データ、ワークロード、アプリケーションを、Azure Data Lake Storage Gen1 から Azure Data Lake Storage Gen2 に移行することができます。 この記事では、推奨される移行方法について説明し、さまざまな移行パターンと、それぞれを使用するタイミングについて説明します。 この記事では、読みやすくするために、 Gen1 という用語を使用して Azure Data Lake Storage Gen1 を参照し、 Gen2 という用語を使用して Azure Data Lake Storage Gen2 を参照します。
注
Azure Data Lake Storage Gen1 は廃止されました。 提供終了のお知らせ については、こちらをご覧ください。Data Lake Storage Gen1 リソースにアクセスできなくなりました。
Azure Data Lake Storage Gen2 は Azure Blob Storage 上に構築されており、ビッグ データ分析専用の一連の機能を提供します。 Data Lake Storage Gen2 は、ファイル システムセマンティクス、ディレクトリ、ファイル レベルのセキュリティなどの Azure Data Lake Storage Gen1 の機能と、低コストの階層化ストレージ、Azure Blob Storage の高可用性/ディザスター リカバリー機能を備えたスケーリングを組み合わせた機能です。
注
Gen1 と Gen2 は異なるサービスであり、インプレース アップグレードのエクスペリエンスはありません。 Azure portal を使用して Gen2 への移行を簡略化するには、Azure portal を 使用して Gen1 から Gen2 に Azure Data Lake Storage を移行する方法に関するページを参照してください。
推奨される方法
Gen1 から Gen2 に移行するには、次の方法が推奨されます。
手順 1:適応性を評価する
手順 2:移行を準備する
手順 3: データとアプリケーション ワークロードを移行する
手順 4:Gen1 から Gen2 に切り替える
手順 1:適応性を評価する
Data Lake Storage Gen2 オファリングについて説明します。その利点、コスト、および一般的なアーキテクチャ。
Gen1 の機能と Gen2 の機能を比較します。
既知の問題の一覧を確認して、機能のギャップを評価します。
Gen2 では、 診断ログ、 アクセス層、 Blob Storage ライフサイクル管理ポリシーなどの Blob Storage 機能がサポートされています。 これらの機能のいずれかを使用する場合は、 現在のサポート レベルを確認してください。
Azure エコシステムサポートの現在の状態を確認して、ソリューションが依存するすべてのサービスが Gen2 でサポートされていることを確認します。
手順 2:移行を準備する
移行するデータ セットを明らかにします。
この機会を利用して、使用しなくなったデータセットをクリーンアップします。 すべてのデータを一度に移行することを計画しているのでない限り、この時間を使って、段階的に移行できるデータの論理グループを明らかにします。
Gen1 アカウントで エージング分析 (または類似) を実行して、インベントリに長期間留まっているファイルやフォルダー、または古くなっている可能性があるファイルやフォルダーを特定します。
移行がビジネスに与える影響を決定します。
たとえば、移行の実行中にダウンタイムを許容できるかどうかを検討します。 これらの考慮事項は、適切な移行パターンを特定し、最適なツールを選択するのに役立ちます。
移行計画を作成します。
これらの 移行パターンをお勧めします。 これらのパターンのいずれかを選択するか、これらを組み合わせるか、独自のカスタム パターンを設計することができます。
手順 3:データ、ワークロード、アプリケーションを移行する
