TripPin パート 10 - 基本的なクエリの折りたたみ
Note
現在このコンテンツは、Visual Studio のログのレガシ実装のコンテンツを参照しています。 コンテンツは近い将来更新され、Visual Studio Code の新しい Power Query SDK に対応する予定です。
このマルチパート チュートリアルでは、Power Query 用の新しいデータ ソース拡張機能の作成について説明します。 このチュートリアルは順番に実行することを目的としています。各レッスンは前のレッスンで作成したコネクタに基づいて構築され、コネクタに新しい機能が段階的に追加されます。
このレッスンの内容:
- クエリ フォールディングの基本を学習する
- Table.View 関数について学ぶ
- 次のものに対する OData クエリ フォールディング ハンドラーをレプリケートする:
$top$skip$count$select$orderby
M 言語の強力な機能の 1 つは、変換作業を 1 つ以上の基礎となるデータ ソースにプッシュできる機能です。 この機能は クエリ フォールディング と呼ばれます (他のツールやテクノロジでは、同様の機能が述語プッシュダウンやクエリ委任と呼ばれることもあります)。
OData.Feed やOdbc.DataSource など、組み込みのクエリ フォールディング機能を持つ M 関数を使用するカスタム コネクタを作成する場合、コネクタはこの機能を無料で自動的に継承します。
このチュートリアルでは、Table.View 関数の関数ハンドラーを実装することによって、OData の組み込みクエリの折りたたみ動作を複製します。 チュートリアルのこのパートでは、実装が さらに簡単 ないくつかのハンドラー (つまり、式の解析と状態追跡を必要としないもの) を実装します。
OData サービスが提供するクエリ機能の詳細については、「OData v4 URL 規則」を参照してください。
Note
上で述べたように、OData.Feed 関数はクエリ フォールディング機能を自動的に提供します。 TripPin シリーズは、OData.Feed ではなくWeb.Contentsを使用して OData サービスを通常の REST API として扱っているため、クエリ折りたたみハンドラーを自分で実装する必要があります。 実際の使用では、可能な限りOData.Feedを使用することをお勧めします。
クエリの折りたたみの詳細については、「Power Query でのクエリ評価とクエリの折りたたみの概要」を参照してください。
Table.View の使用
Table.View 関数を使用すると、データ ソース用の既定の変換ハンドラーをカスタム コネクタでオーバーライドできます。 Table.Viewの実装は、サポートされている 1 つ以上のハンドラーに関数を提供します。 ハンドラーが実装されていない場合、または評価中に error を返した場合、M エンジンはデフォルトのハンドラーに戻ります。
カスタム コネクタがWeb.Contentsなどの暗黙的なクエリの折りたたみをサポートしていない関数を使用する場合、デフォルトの変換ハンドラーは常にローカルで実行されます。 接続先の REST API がクエリの一部としてクエリ パラメーターをサポートしている場合、Table.Viewを使用して、変換作業をサービスにプッシュできる最適化を追加できます。
Table.View 関数には次のシグネチャがあります。
Table.View(table as nullable table, handlers as record) as table
実装では、メイン データ ソース関数をラップします。 Table.View には 2 つの必須ハンドラーがあります。
GetType- クエリ結果の期待されるtable typeを返します。GetRows- データ ソース関数の実際のtable結果を返します。
最も簡単な実装は次の例のようになります。
TripPin.SuperSimpleView = (url as text, entity as text) as table =>
Table.View(null, [
GetType = () => Value.Type(GetRows()),
GetRows = () => GetEntity(url, entity)
]);
GetEntity ではなく TripPin.SuperSimpleView を呼び出すように TripPinNavTable 関数を更新します。
withData = Table.AddColumn(rename, "Data", each TripPin.SuperSimpleView(url, [Name]), type table),
単体テストを再度実行すると、関数の動作が変わっていないことがわかります。 この場合、Table.View実装は単にGetEntityへの呼び出しをパススルーしています。 変換ハンドラーを (まだ) 実装していないため、元の url パラメーターはそのまま残ります。
Table.View の初期実装
上記の Table.View の実装は単純ですが、あまり役に立ちません。 次の実装はベースラインとして使用されます。これは折りたたみ機能を実装していませんが、折りたたみ機能を行うために必要な足場を備えています。
TripPin.View = (baseUrl as text, entity as text) as table =>
let
// Implementation of Table.View handlers.
