複数の社内システムから Microsoft Fabric Lakehouse の単一ソースにデータを収集し、Dataverse の仮想テーブルを使用して Power Platform アプリやフローで統合データを利用します。
チップ
この記事では、Microsoft Dataverse の仮想テーブルを使用してソリューションに Microsoft Fabric Lakehouseデータを統合する方法を、シナリオ例と一般的なアーキテクチャ例で説明します。 アーキテクチャの例は、さまざまなシナリオや業界に合わせて変更できます。
アーキテクチャ ダイアグラム
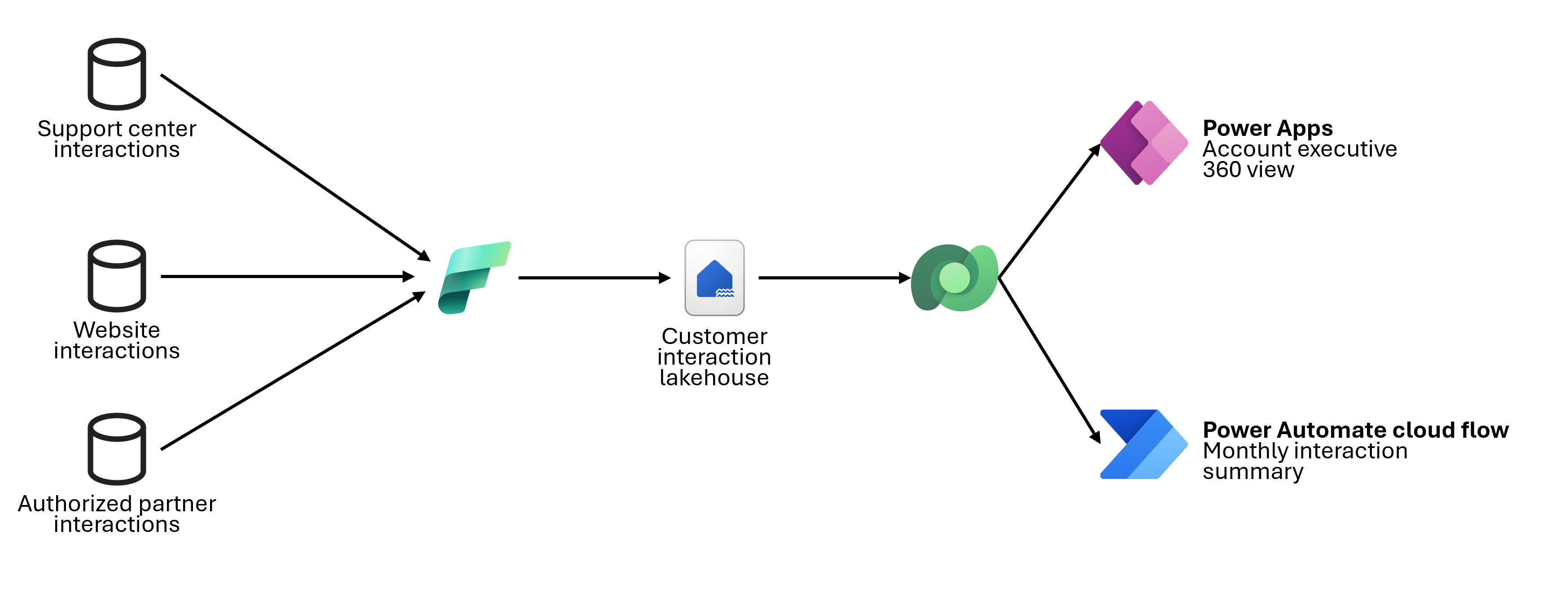
Workflow
次の手順では、アーキテクチャ図の例に示されているワークフローについて説明します。
ソースの準備: データフローは、組織全体から利用可能なデータソースを特定します。そして、このデータを Fabric Lakehouse にプッシュし、ETL オペレーションがそれを抽出し、さらに使用するために変換します。
仮想テーブル: Fabric 仮想コネクタ プロバイダーは、Fabric Lakehouse 内のデータを表す仮想テーブルを作成します。
アカウント エグゼクティブ 360 ビュー: キャンバスまたはモデル駆動型アプリは、ユーザー フレンドリーなインターフェイスで仮想テーブルのデータを表示し、アカウント エグゼクティブが取引先企業とのすべてのやり取りをすばやく表示できるようにします。
アカウント エグゼクティブの月次対話サマリー: スケジュールされた Power Automate フローが毎月実行され、同じ仮想テーブルのデータに基づいて、各アカウント エグゼクティブの顧客とのやりとりのサマリーが生成されます。
コンポーネント
Power Platform 環境: ユーザー エクスペリエンスを実装する Power Platform のリソースが含まれます。 Fabric Lakehouse のデータに接続する仮想テーブルは、関連する Dataverse インスタンスの Power Platform 環境で作成されます。
Microsoft Fabric: 組織全体から構造化データおよび非構造化データを取り込み、変換し、保存します。 Power Platform 環境と同様に、Fabric はワークスペースというコンセプトを使用して、ソリューションで使用する Lakehouse、データ フロー、その他の Fabric リソースのコンテナを作成します。
仮想コネクタ プロバイダー: 仮想テーブルの作成を効率化します。 仮想テーブルは、データを複製することなく、外部ソースから統合されたデータを Microsoft Dataverse のテーブルとして表します。 データ ソースごとに、データ プロバイダが Dataverse とソース間の対話を処理し、仮想テーブルの動作を定義する必要があります。 ファブリック レイクハウス データの仮想テーブルを作成する場合、事前構築済みのファブリック仮想コネクタ プロバイダーがデータ プロバイダーになります。 このアプローチでは、一般的な Power Platform 接続と接続参照を使用して、Fabric ワークスペースと Power Platform 環境の仕様を管理します。これにより、作成者は複数のシステムで作業する複雑性に煩わされずにアプリを構築することができます。

Power Apps: ソリューションのユーザー エクスペリエンスを実装します。 作成者は、Fabric データを表す仮想テーブルを使用して、他の Dataverse テーブルと同様にデータ ソースとして追加し、キャンバスまたはモデル駆動型アプリを構築できます。
Power Automate: 月次サマリーの作成を自動化します。 フローは毎月実行するようにスケジュールでき、アプリと同じ仮想テーブルを使用できます。 フローは、レコードの作成時や更新時など、Fabric レイクハウス データのイベントによってトリガーすることもできます。
Power BI: Fabric レイクハウス のデータを視覚化します。 Power BI は Fabric Lakehouse に直接、または仮想テーブルを介して接続することができ、Fabric Lakehouse や他の Dataverse テーブルを含む複数のソースからのデータを組み合わせたレポートやダッシュボードを作成することができます。
シナリオの詳細
