適用対象:![]() Power BI Desktop
Power BI Desktop ![]() Power BI サービス
Power BI サービス
主要なインフルエンサーのビジュアルは、関心のあるメトリックを推進する要因を理解するのに役立ちます。 データを分析し、重要な要因にランクを付け、主要なインフルエンサとして表示します。 たとえば、従業員の離職率 (チャーンとも呼ばれます) に何が影響するかを把握したいとします。 要因は雇用契約期間である場合や、通勤時間である場合があります。
この記事では、Power BI で主要なインフルエンサー ビジュアルを使用する方法に関する詳細なチュートリアルを提供します。 ビジュアルを設定し、その結果を解釈し、一般的な問題のトラブルシューティングを行う方法について説明します。 顧客からのフィードバック、売上、その他のメトリックなど、データ内の特定の結果を引き起こす要因を理解する必要がある場合、このガイドは、Power BI の AI を利用した分析ツールを使用して実用的な分析情報を得るのに役立ちます。
主要なインフルエンサーを使用するタイミング
主要なインフルエンサーの視覚化は、次のような場合に最適な選択です。
- 分析対象のメトリックに影響する要因を確認する。
- これらの要因の相対的重要度を比較する。 たとえば、短期契約は長期契約の場合よりもチャーンへの影響が大きくなるかなど。
主要なインフルエンサーの視覚化の機能
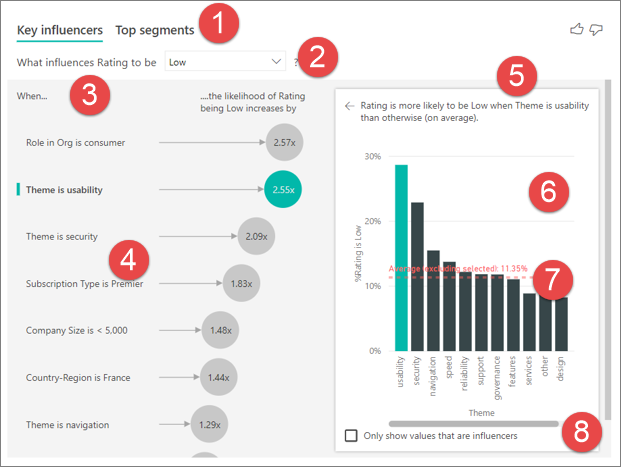
タブ: タブを選択し、ビューを切り替えます。 [主要なインフルエンサー] では、選択されたメトリック値に影響した上位の要素が示されます。 [上位セグメント] では、選択されたメトリック値に影響した上位のセグメントが示されます。 セグメント は、値の組み合わせで構成されます。 たとえば、1 つのセグメントは、長期的な顧客であり、西リージョンに住んでいるコンシューマーです。
ドロップダウン ボックス: 調査中のメトリックの値。 この例では、評価のメトリックを調べます。 選択された値は [低] です。
再述: 左側のウィンドウのビジュアルを解釈するのに役立ちます。
左側のウィンドウ:左側のウィンドウには 1 つの視覚化が含まれています。 この場合、左側のウィンドウには、上位の主要なインフルエンサーのリストが示されています。
テキスト表示: 右側のウィンドウの視覚化を解釈するのに役立ちます。
右側のウィンドウ:右側のウィンドウには 1 つの視覚化が含まれています。 この場合、縦棒グラフには、主要なインフルエンサー (左側のウィンドウで選択されているテーマ) のすべての値が表示されています。 左側のウィンドウから使いやすさの特定の値が緑色で示されています。 テーマの他のすべての値は黒で表示されています。
平均線:使いやすさ (選択されたインフルエンサー) を除く、テーマのすべての有効な値の平均が計算されています。 したがって、計算は黒のすべての値に適用されています。 低評価となったその他のテーマの割合がわかります。 この場合、11.35% は低い評価を持っていました (点線で示されています)。
チェックボックス: 右側のペインのビジュアルをフィルター処理して、そのフィールドのインフルエンサーである値のみを表示します。
メトリックの中でカテゴリー型のものを分析する
- あなたは、プロダクト マネージャーから顧客が自社のクラウド サービスについて否定的なレビューをすることにつながる要因を把握するように指示されています。 Power BI Desktop で把握するには、カスタマー フィードバック PBIX ファイルを開きます。
注
カスタマーフィードバックデータセットは、[Moro et al., 2014] S. Moro、P. Cortez、P. Rita に基づいています。 銀行のテレマーケティングの成功を予測するデータ駆動型アプローチ。Decision Support Systems, Elsevier, 62:22-31, June 2014.
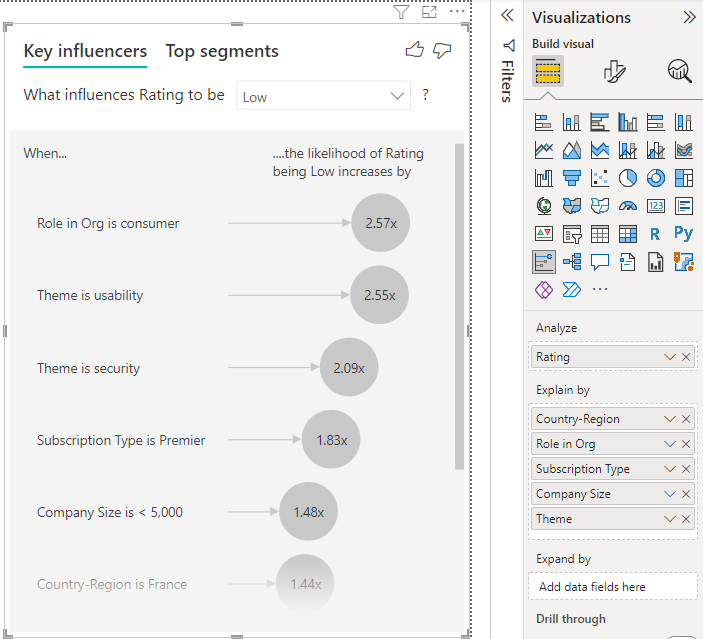
[視覚化] ウィンドウの [ビジュアルのビルド] で、[主要なインフルエンサー] アイコンを選択します。
![[視覚化] ウィンドウの [主要なインフルエンサー] アイコンのスクリーンショット。](media/power-bi-visualization-influencers/power-bi-template-new.png)
調査するメトリックを [分析] フィールドに移動します。 サービスに対する顧客の評価が低くなる要因を確認するには、 [顧客テーブル]>[評価] の順に選択します。
評価に影響したと思われるフィードを [説明] フィールドにドラッグします。 フィールドは好きな数だけ移動することができます。 この場合、以下で始まります。
- 国/地域
- 組織でのロール
- サブスクリプションの種類
- 企業規模
- テーマ
Expand by フィールドは空のままにします。 このフィールドは、メジャーまたは集計されたフィールドを分析する場合にのみ使用されます。
