データフローを使用すると、複数のソースからのデータを統合し、その統合データをモデリング用に準備できます。 データフローを作成するたびに、データフローのデータを更新するように求められます。 データフローを Power BI Desktop のセマンティック モデルで使用したり、リンクテーブルまたは計算テーブルとして参照したりする前に、データフローを更新する必要があります。
注
データフローは、米国政府の DoD のお客様全員が Power BI サービスで利用できない場合があります。 使用可能な機能と使用できない機能の詳細については、 米国政府のお客様向けの Power BI 機能の可用性に関する記事を参照してください。
データフローを構成する
データフローの更新を構成するには、[ その他のオプション ] (省略記号) を選択し 、[設定] を選択します。
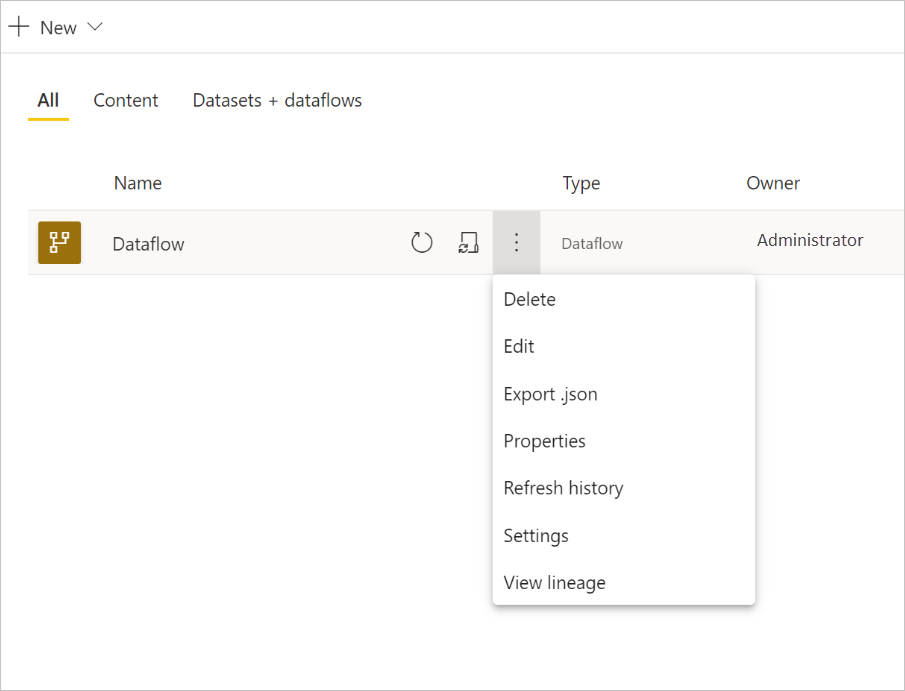
次のセクションで説明するように、[ 設定] オプションには、データフローの多くのオプションが用意されています。
![[データフロー] ドロップダウンで [設定] を選択した後のデータフローの [設定] ページのスクリーンショット。](media/dataflows-configure-consume/dataflow-settings-detailed.png)
所有権: データフローの所有者でない場合、これらの設定の多くは無効になります。 データフローの所有権を取得するには、[ 引き継ぐ ] を選択して制御します。 必要なアクセス レベルを確保するための資格情報の入力を求められます。
ゲートウェイ接続: このセクションでは、データフローでゲートウェイを使用するかどうかを選択し、使用するゲートウェイを選択できます。 データフローの編集の一環としてゲートウェイを指定している場合は、所有権を取得するときに、データフローの編集オプションを使用して資格情報を更新する必要があります。
データ ソースの資格情報: このセクションでは、使用する資格情報を選択し、データ ソースに対する認証方法を変更できます。
秘密度ラベル: ここでは、データフロー内のデータの機密性を定義できます。 秘密度ラベルの詳細については、「 Power BI で秘密度ラベルを適用する方法」を参照してください。
スケジュールされた更新: ここでは、選択したデータフローが更新される時刻を定義できます。 データフローは、セマンティック モデルと同じ頻度で更新できます。
拡張コンピューティング エンジンの設定: ここでは、データフローをコンピューティング エンジンに格納するかどうかを定義できます。 コンピューティング エンジンを使用すると、このデータフローを参照する後続のデータフローで、それ以外の場合よりも高速にマージや結合などの変換を実行できます。 また、DirectQuery をデータフローに対して実行することもできます。 [オン] を選択すると、データフローが DirectQuery モードで常にサポートされ、すべての参照がエンジンの恩恵を受けます。 [ 最適化] を選択すると、このデータフローへの参照がある場合にのみエンジンが使用されます。 [オフ] を選択すると、このデータフローのコンピューティング エンジンと DirectQuery 機能が無効になります。
承認: データフローを認定または昇格させるかを定義できます。
注
Pro ライセンスまたは Premium Per User (PPU) を持つユーザーは、Premium ワークスペースにデータフローを作成できます。
注意事項
データフローを含むワークスペースが削除されると、そのワークスペース内のすべてのデータフローも削除されます。 ワークスペースの回復が可能な場合でも、削除されたデータフローを直接または Microsoft のサポートを通じて復旧することはできません。
データフローを更新する
データフローは、相互に構成要素として機能します。 生データと呼ばれるデータフローと、変換されたデータと呼ばれるリンク テーブルがあり、そのテーブルには生データ データフローへのリンク テーブルが含まれているとします。 生データ フローのスケジュール更新がトリガーされると、完了時にそれを参照するすべてのデータフローがトリガーされます。 この機能により、更新のチェーン効果が作成されるため、データフローを手動でスケジュールする必要がなくなります。 リンク テーブルの更新を処理する際には、注意すべきいくつかの違いがあります。
