完全なインジェストは実用的ではありません。
- ソースによって適用されるセキュリティ (詳細な行規則) は、パススルー経由で権限を保持する必要があります。
- データ主権または規制規則により、永続化された完全コピーが制限されます。
- ソースは多次元またはメジャー中心 (SAP BW など) であり、サーバー定義のメジャーはビジュアルごとに解決する必要があります。
データが頻繁に変更され、ほぼリアルタイムのレポートが必要
インポートされたモデル (Pro) では、1 日あたり最大 8 回の更新 (さらにオンデマンド/API トリガー) をスケジュールできます。 Premium および PPU では、1 日あたり最大 48 回のスケジュールされた更新と、最新のパーティション (ハイブリッド) の増分更新とリアルタイム DirectQuery がサポートされます。 必要な待機時間が満たされない場合 (または完全なインポートが不可能な場合) は、DirectQuery、ハイブリッド テーブル、または Direct Lake を使用します。 DirectQuery ダッシュボードでは、15 分ごとにタイルを更新できます。
データが大きい
フル インポートがメモリまたは更新ウィンドウを超える可能性があります。 DirectQuery は、データをインプレースで照会します。 ソースが対話型のパフォーマンスに遅すぎる場合は、次の点を考慮してください。
- 集計またはフィルター処理されたサブセットのみをインポートする。
- 増分更新と集計の使用。
- 最近の価値の高いセグメントにハイブリッド テーブルまたは Direct Lake を使用する。
大きなメモリ内データの管理については、 Power BI Premium のLarge セマンティック モデルを参照してください。
ソースによって適用されるセキュリティ
インポートは、Power BI資格情報と、セマンティック モデルで定義されているオプションの行レベル セキュリティ (RLS) に依存します。 DirectQuery は (サポートされている場合) ユーザー ID (SSO) を渡すことができるため、ソースは独自のセキュリティ規則を適用します。 Power BI のオンプレミス データ ゲートウェイの
データ主権の制限
規制でデータを制御された境界内に保持する必要がある場合、DirectQuery では保持されるコピーが制限されます。 ビジュアル キャッシュとタイル キャッシュには、制限付きの集計データを含めることができます。
サーバーで定義されたメジャーのあるソース.
一部のシステム (SAP BW など) には、クエリ時に解決するセマンティック ロジック (メジャーと階層) が含まれています。 DirectQuery では、ビジュアル解像度ごとに有効になります。 「DirectQuery と SAP BW および DirectQuery と SAP HANA を参照してください。
