注
現在、Power Platform のデータフローではプライバシー レベルを利用できませんが、製品チームはこの機能の有効化に向けて取り組んでいます。
Power Query を使用した時間が長い場合は、発生した可能性があります。 突然、オンライン検索やクエリの調整、キーボードを叩くことでは解決できないエラーが発生する瞬間があります。 次のようなエラーが表示されます。
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
または、次の場合があります。
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
これらの Formula.Firewall エラーは、Power Query のデータ プライバシー ファイアウォール (ファイアウォールとも呼ばれます) の結果です。これは、世界中のデータ アナリストを不満にさせるためだけに存在しているように見える場合があります。 ただし、ファイアウォールは重要な目的を果たします。 この記事では、そのしくみをより深く理解するために、内部を掘り下げます。 より深い理解を持って、将来的にファイアウォールエラーの診断と修正を改善できることを願っています。
紹介
データ プライバシー ファイアウォールの目的は単純です。Power Query がソース間で意図せずにデータを漏えいするのを防ぐために存在します。
なぜこれが必要なのですか? つまり、SQL 値を OData フィードに渡す M を確実に作成できます。 しかし、これは意図的なデータ漏洩です。 マッシュアップの著者は、彼らがこれをやっていることを知っている(または少なくともそうする必要があります)。 なぜ意図しないデータ漏えいに対する保護が必要なのでしょうか。
答えは? 折りたたみ。
折りたたみ?
フォールディング は、M の式 (フィルター、名前の変更、結合など) を生データ ソース (SQL、OData など) に対する操作に変換することを指す用語です。 Power Query の機能の大きな部分は、ユーザーがユーザー インターフェイスを介して実行する操作を、ユーザーが知らなくても複雑な SQL またはその他のバックエンド データ ソース言語に変換できることにあります。 ユーザーは、すべてのデータ ソースを共通のコマンド セットを使用して変換できる UI を使いやすくすることで、ネイティブ データ ソース操作のパフォーマンス上の利点を得ることができます。
折りたたみの一環として、Power Query は、特定のマッシュアップを実行する最も効率的な方法は、あるソースからデータを取得して別のソースに渡すことであると判断することがあります。 たとえば、小さな CSV ファイルを巨大な SQL テーブルに結合する場合、Power Query で CSV ファイルの読み取り、SQL テーブル全体の読み取り、ローカル コンピューターでの結合を行いたくない可能性があります。 おそらく、Power Query で CSV データを SQL ステートメントにインライン化し、SQL データベースに結合を実行するように依頼する必要があります。
これは、意図しないデータ漏えいが発生する可能性がある方法です。
従業員の社会保障番号を含む SQL データを外部の OData フィードの結果と結合していて、SQL の社会保障番号が OData サービスに送信されていることを突然発見したとします。 悪いニュースですね?
これは、ファイアウォールが防ぐことを目的としたシナリオの一種です。
それはどのように動作しますか?
ファイアウォールは、あるソースのデータが誤って別のソースに送信されないようにするために存在します。 十分にシンプルです。
では、このミッションはどのように達成されるのでしょうか。
これを行うには、M クエリをパーティションと呼ばれるものに分割し、次の規則を適用します。
- パーティションは、互換性のあるデータ ソースにアクセスするか、他のパーティションを参照する可能性がありますが、両方を参照することはできません。
簡単。。。まだ混乱しています。 パーティションとは 2 つのデータ ソースを "互換性" にする理由 また、パーティションがデータ ソースにアクセスしてパーティションを参照する必要がある場合に、ファイアウォールで注意する必要があるのはなぜですか。
これを分解し、前のルールを一度に 1 つずつ見てみましょう。
パーティションとは
最も基本的なレベルでは、パーティションは 1 つ以上のクエリ ステップのコレクションにすぎません。 可能な限り最も細かいパーティション (少なくとも現在の実装) は 1 つのステップです。 最大のパーティションには、複数のクエリが含まれる場合があります。 (これについては後で詳しく説明します)。
手順に慣れていない場合は、[ 適用 されたステップ] ウィンドウでクエリを選択した後、Power Query エディター ウィンドウの右側に表示できます。 手順では、データを最終的な形に変換するために行うすべての操作を追跡します。
他のパーティションを参照するパーティション