好みのパターンを使用して、データ、ワークロード、アプリケーションを移行します。 シナリオを段階的に検証することをお勧めします。
ストレージ アカウントを作成 し、階層型名前空間機能を有効にします。
データを移行します。
Gen2 エンドポイントを指すように ワークロード内のサービス を構成します。
HDInsight クラスターの場合は、%HADOOP_HOME%/conf/core-site.xml ファイルにストレージ アカウントの構成設定を追加できます。 外部 Hive テーブルを Gen1 から Gen2 に移行する場合は、ストレージ アカウント設定を %HIVE_CONF_DIR%/hive-site.xml ファイルにも追加してください。
Apache Ambari を使用して、各ファイルの設定を変更できます。 ストレージ アカウントの設定については、「 Hadoop Azure サポート: ABFS — Azure Data Lake Storage Gen2」を参照してください。 この例では、 設定
fs.azure.account.keyを使用して、共有キーの承認を有効にします。<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>Gen2 を使用するように HDInsight、Azure Databricks、およびその他の Azure サービスを構成するのに役立つ記事へのリンクについては、 Azure Data Lake Storage Gen2 をサポートする Azure サービスを参照してください。
Gen2 API を使用するようにアプリケーションを更新します。 これらのガイドを参照してください。
| 環境 | [アーティクル] |
|---|---|
| Azure 記憶域エクスプローラー | Azure Storage Explorer を使用して Azure Data Lake Storage Gen2 のディレクトリとファイルを管理する |
| .NET | .NET を使用して Azure Data Lake Storage Gen2 のディレクトリとファイルを管理する |
| ジャワ | Java を使用して Azure Data Lake Storage Gen2 のディレクトリとファイルを管理する |
| Python(プログラミング言語) | Python を使用して Azure Data Lake Storage Gen2 のディレクトリとファイルを管理する |
| JavaScript (Node.js)JavaScript (Node.js) | Node.js で JavaScript SDK を使用して Azure Data Lake Storage Gen2 のディレクトリとファイルを管理する |
| REST API | Azure Data Lake Store REST API |
Data Lake Storage Gen2 PowerShell コマンドレットと Azure CLI コマンドを使用するようにスクリプトを更新します。
コード ファイル、Databricks ノートブック、Apache Hive HQL ファイル、またはワークロードの一部として使用されるその他のファイルで、文字列
adl://が含まれる URI 参照を検索します。 これらの参照を、新しいストレージ アカウントの Gen2 形式の URI に 置き換えます。 たとえば、Gen1 の URIadl://mydatalakestore.azuredatalakestore.net/mydirectory/myfileは、abfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfileになる可能性があります。Azure ロール、ファイルとフォルダー レベルのセキュリティ、Azure Storage のファイアウォールと仮想ネットワークを含むように、アカウントのセキュリティを構成します。
