データ ソースによっては、データ型と列名に関する情報が明示的に提供される場合と提供されない場合があります。 OData REST API は通常、 $metadata定義を使用してこれを処理します。Power Query OData.Feed メソッドは、この情報の解析と OData ソースから返されたデータへの適用を自動的に処理します。
多くの REST API には、スキーマをプログラムで決定する方法がありません。 このような場合は、コネクタにスキーマ定義を含める必要があります。
単純なハードコーディングされたアプローチ
最も簡単な方法は、スキーマ定義をコネクタにハードコーディングすることです。 これは、ほとんどのユース ケースで十分です。
全体として、コネクタから返されるデータにスキーマを適用するには、次のような複数の利点があります。
- 正しいデータ型の設定。
- エンド ユーザーに表示する必要のない列 (内部 ID や状態情報など) を削除する。
- 応答に欠けている可能性がある列を追加して、データの各ページが同じ図形を持っていることを確認します (REST API は、通常、フィールドを完全に省略して null にする必要があることを示します)。
を使用して既存のスキーマを表示する Table.Schema
TripPin OData サンプル サービスから単純なテーブルを返す次のコードを考えてみましょう。
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
asTable
注
TripPin は OData ソースであるため、現実的には、 OData.Feed 関数の自動スキーマ処理を使用する方が理にかなっています。 この例では、ソースを一般的な REST API として扱い、 Web.Contents を使用して、スキーマを手動でハードコーディングする手法を示します。
次の表に結果を示します。
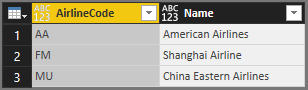
便利な Table.Schema 関数を使用して、列のデータ型を確認できます。
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
Table.Schema(asTable)

AirlineCode と Name はどちらも any の種類です。
Table.Schema は、名前、位置、型情報、Precision、Scale、MaxLength などの多くの高度なプロパティなど、テーブル内の列に関する多くのメタデータを返します。 今のところ、注目すべきは付加型 (TypeName)、プリミティブ型 (Kind)、列の値が null であるかどうかです。
単純なスキーマ テーブルの定義
スキーマ テーブルは、次の 2 つの列で構成されます。
| コラム | 詳細 |
|---|---|
| 名前 | 列の名前。 これは、サービスによって返される結果の名前と一致する必要があります。 |
| タイプ | 設定する M データ型。 これには、プリミティブ型 (テキスト、数値、datetime など)、または接する型 (Int64.Type、Currency.Type など) を指定できます。 |
Airlines テーブルのハードコーディングされたスキーマ テーブルでは、AirlineCode列とName列がtextに設定され、次のようになります。
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})
他のエンドポイントの一部を確認するときは、次のスキーマ テーブルを検討してください。
Airports テーブルには、保持する 4 つのフィールドがあります (record型のいずれかを含む)。
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})
People テーブルには、list (Emails、AddressInfo)、null を許容する 列 (Gender)、および型が指定された列 () を含む 7 つのフィールドがあります。
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
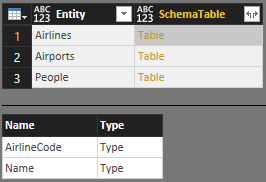
これらのテーブルはすべて、次の SchemaTable単一のマスター スキーマ テーブルに配置できます。
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", Airlines},
{"Airports", Airports},
{"People", People}
})
SchemaTransformTable ヘルパー関数
以下で説明する SchemaTransformTablehelper 関数 を使用して、データにスキーマを適用します。 次のパラメーターを受け取ります。
| パラメーター | タイプ | Description |
|---|---|---|
| テーブル | テーブル | スキーマを適用するデータのテーブル。 |
| スキーマ | テーブル | 列情報を読み取るスキーマ テーブルの種類: type table [Name = text, Type = type]。 |
| enforceSchema | 数値 | (省略可能)関数の動作を制御する列挙型。 既定値 ( EnforceSchema.Strict = 1) を使用すると、不足している列を追加し、追加の列を削除することで、出力テーブルが指定されたスキーマ テーブルと一致します。 EnforceSchema.IgnoreExtraColumns = 2 オプションを使用すると、結果に追加の列を保持できます。 EnforceSchema.IgnoreMissingColumns = 3を使用すると、不足している列と余分な列の両方が無視されます。 |
この関数のロジックは次のようになります。
- ソース テーブルに列がないかどうかを確認します。
- 追加の列があるかどうかを判断します。
- 構造化列 (
