重要
データ セキュリティ調査では、organization内のデータの分析に、ジェネレーティブ 人工知能 (AI)、大規模な言語モデル、オーケストレーションが使用されます。 AI によって生成された結果が、常に正確または完全であるとは限りません。 信頼性の高い有用な情報の提供に努めていますが、AI システムは誤った結果や誤った結果を生み出す可能性があります。 情報を確認し、慎重に使用することが重要です。 Microsoft は、AI システムによって提供される情報に関して、明示的、黙示的、または法的な保証を行いません。
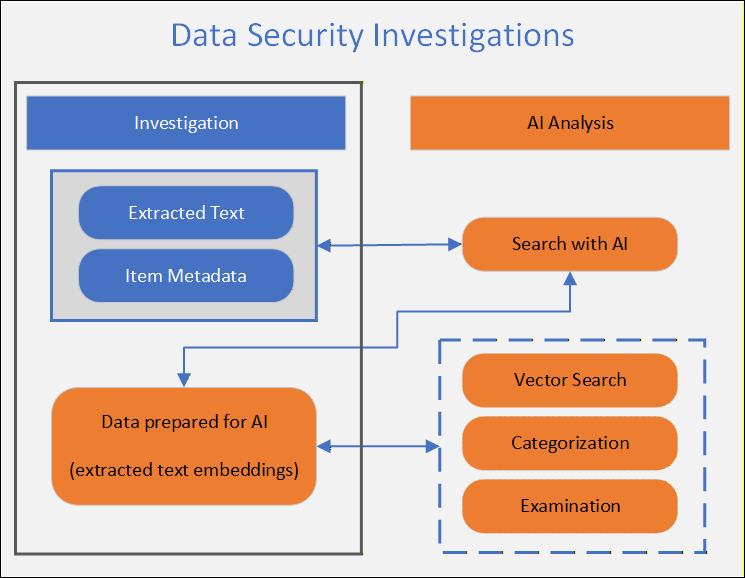
データ セキュリティ調査は、AI サービスとツールを使用して、セキュリティ インシデントに関連する項目をすばやく確認してアクションを実行するのに役立ちます。 AI 関連のサービスには、次のツールが含まれます。
- ベクター検索
- 分類
- 試験
ベクター検索
データ セキュリティ調査のベクター検索を使用すると、高度なオーケストレーションと埋め込みを使用して、調査スコープに追加したデータをコンテキストで検索できます。 ベクター検索は、キーワードを一致するだけでなく、クエリ内の単語やフレーズの背後にある意味とコンテキストを理解することに焦点を当てた検索エンジン テクノロジです。
ベクター検索のいくつかの重要な側面は次のとおりです。
コンテキスト理解: ベクター検索は、organization、検索履歴、クエリの全体的な意味などの要因を考慮して、検索用語のコンテキストを解釈します。
意図認識: ベクター検索は、情報を探しているか、アクションを実行しようとしているか、検索に関連付けられている特定の種類のコンテンツを探しているかに関係なく、意図を理解するために機能します。
関連性と正確性: セマンティクス (クエリ内の単語の意味と意図) に焦点を当てることで、ベクター検索はより正確で関連性の高い結果を提供し、全体的な検索エクスペリエンスを向上させます。
推奨検索 (プレビュー): ベクター検索を使用すると、 調査コンテキストまたは調査 の以前の 検索 に基づいて、カスタマイズされた推奨検索クエリを選択することもできます。 調査にコンテキストが定義されておらず、以前の検索がない場合は、次の既定の推奨検索から選択できます。
- 資格情報またはパスワードを含む何かを探します
- 機密情報を含むすべてのコンテンツを検索する
- すべての法的ドキュメントと財務ドキュメントを一覧表示する
organizationの調査担当者が侵害されたデータ セットを調査する場合、データ セキュリティ調査でのベクター検索は、いくつかの重要な課題に対処することで調査を大幅に強化できます。
- 関連情報の特定: ベクター検索は、クエリの背後にあるコンテキストと意図を理解します。 このフォーカスは、使用した正確なキーワードが含まれていない場合でも、関連するドキュメント、電子メール、またはレコードをすばやく見つけるのに役立ちます。
- あいまいさの処理: ベクター検索では、複数の意味を持つ用語が明確に区別され、調査にコンテキストに応じて適切な結果が得られます。
- ノイズの削減: ベクトル検索は無関係な情報を除外するため、最も関連性の高いデータに焦点を当て、無関係な結果を取り込むのに費やす時間を短縮できます。
- 効率の向上: ベクター検索は検索プロセスを合理化し、最も関連性の高い情報をすばやく表示することで、調査をより効率的かつ効果的にします。
メカニズム
調査を作成し、スコープを定義し、AI 用のデータを準備する場合は、データ セットに対してベクター検索を実行できます。 このプロセスの前の手順では、単純なキーワード (keyword)、メタデータ、日付範囲の検索が可能ですが、ベクター検索では AI 埋め込みを使用して、コンテキストに応じてデータを検索します。 このプロセスにより、調査担当者は正確な内容を知らずにアイテムを見つけることができます。
重要
