分析に基づいて、統合を計画し、要件に最適なパターンを特定します。 次の統合パターンの一覧は完全ではありません。 これらのパターンの組み合わせがシナリオに最も適している場合があります。
各パターンは、特定のビジネス シナリオと技術的な制約に対処します。
- インスタント トリガー パターン: このパターンは、ユーザーがシステムと対話する方法を反映しています。 ユーザー主導のアクションは、定義済みの一連のアクションをトリガーします。
- イベント ドリブン パターン: このパターンには、特定のシステムで発生するイベントへの応答などの自動トリガーが必要です。
- データ統合パターン: このパターンは、さまざまなシステムにわたってデータの全体像を必要とする複数の管理システムを持つ組織にとって不可欠です。
- サービス指向アーキテクチャ パターン: 通常、このパターンには複数のシステム間のフローが含まれるので、複雑な環境でのモジュール式のスケーラブルな統合が可能になります。
- 同期パターン: このパターンでは、さまざまなデータベース間でデータの同期が維持され、パフォーマンスと規制の要件に対応します。
即時トリガーパターン
インスタント トリガー パターンは、ユーザー主導で直感的です。 ユーザーが Power App のボタンを押すなどのアクションを実行すると、統合フローが開始されます。 このパターンは、継続的ではなくオンデマンドでデータが必要なシナリオに最適です。
サンプル シナリオ
Power App を使用すると、製品マネージャーは顧客のフィードバックを確認し、アクション プランを作成できます。 一部の技術仕様は、Oracle の製品ライフサイクル管理システムに格納されます。 データセット全体を Dataverse にコピーする代わりに、必要に応じてデータをフェッチするボタンがアプリに含まれています。
ユーザーを Oracle にリダイレクトするのではなく、統合する理由は次のとおりです。
- ユーザー エクスペリエンスが低い
- セキュリティに関する懸念事項
- ライセンスコスト
Power Platform 統合のコスト効率を考えると、これらの理由のいずれかが実装を正当化する可能性があります。
フロー設計
アプリケーションでボタンを押すとトリガーされるインスタント クラウド フローを使用します。
次の図は、ユーザーが開始したアクションが外部システムからデータを取得して Dataverse に書き込むインスタント トリガー パターンを示しています。
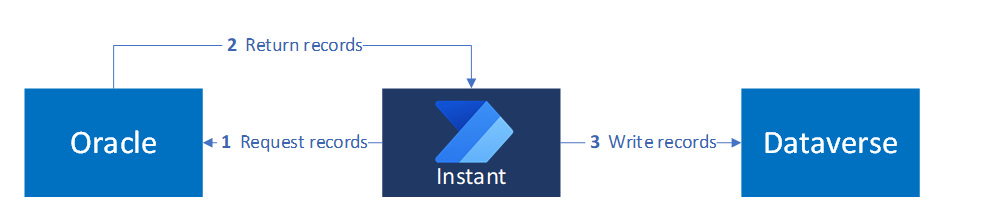
フローには、次の手順が含まれます。
- アプリによって提供されるパラメーター (製品 ID など) を使用して、Oracle からレコードを要求します。
- Oracle からアプリにレコードを返します。
- Dataverse にレコードを書き込みます。
その後、このデータは Power Apps インターフェイスに反映されます。
考慮 事項:
- Oracle と Dataverse の間のデータ モデルは異なる場合があり、変換手順が必要です。
- インスタント トリガーは、本当にインスタントではありません。 実行時間は、システムの可用性と変換の複雑さに依存します。
- アプリにビジュアル インジケーターを追加して進行状況を表示し、操作に時間がかかりすぎる場合はキャンセルを許可します。
- 大規模な組織では、多くのユーザーからの同時要求がシステムに負担をかける可能性があります。