list、record、およびtableの型) と、any型に設定された列は無視します。 -
Table.TransformColumnTypesを使用して、各列の種類を設定します。 - スキーマ テーブルに表示される順序に基づいて列を並べ替えます。
-
Value.ReplaceTypeを使用して、テーブル自体に型を設定します。
注
テーブルの種類を設定する最後の手順では、クエリ エディターで結果を表示するときに Power Query UI で型情報を推論する必要がなくなります。この場合、API が 2 回呼び出される場合があります。
すべてをまとめる
完全な拡張機能のより大きなコンテキストでは、API からテーブルが返されるときにスキーマ処理が行われます。 通常、この機能は、ナビゲーション テーブルから渡されるエンティティ情報を使用して、ページング関数の最下位レベル (存在する場合) で実行されます。
ページングテーブルとナビゲーション テーブルの実装の多くはコンテキスト固有であるため、ハードコーディングされたスキーマ処理メカニズムを実装する完全な例はここには示されません。 この TripPin の例では 、エンド ツー エンドのソリューションがどのように表示されるかを示します。
高度なアプローチ
上で説明したハードコーディングされた実装は、単純な JSON 応答に対してスキーマの一貫性を保つための適切なジョブですが、応答の最初のレベルの解析に限定されます。 深く入れ子になったデータ セットは、M 型を利用する次のアプローチの利点があります。
M 言語の型について、言語仕様からのクイックリフレッシュは以下の通りです。
"型値" はその他の値を "分類する" 値です。 型で分類される値は、その型に "準拠する" とされます。 M 型システムは、次の種類の型で構成されています。
- プリミティブ型。プリミティブ値 (
binary、date、datetime、datetimezone、duration、list、logical、null、number、record、text、time、type) を分類し、さらに多くの抽象型 (function、table、any、およびnone) を含みます。- レコード型。フィールド名と値型に基づいてレコード値を分類します。
- リストの種類。1 つの項目の基本型を使用してリストを分類します。
- 関数型。パラメーターと戻り値の型に基づいて関数の値を分類します。
- テーブル型。列名、列の型、およびキーに基づいてテーブル値を分類します。
- Null 許容型は、基本型で分類されるすべての値に加えて、null 値も分類します。
- 型タイプ、型である値を分類します。
取得した未加工の JSON 出力 (または サービスの$metadata内の定義を参照) を使用して、OData 複合型を表す次のレコード型を定義できます。
LocationType = type [
Address = text,
City = CityType,
Loc = LocType
];
CityType = type [
CountryRegion = text,
Name = text,
Region = text
];
LocType = type [
#"type" = text,
coordinates = {number},
crs = CrsType
];
CrsType = type [
#"type" = text,
properties = record
];
LocationTypeがCityTypeとLocTypeを参照してその構造化列を表す方法に注目してください。
テーブルとして表す最上位レベルのエンティティの場合は、 テーブルの種類を定義できます。
AirlinesType = type table [
AirlineCode = text,
Name = text
];
AirportsType = type table [
Name = text,
IataCode = text,
Location = LocationType
];
PeopleType = type table [
UserName = text,
FirstName = text,
LastName = text,
Emails = {text},
AddressInfo = {nullable LocationType},
Gender = nullable text,
Concurrency Int64.Type
];
その後、 SchemaTable 変数 (エンティティと型のマッピングの参照テーブルとして使用できます) を更新して、次の新しい型定義を使用できます。
SchemaTable = #table({"Entity", "Type"}, {
{"Airlines", AirlinesType},
{"Airports", AirportsType},
{"People", PeopleType}
});
前の演習でTable.ChangeType使用したのと同様に、共通の関数 (SchemaTransformTable) を使用してデータにスキーマを適用できます。
SchemaTransformTableとは異なり、Table.ChangeTypeは実際の M テーブル型を引数として受け取り、入れ子になったすべての型にスキーマを再帰的に適用します。 そのシグネチャは次のとおりです。
Table.ChangeType = (table, tableType as type) as nullable table => ...
注
柔軟性を高めるために、テーブルとレコードのリスト (JSON ドキュメントでのテーブルの表現方法) で関数を使用できます。
その後、コネクタ コードを更新して、 schema パラメーターを table から typeに変更し、 Table.ChangeTypeの呼び出しを追加する必要があります。 ここでも、これを行うための詳細は実装固有であるため、ここで詳しく説明する価値はありません。
この拡張された TripPin コネクタの例は 、スキーマを処理するためのこのより高度なアプローチを実装するエンドツーエンドのソリューションを示しています。