//
// We wrap the record with Diagnostics.WrapHandlers() to get some automatic
// tracing if a handler returns an error.
//
View = (state as record) => Table.View(null, Diagnostics.WrapHandlers([
// Returns the table type returned by GetRows()
GetType = () => CalculateSchema(state),
// Called last - retrieves the data from the calculated URL
GetRows = () =>
let
finalSchema = CalculateSchema(state),
finalUrl = CalculateUrl(state),
result = TripPin.Feed(finalUrl, finalSchema),
appliedType = Table.ChangeType(result, finalSchema)
in
appliedType,
//
// Helper functions
//
// Retrieves the cached schema. If this is the first call
// to CalculateSchema, the table type is calculated based on
// the entity name that was passed into the function.
CalculateSchema = (state) as type =>
if (state[Schema]? = null) then
GetSchemaForEntity(entity)
else
state[Schema],
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity])
in
urlWithEntity
]))
in
View([Url = baseUrl, Entity = entity]);
Table.Viewへの呼び出しを見ると、handlers レコードの周囲に追加のラッパー関数 (Diagnostics.WrapHandlers) があることがわかります。 このヘルパー関数は Diagnostics モジュール (診断の追加レッスンで紹介) にあり、個々のハンドラーによって発生したエラーを自動的に追跡する便利な方法を提供します。
GetType および GetRows関数は、2 つの新しいヘルパー関数CalculateSchemaおよびCalculateUrlを使用するように更新されました。 現時点では、これらの関数の実装は非常に簡単です。以前に GetEntity 関数によって実行されていた処理の一部が含まれているに注意してください。
最後に、state パラメーターを受け取る内部関数 (View) が定義されていることに注意してください。
さらに多くのハンドラーを実装するときは、内部 View 関数を再帰的に呼び出し、state を更新して渡していきます。
TripPinNavTable 関数を再び更新し、TripPin.SuperSimpleView の呼び出しを新しい TripPin.View 関数の呼び出しに置き換えてから、単体テストを再度実行します。 新しい機能はまだ何もありませんが、テストのための確実なベースラインが作成されました。
クエリの折りたたみの実装
クエリを折りたためない場合、M エンジンは自動的にローカル処理にフォールバックするため、Table.Viewハンドラーが正しく動作していることを検証するために、いくつかの追加手順を実行する必要があります。
フォールディング動作を手動で検証するには、Fiddler のようなツールを使用して、単体テストで行われている URL 要求を監視します。 または、TripPin.Feed に追加した診断ログは、実行されている完全な URL を出力します。この URL には、ハンドラーによって追加された OData クエリ文字列パラメーターが含まれている 必要があります。