ソース固有の考慮事項 (PostgreSQL と MySQL を含む)
動作とパフォーマンスはエンジンによって異なります。
- PostgreSQL: 引用符で囲まれた識別子では、大文字と小文字の区別が行われます。 結合列とフィルター列で適切な b ツリー インデックスを確保します。 クエリの折りたたみを早期に中断する関数は避けてください。 テキスト結合と数値結合に対する暗黙的なキャストを確認します。
-
MySQL: 一貫性のある照合順序と SQL モードを使用します。 一般的なフィルターと結合パターンの複合インデックスを作成します。 大きな
TEXT列を使用すると、折りたたみや強制後処理を減らすことができます。 - Snowflake、BigQuery、Databricks: エラスティック スケーリングではコンカレンシーが向上しますが、コールド スタートの待機時間が最初のクエリに影響する可能性があります。 ウォームアップ ping を送信するか、定期的なアクティビティをスケジュールします。
- Azure Synapse、SQL、および Fabric Warehouse: 列ストア インデックスと結果セット キャッシュは、強力な高速化を提供します。 それらを自動集計とペアリングします。
-
Kusto ベースのソース (Azure Data Explorer および Fabric KQL データベース): プロジェクションの排除は重要です。 必要な列のみを選択し、フィルターを早期にプッシュします。 大量の時系列テレメトリの場合は、クライアント側のグループ化ではなく、ソース側の集計を使用します。
make-series、summarize、series_decompose_anomaliesを KQL エンジンにプッシュし、集計された結果をビジュアルに返します。 Power Queryステップがネイティブ KQL にフォールドされ、未加工のイベントではなく集計された結果がPower BIに返されることを確認します。 - SAP BW と SAP HANA: 測定の解決と階層セマンティクスによってクエリ パターンが促進されます。 折りたたみをブロックするオーバーレイ変換は避けてください。
変換がプッシュダウンされることを確認するには、Power Query エディター で View Native Query を選択します。
DirectQuery に関する制限
DirectQuery を使用すると、一貫性、パフォーマンス、セキュリティ、変換、モデリング、レポートに影響があります。
一般的な影響
Power BIで DirectQuery を使用する場合、次の一般的な影響が適用されます。