テキストを含む項目のみがベクター化されます。 画像ファイル、画像のみを含むメール、会議出席依頼、予定表の通知は除外されます。
ベクター検索は、まず、AI 埋め込みモデルを通じて調査でスコープ付きデータをすべて実行することで機能します。 このモデルは、データ セット内のすべての項目からセマンティックな意味を抽出し、小さな部分に分割します。 このプロセスは埋め込みと呼ばれ、データ セキュリティ調査がディメンション値を使用してデータをコンテキストで理解できます。 セマンティック検索インデックスは、クエリを実行できるこれらの値から構築されます。
調査でベクター検索クエリを作成すると、AI によってクエリが自動的に拡張および拡張され、セマンティック検索インデックスを介してクエリが実行されます。 データ セキュリティ調査は、クエリのセマンティックな意味とコンテンツのセマンティックな意味を一致させ、コンテキストに関連するすべての項目を返します。
たとえば、"Contoso Security プロジェクトに含まれる機密データ" を検索すると、ベクター検索エンジンは、検索クエリに含まれるキーワード (機密、データ、Contoso など) を単に照合するのではなく、この特定のプロジェクトで機密データを探していることを認識します。 ベクター検索を使用すると、影響を受けるデータを照会して、キーワードが見つからない場合でも、特定の件名に関連するすべてのデータ項目を検索できます。
さらに、返された各項目に検索関連スコアが自動的に割り当てられます。 検索関連スコアを使用すると、検索とベクター検索によって識別される項目との間の接続の信頼度をすばやく判断できます。
ベクター検索の概念の詳細については、「Azure AI 検索 のベクター」の「概念」セクションを参照してください。
AI を使用した検索 (プレビュー)
ベクター検索を基にして、 AI を使用した検索 (プレビュー) には、取得拡張生成 (RAG) 機能が組み込まれており、検索結果モデルが最適化されます。 この機能には、アイテムのファイルの種類、サイズ、バージョンなどを基にした関連アイテムの検索が含まれます。
ベクター検索へのこの機能拡張には、検索で返された個々の項目に基づく検索の概要も含まれます。これには、特定の検索結果サンプルへの引用リンクなど、検索がニーズを満たしているかどうかを迅速に評価するのに役立ちます。
分類
organizationが侵害され、影響を受けるデータを特定した場合、調査担当者はセキュリティ リスクの特定を開始するためにデータの優先順位を付ける必要があります。 データ セキュリティ調査分類では、重要なデータ セキュリティ リスクに関するコンテンツを自動的にグループ化することで調査が高速化されるため、アナリストは手動によるレビューを行わずに、数千ものファイルを少数の優先順位付けされた意味のあるクラスターに絞り込むことができます。
データ セキュリティ調査でStandardまたは高度な AI を利用した分類を使用して、影響を受ける可能性のあるデータをより迅速に推論し、優先順位を付けることができます。 データを分類するには、すべてまたはいくつかの既定のカテゴリ オプションを選択するか、調査に基づいて AI が推奨するカテゴリを使用するか、独自のカスタム カテゴリを作成します。
また、初期分類の実行が完了した後に、カテゴリを 段階的に追加 することもできます。 新しいカテゴリを追加すると、ネットの新しいカテゴリのみが処理され、以前に分類されたデータが保持されます。 また、Standardと高度な処理レベルの間で既存のカテゴリを変更することもできます。
AI によって生成されたカテゴリは、スコープ内のサブジェクト レベルのコンテンツに関する追加情報でエンリッチされます。
- 名前: コンテンツに基づくカテゴリまたは領域の名前
- 概要: 基になるコンテンツの簡単な説明
各カテゴリ内では、任意のコンテンツでベクター検索および検査ツールを使用できます。
分類でデータを処理する方法