手順 4:Gen1 から Gen2 に切り替える
Gen2 でアプリケーションとワークロードが安定していることを確認したら、Gen2 を使用してビジネス シナリオを満たすことができます。 Gen1 で実行されている残りのパイプラインをオフにし、Gen1 アカウントの使用を停止します。
Gen1 と Gen2 の機能の比較
次の表は、Gen1 の機能と Gen2 の機能を比較したものです。
| 領域 | 第1世代 | Gen2 |
|---|---|---|
| データの編成 |
階層型名前空間 ファイルとフォルダーのサポート |
階層型名前空間 コンテナー、ファイル、フォルダーのサポート |
| geo 冗長 | LRS | LRS、 ZRS、 GRS、 RA-GRS |
| 認証 |
Microsoft Entra マネージド ID サービス プリンシパル |
Microsoft Entra マネージド ID サービス プリンシパル Shared Access Key |
| 承認 | 管理 - Azure RBAC データ - ACLs |
管理 - Azure RBAC データ - ACL、 Azure RBAC |
| 暗号化 - 保存データ | サーバー側 - Microsoft が管理 するキーまたは カスタマー マネージド キーを 使用する | サーバー側 - Microsoft が管理 するキーまたは カスタマー マネージド キーを 使用する |
| VNET のサポート | VNET 統合 | サービス エンドポイント、 プライベート エンドポイント |
| 開発者エクスペリエンス | REST, .NET, Java, Python, PowerShell, Azure CLI | 一般提供 - REST、 .NET、 Java、 Python パブリック プレビュー - JavaScript、 PowerShell、 Azure CLI |
| リソース ログ | クラシック ログ Azure Monitor が統合されました |
クラシック ログ - 一般公開 Azure Monitor 統合 - プレビュー |
| エコシステム | HDInsight (3.6)、 Azure Databricks (3.1 以降)、 Azure Synapse Analytics、 ADF | HDInsight (3.6、4.0)、 Azure Databricks (5.1 以降)、 Azure Synapse Analytics、 ADF |
Gen1 から Gen2 へのパターン
移行パターンを選択し、必要に応じてそのパターンを変更します。
| 移行パターン | 詳細 |
|---|---|
| リフトアンドシフト | 最も簡単なパターンです。 データ パイプラインがダウンタイムを許容できる場合に最適です。 |
| 増分コピー | リフトアンドシフトに似ていますが、ダウンタイムは短くなります。 コピーに時間がかかる大量のデータに適しています。 |
| デュアル パイプライン | ダウンタイムをまったく許容できないパイプラインに最適です。 |
| 双方向同期 | デュアル パイプラインに似ていますが、より複雑なパイプラインに適した段階的なアプローチを使用します。 |
各パターンについて詳しく説明します。
リフト アンド シフト パターン
これは最も簡単なパターンです。
Gen1 へのすべての書き込みを停止します。
Gen1 から Gen2 にデータを移動します。 Azure Data Factory または Azure portal を使用することをお勧めします。 ACL はデータと共にコピーします。
インジェスト操作とワークロードで Gen2 をポイントします。
Gen1 の使用を停止します。
リフト アンド シフト移行サンプルのリフト アンド シフト パターンのサンプル コードをご確認ください。