負の評価に注目するには、[評価に影響するもの] ドロップダウン ボックスで [低] を選択します。
分析対象のフィールドのテーブル レベルで分析が行われます。 この場合は、評価メトリックです。 このメトリックは、顧客レベルで定義されます。 各顧客は、高いスコアまたは低いスコアを提供します。 すべての説明要因は、視覚化で利用するために顧客レベルで定義する必要があります。
上記の例では、すべての説明要因にはメトリックと一対一または多対一のリレーションシップがあります。 このケースでは、各顧客が 1 つのテーマを評価に割り当てました。 同様に、顧客は 1 つの国または地域に属しており、メンバーシップの種類を 1 つ持ち、組織内で 1 つのロールを担当しています。 説明要素は既に顧客の属性であり、変換は必要ありません。 ビジュアルではそれらをすぐに利用できます。
このチュートリアルで後ほど、一対多リレーションシップのより複雑な例を見ていきます。 その場合、分析を実行する前に、まず、列を顧客レベルまで集計する必要があります。
説明要因として使用されたメジャーと集計も、分析メトリックのテーブル レベルで評価されます。 この記事で後ほどいくつか例を示します。
カテゴリ別の主要なインフルエンサーを解釈する
低評価の主要なインフルエンサーを見ていきましょう。
低評価の確率に影響する上位の単一要因
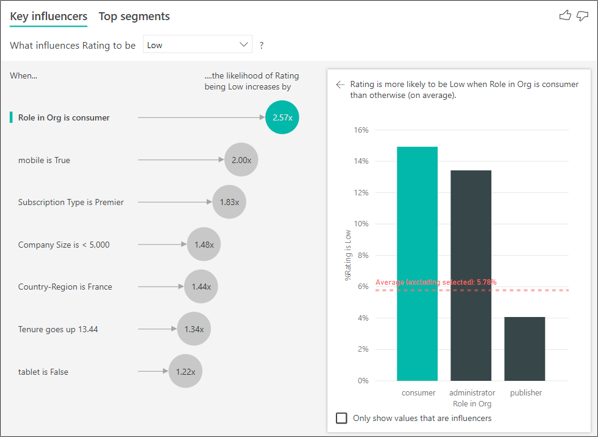
この例の顧客は、コンシューマー、管理者、または発行元の 3 つのロールのいずれかを持つことができます。 コンシューマーは、低評価に影響する上位の要因です。
![[Role in Org is consumer] が選択された主要なインフルエンサーのスクリーンショット。](media/power-bi-visualization-influencers/power-bi-role-consumer.png)
より正確に言えば、コンシューマーは、サービスに否定的なスコアを付ける可能性が 2.57 倍高くなっています。 主要なインフルエンサー グラフの左側のリストには、まず、 [Role in Org is consumer](組織でのロールはコンシューマー) が示されます。 [Role in Org is consumer](組織でのロールはコンシューマー) を選択することで、Power BI によって詳細が右側のウィンドウに示されます。 低評価の確率に対する各ロールの影響の比較が示されます。
- 14.93% のコンシューマーが低いスコアを付けています。
- 平均すると、他のすべての役割はその時点で 5.78% という低いスコアになります。
- コンシューマーは、他のすべてのロールと比べて、低いスコアを付ける可能性が 2.57 倍高くなっています。 このスコアは、緑の棒を赤の点線で分割することで判断できます。
低評価の確率に影響する 2 番目の単一要因
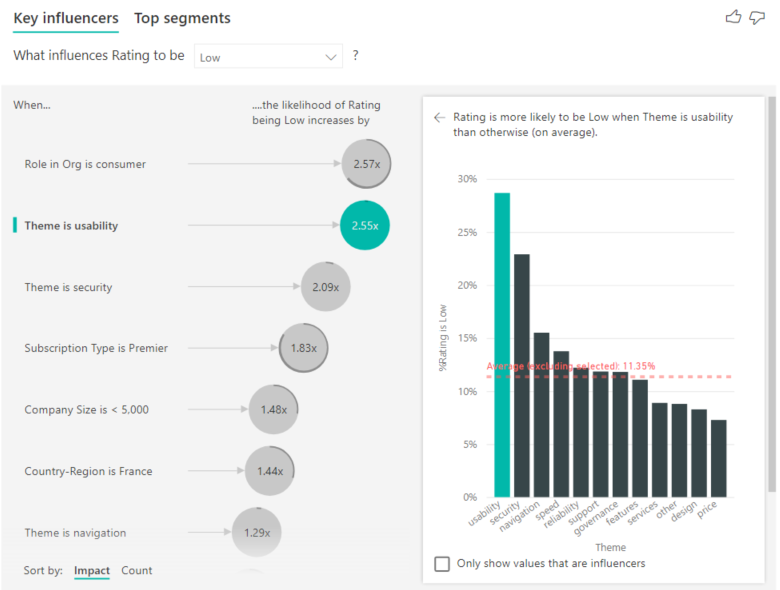
主要なインフルエンサーの視覚化では、さまざまな変数からの要因を比較してランク付けすることができます。 2 番目のインフルエンサーは、組織でのロールとは関係ありません。リストの 2 番目のインフルエンサーである [Theme is usability](テーマは使いやすさ) を選択します。
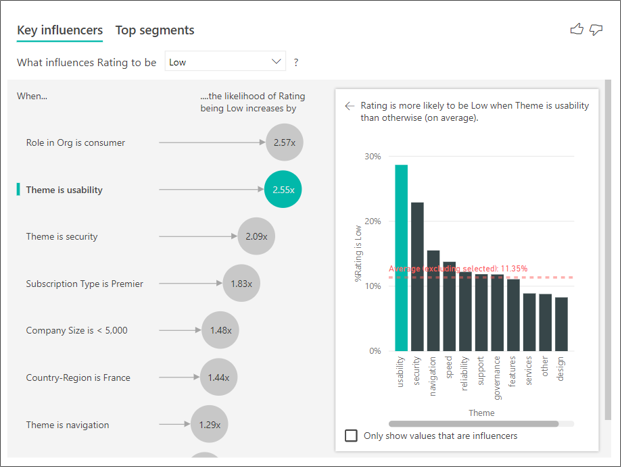
2 番目に重要な要因は、顧客のレビューのテーマに関連しています。 製品の使いやすさについてコメントした顧客は、信頼性、設計、速度などの他のテーマにコメントした顧客に比べ、低いスコアを付ける可能性が 2.55 倍高くなっています。
視覚化の赤い点線で示されている平均が 5.78% から 11.35% に変わりました。 平均は、その他のすべての値の平均に基づいているため動的です。 最初のインフルエンサーの場合、平均では顧客ロールが除外されています。 2 番目のインフルエンサーの場合、使いやすさのテーマが除外されています。
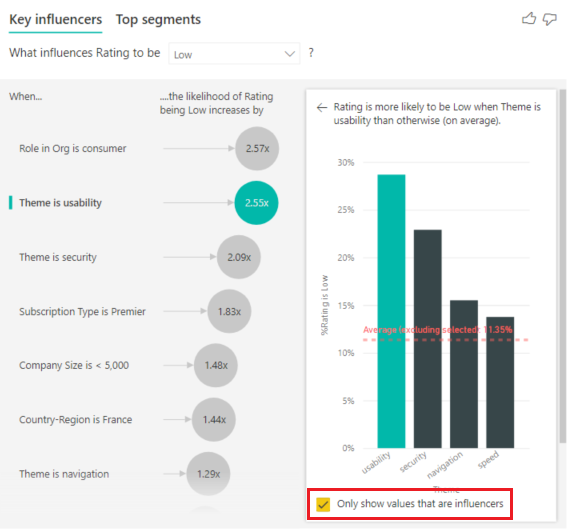
影響を受ける値のみを使用してデータをフィルター処理するには、[ インフルエンサーである値のみを表示 する] チェック ボックスをオンにします。 この場合、これらがスコアを低くするロールです。 12 個のテーマは、低評価を推進するテーマとして Power BI によって識別された 4 つに減らされます。
他の視覚化の操作
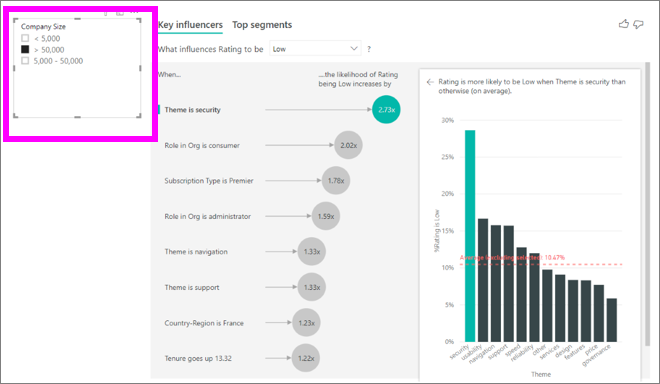
キャンバス上のスライサー、フィルター、またはその他の視覚化を選択するたびに、主要なインフルエンサーの視覚化によってデータの新しい部分の分析が再実行されます。 たとえば、レポートに企業規模を移動し、それをスライサーとして使用できます。 それを使用して、エンタープライズ顧客の主要なインフルエンサーが、一般集団と異なるかどうかを確認します。 エンタープライズの企業規模は、従業員数 50,000 人超です。