クエリ フォールディングを自動的に検証するには、クエリでフォールディングが完全に行われていない場合は、単体テストの実行を強制的に失敗させます。 これを行うには、プロジェクトのプロパティを開き、[Error on Folding Failure]\(フォールディング失敗でエラー\) を [True] に設定します。 この設定を有効にすると、ローカル処理を必要とするクエリでは、次のエラーが発生します。
式をソースに折り畳むことができませんでした。 もっと簡単な表現を試してください。
これをテストするには、1 つ以上のテーブル変換を含む新しい Fact を、単体テスト ファイルに追加します。
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
)
Note
[Error on Folding Failure]\(フォールディング失敗でエラー\) の設定は、"オール オア ナッシング" のアプローチです。 単体テストの一部として、フォールディングを行うように設計されていないクエリをテストする場合は、必要に応じてテストを有効または無効にする条件付きロジックを追加する必要があります。
このチュートリアルの残りのセクションでは、それぞれ新しい Table.Viewハンドラーを追加します。 テスト駆動開発 (TDD) アプローチを採用している場合、最初に失敗した単体テストを追加し、次に M コードを実装してそれらを解決します。
次の各ハンドラー セクションでは、ハンドラーによって提供される機能、OData と同等のクエリ構文、単体テスト、および実装について説明します。 前述したスキャフォールディング コードを使用すると、各ハンドラーの実装には 2 つの変更が必要です。
stateレコードを更新するハンドラーを Table.Viewに追加します。stateから値を取得し、URL とクエリ文字列のパラメーターの一方または両方に追加するように、CalculateUrlを変更します。
OnTake での Table.FirstN の処理
OnTakeハンドラーは、GetRowsから取得する最大行数であるcountパラメーターを受け取ります。
OData の記述では、これは $top クエリ パラメーターに相当します。
次の単体テストを使用してください。
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
),
Fact("Fold $top 0 on Airports",
#table( type table [Name = text, IataCode = text, Location = record] , {} ),
Table.FirstN(Airports, 0)
),
これらのテストはどちらも Table.FirstNを使用して、最初の X 行の結果セットをフィルター処理します。 [折りたたみ失敗時のエラー] を False (デフォルト) に設定してこれらのテストを実行すると、テストは成功するはずですが、Fiddler を実行する (またはトレース ログを確認する) 場合は、送信するリクエストに OData クエリ パラメーターが含まれていないことに注意してください。 。
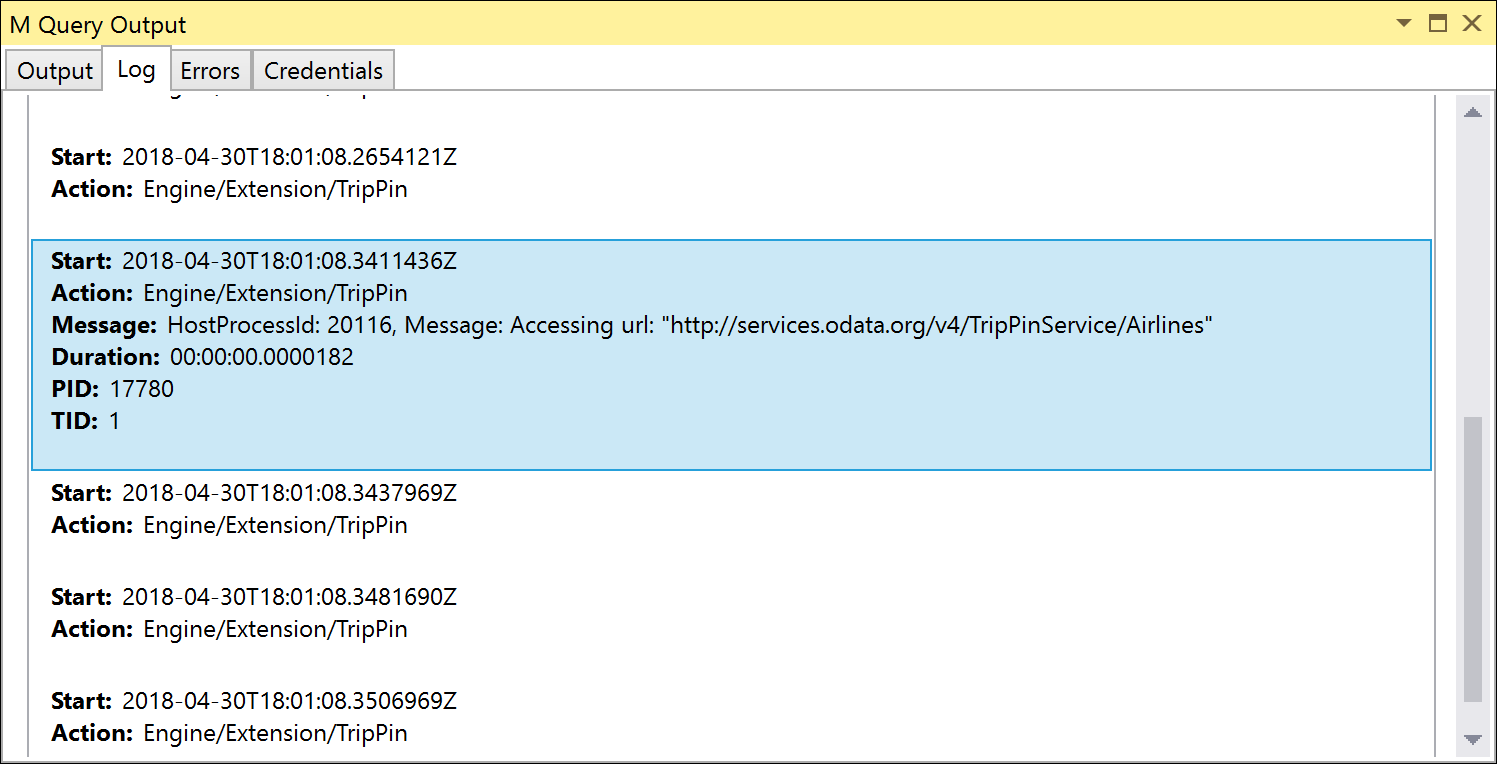
折りたたみ失敗時のエラーを True に設定すると、テストは Please try a simpler expression. エラーで失敗します。 このエラーを修正するには、OnTakeの最初のTable.View ハンドラーを定義する必要があります。
OnTake ハンドラーは次のコードのようになります。
OnTake = (count as number) =>
let
// Add a record with Top defined to our state
newState = state & [ Top = count ]
in
@View(newState),
state レコードから Top の値を抽出し、クエリ文字列に適切なパラメーターを設定するように、CalculateUrl 関数が更新されています。
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity]),
// Uri.BuildQueryString requires that all field values
// are text literals.