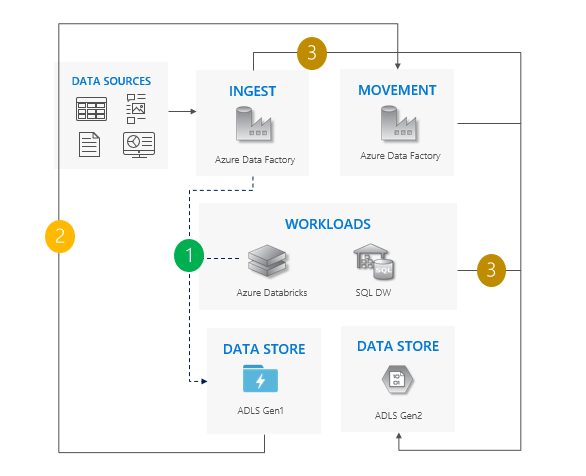
リフト アンド シフト パターンを使用する場合の考慮事項
すべてのワークロードを Gen1 から Gen2 に同時に切り替えます。
移行と切り替えの期間中にダウンタイムが予想されます。
ダウンタイムを許容できるパイプラインに最適であり、すべてのアプリを一度にアップグレードできます。
ヒント
Azure portal を使用してダウンタイムを短縮し、移行を完了するために必要な手順の数を減らすことを検討してください。
増分コピー パターン
Gen1 から Gen2 にデータを移動を始めます。 Azure Data Factory をお勧めします。 ACL はデータと共にコピーします。
Gen1 から新しいデータを増分コピーします。
すべてのデータがコピーされたら、Gen1 へのすべての書き込みを停止し、ワークロードで Gen2 をポイントします。
Gen1 の使用を停止します。
増分コピー移行サンプルにおける増分コピー パターンのサンプルコードをチェックしてください。
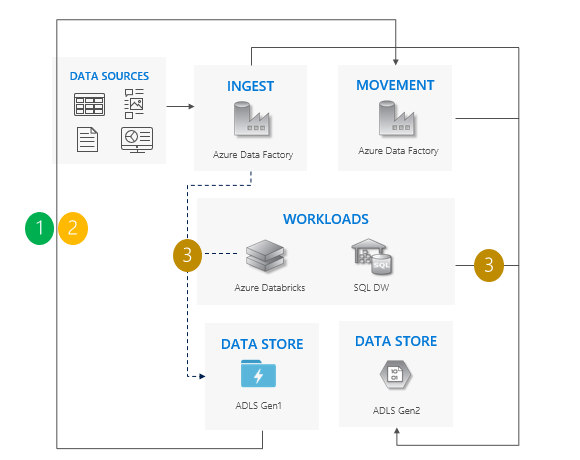
増分コピー パターンを使用する場合の考慮事項:
すべてのワークロードを Gen1 から Gen2 に同時に切り替えます。
切り替え期間中にのみダウンタイムが予想されます。
すべてのアプリが一度にアップグレードされるパイプラインに最適ですが、データのコピーにはより多くの時間が必要です。
デュアル パイプライン パターン
Gen1 から Gen2 にデータを移動します。 Azure Data Factory をお勧めします。 ACL はデータと共にコピーします。
Gen1 と Gen2 の両方に新しいデータを取り込みます。
ワークロードで Gen2 をポイントします。
Gen1 へのすべての書き込みを停止し、Gen1 の使用を停止します。
デュアル パイプライン移行サンプルのデュアル パイプライン パターンのサンプル コードを確認してください。
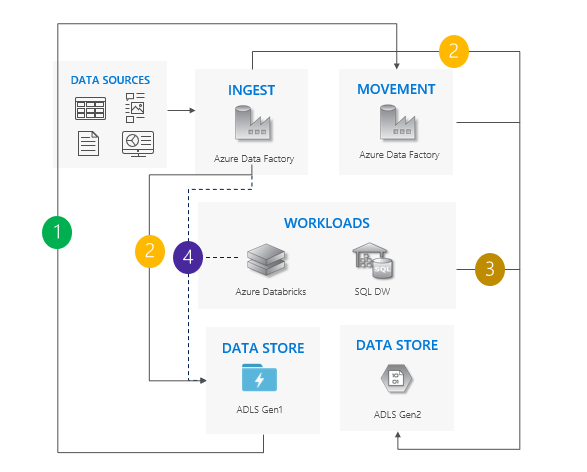
デュアル パイプライン パターンを使用する場合の考慮事項:
Gen1 パイプラインと Gen2 パイプラインがサイドバイサイドで実行されます。
ゼロ ダウンタイムをサポートします。
ワークロードとアプリケーションでダウンタイムを許容できず、両方のストレージ アカウントに取り込むことができる場合に適しています。
双方向同期パターン
Gen1 と Gen2 の間に双方向のレプリケーションを設定します。 WanDisco をお勧めします。 既存のデータに修復機能が提供されます。
すべての移動が完了したら、Gen1 へのすべての書き込みを停止し、双方向レプリケーションをオフにします。
Gen1 の使用を停止します。
双方向同期 移行サンプルの双方向同期パターンのサンプル コードを確認してください。
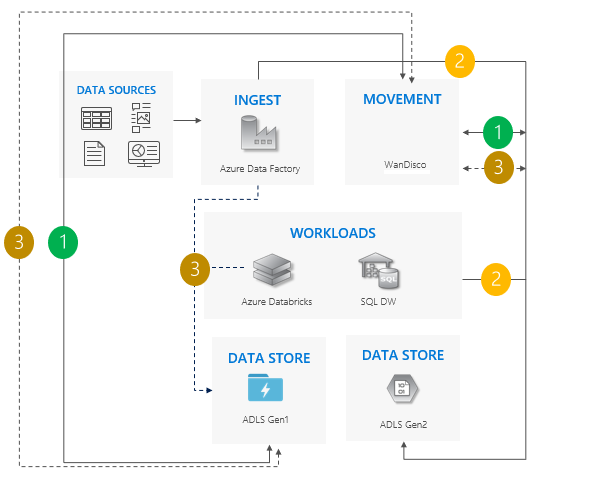
双方向同期パターンを使用する場合の考慮事項:
段階的なアプローチがより効果的な、多数のパイプラインと依存関係が関係する複雑なシナリオに適しています。
移行作業は多くなりますが、Gen1 と Gen2 に対してサイドバイサイドのサポートが提供されます。
次のステップ
- ストレージ アカウントに対するセキュリティの設定のさまざまな部分について学習します。 詳細については、 Azure Storage のセキュリティ ガイドを参照してください。
- Data Lake Store のパフォーマンスを最適化します。 パフォーマンスについては、Azure Data Lake Storage Gen2 の最適化に関するページを参照してください
- Data Lake Store の管理に関するベスト プラクティスを確認します。 Azure Data Lake Storage Gen2 の使用に関するベスト プラクティスを参照してください