組織では、データがサイロに保存されている可能性があります。 このアーキテクチャ パターンを使用して、データ ストリームを所定の位置に保ちながら、Power Platform が Dataverse の仮想テーブルとして利用できるようにします。
潜在的なユース ケース
この例では、複数の内部システムからの顧客 対話 データが Fabric に一元化されています。 「Customer 360」アプリを使用すると、アカウントエグゼクティブは組織と顧客とのやり取りをすべて完全に把握できます。 アプリは仮想テーブルを使用して Fabric レイクハウス のデータにアクセスするため、アカウント エグゼクティブは、データがどこから来たのか、どのように変換されたのかを知ることなく、データを表示および分析できます。
その他の一般的な使用例を次に示します。
- Dynamics 365 または Dataverse の財務データと他のシステムの財務データを組み合わせて、統合された分析情報を導き出します。
- 従来のシステムから OneLake に取り込んだ履歴データを、Dynamics 365 および Dataverse からの現在のビジネス データとマージします。
- Web サイトからの Web ログおよびテレメトリ データを、Dynamics 365 からの製品および注文詳細と組み合わせます。
- 機械学習を適用し、データの異常や例外を検出します。
考慮事項
これらの考慮事項は、ワークロードの品質を向上させる一連の基本原則である Power Platform Well-Architected の柱を実行します。 詳細については、Microsoft Power Platform Well-Architected を参照してください。
信頼性
- 回復力を考慮した設計: ソリューションの Power Apps と Power Automate コンポーネントは、Fabric Lakehouse のデータのみに依存することで耐エラー性を高めているため、内部システムの影響を直接受けることはありません。
セキュリティ
機密性を保護する設計: 仮想テーブルは組織が所有します。 行レベルやフィールド レベルの Dataverse セキュリティの概念はサポートしていません。 仮想テーブル内のデータの機密性を評価し、外部データ ソースに対して独自のセキュリティ モデルを実装する必要があるかどうかを検討します。
アプリケーション シークレットの保護: Fabric の仮想コネクタ プロバイダーによって作成される仮想テーブルは、コネクタとコネクタ参照を使用して、Fabric Lakehouse にアクセスするための認証情報を管理し、保護します。
パフォーマンス効率
- データ使用量の最適化: Fabric Lakehouse からソリューションを構築すると、Power Platform コンポーネントで使用するデータを簡単に最適化ことができます。 例えば、アカウントエグゼクティブが対話の詳細に目を通す必要はなく、FabricのETL運用は、より洞察力のある、より理解しやすいデータに変換することができます。
エクスペリエンスの最適化
- 一貫性のある情報アーキテクチャを実装する: 複数のシステムから取得されるデータには、多くの場合一貫性のないメタデータが含まれます。 たとえば、あるシステムは対話を 「成功 」とマークする場合もありますが、別のシステムでは 「完了 」と保存される場合もあるでしょう。このような一貫性のないデータをユーザーに提示するアプリは、質の低いエクスペリエンスを提供する可能性があります。 インジェスト プロセス中に、データフローを使用してデータを統合および調整し、ユーザーに一貫したエクスペリエンスを提供します。
投稿者
Microsoft がこの記事を管理しています。 この記事を書いたのは、以下の寄稿者です。
作者代表:
- Ravi Chada、プリンシパル プログラム マネージャー
次の手順
Microsoft Fabric の分析情報を活用して、アプリと自動化を構築してアクションを実行する方法を確認します。
仮想テーブルを使用して Microsoft Fabric からデータにアクセスするソリューション アーキテクチャを設定するには、以下のハイレベルな手順に従ってください:
データを取り込む Lakehouse を含む Fabric ワークスペースを作成します。
Fabric レイクハウスの 1 つ以上のテーブルに仮想テーブルを作成します。
キャンバス アプリ、またはモデル駆動型アプリを作成する Microsoft Dataverse に接続し、アプリのデータソースとして仮想テーブルを追加します。