>[50,000] を選択すると、分析が再実行され、インフルエンサーが変更されたことがわかります。 大規模なエンタープライズ顧客の場合、低評価の上位インフルエンサーのテーマはセキュリティに関するものになっています。 さらに調査して、大企業の顧客が不満を持つ特定のセキュリティ機能があるかどうかを確認することをお勧めします。
継続的な主要なインフルエンサーを解釈する
ここまでは、ビジュアルを使用して、さまざまなカテゴリ フィールドが低い評価にどのように影響するかを調べる方法を学習しました。 [説明] フィールドに継続的な要因 (年齢、高さ、価格など) を入力することもできます。 テニュアが顧客テーブルから Explain by に移動されるとどうなるかを見てみましょう。 テニュアは、顧客がサービスを使用する期間を示しています。
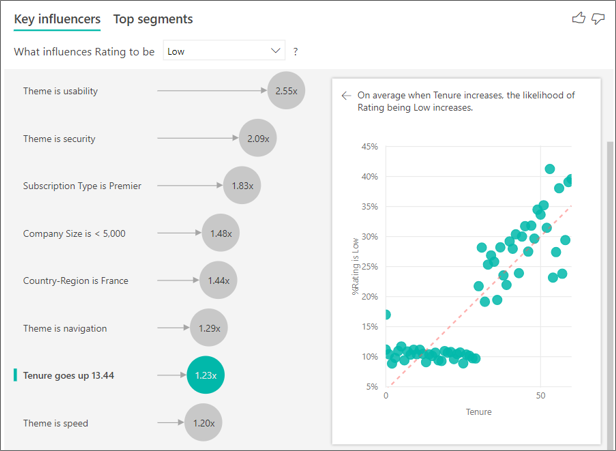
期間が増えるほど、低い評価を受ける可能性も増えます。 この傾向は、期間が長い顧客ほど否定的なスコアを付ける可能性が高いことを示しています。 この分析情報は興味深く、後でフォローアップした方がよいものです。
視覚化では、期間が 13.44 か月増えるごとに、平均して、低評価を受ける確率が 1.23 倍高くなることが示されています。 この場合、13.44 か月は期間の標準偏差を示しています。 したがって、得られた分析情報により、期間が標準量 (期間の標準偏差) だけ増えると、低評価を受ける確率にどのように影響するかがわかります。
右側のペインの散布図には、在任期間の各値に対する低評価の平均パーセンテージがプロットされます。 傾向線によって傾きが強調表示されます。
ビン分割された継続的な主要インフルエンサー
場合によっては、継続的な要因が自動的にカテゴリ別の要因に変わる場合があります。 変数間のリレーションシップが線形でない場合、(前の例のように) 単に増加または減少するリレーションシップを記述することはできません。
相関テストを実行して、インフルエンサーがターゲットと比較される直線性を判断します。 ターゲットが連続している場合は、ピアソン相関を実行します。ターゲットがカテゴリの場合は、Point Biserial 相関テストを実行します。 リレーションシップが十分に線形でないことを検出した場合は、監視ビン分割を実行し、最大 5 つのビンを生成します。どのビンが最も意味を持つのかを把握するために、監視下のビン分割方法を使用します。 監視ビン分割手法では、説明要因と分析対象の関係が調べられます。
指標と集計を重要な要因として解釈する
分析内の説明要素として、指標と集計を使用することもできます。 たとえば、カスタマー サポート チケットの数は、受け取ったスコアにどのような影響を与えます。 または、開いているチケットの平均期間が受け取るスコアにどのような影響を与えるか、などです。
この場合、顧客が持つサポート チケットの数が、その顧客が付けるスコアに影響するかどうかを確認します。 次に、[ サポート チケット] テーブルからサポート チケット ID を 取り込みます。 顧客は複数のサポート チケットを持つことができるため、ID を顧客レベルに集計します。 分析は顧客レベルで実行されるため、集計は重要です。そのため、細分性のレベルですべての要因が定義される必要があります。
ID の数を見てみましょう。 各顧客の行には、関連付けられているサポート チケットの数があります。 この場合、サポート チケットの数が増えると、評価が低くなる確率が 4.08 倍高くなります。 スクリーンショットは、顧客レベルで評価されたさまざまな Rating 値によるサポート チケットの平均数を示しています。
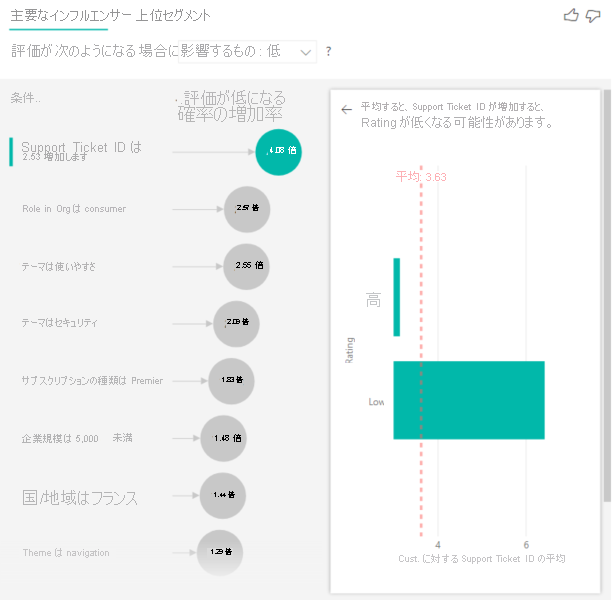
結果を解釈する:上位セグメント
[主要なインフルエンサー] タブを使用して、各要素を個別に評価できます。 また、 [上位セグメント] タブを使用して、要因の組み合わせが分析対象のメトリックにどのように影響するかを確認することもできます。
上位セグメントでは、最初に、Power BI によって検出されたすべてのセグメントの概要が表示されます。 次の例では、6 つのセグメントが検出されたことを示しています。 セグメント内の低い評価の割合によって順位が決まります。 たとえば、セグメント 1 では、低い顧客評価が 74.3% となっています。 バブルの位置が高くなるほど、低評価の比率も高くなります。 バブルのサイズはセグメント内の顧客数を表します。
![[上位セグメント] のタブが選択されているスクリーンショット。](media/power-bi-visualization-influencers/power-bi-top-segments-tab.png)
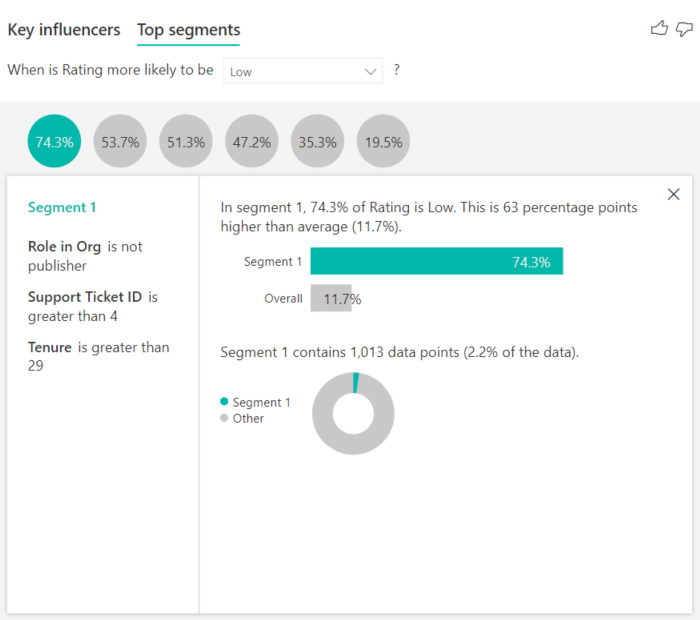
バブルを選択すると、そのセグメントの詳細が表示されます。 たとえば、セグメント 1 を選択すると、それが確立された顧客を表していることがわかります。 これらは顧客になってから 29 か月を超えており、4 枚超のサポート チケットを持っています。 最後に、これらはパブリッシャーではないため、コンシューマーか管理者のいずれかになります。