- 最新のデータを表示するには更新してください。 キャッシュ (ビジュアル、タイル、結果) は、ビジュアルが更新されるまで前の結果を表示できることを意味します。 [ 最新の情報に更新] を選択して、ページ上のすべてのビジュアルの再クエリを強制します。
- ビジュアルは常に時間の整合性を保つとは限りません。 異なるビジュアル (または 1 つのビジュアル内の内部クエリ) は、少し異なる時間に実行できます。 厳密なポイントインタイム精度が必要な場合は、ページを更新するか、集計スナップショットを設計します。
- スキーマの変更には、Power BIデスクトップ更新が必要です。 削除された列または名前が変更された列は、サービスによって自動的に検出されません。 Power BI Desktop でモデルを開き、モデル メタデータを調整するために更新します。
- 中間結果に対する100万行の制限。 1,000,000 行を超える行を返すクエリ (または中間操作) は失敗します。 Premium 容量では、この制限を引き上げることができます。 「中間行セットの最大数」を参照してください。
- ストレージ モードの変更は制約されます。 インポート専用モデルを DirectQuery にグローバルに切り替えることはできません。 次のセクションを参照してください。
Important
Power BIにデータを格納およびクエリするエンジンでは大文字と小文字が区別されないため、大文字と小文字を区別するソースを使用して DirectQuery モードで作業する場合は、特別な注意を払います。 Power BIは、ソースが重複する行を排除していることを前提としています。 Power BIでは大文字と小文字が区別されないため、大文字と小文字のみが異なる 2 つの値が重複として扱われますが、ソースではそのように扱われません。 このような場合、最終的な結果は未定義です。
このような状況を回避するには、大文字と小文字を区別するデータ ソースで DirectQuery モードを使用する場合は、ソース クエリまたはPower Query エディターで大文字と小文字を正規化します。
ストレージ モードの変更 (インポート↔DirectQuery)
モデルのインポート全体を DirectQuery に切り替えることはできません。 その代わりに:
- 同じソースに新しい DirectQuery 接続を追加し、ビジュアルを新しいテーブルにマップします。
- 複合モデルを作成します。インポートされたディメンションを保持しつつ、DirectQuery ファクト テーブルを追加します(またはその逆も可)。必要に応じて、いくつかのテーブルをデュアルとして設定します。