ファイアウォールをオンにしてクエリが評価されると、ファイアウォールはクエリとそのすべての依存関係をパーティション (つまり、ステップのグループ) に分割します。 あるパーティションが別のパーティション内の何かを参照するたびに、ファイアウォールは参照を Value.Firewall という特殊な関数の呼び出しに置き換えます。 言い換えると、ファイアウォールでは、パーティションが相互に直接アクセスすることはできません。 すべての参照は、ファイアウォールを通過するように変更されます。 ファイアウォールをゲートキーパーと考えてください。 別のパーティションを参照するパーティションは、これを行うファイアウォールのアクセス許可を取得する必要があります。ファイアウォールは、参照されるデータをパーティションに許可するかどうかを制御します。
これはすべてかなり抽象的に見えるかもしれませんので、例を見てみましょう。
Employees というクエリがあり、SQL データベースからデータをプルするとします。 また、Employees を参照する別のクエリ (EmployeesReference) もあるとします。
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Employees
in
Source;
これらのクエリは最終的に 2 つのパーティションに分割されます。1 つは Employees クエリ用、1 つは EmployeesReference クエリ用です (Employees パーティションを参照)。 ファイアウォールをオンにして評価すると、これらのクエリは次のように書き換えられます。
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Value.Firewall("Section1/Employees")
in
Source;
Employees クエリへの単純な参照が、Employees クエリの完全な名前を指定した Value.Firewallの呼び出しに置き換えられていることに注意してください。
EmployeesReference が評価されると、ファイアウォールは Value.Firewall("Section1/Employees")への呼び出しをインターセプトします。これにより、要求されたデータが EmployeesReference パーティションに流れるかどうかを制御する機会が得られます。 要求の拒否、要求されたデータのバッファー (元のデータ ソースへのそれ以上の折りたたみの発生を防ぐ) など、任意の数の処理を実行できます。
これは、ファイアウォールがパーティション間を流れるデータを制御する方法です。
データ ソースに直接アクセスするパーティション
たとえば、クエリ Query1 を 1 つのステップで定義するとします (この単一ステップのクエリは 1 つのファイアウォール パーティションに対応し、この 1 つの手順では SQL データベース テーブルと CSV ファイルの 2 つのデータ ソースにアクセスします)。 パーティション参照がなく、それを検出するためのValue.Firewallへの呼び出しもない中で、ファイアウォールはどのように対応するのですか? 前に説明したルールを確認してみましょう。
- パーティションは、互換性のあるデータ ソースにアクセスすることも、他のパーティションを参照することもできますが、両方を参照することはできません。
単一パーティションと 2 つのデータ ソースのクエリの実行を許可するには、その 2 つのデータ ソースに "互換性がある" 必要があります。言い換えると、データを双方向に共有できる必要があります。 これは、両方のソースのプライバシー レベルがパブリックであるか、両方とも組織である必要があることを意味します。これは、両方向で共有できる唯一の 2 つの組み合わせであるためです。 両方のソースがプライベートとしてマークされている場合、または 1 つがパブリックとしてマークされ、1 つが組織としてマークされている場合、または他のプライバシー レベルの組み合わせを使用してマークされている場合、双方向の共有は許可されません。 どちらも同じパーティションで評価しても安全ではありません。 そうすることで、安全でないデータ漏えいが (折りたたみのために) 発生する可能性があり、ファイアウォールはそれを防ぐ方法がありません。
同じパーティション内の互換性のないデータ ソースにアクセスしようとするとどうなりますか?
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
この記事の冒頭に一覧表示されているエラー メッセージの 1 つについて理解を深めれば幸いです。
この 互換性 要件は、特定のパーティション内でのみ適用されます。 パーティションが他のパーティションを参照している場合、参照されるパーティションのデータ ソースは相互に互換性を持つ必要はありません。 これは、ファイアウォールがデータをバッファリングできるためです。これにより、元のデータ ソースに対してさらに折りたたまれるのを防ぐことができます。 データはメモリに読み込まれ、どこからともないかのように扱われます。
なぜ両方をしないのですか?
たとえば、他の 2 つのクエリ (つまり、他の 2 つのパーティション) にアクセスする 1 つのステップ (もう一度 1 つのパーティションに対応する) でクエリを定義するとします。 同じ手順で SQL データベースに直接アクセスする場合はどうしますか? パーティションが他のパーティションを参照し、互換性のあるデータ ソースに直接アクセスできないのはなぜですか?