このグループでは、顧客の 74.3% が低い評価を付けました。 その時点で低い評価を付けた顧客の平均が 11.7% なので、このセグメントの低評価の割合は大きくなっています。 63 パーセンテージ ポイント高くなっています。 また、セグメント 1 には約 2.2% のデータが含まれているため、母集団の指定可能な部分を表しています。
カウントの追加
場合によっては、大きな影響を与えうるインフルエンサーであっても、データをあまり反映していない場合があります。 たとえば、[Theme is usability] は、低評価に対する 3 番目に大きいインフルエンサーです。 しかし、使いやすさに不満を訴えている顧客は少数だけである可能性があります。 カウントを使用すると、注目すべきインフルエンサーの優先順位を決めることができます。
カウントを有効にするには、[表示形式] ウィンドウの [分析] カード を使用します。
![[書式] ウィンドウの [カウント] スライダーの有効化のスクリーンショット。](media/power-bi-visualization-influencers/power-bi-ki-counts-toggle.png)
カウントを有効にすると、各インフルエンサーのバブルの周囲にリングが表示されます。これは、インフルエンサーに含まれるデータのおおよその割合を表します。 リングで囲まれているバブルの部分が多いほど、それに含まれるデータが多くなります。 "Theme is usability" に含まれるデータの割合が少ないことがわかります。
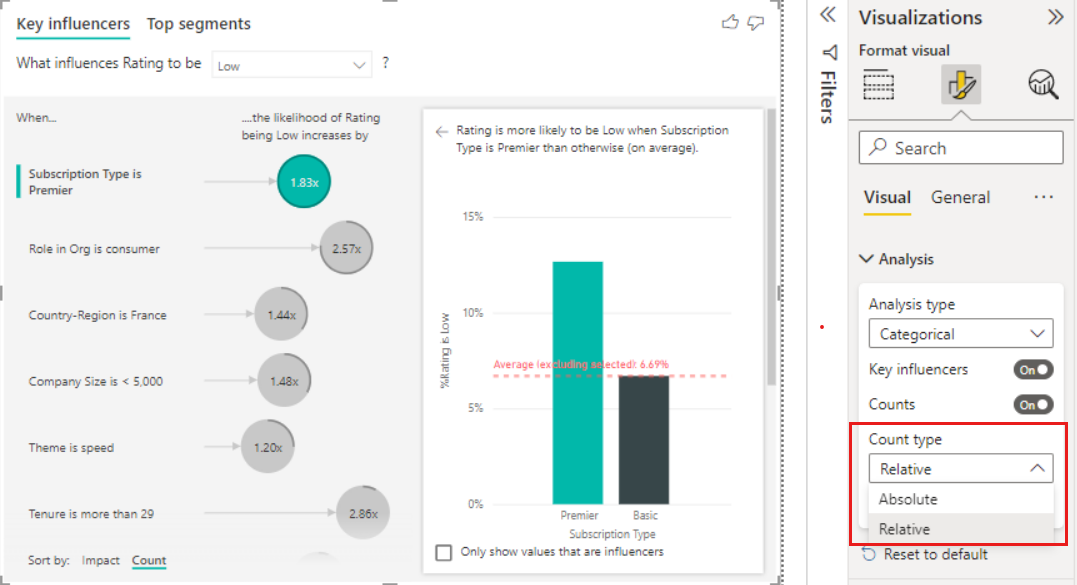
また、ビジュアルの左下にある [並べ替え条件] トグルを使用すると、影響ではなく最初にカウントでバブルを並べ替えることもできます。 "Subscription Type is Premier" は、カウントに基づくトップのインフルエンサーです。
![最初にカウントで並べ替えるための [並べ替え条件] トグルのスクリーンショット。](media/power-bi-visualization-influencers/power-bi-ki-counts-sort.png)
円がリングで完全に囲まれていると、そのデータの 100% がインフルエンサーに含まれることを意味します。 [表示形式] ビジュアル ウィンドウの [分析] カードで [カウントの種類] ドロップダウンを使用して、最大インフルエンサーに対して相対的なカウントの種類に変更できます。 データ量が最も多いインフルエンサーは完全なリングで表され、他のすべてのカウントはそれに対して相対的です。
数値のメトリックを分析する
集計されていない数値フィールドを [分析] フィールドに移動すると、そのシナリオの処理方法を選択できます。 ビジュアルの動作を変更するには、[ビジュアルの 書式設定 ] ウィンドウに移動し、 カテゴリ分析の種類 と 連続分析の種類を切り替えます。
![[カテゴリ別] から [継続的] に変更するためのドロップダウン メニューのスクリーンショット。](media/power-bi-visualization-influencers/power-bi-ki-formatting.png)
カテゴリ分析の種類については、この記事の前半で説明します。 たとえば、1 から 10 の範囲のアンケート スコアを見ると、"アンケート スコアが 1 に与える影響は何ですか?
継続的な分析タイプは、質問を継続的なものに変更します。 前の例を使用して、新しい質問は"アンケート スコアの増減に影響するものは何か" です。
この区別は、分析しているフィールド内に多数の一意の値がある場合に便利です。 次の例では、住宅価格を見ます。 それは具体的であり、パターンを推測するのに十分なデータを持っていない可能性があるため、「住宅価格が156,214に影響するものは何ですか?」と尋ねるのは意味がありません。
代わりに、住宅価格を個別の値ではなく範囲として扱うことを可能にする「住宅価格の上昇に影響するもの」を尋ねたいと思うかもしれません。
結果を解釈する 影響力のある人物
注
このセクションの例では、パブリック ドメインの住宅価格データを使用します。 記事の内容に従いたい場合は、サンプル データセットをダウンロードできます。
このシナリオでは、「住宅価格の上昇に影響するもの」を見ます。建築年 (家が 建 てられた年)、 KitchenQual (キッチン品質)、 YearRemodAdd (家が改装された年) など、いくつかの説明要因が住宅価格に影響する可能性があります。
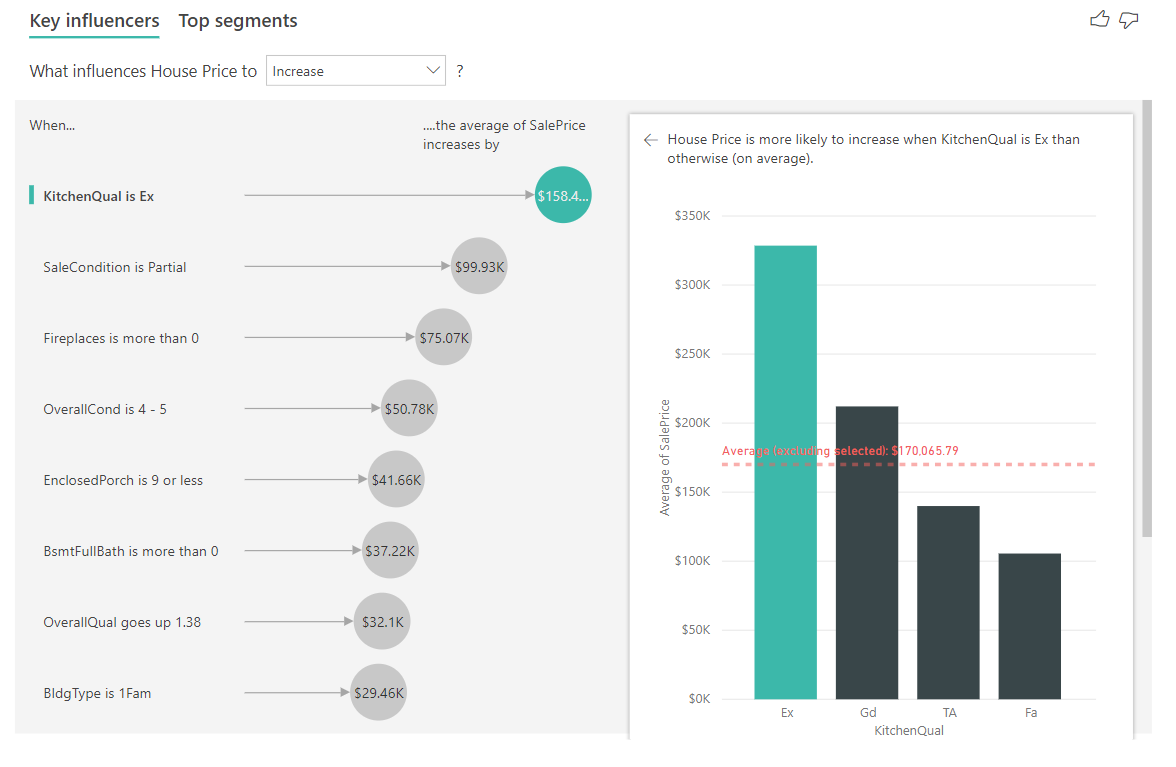
以下の例では、キッチンの品質が「優れている」ことが最大の影響を与えている要因として挙げられます。 結果は、いくつかの重要な相違点があるカテゴリ別のメトリックを分析したときに見たものと似ています。