- ホットとコールドの最適化には、ハイブリッド テーブル (最近の DirectQuery パーティションと履歴インポート) を使用します。
- 前の手順で DirectQuery が禁止されている場合は、フォールドフレンドリ変換を使用して再構築します。
注意
DirectQuery 対応の接続を介して追加された個々のテーブルは、適用されたすべての変換がまだ折りたたまれている場合、DirectQuery、インポート、デュアルを切り替えることができます。
パフォーマンスと負荷の影響
対話型のパフォーマンスは、ソースの待機時間とコンカレンシーによって異なります。 5 秒以下の一般的なビジュアル更新時間を目指します。30 秒を超える場合、使いやすさが低下します。 各ユーザー アクションはクエリをトリガーします。 ユーザー、ビジュアル、タイルの更新数が多い場合、負荷が大きくなる可能性があります。それに応じて容量を計画します。
セキュリティへの影響
SSO が構成されていない限り、DirectQuery では、すべてのビューアーに対して構成された保存された資格情報が使用されます。 必要に応じて、セマンティック モデルで RLS を定義します。 複合モデル内の複数のソースは、ソース間でデータを移動できます。機密データの移動を評価します。 セキュリティへの影響を参照してください。
データ変換の制限
スケーラブルな性能を実現するために、Power Query folding が必要です。 変換は、単一のネイティブ クエリに凝縮する必要があります。 複雑な手順 (非折り込み操作、特定のカスタム関数、複数ステップの手続き型ロジック) により、簡略化またはインポートへの切り替えが必要なエラーが発生する可能性があります。 SAP BW などの OLAP ソースでは、外部モデル全体が公開されるため、クエリ内変換は許可されません。 ストアド プロシージャ呼び出しと共通テーブル式 (CTE) は、DirectQuery での折りたたみを可能にする方法ではサポートされていません。
モデリングの制限事項
ほとんどのエンリッチメントは機能しますが、一部の機能は縮小されています。
- 日付階層は自動的に作成されません (明示的な日付テーブルを作成します)。
- 時間の精度は秒に限定されます。ミリ秒は削除してください。
- 集計列は、折りたたまれる行レベルの式に制限されます。サポートされていない関数がオートコンプリートから省略されました。
- 親子 PATH 関数はありません。
- クラスタリングはサポートされていません。
レポート作成の制限事項
ほとんどのビジュアルは、ソースが応答している場合に機能します。 次の制限事項とパフォーマンスに関する考慮事項をご覧ください。
- 32,764 文字を超える長いテキスト列はサポートされていません。
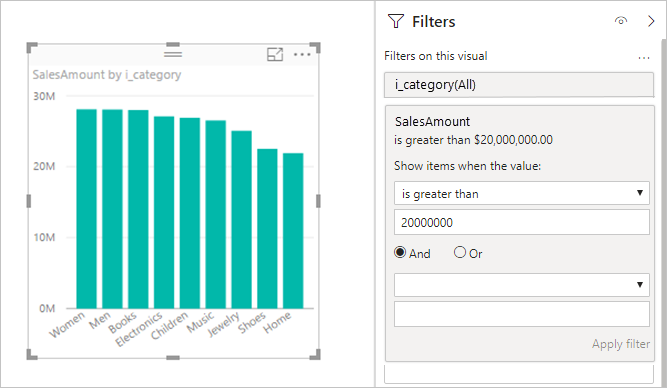
