オンプレミス データ ソースのMicrosoft Purview データ品質を使用すると、組織はデータベースやレガシ プラットフォームなどの内部システムに格納されているデータの品質を評価、監視、および改善できます。 ルールベースの検証、エラー検出、修復ワークフローをサポートしながら、組織のポリシーへの準拠を確保します。 既存のインフラストラクチャと統合することで、オンプレミス環境とクラウド環境の両方で一貫したデータ品質の分析情報とガバナンスを提供します。
セルフホステッド データ統合ランタイムを使用すると、オンプレミスのデータ ソースを Purview に安全に接続することで、データ品質プロセスをスケーリングできます。 この記事では、Kubernetes ベースのLinuxセルフホステッド データ統合ランタイムについて説明します。これにより、基になるインフラストラクチャが強化され、いくつかの重要な利点が提供されます。
- スケーラビリティ: 数百台のマシンにスケーリングする機能。
- パフォーマンス: ワークロードのスキャンのパフォーマンスが向上しました。
- セキュリティ (コンテナー化): Kubernetes クラスターでのコンテナー化されたデプロイを有効にし、Windows マシンでデータ統合ランタイムを直接ホストする必要がなくなります。
サポートされているデータ ソース
- Oracle
- SQL Server
アーキテクチャ
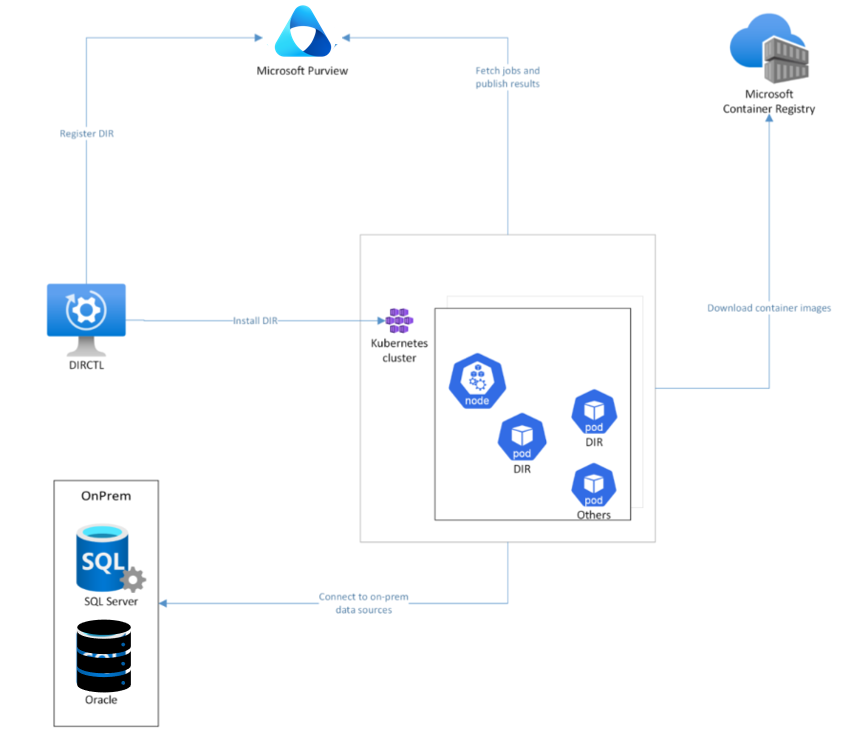
概要のアーキテクチャ ビューでは、Kubernetes ベースのデータ統合ランタイムをインストールすると、Kubernetes クラスターのノードに対して複数のポッドが自動作成されます。 DIRCTL という名前のコマンド ライン ツールによって、このインストールがトリガーされます。 DIRCTL は Microsoft Purview Service に接続してデータ統合ランタイムを登録し、Kubernetes クラスターに接続してセルフホステッド データ統合ランタイムをインストールします。