- 右側の縦棒グラフはパーセンテージではなく、平均を示しています。 したがって、優れたキッチンを持つ家の平均住宅価格が(グリーンバー)優れたキッチン(点線)のない家の平均住宅価格と比較して何であるかを示しています。
- バブルの数値は赤い点線と緑の棒の差ですが、尤度 (1.93 倍) ではなく数値 (\$158.49K) で表されます。 だから、平均して、優れたキッチンを持つ家は、優れたキッチンのない家よりもほぼ\$160K高価です。
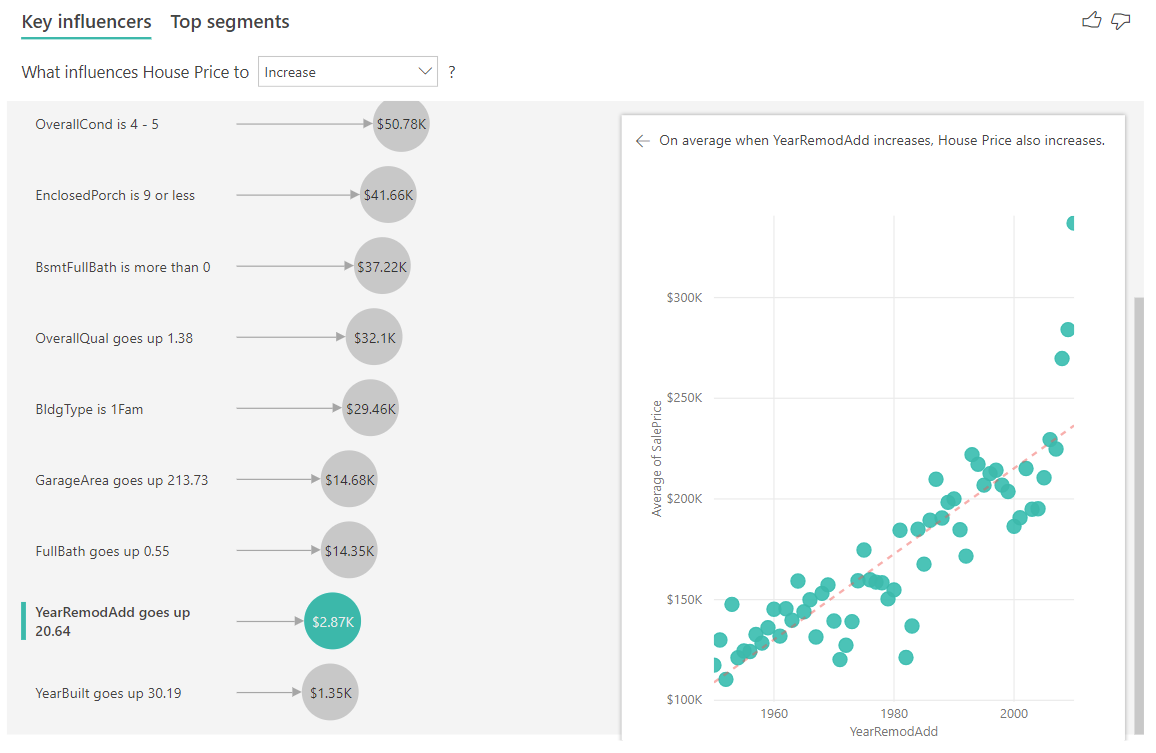
次の例では、継続的な要因 (年の家が改装された) が住宅価格に与える影響を見てみましょう。 カテゴリ別のメトリックの継続的インフルエンサーを分析する方法と比べて、違いは次のとおりです。
- 右側のペインにある散布図は、リフォームされた年のユニークな値ごとに平均住宅価格をプロットしています。
- バブル内の値は、住宅が改装された年がその標準偏差 (この場合は20年) によって増加するとき、平均住宅価格がどれだけ上昇するか (この場合は2870ドル) を示しています。
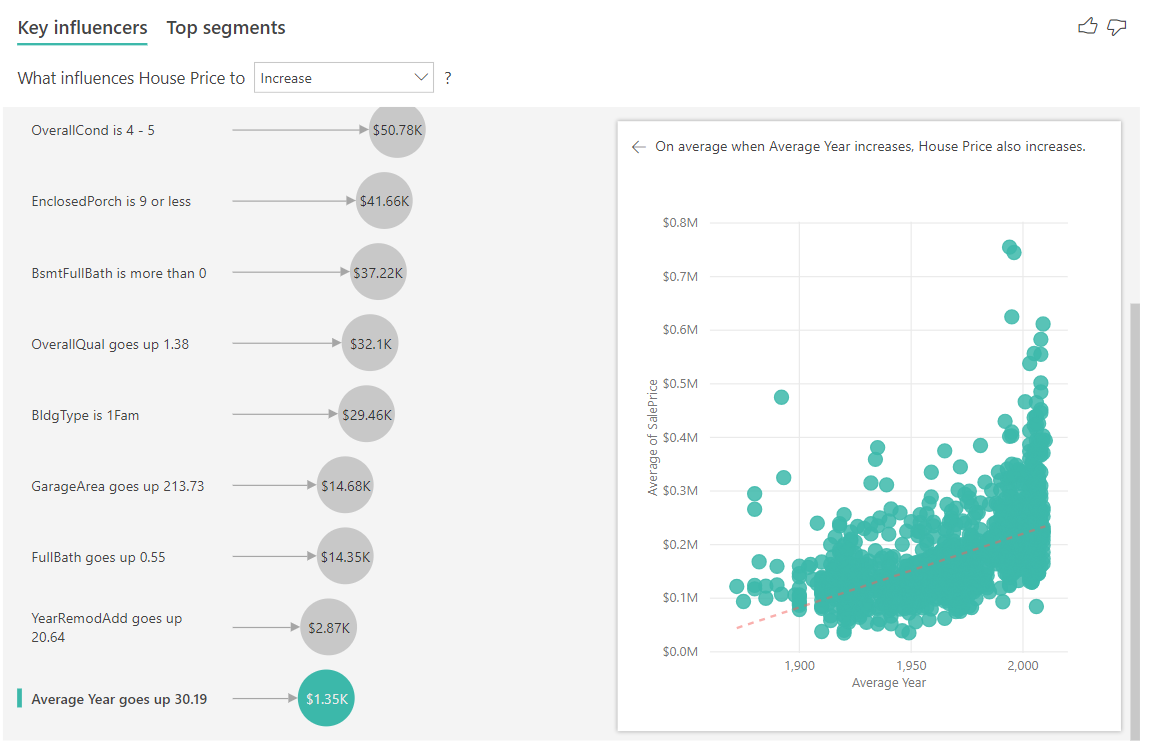
最後に、指標として、家が建築された平均的な年を調べます。 分析は次のとおりです。
- 右側ペインの散布図では、テーブル内の各値の平均住宅価格がプロットされます。
- バブルの値は、平均年が標準偏差 (この場合は 30 年) だけ増加したときに、平均住宅価格がどれだけ上昇したか (この場合は \$1.35K) によって示されます。
上位セグメントを使用して結果を解釈する
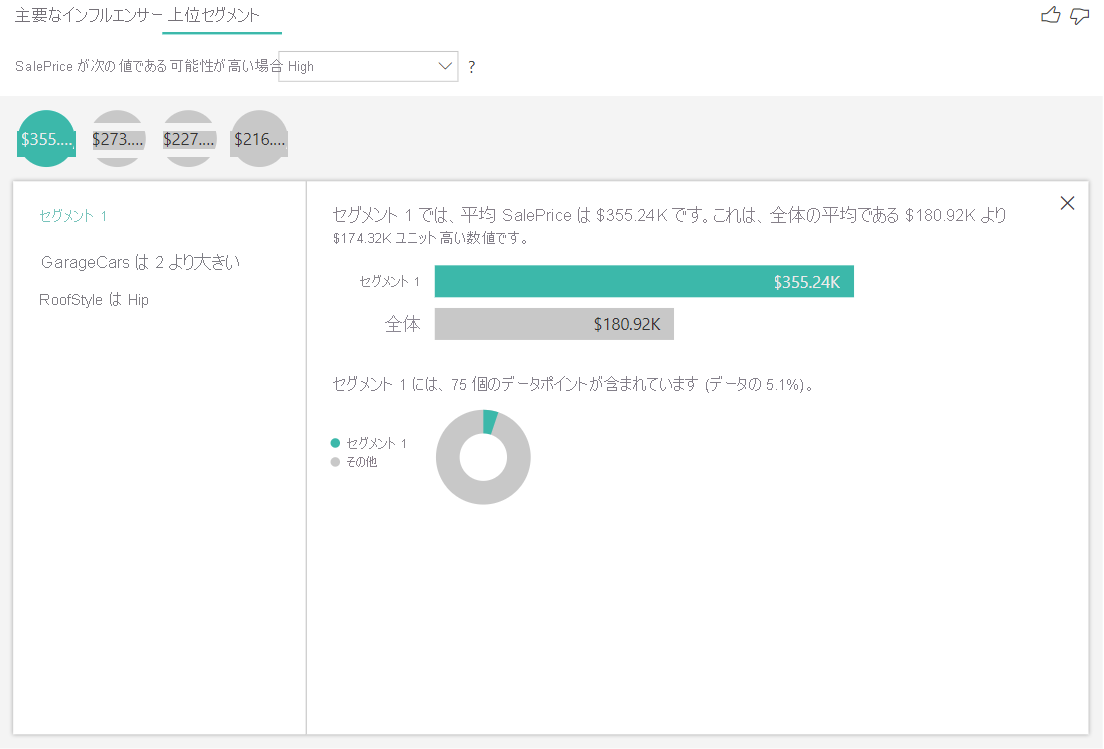
数値ターゲットの上位セグメントは、住宅価格の平均が全体のデータセット内よりも高いグループを示します。 たとえば、次では、Segment 1 は GarageCars (ガレージに収まる車の台数) が 2 より大きく、RoofStyle が隅棟である家で構成されていることがわかります。 これらの特性を持つ住宅の平均価格は、データ全体の平均 \$180,000 と比較して \$355K です。
メジャーまたは集計された列であるメトリックを分析する
メジャーまたは集計された列の場合、分析の既定値はこの記事で前に説明した継続的な分析タイプになります。 それを変更することはできません。 メジャーまたは集計された列の分析と、集計されていない数値列の分析の最大の違いは、分析が実行されるレベルです。
非正規化列の場合、分析は常にテーブル レベルで実行されます。 住宅価格の例では、 住宅価格 メトリックを分析して、住宅価格が増減に影響を与えるものを確認しました。 分析はテーブル レベルで自動的に実行されます。 テーブルには家ごとに一意の ID があるので、分析は家のレベルで実行されます。
メジャーと集計された列の場合は、分析レベルはすぐにはわかりません。 House Price が Average として集計されている場合は、この平均住宅価格計算のレベルを考慮する必要があります。 それは、近所レベルでの平均住宅価格でしょうか。 それとも、地域レベルでしょうか。
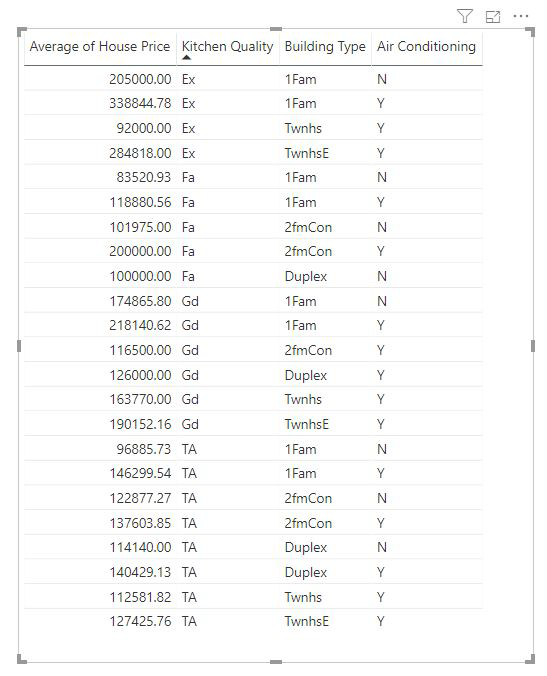
メジャーおよび集計された列は、使用されている Explain by フィールドのレベルで自動的に分析されます。 私たちは「Explain by」の 3 つのフィールド、キッチンの品質、建物の種類、エアコンを検討したいと考えています。 住宅価格の平均 は、これら 3 つのフィールドの一意の組み合わせごとに計算されます。 多くの場合、テーブル ビューに切り替えて、評価されるデータがどのように表示されるかを確認すると便利です。
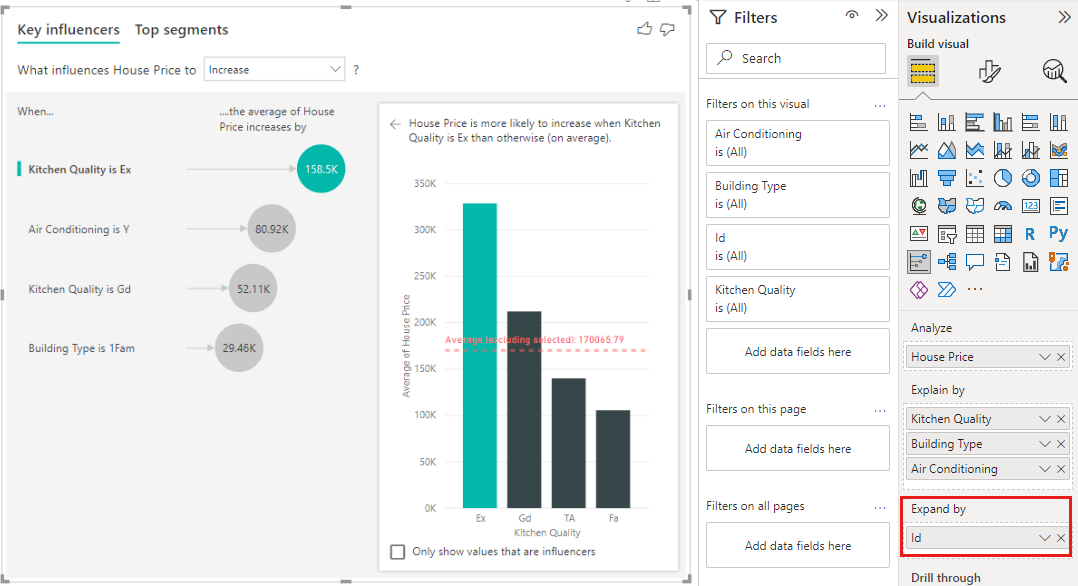
この分析は高度に要約されているため、回帰モデルが学習できるデータ内のパターンを見つけるのが難しい場合があります。 より良い結果を得るには、さらに詳細なレベルで分析を実行する必要があります。 住宅レベルで住宅価格を分析する場合は、[ID] フィールドを分析に明示的に追加する必要があります。 それでも、家の ID をインフルエンサーと考えたくはありません。 家の識別番号が高くなると、家の価格が上がるということを知っても役に立ちません。 フィールドウェルで拡張するオプションが便利です。 [展開] を使用すると、新しいインフルエンサーを探さずに、分析のレベルを設定するために使用するフィールドを追加できます。
ID を[展開条件]に追加すると、可視化がどのように見えるかを見てみましょう。 メジャーを評価するレベルを定義すると、インフルエンサーの解釈は、未集計の数値列の場合と同様です。
Power BI によりバックグラウンドで ML.NET を使用してどのようにデータが分析され、自然な方法で分析情報が表示されるかについては、「Power BI で ML.NET を使用して主要なインフルエンサーを特定する」を参照してください。
考慮事項とトラブルシューティング
視覚化の制限事項とは
主要なインフルエンサーの視覚化には、次のような制限があります。