- メジャーフィルター、TopNフィルター、
Median、テキストの高度な含有/開始フィルター、複数選択スライサー、および合計/小計(特にDistinctCountの場合)は、追加のクエリを発生させたりパフォーマンスを低下させたりする可能性があります。 - 設計を簡略化するか、特定の操作を無効にすることを検討してください。
例 (測定フィルター):
DirectQuery に関する推奨事項
このセクションでは、Power BIでの DirectQuery モデルの設計、最適化、トラブルシューティングに関する実用的な推奨事項について説明します。 DirectQuery 接続を使用する場合のパフォーマンス、信頼性、ユーザー エクスペリエンスを向上させるには、次のガイドラインに従います。
基になるデータ ソースのパフォーマンス
ベースライン対話型クエリを検証します。 低速の場合は、パフォーマンス アナライザーを使用してクエリを検査し、ソース スキーマ (インデックス、統計、列ストア (該当する場合)) を最適化します。 結合には整数キーを優先します。
モデルの設計
- Power Query のステップをシンプルで折りたたみ可能にします。 "ネイティブ クエリの表示" を頻繁にプレビューします。
- 単純な対策から始めて、繰り返し実行します。
- 計算式列での結合を避け、必要に応じてソースで具体化します。
-
uniqueidentifierでの結合を回避するキャストがインデックスの使用を中断する場合。代替キーの種類を具体化します。 - サロゲート/システム キーを非表示にする。必要に応じて、表示されるエイリアス付き列を作成します。
- 折り返し不可能な式を生成できる計算テーブル/列を確認します。
- 双方向フィルター を必須ケースのみに制限します。 パフォーマンスへの影響をテストします。
-
参照整合性を想定 して、
INNER JOINの使用を有効にすることを検討してください。 - Power Query で相対日付フィルターを避ける。 代わりに、モデルまたはレポート レイヤーに相対ロジックを実装します。
フィルター処理の例:
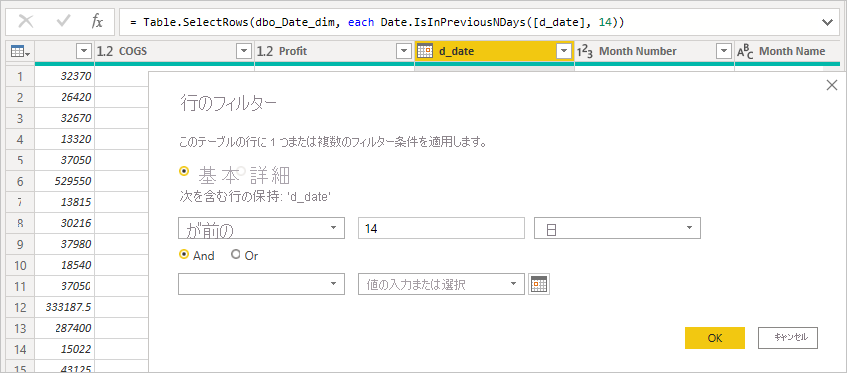
結果のネイティブ クエリでは、固定リテラル日付が使用されます。
レポート デザイン
DirectQuery を使用するレポートを設計する場合は、使いやすさとパフォーマンスを最適化するために次のベスト プラクティスを検討してください。
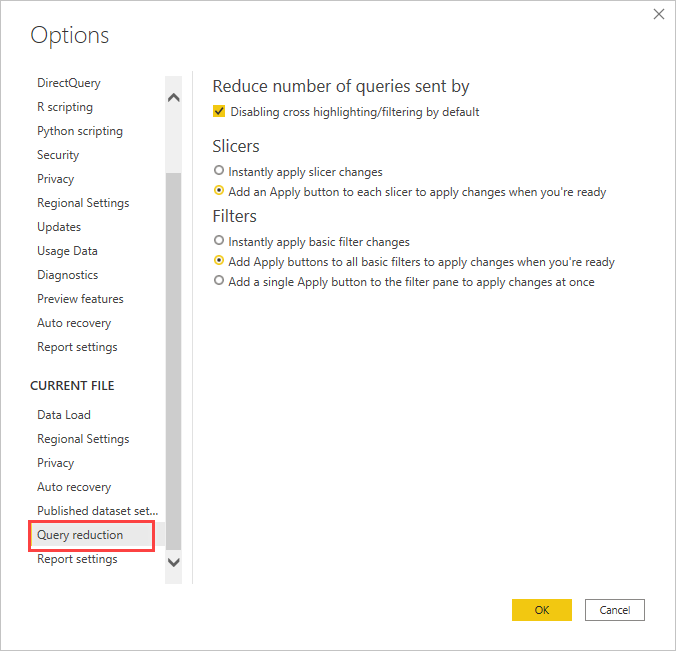
クエリ削減オプションを使用します (スライサーとフィルターには [適用] ボタンを使用し、待機時間によってエクスペリエンスが損なわれるクロス強調表示を無効にします)。