- 統合は、さまざまな理由で失敗する可能性があります。 実行中にアプリがユーザーにフィードバックを提供していることを確認します。 ユーザーがボタンを選択し、応答を受け取らないようにするシナリオは避けてください。その結果、ユーザー エクスペリエンスが低下します。
イベント駆動パターン
イベント ドリブン (自動トリガーとも呼ばれます) アーキテクチャは、ユーザーが直接操作することなく、システムの変更に応答します。 たとえば、Dataverse で作成されたレコード、受信メール、OneDrive に追加されたファイル、その他の任意の数のイベントに応答するようにトリガーを構成できます。 このパターンは直感的でスケーラブルであり、システム イベントに基づくビジネス プロセスの自動化に最適です。
サンプル シナリオ
顧客サービス部門は、Dataverse に接続されたアプリを使用してケースに対応し、手動で電子メールを作成することなく、顧客に自動的に更新を提供します。 通知をトリガーする必要があるのは、メモの追加や状態の変更など、特定の変更だけです。
Power Automate で自動トリガーを使用して、これらのイベントに応答します。 フローは、Dataverse レコードの変更をリッスンし、定義された条件が満たされたときに通知を送信します。
この図は、Dataverse の変更によって、関連するケース情報で顧客を更新するダウンストリーム アクションを自動的に開始する自動トリガー パターンを示しています。
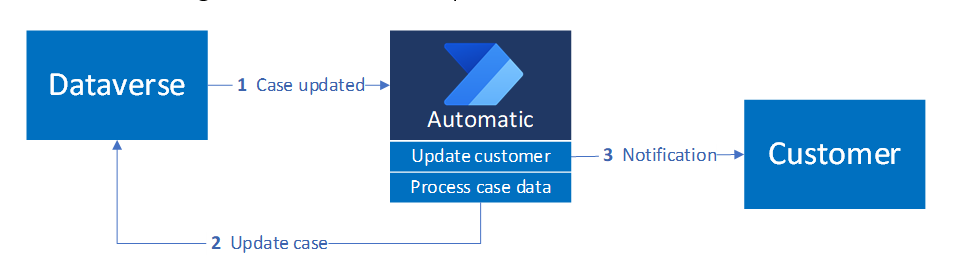
トリガーの構成
次のようにフローを構成します。
- 監視する 変更の種類 を指定します。
- [列の選択] パラメーターを使用して応答する 列 を定義します。
- [Filter Rows]\(行のフィルター\) パラメーターを使用して、顧客向けの状態の変更のみがフローをトリガーし、その他のろ過要件がトリガーされるようにします。
If アクションを使用して、フロー自体にこのロジックを実装しないでください。 トリガー パラメーターを使用して、不要な実行を減らし、パフォーマンスを向上させます。
論理的な競合を回避する
意図しない動作を防ぐためにイベント ロジックを評価します。
- イベントが同じイベントをリトリガーするアクションをトリガーするループを回避します。
- 複数の更新によって迅速な繰り返し通知が発生しないようにします。
- エッジ ケースを処理し、過剰な実行を避けるためにフローを設計します。
ボリュームと頻度に関する考慮事項
トリガーされるイベントの予想される量について理解します。 通知サービス (電子メール、SMS など) では、特定の期間に送信できるメッセージの数が制限されます。
- 1 日または 1 か月あたりのイベント数を見積もります。
- スロットリングまたはレート制限メカニズムを実装します。
- イベント頻度の予期しない急増に対する軽減計画を準備します。
データ統合パターン
データ統合 (スケジュールされたトリガーとも呼ばれます) は、組織が複数のシステム間で情報を統合し、レポートと運用プロセスをサポートするのに役立ちます。 多くの場合、分析には完全なデータセットが必要ですが、運用上のユース ケースでは、ビジネス タスクを完了するために必要なデータのみを取得することに重点を置きます。
サンプル シナリオ