- 直接クエリはサポートされていません。
- Azure Analysis Services と SQL Server Analysis Services へのライブ接続はサポートされていません。
- Web への発行はサポートされていません。
- .NET Framework 4.6 以降が必要です。
- SharePoint Online の埋め込みはサポートされていません。
- データ モデルに対して [暗黙のメジャーを推奨しない] が true に設定されている場合 (たとえば、計算グループがデータ モデルで定義されている場合)、カテゴリ変数のメトリックを分析することはサポートされていません。
インフルエンサーまたはセグメントが見つからないというエラーが表示されます。 なぜでしょうか。
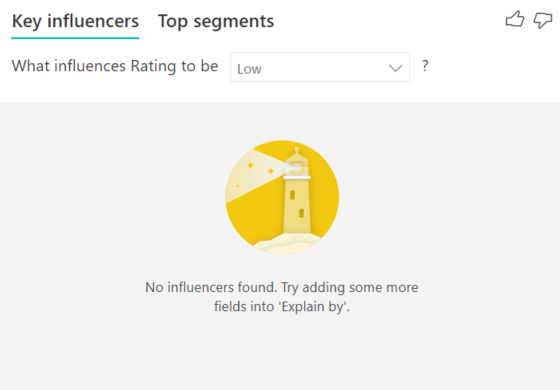
このエラーは、 [説明] にフィールドを含めたのに、インフルエンサーが見つからない場合に発生します。 次のいずれかの問題が適用される可能性があるかどうかを確認します。
- [分析] と [説明] の両方に分析していたメトリックを含めました。 それを [説明] から削除します。
- 説明フィールドに含まれる、観測値がほとんどないカテゴリが多すぎます。 この状況が、視覚化でどの要因がインフルエンサーかを特定するのを困難にしています。 わずかな観測値に基づいて一般化するのは困難です。 数値フィールドを分析する場合は、[分析] カードの [表示形式] ウィンドウでカテゴリ分析から連続分析に切り替えることができます。
- 説明要因には一般化するのに十分な数の観測値はありますが、視覚化では報告するための意味のある相関関係が見つかりませんでした。
分析対象のメトリックに分析を行うための十分なデータがないというエラーが表示されます。 なぜでしょうか。
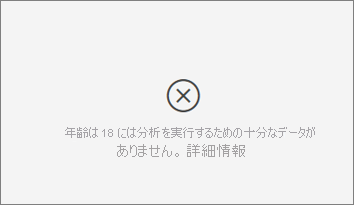
視覚化は、あるグループを他のグループと比較してデータ内のパターンを調べることで機能します。 たとえば、高評価を付けた顧客と比較して低評価を付けた顧客を検索します。 モデル内のデータの観測値が少ししかない場合は、パターンを見つけるのは困難です。 視覚化に意味のあるインフルエンサーを見つけるのに十分なデータがない場合、分析を行うにはさらにデータが必要であることが示されます。
選択した状態に対して少なくとも 100 個の観測値を持つことをお勧めします。 この場合、状態は解約する顧客です。 比較のために使用する状態にも、少なくとも 10 個の観測値が必要です。 この場合、比較の状態は、解約しない顧客です。
数値フィールドを分析する場合は、[分析] カードの [表示形式] ウィンドウでカテゴリ分析から連続分析に切り替えることができます。
"分析" が集計されていないときは、分析は常に親テーブルの行レベルで実行されるというエラーが表示されます。 'Expand by' フィールドでこのレベルを変更することは許可されていません。 なぜでしょうか。
数値列またはカテゴリ列を分析する場合、分析は常にテーブル レベルで実行されます。 たとえば、住宅価格を分析していて、テーブルに ID 列が含まれている場合、分析は住宅 ID レベルで自動的に実行されます。
メジャーまたは集計された列を分析するときは、分析を実行するレベルを明示的に指定する必要があります。 [展開] を使用すると、新しいインフルエンサーを追加せずに、測定値および集計列の分析レベルを変更できます。 住宅価格がメジャーとして定義されている場合は、[配置方法] に家の ID 列を追加して、分析のレベルを変更できます。
[説明] 内のフィールドが、分析対象のメトリックを含むテーブルに一意に関係していないというエラーが表示されます。 なぜでしょうか。
分析対象のフィールドのテーブル レベルで分析が行われます。 たとえば、サービスに対する顧客フィードバックを分析する場合、顧客が付けた評価が高いか低いかを示すテーブルがある場合があります。 この場合、顧客テーブルのレベルで分析が行われます。
関連テーブルがメトリックを含むテーブルよりも詳細なレベルで定義されている場合、このエラーが表示されます。 次に例を示します。
- 顧客がサービスを低く評価する要因を分析します。
- 顧客がサービスを利用しているデバイスが、その顧客によって与えられたレビューに影響するかどうかを確認したいと思っています。
- 顧客は複数の異なる方法でサービスを利用することができます。
- 次の例では、顧客 10000000 はブラウザーとテーブルの両方を使用して、サービスと対話しています。
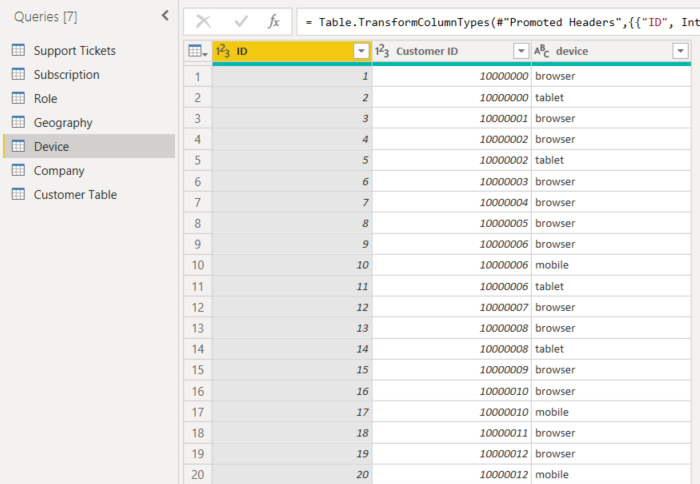
説明要因としてデバイス列を使用しようとすると、以下のエラーが表示されます。
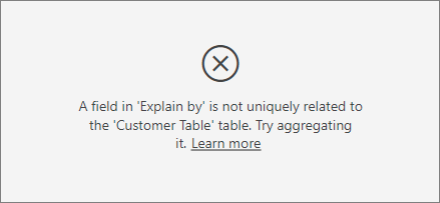
このエラーが表示されるのは、デバイスが顧客レベルで定義されていないためです。 1 人の顧客が複数のデバイス上でサービスを利用できます。 視覚化でパターンを見つける場合、デバイスが顧客の属性になる必要があります。 ビジネスの理解に応じて、いくつかのソリューションがあります。