キー フィルターを早期に適用して、中間行数を減らし、制限に達しないようにします。
並列クエリとシリアル化されたクエリを最小限に抑えるために、ページごとのビジュアルを制限します。
コストの高いソース クエリをトリガーする場合は、不要な操作 (クロス フィルター処理または強調表示) を無効にします。
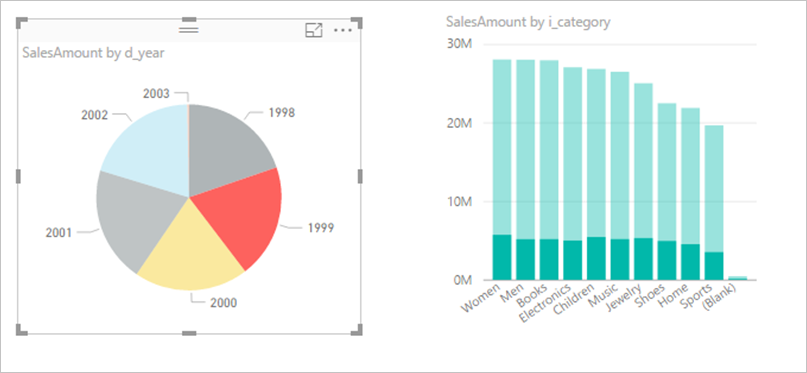
[接続の最大数]
ファイルごとの DirectQuery コンカレンシーを [ファイル] > [オプションと設定] > [オプション] > DirectQueryで調整します (既定では 10)。
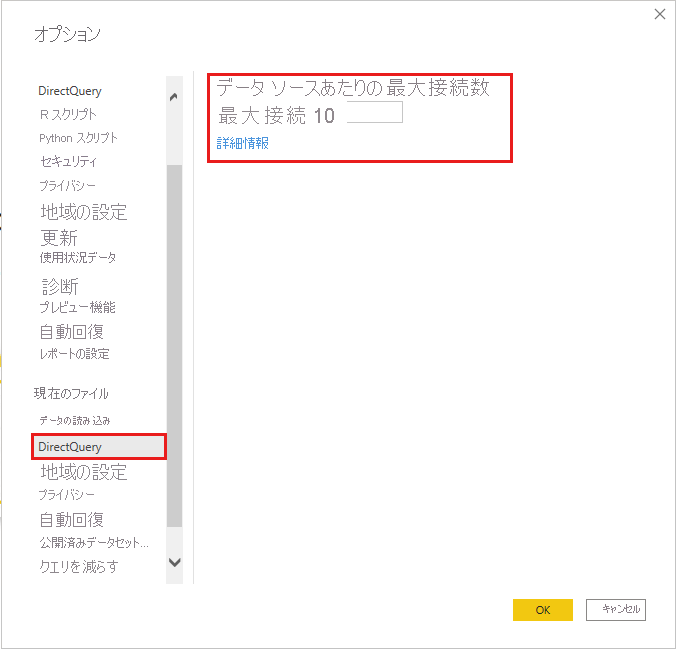
値を大きくすると、多くのビジュアルのスループットが向上しますが、ソースの読み込みも増加する可能性があります。 公開された動作は、サービスまたは容量の制限にも依存します。
| 環境 | データ ソースあたりの上限 |
|---|---|
| Power BI Pro | 10 アクティブ接続 |
| Power BI Premium | セマンティック モデルのストック保持ユニット (SKU) の制限に依存 |
| Power BI Report Server | 10 アクティブ接続 |
注意
拡張メタデータが有効になっている場合 (新しいモデルの場合は既定値) は、DirectQuery 接続の最大設定がすべての DirectQuery ソースに適用されます。
パフォーマンス軽減機能
DirectQuery のパフォーマンスを向上させるには、次の機能を使用します。
- 自動集計と手動集計テーブル: 集計データをキャッシュしてソース クエリを減らします。
- ハイブリッド テーブル: DirectQuery を使用して最新のデータを保持し、インポートを使用して履歴を保持します。
- 集計対応のメジャー設計: 可能な場合は、DAX が集計レイヤーで評価されるようにします。
- 動的 M パラメーター: ユーザーの選択をソース述語に早い段階でプッシュします。
- クエリと結果のキャッシュ (容量設定): 繰り返し表示するために最近の結果セットを再利用します。
- 共有ディメンション テーブルのデュアル ストレージ モード: リモート ディメンション スキャンの繰り返しを減らします。
Power BI サービス における DirectQuery
すべての DirectQuery データ ソースは、Power BI Desktop を介してサポートされます。 サービス UI から直接開始されるのは、限られたサブセットのみです。 Power BI Desktop から始めて、より高度なモデリングと変換の制御を行います。 サービスで直接使用できるソースの現在の一覧については、「Power BI データ ソースを参照してください。