defaultQueryString = [],
// Check for Top defined in our state
qsWithTop =
if (state[Top]? <> null) then
// add a $top field to the query string record
defaultQueryString & [ #"$top" = Number.ToText(state[Top]) ]
else
defaultQueryString,
encodedQueryString = Uri.BuildQueryString(qsWithTop),
finalUrl = urlWithEntity & "?" & encodedQueryString
in
finalUrl
単体テストを再実行すると、現在アクセスしている URL に $top パラメーターが含まれていること注意してください。 URL エンコードにより、$top は %24top として表示されますが、OData サービスはこれを自動的に変換する機能を備えています。
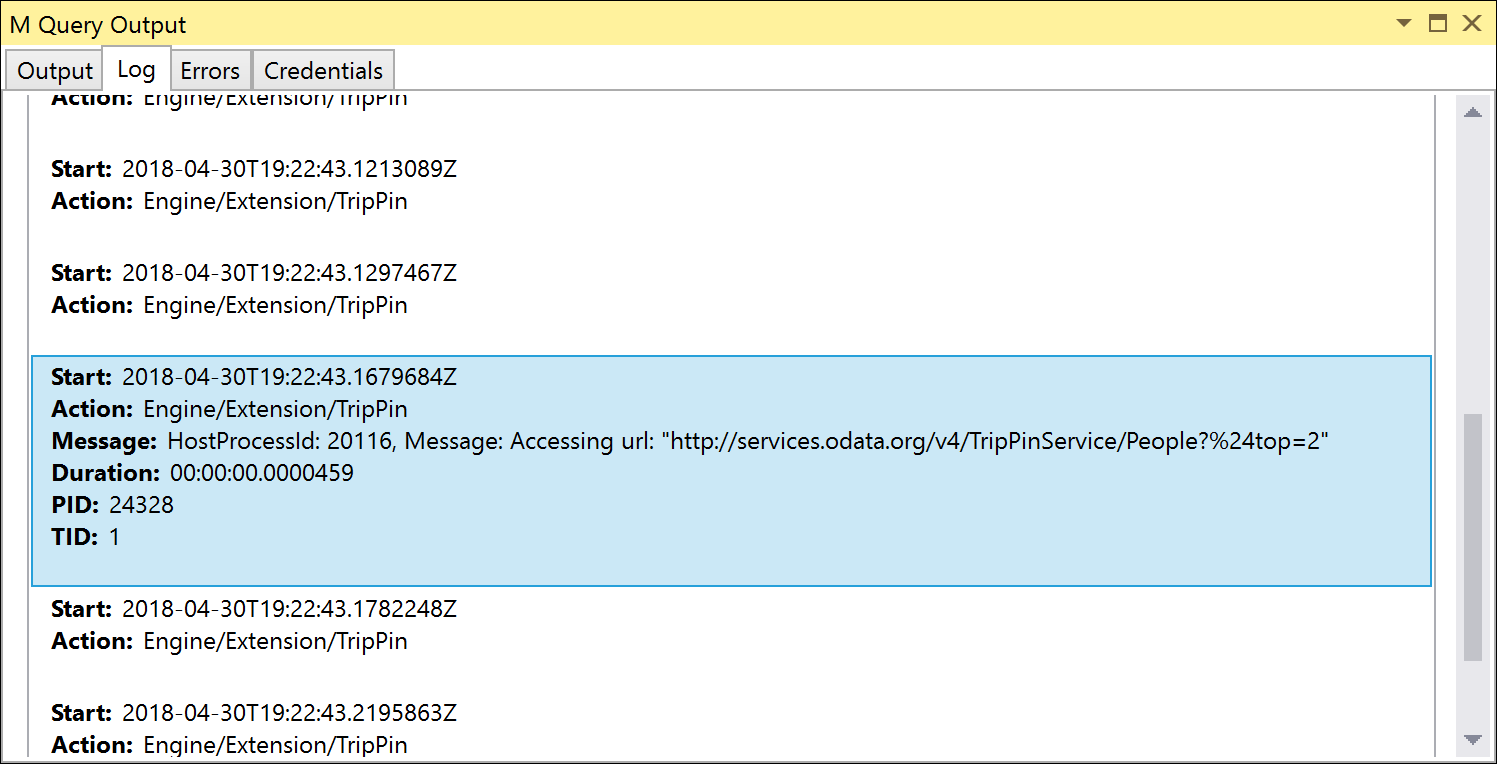
OnSkip での Table.Skip の処理
OnSkipハンドラーは OnTakeによく似ています。 結果セットからスキップする行数を示す count パラメーターを受け取ります。 このハンドラーは、OData $skip クエリ パラメーターに適切に変換されます。
単体テスト:
// OnSkip
Fact("Fold $skip 14 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"EK", "Emirates"}} ),
Table.Skip(Airlines, 14)
),
Fact("Fold $skip 0 and $top 1",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Table.Skip(Airlines, 0), 1)
),
実装:
// OnSkip - handles the Table.Skip transform.
// The count value should be >= 0.
OnSkip = (count as number) =>
let
newState = state & [ Skip = count ]
in
@View(newState),
CalculateUrl に対する更新の照合:
qsWithSkip =
if (state[Skip]? <> null) then
qsWithTop & [ #"$skip" = Number.ToText(state[Skip]) ]
else
qsWithTop,
詳細: Table.Skip
OnSelectColumns での Table.SelectColumns の処理
OnSelectColumns ハンドラーは、ユーザーが結果セットから列を選択または削除するときに呼び出されます。 ハンドラーは、選択される 1 つ以上の列を表す list 値の text を受け取ります。
OData の用語では、この操作は $select クエリ オプションにマップされます。
列選択を折りたたむことの利点は、多くの列を含むテーブルを扱う場合に明らかになります。 $select 演算子を使用すると、選択されていない列が結果セットから削除され、クエリの効率が向上します。
単体テスト:
// OnSelectColumns
Fact("Fold $select single column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode"}), 1)
),
Fact("Fold $select multiple column",
#table( type table [UserName = text, FirstName = text, LastName = text],{{"russellwhyte", "Russell", "Whyte"}}),
Table.FirstN(Table.SelectColumns(People, {"UserName", "FirstName", "LastName"}), 1)
),
Fact("Fold $select with ignore column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode", "DoesNotExist"}, MissingField.Ignore), 1)
),
最初の 2 つのテストでは、Table.SelectColumnsで異なる数の列を選択し、テスト ケースを簡素化するために Table.FirstN 呼び出しを含めています。
Note