分類は、調査スコープ内のすべての項目を分析するのではなく、選択したカテゴリごとに最も関連性の高いコンテンツを優先順位付けするように設計されています。 分類を実行すると、システムは AI を使用して選択したカテゴリに対してコンテンツを評価し、各コンテンツ セグメントの関連性をスコア付けし、最高の信頼度の結果を保持します。 カテゴリの関連性のしきい値を満たしていないコンテンツは、そのカテゴリの結果には含まれません。
分類は速度とコスト効率のために最適化されているため、次の考慮事項に注意してください。
- 結果は優先順位付けされたコンテンツを表します。分類では、データ セット内のすべての項目を網羅的に分析するものではなく、カテゴリごとに最も関連性の高いコンテンツの優先順位付けされたサブセットが表示されます。
- コンテンツ ボリュームが結果に影響を与える可能性がある: 大規模なデータセットでは、広範なコンテンツを含むドキュメントが結果により強く表現される可能性があります。 関連する項目の一部は、関連性のしきい値を下回ると表示されない場合があります。
- カテゴリは個別に処理されます。選択した各カテゴリは個別に評価されます。 選択したカテゴリの数は処理時間とコンピューティング単位のコストに影響しますが、個々のカテゴリに対する関連性の決定方法は変更されません。
Standard分類を選択すると、関連度スコアリングに基づいてコンテンツが選択したカテゴリにグループ化されます。 [高度な分類] を選択すると、追加の処理が実行され、各カテゴリ内の特定のトピックにコンテンツが識別および整理され、より詳細なグループ化が提供され、より詳細な分析が可能になります。
ヒント
調査にスコープ内のすべてのコンテンツの包括的な分析が必要な場合は、分類の代わりに、または分類に加えて 調査ツール を使用します。 分類は、大規模なデータセットの優先順位付けとトリアージを迅速に行う場合に最適です。一方、調査では、選択した項目の対象となる項目レベルの分析が提供されます。
既定のカテゴリ
データ セキュリティ調査には、調査スコープ内の項目を分類するための既定のカテゴリが含まれています。 分類を実行するときに、すべての既定のカテゴリ、またはレビューのスコープに適用される既定のカテゴリのみを選択できます。 この分析では、選択されていない既定のカテゴリは無視され、これらのカテゴリの結果を確認することはできません。
AI 処理は、コンテンツ 項目の最初の既定のカテゴリを決定します。
- ビジネス情報: 一般的なビジネス情報。 通常、このカテゴリには多数の項目が含まれています。 このカテゴリの領域の例としては、デジタル エンゲージメントと分析、ユーザーと人事、日常的な管理コミュニケーション、顧客エンゲージメント/エクスペリエンスなどがあります。
- 通信レコード: 一般的な通信情報。 このカテゴリには、通常、多数の項目が含まれています。 このカテゴリを使用して、通信領域に基づいて調査を確認します。 このカテゴリの領域の例としては、クライアントの苦情、休日の挨拶、内部メモ、プロジェクトの更新などが含まれます。
- 資格情報とアクセス情報: 調査中の資産へのアクセスに関連する情報。 この情報は、潜在的に危険なデータと、organization内の通信を識別するのに役立ちます。 このカテゴリの領域の例としては、ユーザー資格情報、未承認のデータベース アクセス、データ公開などがあります。
- 顧客情報: 顧客と共有される情報。 このカテゴリを使用して、リスクが発生する可能性のある顧客データを把握します。 このカテゴリの領域の例としては、支払い確認、カスタマー エクスペリエンスの向上、配信情報などがあります。
- ユーザー情報: organization内のユーザーに関連する情報。 このカテゴリには、通常、多数の項目が含まれています。 このカテゴリの領域の例としては、ユーザーの雇用情報、ユーザー保持戦略、特殊なグループ メンバーシップなどが含まれます。
- 財務情報: 調査中の財務情報。 このカテゴリの領域の例としては、財務計画、機会の付与、予算、財務諸表などがあります。