前に説明したように、あるパーティションが別のパーティションを参照する場合、ファイアウォールはパーティションに流れるすべてのデータのゲートキーパーとして機能します。 そのためには、許可されるデータを制御できる必要があります。 パーティション内にデータ ソースがアクセスされていて、他のパーティションからデータが流れ込んでいる場合、内部でアクセスされるデータ ソースの 1 つにデータが漏えいする可能性があるため、ゲートキーパーになる機能が失われます。 したがって、ファイアウォールは、他のパーティションにアクセスするパーティションがデータ ソースへの直接アクセスを許可されないようにします。
では、パーティションが他のパーティションを参照し、データ ソースにも直接アクセスしようとするとどうなりますか。
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
これで、この記事の冒頭に記載されている他のエラー メッセージについて理解が深まるようになりました。
パーティションの詳細な解説
以前の情報から推測できるように、クエリのパーティション分割方法は非常に重要になります。 他のクエリを参照しているステップや、データ ソースにアクセスするその他の手順がある場合、特定の場所でパーティション境界を描画するとファイアウォール エラーが発生し、他の場所で描画するとクエリが正常に実行されることを認識できるようになりました。
では、クエリはどのようにパーティション分割されますか?
このセクションは、ファイアウォール エラーが発生する理由を理解し、それらを解決する方法 (可能な場合) を理解するために、おそらく最も重要です。
パーティション分割ロジックの概要を次に示します。
- 初期パーティション分割
- 各クエリの各ステップのパーティションを作成します。
- 静的フェーズ
- このフェーズは、評価結果に依存しません。 代わりに、クエリの構造に依存します。
- パラメータートリミング
- パラメーターに似たパーティション、すなわち次のいずれかをトリミングします。
- 他のパーティションを参照しない
- 関数呼び出しが含まれていない
- 循環的ではありません (つまり、それ自体を参照していません)
- パーティションを "削除" すると、他のパーティションが参照するパーティションに実質的に含まれていることに注意してください。
- パラメーター パーティションをトリミングすると、データ ソース関数呼び出し (たとえば、
Web.Contents(myUrl)) 内で使用されるパラメーター参照を機能させることができます。"パーティションはデータ ソースやその他のステップを参照できません" エラーをスローする代わりに機能します。
- パラメーターに似たパーティション、すなわち次のいずれかをトリミングします。
- グループ化 (静的)
- パーティションは、ボトムアップ依存関係の順序でマージされます。 結果としてマージされたパーティションでは、次の内容は個別です。
- 異なるクエリ内のパーティション
- 他のパーティションを参照していない (そのため、データ ソースへのアクセスが許可されている) パーティション
- 他のパーティションを参照する (そのため、データ ソースへのアクセスが禁止されている) パーティション
- パーティションは、ボトムアップ依存関係の順序でマージされます。 結果としてマージされたパーティションでは、次の内容は個別です。
- パラメータートリミング
- このフェーズは、評価結果に依存しません。 代わりに、クエリの構造に依存します。
- 動的フェーズ
- このフェーズは、さまざまなパーティションによってアクセスされるデータ ソースに関する情報など、評価結果に依存します。
- トリミング
- 次のすべての要件を満たすパーティションをトリミングします。
- データ ソースにアクセスしない
- データ ソースにアクセスするパーティションを参照しない
- 循環的ではない
- 次のすべての要件を満たすパーティションをトリミングします。
- グループ化 (動的)
- 不要なパーティションがトリミングされたので、可能な限り大きいソース パーティションを作成してみてください。 この作成は、前の静的グループ化フェーズで説明したのと同じ規則を使用してパーティションをマージすることによって行われます。
これはどういう意味ですか?