テストが単に列名を返すだけの場合 (データではなく Table.ColumnNamesを使用)、OData サービスへのリクエストは実際には送信されません。 これは、GetType の呼び出しによってスキーマが返され、M エンジンが結果を計算するために必要なすべての情報がそれに含まれるためです。
3 番目のテストでは、MissingField.Ignoreオプションを使用します。これは、結果セットに存在しない選択された列を無視するように M エンジンに指示します。 OnSelectColumns ハンドラーはこのオプションを気にする必要はありません。M エンジンが自動的に処理します (つまり、欠落している列は columns リストに含まれません)。
Note
Table.SelectColumnsのもう 1 つのオプションであるMissingField.UseNullには、OnAddColumnハンドラーを実装するためのコネクタが必要です。 これについては、後のレッスンで行います。
OnSelectColumns の実装では、次の 2 つの処理が行われます。
- 選択された列のリストを
stateに追加します。 - 適切なテーブルの種類を設定できるように、
Schemaの値を再計算します。
OnSelectColumns = (columns as list) =>
let
// get the current schema
currentSchema = CalculateSchema(state),
// get the columns from the current schema (which is an M Type value)
rowRecordType = Type.RecordFields(Type.TableRow(currentSchema)),
existingColumns = Record.FieldNames(rowRecordType),
// calculate the new schema
columnsToRemove = List.Difference(existingColumns, columns),
updatedColumns = Record.RemoveFields(rowRecordType, columnsToRemove),
newSchema = type table (Type.ForRecord(updatedColumns, false))
in
@View(state &
[
SelectColumns = columns,
Schema = newSchema
]
),
state から列のリストを取得し、それら (および区切り記号) を $select パラメーターに結合するように、CalculateUrl が更新されています。
// Check for explicitly selected columns
qsWithSelect =
if (state[SelectColumns]? <> null) then
qsWithSkip & [ #"$select" = Text.Combine(state[SelectColumns], ",") ]
else
qsWithSkip,
OnSort での Table.Sort の処理
OnSortハンドラーは、次のタイプのレコードのリストを受け取ります。
type [ Name = text, Order = Int16.Type ]
各レコードには、列の名前を示す Name フィールドと、Order.Ascending または Order.Descending に等しい Order フィールドが含まれています。
OData の用語では、この操作は $orderby クエリ オプションにマップされます。
$orderby の構文では、列名の後に、昇順または降順を示す asc または desc が続きます。 複数の列で並べ替える場合、値はコンマで区切られます。 columns パラメータに複数の項目が含まれる場合は、項目の表示順序を維持することが重要です。
単体テスト:
// OnSort
Fact("Fold $orderby single column",
#table( type table [AirlineCode = text, Name = text], {{"TK", "Turkish Airlines"}}),
Table.FirstN(Table.Sort(Airlines, {{"AirlineCode", Order.Descending}}), 1)
),
Fact("Fold $orderby multiple column",
#table( type table [UserName = text], {{"javieralfred"}}),
Table.SelectColumns(Table.FirstN(Table.Sort(People, {{"LastName", Order.Ascending}, {"UserName", Order.Descending}}), 1), {"UserName"})