サービスのパフォーマンスは次に依存します。
- 同時ユーザーの数
- 視覚的な複雑さとページあたりの数
- 行レベルのセキュリティの存在 (キャッシュの再利用を減らすことができます)
- タイル更新スケジュール
Power BI サービスでのレポートの動作
レポート ページを開くと、ビジュアルごとにクエリが実行されます (ビジュアルごとに複数の場合があります)。 操作 (スライサーの変更、クロスハイライト、フィルター) により、クエリが再度実行されます。 サービスによっていくつかの結果がキャッシュされます。 セキュリティの境界が異なる場合を除き、正確な繰り返しクエリは即座に返されます。
機能の違い:
- クイック分析情報: DirectQuery セマンティック モデルではサポートされていません。
- Excel での分析 / Analyze in Excel: サポートされていますが、速度が低下する可能性があります。 Excelの使用量が多い場合は、インポート モードまたは集計を検討してください。
- Excel の 階層: 一部の DirectQuery セマンティック モデルの階層は、Excel で同じように表示されません。
ダッシュボードの更新
DirectQuery タイルはスケジュールに従って更新されます。 既定値は1時間ごとですが、15分ごとから毎週まで設定することができます。 行レベルのセキュリティでは、各ユーザーが個別のタイル クエリを実行します。 タイルの数にユーザー数と更新頻度を乗算すると、負荷が高くなる可能性があります。容量を計画し、集計を検討します。
クエリのタイムアウト
このサービスでは、クエリごとに 4 分間のタイムアウトが適用されます。 制限を超えるビジュアルは、タイムアウト エラーで失敗します。 DirectQuery を選択する前に、基になるソースが対話型のパフォーマンスを提供することを確認します。
パフォーマンス診断
Power BI Desktop で最初にパフォーマンスを診断します。
パフォーマンス アナライザーを使用して、低速のビジュアルを分離します。 一度に 1 つの問題のあるビジュアルに焦点を当てます。
SQL Server Profiler を使用してクエリを表示する
Power BI Desktop は、一部のソースの DirectQuery SQL を含むセッション トレースを、ユーザーの
トレースを確認するには次の手順に従ってください:
Power BI Desktop で、ファイル > オプションと設定 > オプション > 診断 を選択します。
[ クラッシュ ダンプ/トレース フォルダーを開く] を選択します。