インストール中に、プロセスは MCR (Microsoft Container Registries) からデータ統合ランタイム ポッドにデータ統合ランタイム イメージをダウンロードします。 インストールが完了すると、クラスター内のポッドが Purview サービスに接続してスキャン ジョブをプルします。 スキャン ジョブがプルされると、オンプレミスのデータ ソースを接続してデータ品質スキャンを行うことができます。
前提条件
Data Integration ランタイム コマンド ライン ツール (DIRCTL)
データ統合ランタイムを設定するには、Data Integration ランタイム コマンド ライン ツール (DIRCTL) が必要です。 ダウンロードとインストールの手順については、「 セルフホステッド統合ランタイム用の DIRCTL ツールのセットアップ (プレビュー)」を参照してください。
役割
Purview でセルフホステッド統合ランタイムを設定するには、データ ガバナンス管理者ロールが必要です。
Kubernetes クラスター
既存のLinuxベースの Kubernetes クラスターが必要です。または、クラスターを準備する必要があります。 Kubernetes ノード セレクターの定義に従うノード セレクターを使用してノードを識別します。 最小構成:
- コンテナーの種類: Linux
- Kubernetes バージョン: 1.24.9 以降
- ノード OS: x86 アーキテクチャで実行されているLinux ベースの OS
- ノード スペック: 最小 8 コア CPU、32 GB メモリ、少なくとも 80 GB の使用可能なハード ディスク領域
- ノード数: 1 つ以上 (固定、有効になっていないクラスター自動スケーラー)
- ノードあたりのポッド数: 20 以上 (最大ポッド数 - Self-Hosted IR に属していない他のポッドの数)
注:
各ノードのフォルダー /var/irstorage/ は、セルフホステッド統合ランタイム用に予約されています。 読み取り可能で、データ統合ランタイムに書き込み可能です。 このフォルダーからログを取得することも、外部ドライバーをこのフォルダーにアップロードすることもできます。 データ統合ランタイムは、存在しない場合はフォルダーを作成し、データ統合ランタイムが削除された後はフォルダーを削除しません。 データ統合ランタイムによって使用されるコンテナー イメージは 、Kubernetes ガベージ コレクションによって管理されます。これは、データ統合ランタイムによってクリーンアップされません。 Kubernetes クラスターの適切なしきい値を構成します。
送信接続は、コンテナー イメージを取り込むだけでなく、データ品質ジョブのプルや生成された統計のプッシュなどのアクティビティを含む、さらなる操作のために必要です。
Kubernetes コンテキスト
Kubernetes クラスターと通信するには、Kubernetes クラスター情報と、このクラスターのユーザーのアクセス許可と資格情報を含む Kubernetes コンテキストが必要です。 DIR 管理に対するユーザーのアクセス許可の構成を簡単にするには、Kubernetes 管理 ロールから始めることができます。 このコンテキストは、Kubernetes クラスターのセットアップで生成され、構成ファイルに保存されます。 このファイルを取得する場所と方法は、Kubernetes クラスターの設定によって異なります。
kubeadm init を使用して Kubernetes クラスターを設定する場合は、[
/etc/Kubernetes/admin.conf] の下に構成ファイルがあります。AKS を使用する場合は、AKS のガイダンスに従って、Az PowerShell モジュール コマンドを使用して、このクラスターの資格情報をローカル コンピューターに取得できます。 コンテキストは、
$HOME/.kube/configの下の構成ファイルに直接マージできます。他のツールを使用して Kubernetes クラスターを設定している場合は、 Kubernetes のドキュメントを参照してください。
