あいまい一致、値のクラスター化、あいまいグループ化などの Power Query の機能の動作には、あいまい一致と同じメカニズムが使われます。
この記事では、「あいまい」を明確にすることを目的として、あいまい一致のオプションを活用する方法を説明する多くのシナリオについて説明します。
類似性のしきい値を調整する
ファジー一致アルゴリズムを適用するための最良のシナリオは、列内のすべてのテキスト文字列に比較する必要のある文字列のみが含まれており、余分なコンポーネントが含まれていない場合です。 たとえば、Apples と 4ppl3s を比較する方が、Apples と My favorite fruit, by far, is Apples. I simply love them! を比較するより類似性スコアが高くなります。
2 番目の文字列内の単語 Apples はテキスト文字列全体のほんの一部にすぎないため、その比較では類似性スコアが低くなります。
たとえば、次のデータ セットは、質問が 1 つだけ「あなたの好きな果物は何ですか?」というアンケートの回答で構成されています。
| Fruit |
|---|
| Blueberries |
| Blue berries are simply the best |
| Strawberries |
| イチゴ = <3 |
| Apples |
| 'sples |
| 4ppl3s |
| バナナ |
| fav fruit is bananas |
| Banas |
| My favorite fruit, by far, is Apples. I simply love them! |
調査では、値を入力するための単一のテキストボックスが提供され、検証は行われませんでした。
次に、値のクラスター化を行います。 このタスクを実行するには、前のフルーツのテーブルを Power Query に読み込み、列を選択して、リボンの [列の追加] タブで [クラスター値] オプションを選択します。
![]()
[クラスター値] ダイアログ ボックスが表示され、新しい列の名前を指定できます。 この新しい列に Cluster という名前を付け、OK を選択します。
![[Fruit] 列を選択した後の [クラスター値] ダイアログ ボックスのスクリーンショット。新しい列名フィールドが Cluster に設定されています。](media/fuzzy-matching/cluster-values-default-window.png)
既定では、Power Query では類似性しきい値 0.8 (または 80%) が使用されます。 最小値が 0.00 の場合、任意のレベルの類似性を持つすべての値が相互に一致し、最大値 1.00 では完全一致のみが許可されます。 あいまいな "完全一致" では、大文字と小文字の区別、語順、句読点などの違いが無視される場合があります。 前の操作の結果、新しい Cluster 列を含む次の表が生成されます。
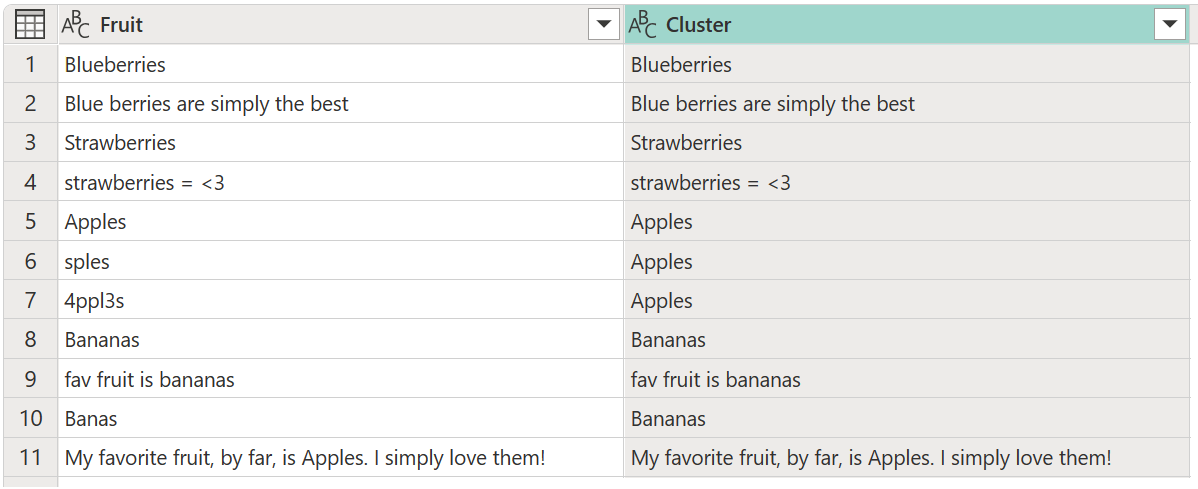
クラスタリングは完了していますが、すべての行に対して期待した結果が得られるわけではありません。 行番号 2 の値はまだ Blue berries are simply the best のままですが、Blueberries にクラスター化されていなければならず、テキスト文字列 Strawberries = <3、fav fruit is bananas、My favorite fruit, by far, is Apples. I simply love them! についても同様のことが発生しています。