- 健康情報: 調査中の健康および医療関連項目。 このカテゴリの領域の例としては、ウェルネスと健康記録、COVID-19 安全プロトコルの更新、正常性要求とインシデント レポートなどがあります。
- インシデントと調査の情報: 調査におけるインシデントと調査に関する項目。 このカテゴリには、organization内のセキュリティ インシデントと調査が含まれます。 このカテゴリの領域の例としては、データ侵害、正常性レコード インシデント、リスクの高いクライアント アカウントの監視などがあります。
- 知的財産: 調査における知的財産 (IP) データ。 このカテゴリの領域の例としては、将来の特許出願、研究開発作業、実験結果メトリックなどが含まれます。
- マーケティング情報: 調査中のマーケティング データ。 このカテゴリの領域の例としては、プレスリリース、広告キャンペーン、マーケティングおよび販売計画、戦略などがあります。
- 運用情報: organizationの運用データ。 このカテゴリの領域の例としては、物流、出荷、在庫、コンプライアンス、税記録などが含まれます。
- 個人を特定できる情報: 調査で 個人データ と関連項目をグループ化します。 このカテゴリの領域の例としては、イベント ゲスト リスト、スタッフとトレーニング セッション、従業員の個人情報などが含まれます。
- 規制データ: 調査中の規制データ。 このカテゴリの領域の例としては、規制、データ保護、規制レコードなどがあります。
推奨されるカテゴリ
データ セキュリティ調査では、調査範囲で分析されたコンテンツに基づいて、AI によって生成された推奨カテゴリも提供されます。 これらの推奨されるカテゴリは、調査で予期しない領域または不明な領域にグループ化されたアイテムを自動的に確認するのに役立ちます。 含まれるコンテンツの種類に応じて、推奨されるカテゴリは異なります。
分析されたコンテンツが主に既定のカテゴリ領域以外の特定のサブジェクト領域に焦点を当てている場合、推奨されるカテゴリはその特定のコンテンツ領域に合わせてカスタマイズされます。 たとえば、分析されたコンテンツが、organizationのみに固有の用語と概念を持つ機密性の高い主題に焦点を当てた場合、これらの領域に対して推奨されるカテゴリが自動的に作成されます。 これらのカテゴリは、organizationと分析されたコンテンツに固有です。
カスタム カテゴリ
データ セキュリティ調査を使用すると、コンテンツを分析するときに使用する生成 AI プロセスのカスタム カテゴリを手動で作成できます。 調査のニーズに最も適したカテゴリを定義することで、時間を節約し、AI プロセスでこれらのカスタム カテゴリに基づいて項目を自動的に分類できます。
カスタム カテゴリには、調査中に関心のあるコンテンツの特定の性質をキャプチャする特定の単語またはフレーズを指定できます。 たとえば、カスタム カテゴリには、 セキュリティの脆弱性、 バグ修正、特定のプロジェクト コード名、または特定の医薬品や医薬品候補に関連する R&D などのカスタム知的財産が含まれる場合があります。
調査に役立つ可能性のある追加のカスタム カテゴリ:
- アクセス コード
- API アクセスに関するドキュメント
- API 認証キー
- API トークン
- アプリケーション構成ファイル
- 証明機関 (CA) の詳細
- 証明書
- データベース資格情報
- デジタル証明書
- ディザスター リカバリー計画
- 従業員の場所データ
- 暗号化キー
- 環境構成ファイル
- インシデント管理ログ
- 統合トークン
- JWT トークン
- キー管理ポリシー
- 多要素認証 (MFA) バックアップ コード
- 個人識別番号 (PIN)
- 特権アカウントの詳細
- セキュリティで保護された文字列
- セキュリティ ログ
- セキュリティ ポリシー
- セッション
- SSH 秘密キー
- サード パーティ製 API シークレット
- ユーザー資格情報
- 脆弱性評価
試験