前にレイアウトした複雑なロジックがどのように機能するかを示す例を見てみましょう。
サンプル シナリオを次に示します。 これは、テキスト ファイル (連絡先) と SQL データベース (Employees) の簡単なマージです。SQL サーバーはパラメーター (DbServer) です。
3 つのクエリ
この例で使用する 3 つのクエリの M コードを次に示します。
shared DbServer = "MySqlServer" meta [IsParameterQuery=true, Type="Text", IsParameterQueryRequired=true];
shared Contacts = let
Source = Csv.Document(File.Contents(
"C:\contacts.txt"),[Delimiter=" ", Columns=15, Encoding=1252, QuoteStyle=QuoteStyle.None]
),
#"Promoted Headers" = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(
#"Promoted Headers",
{
{"ContactID", Int64.Type},
{"NameStyle", type logical},
{"Title", type text},
{"FirstName", type text},
{"MiddleName", type text},
{"LastName", type text},
{"Suffix", type text},
{"EmailAddress", type text},
{"EmailPromotion", Int64.Type},
{"Phone", type text},
{"PasswordHash", type text},
{"PasswordSalt", type text},
{"AdditionalContactInfo", type text},
{"rowguid", type text},
{"ModifiedDate", type datetime}
}
)
in
#"Changed Type";
shared Employees = let
Source = Sql.Databases(DbServer),
AdventureWorks = Source{[Name="AdventureWorks"]}[Data],
HumanResources_Employee = AdventureWorks{[Schema="HumanResources",Item="Employee"]}[Data],
#"Removed Columns" = Table.RemoveColumns(
HumanResources_Employee,
{
"HumanResources.Employee(EmployeeID)",
"HumanResources.Employee(ManagerID)",
"HumanResources.EmployeeAddress",
"HumanResources.EmployeeDepartmentHistory",
"HumanResources.EmployeePayHistory",