このクラスタリングの原因を特定するには、[適用されたステップ] パネルの [クラスタ化された値] をダブルクリックして、[クラスタ値] ダイアログ ボックスに戻ります。 このダイアログ ボックス内で、ファジー クラスター オプションを展開します。 [類似性スコアを表示] オプションを有効にして、[OK] を選択します。
![[あいまいクラスター オプション] が表示され、[類似度スコアを表示する] オプションがオンになっている [クラスター値] ウィンドウのスクリーンショット。](media/fuzzy-matching/window-with-show-similarity-score.png)
[類似スコアを表示] オプションを有効にすると、テーブルに新しい列が作成されます。 この列には、定義されたクラスターと元の値の間の正確な類似性スコアが表示されます。

詳しく調べたところ、Power Query はテキスト文字列Blue berries are simply the best、Strawberries = <3、fav fruit is bananas、My favorite fruit, by far, is Apples. I simply love them! の類似性しきい値に他の値を見つけることができませんでした。
[適用されたステップ] パネルの [クラスター化された値] をダブルクリックして、もう一度 [クラスター値] ダイアログ ボックスに戻ります。 類似性のしきい値を0.8から 0.6 に変更し、OKを選択します。
![[あいまいクラスター オプション] が表示され、[類似性しきい値] が 0.6 に設定された [クラスター値] ダイアログ ボックスのスクリーンショット。](media/fuzzy-matching/window-with-show-similarity-score-60.png)
この変更により、テキスト文字列 My favorite fruit, by far, is Apples. I simply love them! を除き、望ましい結果に近づきます。 Similarity threshold の値を0.8 から 0.6に変更すると、Power Query は 0.6 から 1 までの類似度スコアを持つ値を使用できるようになりました。

Note
Power Query では、常に、しきい値に最も近い値を使用してクラスターが定義されます。 閾値は、クラスタに値を割り当てるために許容される類似度スコアの下限を定義します。
探している結果が得られるまで、類似性スコア を 0.6 からより低い数値に変更して再試行できます。 この場合、類似性スコアを0.5に変更します。 この変更により、クラスタ Apples に割り当てられたテキスト文字列 My favorite fruit, by far, is Apples. I simply love them! で期待どおりの結果が得られます。
![[Cluster] 列にすべての正しい値を含むテーブルのスクリーンショット。](media/fuzzy-matching/values-with-show-similarity-score-50.png#lightbox)
Note
現在、Power Query Online の クラスター値 機能のみが類似性スコアを含む新しい列を提供します。
変換テーブルに関する特別な考慮事項
変換テーブルは、あいまい一致アルゴリズムを実行する前に、列の値を新しい値にマップするのに役立ちます。
変換テーブルの使用方法の例をいくつか示します。
重要
変換テーブルを使用する場合、変換テーブルの値の最大類似性スコアは 0.95 です。 この意図的な 0.05 のペナルティは、そのような列の元の値が、変換が発生してから比較された値と等しくないことを区別するために設けられています。
最初に値をマップしてから、0.05 ペナルティなしであいまい一致を実行するシナリオでは、列の値を置き換えてからあいまい一致を実行することをお勧めします。