ある会社では、3つのレガシーシステムを使用して主要なビジネス機能を管理しています。SAPは注文と売掛金、Oracleは製品在庫、IBMは顧客関連のコンテンツ管理に使用されています。 組織は、AI を使用して履歴データに基づいて各顧客の次に最適なアクションを予測する新しい Power Platform アプリを委託しました。 アプリでは、3 つのシステムすべてから関連情報を収集し、営業マネージャーがエンゲージメントを導く販売アクション プランを生成する必要があります。
統合アプローチ
統合には、リアルタイムの更新やイベント ドリブン トリガーは必要ありません。 代わりに、営業スタッフが顧客と対話する頻度に基づいて、スケジュールされたプロセスを使用します。
このユース ケースでは、スケジュールされたトリガーによって次のようにデータが統合されます。
- 各システムから必要なデータのみを要求する
- Dataverse と互換性のある形式でデータを返します。
- 分析のために AI モデルにデータをアップロードします
この図は、定期的なプロセスが複数のシステムから情報を収集し、結合されたデータセットを Dataverse にアップロードする、スケジュールされたデータ統合パターンを示しています。
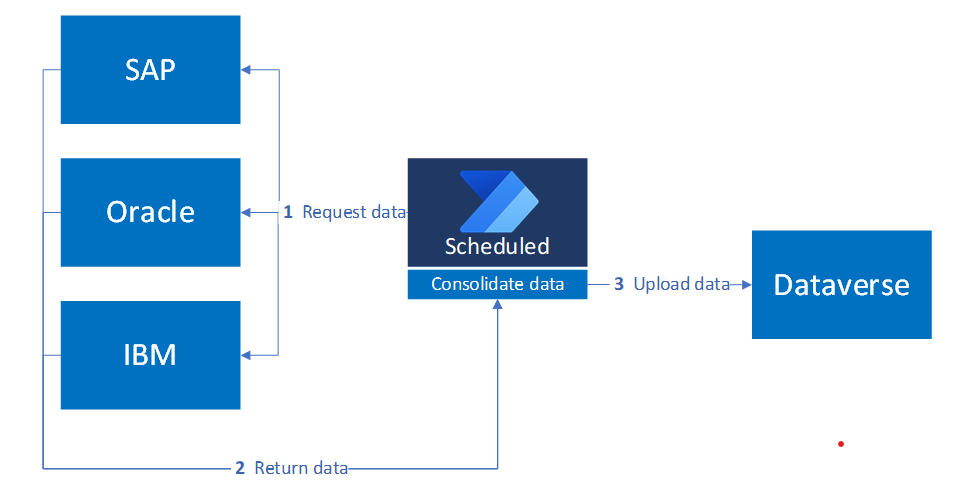
スケジュールされたトリガー構成
スケジュールされたトリガーは、1 秒あたり 1 回から年に 1 回まで、柔軟な繰り返しオプションを提供します。 タイミングは予測可能ですが、データ スコープが拡大したり、増加が予想を超えたりすると、ボリュームが予測できなくなる可能性があります。
- フローの実行時間を監視して、重複や遅延を回避する
- パフォーマンスの低下を防ぐためのセーフガードを実装する
- Application Insights または同様のツールを使用して、フローが一貫して実行されるようにする
リスク軽減策
スケジュールされたフローに予想以上の時間がかかる場合は、ビジネス プロセスが中断される可能性があります。 たとえば、10 分ごとに実行するように設計されたフローは、完了に 10 分以上かかると失敗することがあります。
- ランタイムを監視し、異常のアラートを設定する
- データ量の増加に応じてスケーラビリティを計画する
- 目に見えない障害を防ぐために、フローの正常性を確実に可視化する
サービス指向の統合パターン
大規模な組織では、多くの場合、部門間で複数のシステムを運用しています。 これらのシステムは、ビジネス プロセスを完了するために相互に依存するように進化します。 統合層はこれらのシステムをブリッジし、システム間通信を可能にしながら、それぞれがコア機能を実行できるようにします。
シナリオ例の再検討
組織が複数のシステムを使用してビジネスのさまざまな部分を管理するシナリオの例を続けてみましょう。 SAP は注文と売掛金を処理し、Oracle は製品在庫を管理し、IBM は内部財務ドキュメントを保存します。 Dataverse は、販売、顧客サービス、製品管理用のアプリを実行します。 SharePoint は内部コラボレーションとナレッジ ベース管理をサポートし、Maersk API は物流プロセスを自動化します。
この図は、さまざまなエンタープライズ システム間の更新によって、それらの間のデータとアクションを調整する自動化されたフローをトリガーする、マルチシステム ランドスケープのイベント ドリブン パターンを示しています。
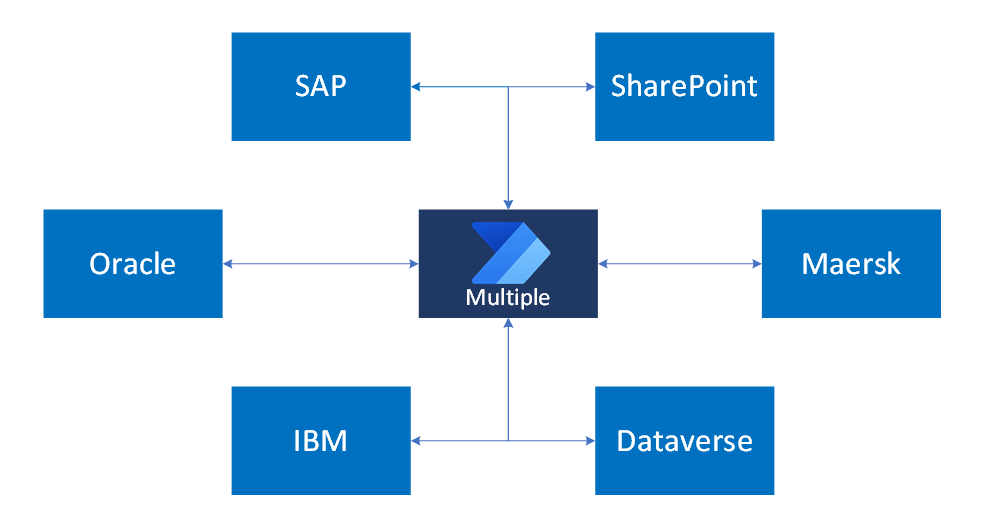