- カウントするデバイスの概要作成を変更できます。 たとえば、デバイスの数がその顧客が付けるスコアに影響する可能性がある場合は、カウントを使用します。
- デバイス列をピボットすることで、特定のデバイス上でのサービスの利用が顧客の評価に影響するかどうかを確認できます。
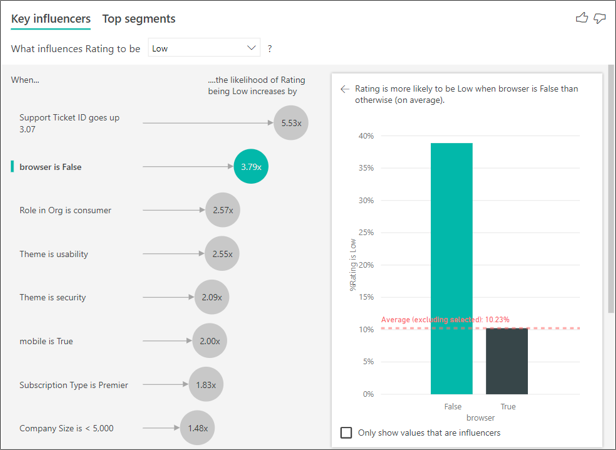
この例では、データは、ブラウザー、モバイル、およびタブレット用の新しい列を作成するためにピボットされました (データをピボットした後、モデリング ビューで関係を削除して再作成するようにしてください)。 これで [説明] でこれらの特定のデバイスが使えます。 すべてのデバイスがインフルエンサーで、ブラウザーが顧客スコアに最も大きな影響があることがわかりました。
より正確に言えば、サービスを利用するのにブラウザーを使用していない顧客は、使用している顧客より低いスコアを付ける可能性が 3.79 倍高くなります。 リストの下の方では、モバイルの場合は逆のことが当てはまります。 モバイル アプリを使用している顧客が、使用していない顧客より低いスコアを付ける可能性が高くなっています。
分析に測定値が含まれていないという警告が表示されます。 なぜでしょうか。
分析対象のフィールドのテーブル レベルで分析が行われます。 顧客離れを分析する場合、顧客が解約したかどうかが示されるテーブルがある場合があります。 この場合、顧客テーブルのレベルで分析が行われます。
既定では、メジャーと集計はテーブル レベルで既定で分析されます。 平均月間支出の指標があった場合、それは顧客テーブル レベルで分析されます。
顧客テーブルにユニーク識別子がない場合、測定値を評価できず、分析において無視されます。 このような状況を回避するために、メトリックを含むテーブルには一意の識別子があることを確認します。 この場合、対象となるのは顧客テーブルであり、一意の識別子は顧客IDです。 Power Query を使用してインデックス列を追加するのも簡単です。
分析対象のメトリックに 10 個を超える値があり、この量が分析の質に影響する可能性があるという警告が表示されます。 なぜでしょうか。
AI 視覚化では、カテゴリ別フィールドと数値フィールドを分析できます。 カテゴリ フィールドの場合、チャーンが [はい] または [いいえ] で、顧客満足度が [高]、[中]、または [低] の場合があります。 分析するカテゴリの数が増えると、カテゴリあたりの観測値が少なくなることを意味します。 このような状況では、視覚化でデータ内のパターンを見つけるのが難しくなります。
数値フィールドを分析する場合は、数値フィールドをテキストのように扱うオプションがあります。その場合は、カテゴリ データの場合と同じ分析を実行します (カテゴリ分析)。 多数の個別の値がある場合は、分析を 連続分析に切り替えるのが推奨されます。つまり、数値を個別の値として扱う代わりに、数値の増減からパターンを推測できるためです。 カテゴリ分析から連続分析に、分析カードの表示形式ペインで切り替えることができます。
より強力なインフルエンサーを見つけるために、類似する値を単一ユニットにグループ化することをお勧めします。 たとえば、価格のメトリックがある場合、類似する価格を高、中、低のカテゴリにグループ化する方が、個別の価格ポイントを使用するよりも良い結果が得られる可能性があります。
データに含まれる要因が主要なインフルエンサーのように見えますが、そうではありません。 どうしてこのようになるのですか。
次の例では、コンシューマーである顧客が、低評価の 14.93% を占めており、低評価の要因となっています。 また、管理者ロールは 13.42%で低評価の割合が高いですが、インフルエンサーとは見なされません。
この判断の理由は、視覚化ではインフルエンサーを見つけるときに、データ ポイントの数も考慮されるからです。 次の例では、29,000 人を超えるコンシューマーと、その 10 分の 1 の数の約 2,900 人の管理者がいます。 そのうちの 390 人だけが低い評価を付けました。 この視覚的表示には、管理者評価のパターンを発見したのか、それとも偶然の発見なのかを判断するための十分なデータがありません。
主要なインフルエンサーのデータ ポイント制限は何ですか?
10,000 のデータ ポイントのサンプルで分析を実行します。 一方の側のバブルには、見つかったすべてのインフルエンサーが表示されています。 他方の縦棒グラフと散布図は、これらのコア ビジュアルのサンプリング戦略に従います。
カテゴリ別の分析に対して主要なインフルエンサーをどのように計算しますか。
AI の視覚化では、バックグラウンドで ML.NET を使用してロジスティック回帰が実行され、主要なインフルエンサが計算されます。 ロジスティック回帰は、さまざまなグループを互いに比較する統計モデルです。