Kubernetes コンテキストの構成ファイルを取得したら、IRCTL コマンドを実行するコンピューター上の構成ファイル
$HOME/.kube/configにマージします。 または、kubernetes コンテキストの構成ファイルを、KUBECONFIGという名前の環境変数で設定することもできます。 Kubernetes コンテキストの詳細については、 複数のクラスターへのアクセスを構成する方法に関するページを参照してください。
セルフホステッド データ統合ランタイムを設定する
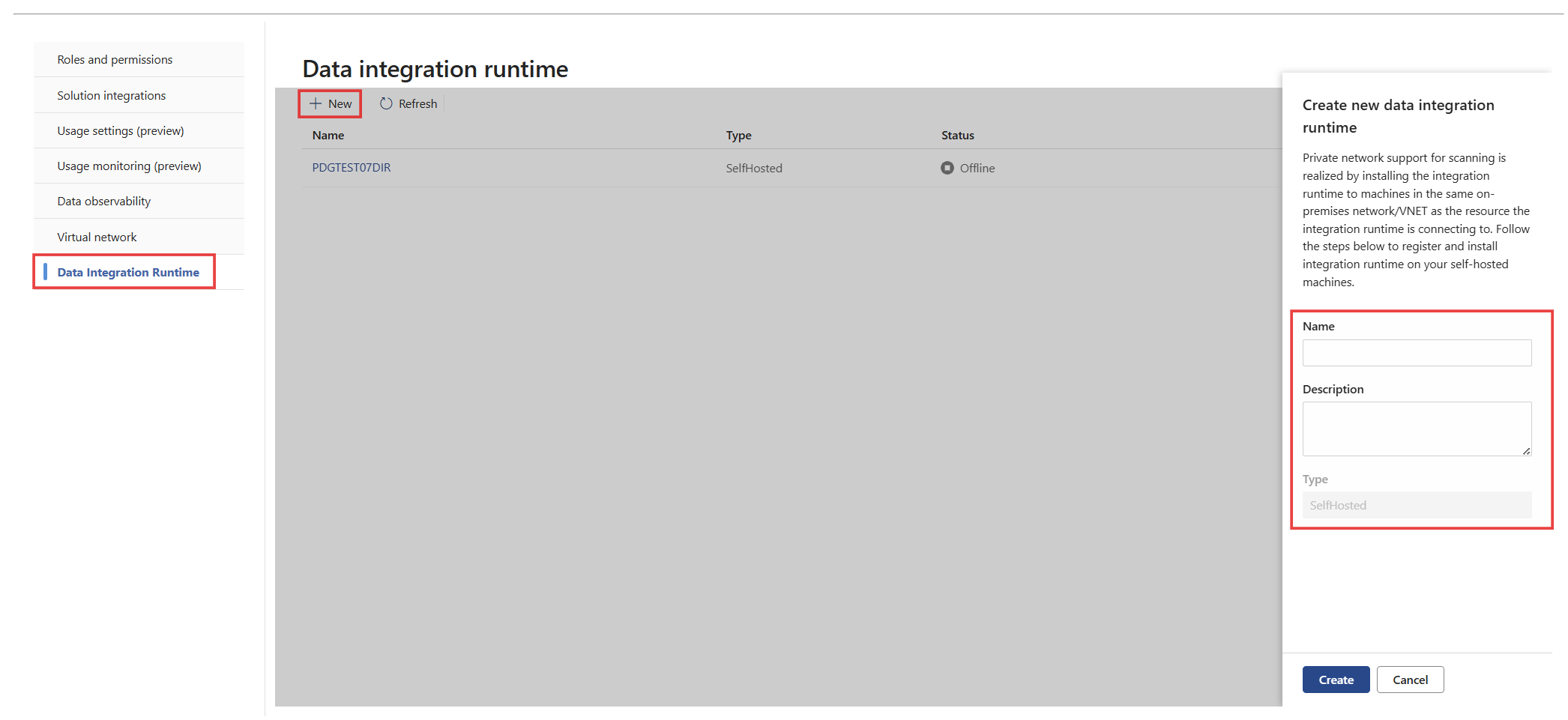
[設定>Microsoft Purview 統合カタログ>Data Integration ランタイム] に移動し、[新規] を選択してデータ統合ランタイムを作成します。
セルフホステッド統合ランタイムの [名前] と [説明] を入力し、[ 作成] を選択します。
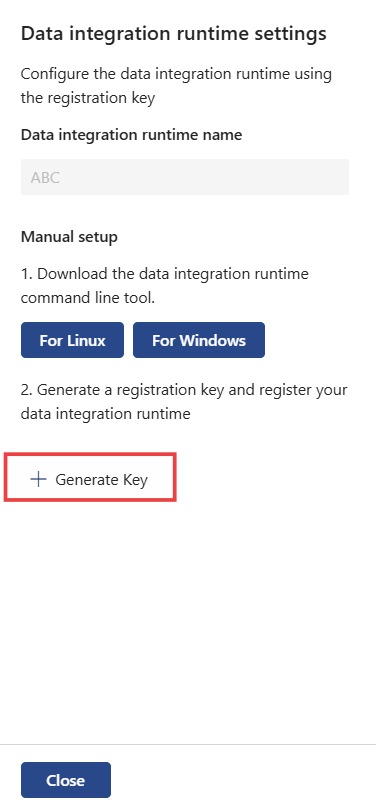
[ キーの生成] を選択して登録キーを生成し、データ統合ランタイムを登録します。
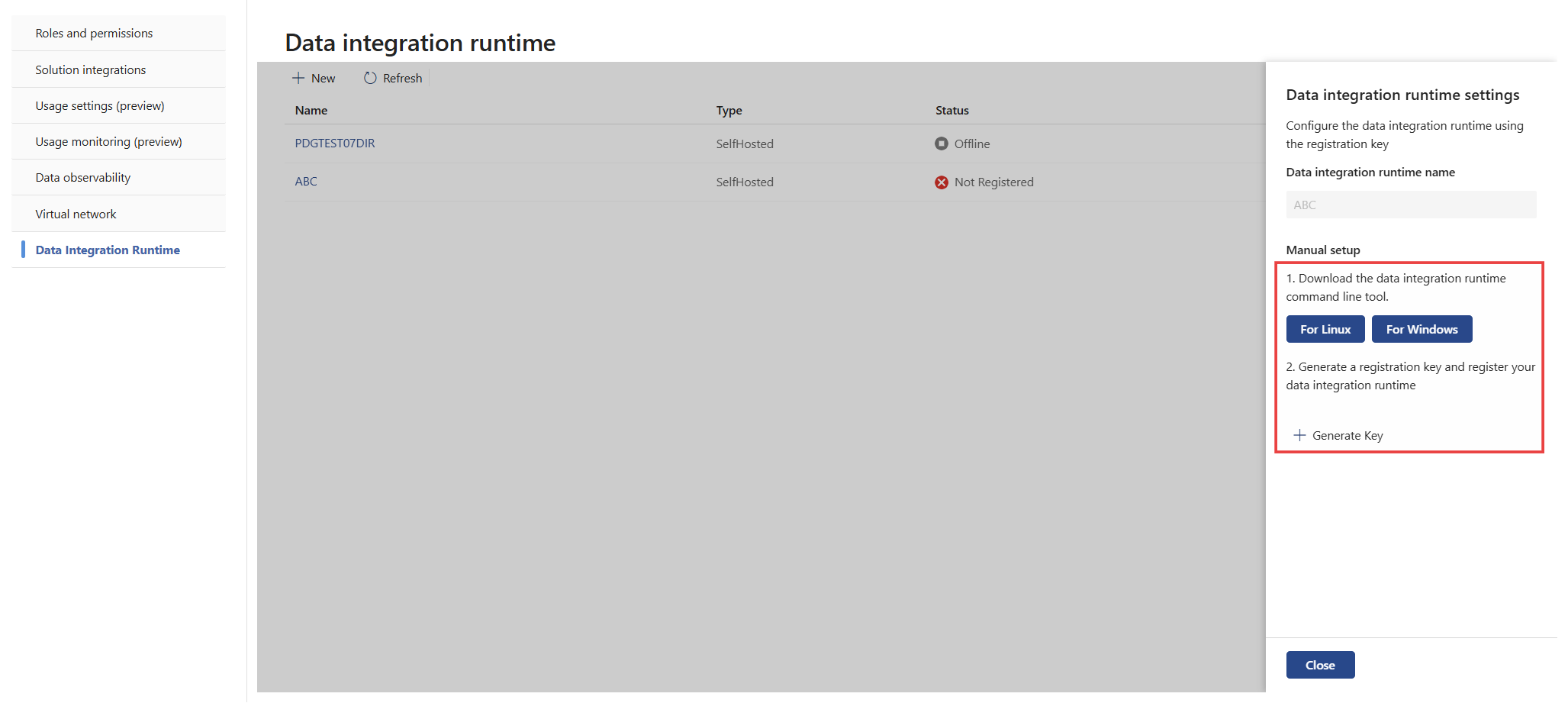
キー値をコピーし、[ 完了] を選択します。
ヒント
必要に応じて、キーを再生成するか、生成されたキーを取り消すことができます。
[Linux] を選択して、Data Integration ランタイム コマンド ライン (DIRCTL) ツールをダウンロードします。 DIRCTL をインストールして管理する方法の詳細を取得します。
DIRCTL コマンド ラインを実行するコンピューターで、ダウンロードから DIRCTL をインストールします。 DIRCTL は、Kube 構成のコンテキストによって Kubernetes クラスターに接続します。コンテキストを指定しない場合、DIRCTL は現在のコンテキストを使用します。 コンテキストは、次の 2 つの方法のいずれかで設定できます。
- コマンド ライン
kubectl実行し、次のコマンドを実行して現在のコンテキストを確認します。-