![トレース フォルダーを開くリンクを含む Power BI Desktop の [診断オプション] ダイアログのスクリーンショット](media/desktop-directquery-about/directquery-about_06.png)
AnalysisServicesWorkspaces に 1 レベル上がり、アクティブなワークスペース フォルダーを開き、[データ] を開き、FlightRecorderCurrent.trc を見つけます。
SQL Server Profiler で、ファイル File >> トレース ファイルを開くを開きます。
Profiler では、グループ化されたイベントが表示されます。
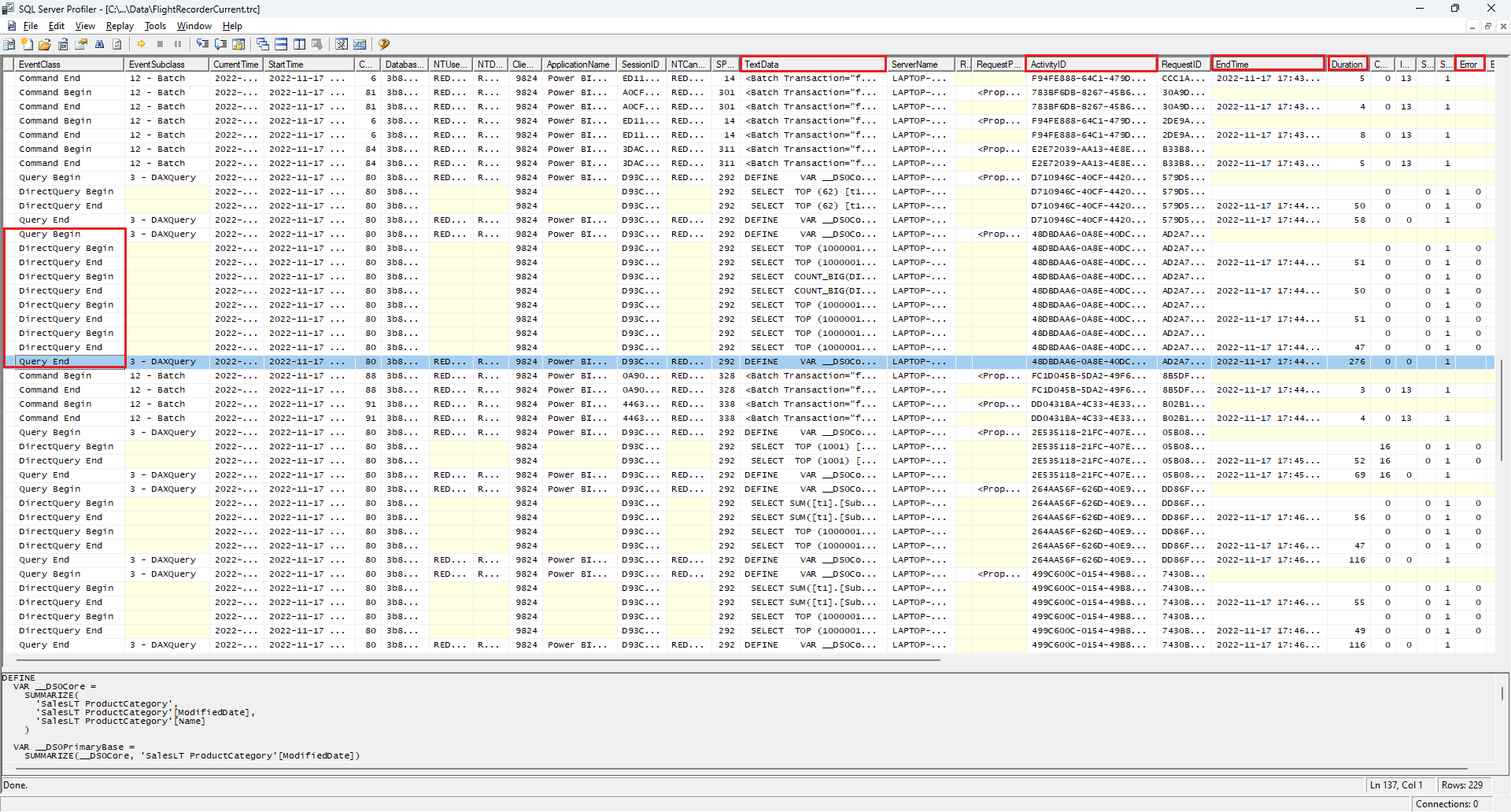
イベント列:
- TextData: DAX (クエリの開始/終了の場合) またはネイティブ SQL (DirectQuery Begin/End の場合)。
- Duration (ms) と EndTime は 、低速なステージを特定するのに役立ちます。
- ActivityID は関連するイベントをグループ化します。
キャプチャ ガイダンス:
- セッションを短くする (≈ 10 秒の対象となるアクション)。
- トレース ファイルをもう一度開き、新しくフラッシュされたイベントを表示します。
- 混乱を減らすために、複数の同時デスクトップ インスタンスを避けてください。
クエリの形式を理解する
Power BIは、多くの場合、Power Queryステップで定義された参照される論理テーブルごとにサブセレクト (派生テーブル) を使用します。
SQL ServerのサンプルTPC-DSテーブルのスクリーンショットで、生成されたSQLパターンをDirectQueryビジュアルに示すために使用されます。
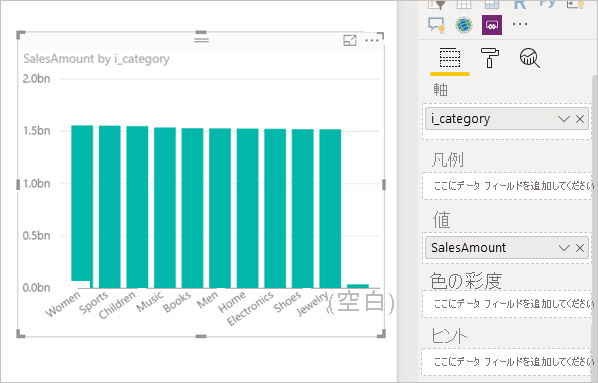
サンプル クエリ ロジック:
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
結果のビジュアル:
サブセレクトを使用して生成された SQL:
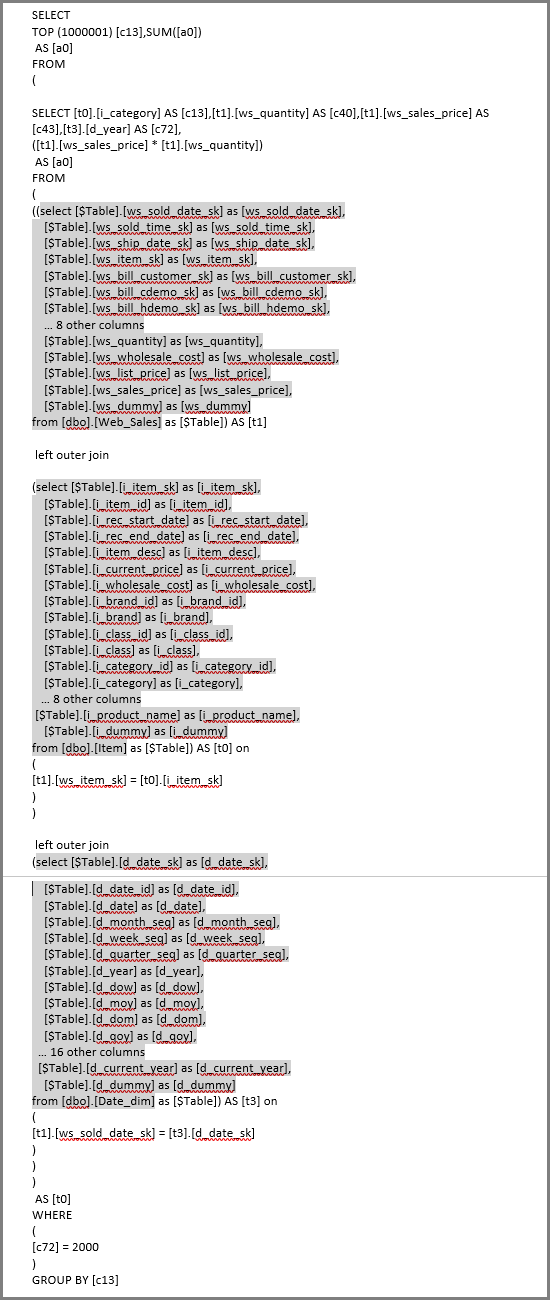
オプティマイザーによって未使用の列が排除されるため、通常、サブセレクト クエリ パターンはサポートされているエンジンのパフォーマンスを損ないません。 折りたたみ性に優先順位を付けます。
注意
この記事では、Power BIの DirectQuery に関する一般的なガイダンスを提供します。 運用環境にデプロイする前に、DirectQuery のパフォーマンスと動作を特定のデータ ソース、スキーマ、インデックス、ワークロード、コンカレンシーの要件で常に検証してください。