各システムは、スケジュールされたイベントまたは手動のユーザー アクションを使用して他のユーザーと対話します。 すべてのユース ケースに対応するフローは 1 つもありません。 代わりに、ソリューションには、特定のトリガーとビジネス プロセスに合わせた複数のフローが必要です。
モノリシック フローを回避する
すべての統合を処理するために 1 つの大きなフローを作成することは実用的ではありません。 パフォーマンス、セキュリティ、メンテナンスの課題が導入されています。 代替案:
- トリガーとプロセスごとにモジュール式フローを構築する
- 特定のユース ケースに合わせてフローを最適化する
- 管理可能なコンポーネントを使用して統合ランドスケープをスケーリングする
システム間プロセスを最適化する
必要に応じてロジックを統合する機会を探します。 たとえば、SharePoint のドキュメントを同じイベント中に SAP と Oracle の両方に送信する必要がある場合、ファイルを 1 回読み取って両方のシステムに書き込むフローを 1 つ作成したくなる場合があります。 ただし、最初に、作成するロジックが厳密すぎるかどうかを検討します。 大規模な環境では、システム間でのビジネス プロセスの動作に対する変更は、それらのシステムに対する変更と同じくらい頻繁に行われます。
過剰な統合は避けてください。 ビジネス プロセスとシステム構成は頻繁に変更されます。 厳格で一元化されたロジックにより、柔軟性が低下し、メンテナンスのオーバーヘッドが増加します。
次の設計フロー:
- モジュール式で保守可能
- 部門とシステム全体でスケーラブル
- ビジネス ロジックとシステム動作の変化に対する回復力
このパターンは、明確に定義された目的で構築されたフローを通じてシステムが相互接続されるサービス指向アーキテクチャ (ユーモラスな "スパゲッティ アーキテクチャ" とも呼ばれます) になります。
データ同期パターン
同じシステムが別々のデータベースにデータを格納する場合は、データ同期を使用します。 同じデータを 2 回格納すると非効率的に見えるかもしれませんが、このパターンは、パフォーマンスや規制コンプライアンスなどの特定のビジネス ニーズをサポートします。
- パフォーマンス: ローカル データ アクセスにより、特に待機時間の影響を受けやすい業界での応答性が向上します。
- コンプライアンス: 法的規制では、国境内にデータを格納する必要がある場合があります。 組織では、多くの場合、これらの要件を満たすために、同期プロセスを使用してローカル インスタンスをデプロイします。
サンプル シナリオ
ある医療機器会社は、地域の医療機関と協力して、ヨーロッパの複数の地域で事業を展開しています。 医療データに関する各リージョンの法律は明確であり、そのリージョンの境界内に格納する必要があります。 注文、製品、出荷に関する情報は、国境を越えて保存できます。 規制要件に対処するために、会社は各リージョンに Power Platform 顧客管理アプリと Dataverse のインスタンスを作成しました。
販売業務をサポートするために、会社はすべてのインスタンスにわたって、連絡先の詳細、注文、出荷などの非センシティブ なデータを同期することを希望しています。 医療データは同期から除外されます。
統合アプローチ
アカウント レコードの更新によってトリガーされる自動クラウド フローを使用します。 次のようにフィルターを構成します。
- 許可されているフィールドのみを監視する
- 制限付きデータの同期を防止する
このアプローチにより、コンプライアンスと運用効率をサポートするイベント ドリブンのターゲット統合が実現されます。