"HumanResources.JobCandidate",
"Person.Contact",
"Purchasing.PurchaseOrderHeader",
"Sales.SalesPerson"
}
),
#"Merged Queries" = Table.NestedJoin(
#"Removed Columns",
{"ContactID"},
Contacts,
{"ContactID"},
"Contacts",
JoinKind.LeftOuter
),
#"Expanded Contacts" = Table.ExpandTableColumn(
#"Merged Queries",
"Contacts",
{"EmailAddress"},
{"EmailAddress"}
)
in
#"Expanded Contacts";
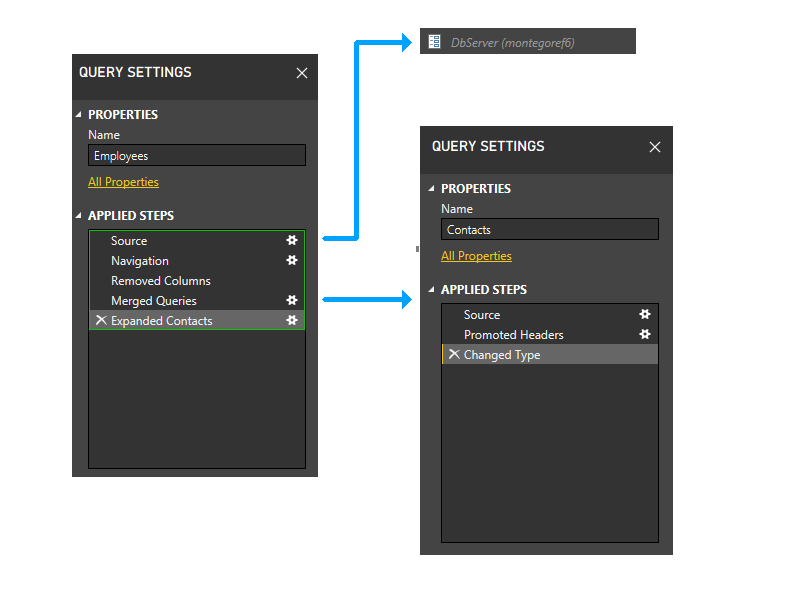
依存関係を示す上位レベルのビューを次に示します。
![[クエリの依存関係] ダイアログ。](media/data-privacy-firewall/firewall-query-dependencies.png)
分割しよう
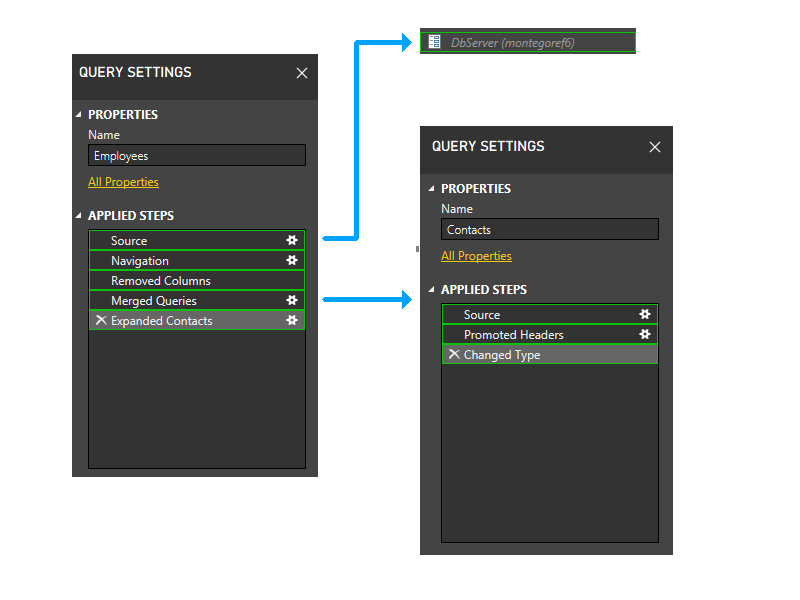
少しズームインし、ステップを図に含めて、パーティション分割ロジックを確認し始めましょう。 最初のファイアウォール パーティションが緑色で表示されている 3 つのクエリの図を次に示します。 各ステップが独自のパーティションで開始されていることに注意してください。
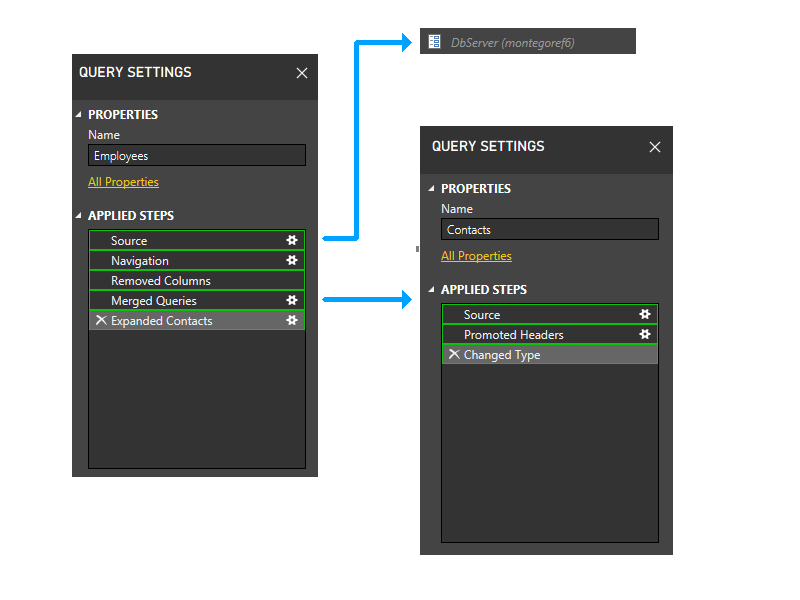
次に、パラメーター パーティションをトリミングします。 したがって、DbServer はソース パーティションに暗黙的に含まれます。
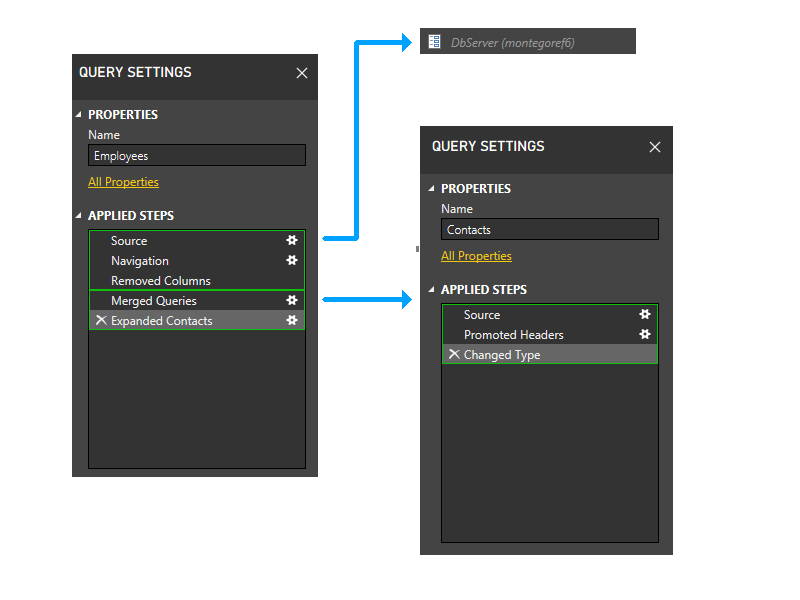
次に、静的グループ化を実行します。 このグループ化では、個別のクエリ内のパーティション (たとえば、従業員の最後の 2 つのステップは連絡先のステップでグループ化されない) と、他のパーティションを参照するパーティション (Employees の最後の 2 つのステップなど) とそうでないパーティション (従業員の最初の 3 つのステップなど) の間の分離が維持されます。
次に、動的フェーズに入ります。 このフェーズでは、上記の静的パーティションが評価されます。 データ ソースにアクセスしないパーティションはトリミングされます。 その後、パーティションはグループ化され、可能な限り大きいソース パーティションが作成されます。 ただし、このサンプル シナリオでは、残りのすべてのパーティションがデータ ソースにアクセスするため、それ以上グループ化することはできません。 したがって、このフェーズでは、サンプルのパーティションは変更されません。
考えて みましょう
ただし、図のために、テキスト ファイルではなく Contacts クエリが (おそらく [ データの入力 ] ダイアログを使用して) M でハードコーディングされた場合に何が起こるかを見てみましょう。
この場合、連絡先クエリはデータ ソースにアクセスしません。 したがって、動的フェーズの最初の部分でトリミングされます。