より詳細な分析が必要な項目を特定する際に、データ セキュリティ調査は、主要なセキュリティと機密データリスクに焦点を当てるのに役立つ AI ベースの調査機能を提供します。
資格情報: この調査対象領域を使用して、調査スコープ内の選択したすべての項目から資格情報をスキャンして抽出します。 この情報を使用すると、調査担当者は、セキュリティ インシデントに関連付けられているアカウントと資格情報を簡単に把握でき、それが流出する可能性があります。
リスク: 調査担当者が調査に集中し、優先順位を付けるのに役立つ、選択したファイル内のすべてのリスク領域をスコア付けするには、この調査対象領域を使用します。 このツールは、アイテムが特権コンテンツである場合、アイテムごとの全体的なリスクと、そのアイテムに対するその他の特定のリスクを提供します。
リスク領域の種類は次のとおりです。
- 資産識別子
- 資格情報とシークレット
- 脅威アクターと侵害の議論の証拠
- 緊急のセキュリティ インシデント
- 脆弱性とセキュリティの検疫
- 個人用および機密性の高いコンテンツ
- ネットワークとアクセスの情報
- ポリシーコンプライアンスとデータ保護
- インフラストラクチャの情報
- カスタマー情報
- 政府機関向け情報
- 特権情報
- 企業秘密
軽減策: この調査の重点領域を使用して、選択したファイルのリスクをスコア付けし、データ セキュリティ調査が次に何を行うかの軽減手順を提供できるようにします。 選択したファイルは、リスク スコア、リスクの概要、詳細な軽減策の推奨事項を取得して、コンテンツの侵害によるより多くの損害を防ぎます。
個人データ: この調査対象領域を使用して、調査範囲内の選択した項目から 個人データ を特定して抽出します。 この情報により、調査担当者は、名前、電子メール アドレス、従業員 ID、IP アドレス、その他の PII など、セキュリティ インシデントに関連するデータに存在する個人データの種類を簡単に把握できます。
AI 分析の推奨事項
次の表は、データ セキュリティ調査で AI 分析ツールを使用するときの推奨事項、シナリオ例、ベスト プラクティスの概要を示しています。
| 推奨事項 | ベクター検索 | 分類 | 試験 |
|---|---|---|---|
| いつ使用するか | ベクトル化されたデータ セット内の特定の項目 (請求書、バグ修正など) の例を探して、仮説を確認し、さらに調査します。 ベクター検索を使用して迅速な対話型分析を行い、結果をすばやく入力します。 |
機密性と重大度によって、既定、カスタム、または AI によって生成されるカテゴリに大量のデータをすばやく優先順位付けします。 分類では、すべてのアイテムを分析するのではなく、カテゴリごとに最も関連性の高いコンテンツが表示されます。 データ セットのサイズによっては、分類が完了するまでに時間がかかる場合があります。 |
選択したすべてのデータ項目の項目レベルでの包括的なターゲット分析。 次の手順で確認されたデータ資産から詳細な分析情報を抽出するのに役立ちます。 調査を使用して、軽減策の項目を特定します。 |
| シナリオ例 | 不正行為の可能性の評価。 | 大規模な侵害後の分析のための項目の優先順位付け。 | 検証済みのデータ セットと推奨される軽減手順からの資格情報と個人データの抽出。 |
| 分析スコープ | 調査スコープ内のすべてのベクター化されたコンテンツ。 | 選択したカテゴリごとに最も関連性の高いコンテンツの優先順位付けされたサブセット。 | 調査スコープ内で選択されたすべての項目。 |
| ベスト プラクティス | ベクター化されたすべてのコンテンツで関心のある項目を検索して、より意味のある AI 推奨カテゴリを生成します。 | 1 つまたは複数のカテゴリを選択し、ベクトル検索を使用してカテゴリ内を検索します。 各カテゴリ内の AI によって生成された領域を確認して、データ セット内の特定のコンテンツを理解します。 |
検査を使用して、高い感度で特定の項目にドリルインして、個々のスコアと結果を取得します。 |