)
実装:
// OnSort - receives a list of records containing two fields:
// [Name] - the name of the column to sort on
// [Order] - equal to Order.Ascending or Order.Descending
// If there are multiple records, the sort order must be maintained.
//
// OData allows you to sort on columns that do not appear in the result
// set, so we do not have to validate that the sorted columns are in our
// existing schema.
OnSort = (order as list) =>
let
// This will convert the list of records to a list of text,
// where each entry is "<columnName> <asc|desc>"
sorting = List.Transform(order, (o) =>
let
column = o[Name],
order = o[Order],
orderText = if (order = Order.Ascending) then "asc" else "desc"
in
column & " " & orderText
),
orderBy = Text.Combine(sorting, ", ")
in
@View(state & [ OrderBy = orderBy ]),
CalculateUrl に対する更新:
qsWithOrderBy =
if (state[OrderBy]? <> null) then
qsWithSelect & [ #"$orderby" = state[OrderBy] ]
else
qsWithSelect,
GetRowCount での Table.RowCount の処理
実装している他のクエリ ハンドラーとは異なり、GetRowCount ハンドラーは単一の値、つまり結果セットで予期される行数を返します。 M クエリでは、これは通常、Table.RowCount変換の結果になります。
この値を OData クエリの一部として処理する方法には、いくつかの異なるオプションがあります。
- $count クエリ パラメーター は、結果セット内の個別のフィールドとしてカウントを返します。
- /$count パス セグメント は、合計カウントのみをスカラー値として返します。
クエリ パラメーターの方法の欠点は、やはりクエリ全体を OData サービスに送信する必要がある点です。 カウントは結果セットの一部としてインラインで返されるため、結果セットのデータの最初のページを処理する必要があります。 このプロセスは、結果セット全体を読み取って行をカウントするよりも効率的ではありますが、それでもおそらく、やりたいことよりも多くの作業が必要になります。
パス セグメントの方法の利点は、結果で受け取るのが 1 つのスカラー値のみであることです。 このアプローチにより、操作全体が大幅に効率化されます。 ただし、OData 仕様で説明されているように、$top や $skip などの他のクエリ パラメーターを含めると、/$count パス セグメントはエラーを返すため、有用性が制限されます。
このチュートリアルでは、パス セグメントの方法を使用して GetRowCount ハンドラーを実装しました。 他のクエリ パラメーターが含まれている場合に発生するエラーを回避するために、他の状態値をチェックし、見つかった場合は「未実装エラー」(...) を返しました。 Table.View ハンドラーからエラーが返されると、M エンジンは操作を折りたたむことができないため、代わりにデフォルトのハンドラーにフォールバックする必要があることが通知されます (この場合、行の合計数がカウントされます)。
まず、単体テストを追加します。
// GetRowCount
Fact("Fold $count", 15, Table.RowCount(Airlines)),
/$count パス セグメントからは JSON 結果セットではなく単一の値 (プレーン/テキスト形式) が返されるので、要求を行って結果を処理するために新しい内部関数 (TripPin.Scalar) を追加する必要もあります。
// Similar to TripPin.Feed, but is expecting back a scalar value.