低評価の要因を確認する場合、ロジスティック回帰で、低いスコアを付けた顧客が高いスコアを付けた顧客とどう違うのかを確認します。 高、中、低のスコアのように複数のカテゴリがある場合、低い評価を付けた顧客と低い評価を付けなかった顧客との違いを調べます。 この場合、低いスコアを付けた顧客は、高いスコアまたはどちらともいえないスコアを付けた顧客とどのように違っているでしょうか。
ロジスティック回帰では、データ内のパターンを検索して、低く評価した顧客と、高く評価した顧客にどのような違いがあるのかを見つけます。 たとえば、より多くのサポート チケットを持っている顧客は、持っているサポート チケットの数が少ない、あるいはサポート チケットを持っていない顧客より、低評価の割合が高くなることがわかる場合があります。
ロジスティック回帰では、存在するデータポイントの数も考慮されます。 たとえば、管理者の役割を果たすお客様が負のスコアを比例的に増やしても、管理者が少数しかない場合、この要因は影響力があるとは見なされません。 パターンを推測するのに十分なデータ ポイントがないため、このように判断されました。 要因をインフルエンサーと見なすかどうかを判断するには、統計テスト (ワルド検定とも呼ばれます) を使用します。 視覚化では p 値 0.05 を使用して、しきい値を決定します。
数値の分析に対して主要なインフルエンサーをどのように計算しますか。
AI の視覚化では、バックグラウンドで ML.NET を使用して線形回帰が実行され、主要なインフルエンサーが計算されます。 線形回帰は、説明要因に基づいて、分析対象のフィールドの結果がどのように変化するかを調べる統計モデルです。
たとえば、住宅価格を分析している場合、線形回帰では、優れたキッチンが住宅価格に与える影響が見られます。 優れたキッチンがある家は、優れたキッチンがない家と比べて、一般的に住宅価格は低くなるまたは高くなるでしょうか。
線形回帰では、データ ポイントの数も考慮されます。 たとえば、テニス コートがある家の価格はより高くなりますが、テニス コートがある家は少ないため、この要因は影響力があるとは見なされません。 パターンを推測するのに十分なデータ ポイントがないため、このように判断されました。 要因をインフルエンサーと見なすかどうかを判断するには、統計テスト (ワルド検定とも呼ばれます) を使用します。 視覚化では p 値 0.05 を使用して、しきい値を決定します。
セグメントはどのように計算するのですか。
AI の視覚化では、バックグラウンドで ML.NET を使用してデシジョン ツリーが実行され、興味深いサブグループが発見されます。 デシジョン ツリーの目的は、最終的に、関心のあるメトリックで比較的高いデータ ポイントのサブグループを見つけることです。 これは、低い評価を付けた顧客や価格の高い家などが考えられます。
デシジョン ツリーでは各説明要因を使用し、最適な分割の要因の判断を試みます。 たとえば、データをフィルター処理して大企業の顧客のみを含める場合、高い評価を与えた顧客と低い評価を与えた顧客が分けられますか? または、セキュリティについてコメントした顧客のみを含むようにデータをフィルター処理することをお勧めします。
デシジョン ツリーは、分割後、データのサブグループを取得して、そのデータの次善の分割を決定します。 この場合、サブグループは、セキュリティについてコメントした顧客です。 各分割の後、デシジョンツリーは、このグループがパターンを推測するのに十分に代表的なデータポイントを持っているかどうかを考慮します。 そうでない場合は、実際のセグメントではなく、データ内の異常です。 p 値が 0.05 の分割条件の統計的有意性をチェックするために、別の統計検定が適用されます。
デシジョンツリーの処理が完了すると、セキュリティのコメントや大企業などのすべての分岐を利用して、Power BI のフィルターが生成されます。 このフィルターの組み合わせは、視覚エフェクトのセグメントとしてパッケージ化されます。
特定の要因がインフルエンサーになったり、インフルエンサーになるのをやめたりする理由は、私がより多くのフィールドを「Explain by」に移動するにつれて何ですか?
視覚化は、すべての説明要因をまとめて評価します。 要因はそれ自体がインフルエンサーかもしれませんが、他の要因と考えるとそうではない可能性があります。 たとえば、説明要因として寝室と家のサイズを使用して、住宅の価格を高くする要因を分析するとします。
- 寝室を増やすだけで、家屋の価格を高くする要因になる場合があります。
- 分析に家のサイズを含めると、家のサイズを一定のままで、寝室がどうなるかを調べることができます。
- 家のサイズが1,500平方フィートで固定されている場合、寝室の数が継続的に増加して住宅価格が劇的に上昇する可能性は低いです。
- 寝室は、家のサイズを考慮する前ほどには重要な要因ではないでしょう。
Power BI の同僚とレポートを共有するには、Fabric または Power BI Pro の個々のライセンスを持っているか、レポートが Premium 容量に保存されている必要があります。 レポートの共有に関するページをご覧ください。