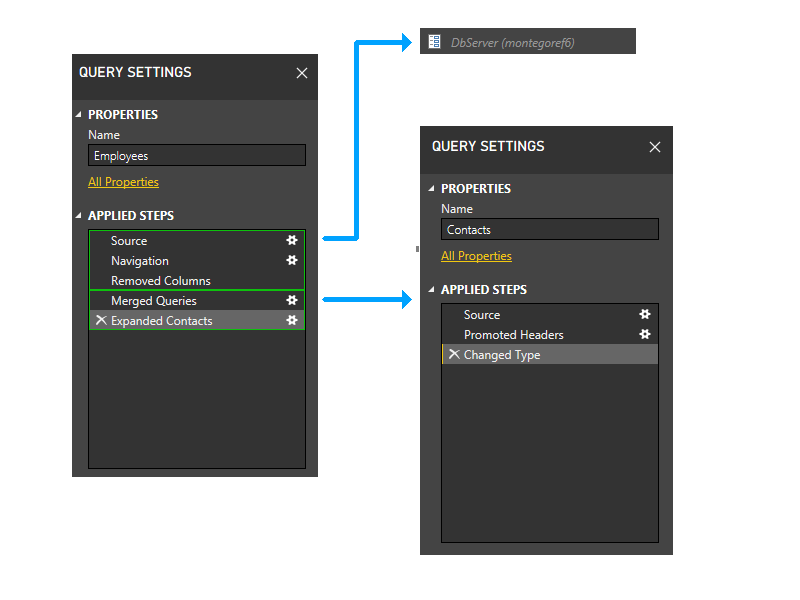
連絡先パーティションが削除された場合、Employees の最後の 2 つの手順は、Employees の最初の 3 つのステップを含むパーティションを除き、パーティションを参照しなくなります。 したがって、2 つのパーティションがグループ化されます。
結果のパーティションは次のようになります。
例: あるデータ ソースから別のデータ ソースにデータを渡す
もう抽象的な説明はこれくらいにしましょう。 ファイアウォール エラーが発生する可能性が高い一般的なシナリオと、それを解決する手順を見てみましょう。
Northwind OData サービスから会社名を検索し、会社名を使用してBing検索を実行するとします。
最初に、会社名を取得する 会社 クエリを作成します。
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName]
in
CHOPS
次に、Company を参照し、Bingに渡す検索クエリを作成します。
let
Source = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & Company))
in
Source
この時点で、問題が発生します。 検索を評価すると、ファイアウォール エラーが発生します。
Formula.Firewall: Query 'Search' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
このエラーは、 検索 のソース ステップがデータ ソース (bing.com) を参照し、別のクエリ/パーティション (Company) も参照しているために発生します。 前述の規則に違反しています ("パーティションは互換性のあるデータ ソースにアクセスするか、他のパーティションを参照できますが、両方を参照することはできません")。
どうすればよいでしょうか。 1 つのオプションは、ファイアウォールを完全に無効にすることです ([プライバシー レベルを無視する] というラベルの付いた [プライバシー] オプションを使用 して、パフォーマンスが向上する可能性があります)。 しかし、ファイアウォールを有効のままにする場合はどうなりますか?
ファイアウォールを無効にせずにエラーを解決するには、次のように Company と Search を 1 つのクエリに結合します。
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName],
Search = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & CHOPS))
in
Search
すべてが 1 つの パーティション内で行われています。 2 つのデータ ソースのプライバシー レベルに互換性があると仮定すると、ファイアウォールは満足でき、エラーが発生しなくなります。
終了です
このトピックでは他にも多くのことが言えますが、この入門記事は既に十分な長さです。 ファイアウォールの理解を深め、将来ファイアウォールエラーが発生したときにファイアウォールエラーを理解して修正するのに役立ちます。