// This function returns the value from the service as plain text.
TripPin.Scalar = (url as text) as text =>
let
_url = Diagnostics.LogValue("TripPin.Scalar url", url),
headers = DefaultRequestHeaders & [
#"Accept" = "text/plain"
],
response = Web.Contents(_url, [ Headers = headers ]),
toText = Text.FromBinary(response)
in
toText;
次に、実装はこの関数を使用します (state 内に他のクエリ パラメーターが見つからない場合)。
GetRowCount = () as number =>
if (Record.FieldCount(Record.RemoveFields(state, {"Url", "Entity", "Schema"}, MissingField.Ignore)) > 0) then
...
else
let
newState = state & [ RowCountOnly = true ],
finalUrl = CalculateUrl(newState),
value = TripPin.Scalar(finalUrl),
converted = Number.FromText(value)
in
converted,
CalculateUrl 関数は、state に RowCountOnly フィールドが設定されている場合は URL に /$count を追加するように更新されています。
// Check for $count. If all we want is a row count,
// then we add /$count to the path value (following the entity name).
urlWithRowCount =
if (state[RowCountOnly]? = true) then
urlWithEntity & "/$count"
else
urlWithEntity,
これで、新しい Table.RowCount 単体テストは合格するようになるはずです。
フォールバックのケースをテストするには、強制的にエラーにする別のテストを追加します。
まず、フォールディング エラーに対する try 操作の結果を調べるヘルパー メソッドを追加します。
// Returns true if there is a folding error, or the original record (for logging purposes) if not.
Test.IsFoldingError = (tryResult as record) =>
if ( tryResult[HasError]? = true and tryResult[Error][Message] = "We couldn't fold the expression to the data source. Please try a simpler expression.") then
true
else
tryResult;
次に、Table.RowCountとTable.FirstNの両方を使用してエラーを強制するテストを追加します。
// test will fail if "Fail on Folding Error" is set to false
Fact("Fold $count + $top *error*", true, Test.IsFoldingError(try Table.RowCount(Table.FirstN(Airlines, 3)))),
ここで重要な点は、「フォールディング エラー時のエラー」が false に設定されている場合、Table.RowCount 操作がローカル (デフォルト) ハンドラーにフォールバックするため、このテストではエラーが返されるようになったということです。 [折りたたみエラー時のエラー] を true に設定してテストを実行すると、Table.RowCount は失敗し、テストは成功します。
まとめ
コネクタに Table.Viewを実装すると、コードが大幅に複雑になります。 M エンジンはすべての変換をローカルで処理できるため、Table.Viewハンドラーを追加してもユーザーに新しいシナリオが有効になるわけではありませんが、より効率的な処理 (ユーザーの満足度が向上する可能性) が得られます。 Table.Viewハンドラーがオプションであることの主な利点の 1 つは、コネクタの下位互換性に影響を与えることなく、新しい機能を段階的に追加できることです。
ほとんどのコネクタでは、返される行数を制限するため、実装する重要な (そして基本的な) ハンドラーは OnTake (OData では $top に変換されます) です。 Power Query エクスペリエンスでは、ナビゲーターやクエリ エディターでプレビューを表示するときに常に OnTake 行の 1000 が実行されるため、ユーザーは大規模なデータ セットを操作するときにパフォーマンスが大幅に向上する可能性があります。