次の図は、イベント ドリブンの同期パターンを示しています。このパターンでは、ある Dataverse 環境の更新によって、対応する更新が別の Dataverse 環境で自動的にトリガーされます。
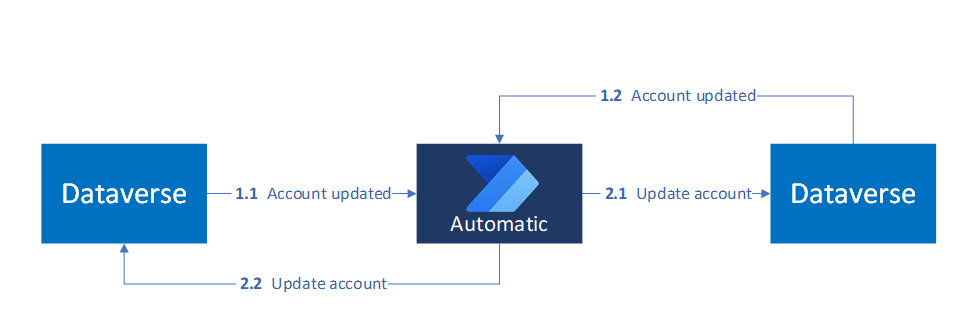
応答時間の期待値
同期速度に対する現実的な期待値を設定します。 Power Automate は非同期であり、リアルタイムのパフォーマンスを保証するものではありません。 ビジネス ユーザーがすぐにデータを利用できる場合は、設計プロセスの早い段階で制限事項を明確にしてください。
- Power Automate がパフォーマンスニーズを満たしているかどうかを評価する
- ビジネス要件で正当な理由がない限り、リアルタイム アクセスのための過剰エンジニアリングを回避する
リアルタイム アクセスに対する多くの要求には、強力なビジネス ケースがありません。 統合設計では、明確さ、スケーラビリティ、保守性に優先順位を付けます。
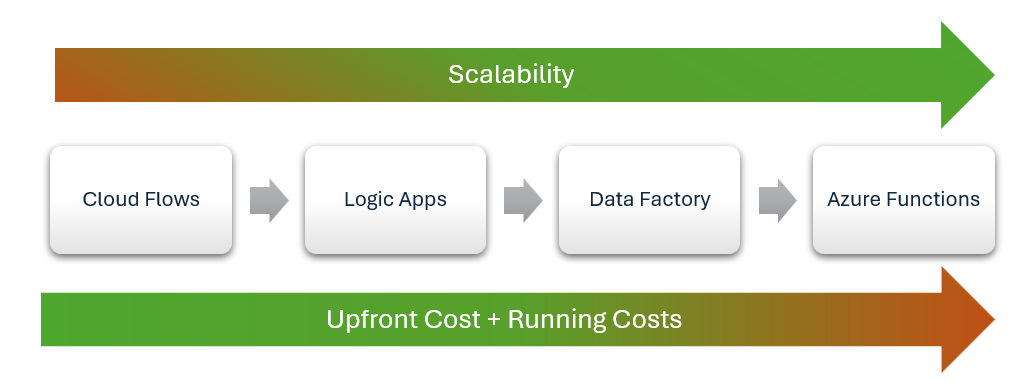
クラウド フロー以上
統合ツールを選択する場合は、既定のオプションとして Power Automate から始めます。 開発とメンテナンスの両方に比類のないコスト効率を提供します。
Power Automate は、次のような多くのシナリオで推奨される統合ツールです。
- ローコード コネクタを使用して迅速な開発を実現
- 長期的なメンテナンス コストを最小限に抑える
- 幅広いトリガーとシステムをサポート
- ほとんどのビジネス シナリオに適したスケーリング
カスタム コード、Azure Functions、Data Factory、または Service Bus を使用すると、制御が強化されたり、パフォーマンスが向上したりする場合がありますが、複雑さとコストが増えます。 これらのオプションは、Power Automate がビジネスまたは技術的なニーズを満たしていない場合にのみ使用します。
サンプル シナリオ
オンラインバンキングサービスは、顧客にローンの資格を迅速に与えたいと考えています。 修飾プロセスには、最終的なリスク スコアを得るために、複雑な計算と複数のシステムからのデータ取得が含まれます。 最初の評価の後、銀行サービスは、計算の複雑さを考慮して、クラウド フローを不適切と見なしました。
ただし、この場合はハイブリッドアプローチが答えです。
- 組み込みのコネクタを使用してデータ収集を処理する Power Automate
- Azure 関数として実行されるカスタム コードにカプセル化された複雑な計算。個別にスケーリングすることも、カスタム コネクタで実行することもできます。
このハイブリッド アプローチは、パフォーマンス、スケーラビリティ、コストのバランスを取ります。
統合戦略
単独でツールを選択しないでください。 代わりに、その長所を組み合わせます。 例えば次が挙げられます。
- オーケストレーションと接続に Power Automate を使用する
- コンピューティング集中型タスクに Azure Functions を使用する
- カスタム コネクタを使用して必要に応じ機能を拡張する
すべての統合の決定では、総保有コストを考慮する必要があります。 カスタム ソリューションは強力に見えるかもしれませんが、多くの場合、開発、ライセンス、サポートのためのより大きな予算が必要になります。 明確なビジネス価値で高いコストを正当化します。