kubectl config get-contexts: マシンで構成されているすべてのコンテキストを一覧表示します -
kubectl config current-context: 現在のコンテキスト名を取得します kubectl config use-context <name of context>
-
- DIRCTL を実行し、
-contextを実行して Kube 構成でコンテキストを指定します。
- コマンド ライン
DIRCTL Create コマンドを実行します:
./DIRCTL create - -registration-key <registration-key copied from the portal>。 DIRCTL Create コマンドは、新しいデータ統合ランタイムを Data Quality に登録し、登録されたデータ統合ランタイムに固有のポッドとして Kubernetes でアプリケーションの作成を開始します。 既存のシステム要件との互換性を維持しながら、データ統合ランタイム機能に不可欠なリソースと構成のプロビジョニングを処理します。
登録が完了すると、[設定] の [Data Integration ランタイム] ページでデータ統合ランタイムの状態をチェックできます。 状態は [オンライン] と表示されます。
./DIRCTL describeコマンドを実行して、データ統合ランタイムの状態をチェックすることもできます。
ヒント
データ統合ランタイムが接続するパブリック エンドポイントのうち、許可する必要があるパブリック エンドポイントを次に示します。
- <purview_account_name>.purview.azure.com
- Mcr.microsoft.com
- *.data.mcr.microsoft.com
データ統合ランタイムを使用したオンプレミス データ ソース接続の設定
Oracle データベースに接続する
接続をデータ統合ランタイム インスタンスに関連付けることによって作成します。
- 統合カタログで、[正常性管理>データ品質] に移動します。