リンク テーブルは、同じワークスペースに存在する場合にのみ、更新によってトリガーされます。
ソース テーブルが更新されている場合、またはソース テーブルの更新が取り消されている場合、リンク テーブルは編集用にロックされます。 参照チェーン内のいずれかのデータフローが更新に失敗すると、すべてのデータフローが古いデータにロールバックされます (データフローの更新はワークスペース内のトランザクションです)。
ソースの更新が完了すると、参照先テーブルのみが更新されます。 すべてのテーブルをスケジュールするには、リンク テーブルにもスケジュール更新を設定する必要があります。 二重更新を回避するために、リンクされたデータフローに更新スケジュールを設定しないでください。
更新の取り消し データフローでは、セマンティック モデルとは異なり、更新を取り消す機能がサポートされています。 更新が長時間実行されている場合は、[ その他のオプション ] (データフローの横にある省略記号) を選択し、[更新の キャンセル] を選択できます。
増分更新 (Premium のみ) データフローは、増分更新するように設定することもできます。 これを行うには、増分更新用に設定するデータフローを選択し、[ 増分更新 ] アイコンを選択します。

増分更新を設定すると、データフローにパラメーターが追加され、日付範囲が指定されます。 増分更新を設定する方法の詳細については、「 データフローでの増分更新の使用」を参照してください。
増分更新を設定すべきでない状況がいくつかあります。
リンク テーブルがデータフローを参照している場合は、増分更新を使用しないでください。 データフローでは、(テーブルが DirectQuery が有効になっている場合でも) クエリ フォールディングはサポートされません。
データフローを参照するセマンティック モデルでは、増分更新を使用しないでください。 通常、データフローへの更新はパフォーマンスが高いので、増分更新は必要ありません。 更新に時間がかかりすぎる場合は、コンピューティング エンジンまたは DirectQuery モードの使用を検討してください。
データフローを消費する
データフローは、次の 3 つの方法で使用できます。
別のデータフロー作成者がデータを使用できるように、データフローからリンク テーブルを作成します。
データフローからセマンティック モデルを作成して、ユーザーがデータを利用してレポートを作成できるようにします。
CDM (Common Data Model) 形式から読み取ることができる外部ツールから接続を作成します。
Power BI Desktop から使用するデータフローを使用するには、Power BI Desktop を開き、[データの取得] ドロップダウンで [データフロー] を選択します。
注
Dataflows コネクタは、現在ログインしているユーザーとは異なる資格情報セットを使用します。 これは、マルチテナント ユーザーをサポートするための仕様です。
![[データの取得] ドロップダウンの [データフロー] オプションが強調表示されている Power BI Desktop のスクリーンショット。](media/dataflows-configure-consume/dataflow-connector-menu.png)
接続するデータフローとテーブルを選択します。
注
どのデータフローまたはテーブルに接続しても、どのワークスペースに存在するか、Premium ワークスペースまたは Premium 以外のワークスペースで定義されたかどうかに関係なく、接続できます。
DirectQuery が使用可能な場合は、DirectQuery またはインポートを使用してテーブルに接続するかどうかを選択するように求められます。
DirectQuery モードでは、大規模なセマンティック モデルをすばやくローカルで問い合わせて使用できます。 ただし、それ以上変換を実行することはできません。
インポートを使用すると、データが Power BI に取り込まれるので、データフローとは別にセマンティック モデルを更新する必要があります。
関連コンテンツ
データフローと Power BI の詳細については、以下の記事を参照してください。