- Oracle データ資産を使用してデータ製品を作成したガバナンス ドメインを選択します。
- [ 管理] を選択し、[ 接続 ] を選択して Oracle データベースの接続を設定します。
次の情報を追加して、接続を設定します。
- 接続の 表示名 を入力します。
- [説明] を入力します。
- [ソースの種類] で、[Oracle] を選択します。
- 前提条件の一部として作成した データ統合ランタイム を選択します。
- ホスト名を入力します。
- ポート番号を入力します。
- サービス名を入力します。
- スキーマ名を入力します。
- 認証方法を選択します。
- [ユーザー名] を入力します。
- [資格情報] で、Azure サブスクリプション、Azure Key Vault接続、シークレット名、シークレット バージョンを入力します。
- [ 送信] を 選択して、接続のセットアップを完了します。
ヒント
必要な情報がすべてない場合は、[ 下書きとして保存] を選択し、残りの情報がある場合は後で続行して接続のセットアップを完了します。
次の図は、接続を作成する方法を示しています。
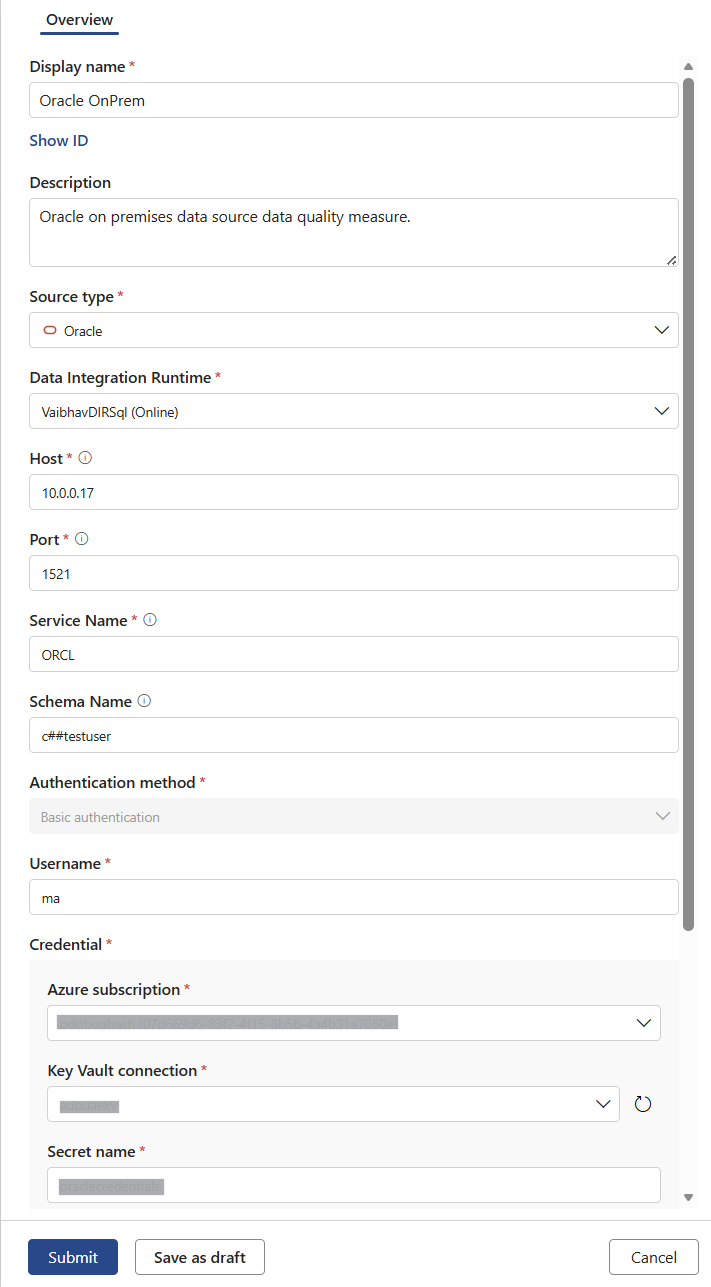
SQL Server データベースに接続する
Oracle の場合と同様に、接続をデータ統合ランタイム インスタンスに関連付けることによって接続を作成します。 SQL Serverでは、1 つのデータベースに複数のスキーマに属するテーブルを含めることができるため、1 つの接続を使用して 1 つのデータベース内のすべてのスキーマをスキャンできます。 接続はデータベース情報のみを受け入れますが、スキーマは受け入れません。 他のデータ ソースの種類と同じように、SQL Serverの接続を作成します。
- 統合カタログで、[正常性管理>データ品質] に移動します。
- Oracle データ資産を使用してデータ製品を作成したガバナンス ドメインを選択します。
- [ 管理] を選択し、[ 接続 ] を選択して Oracle データベースの接続を設定します。
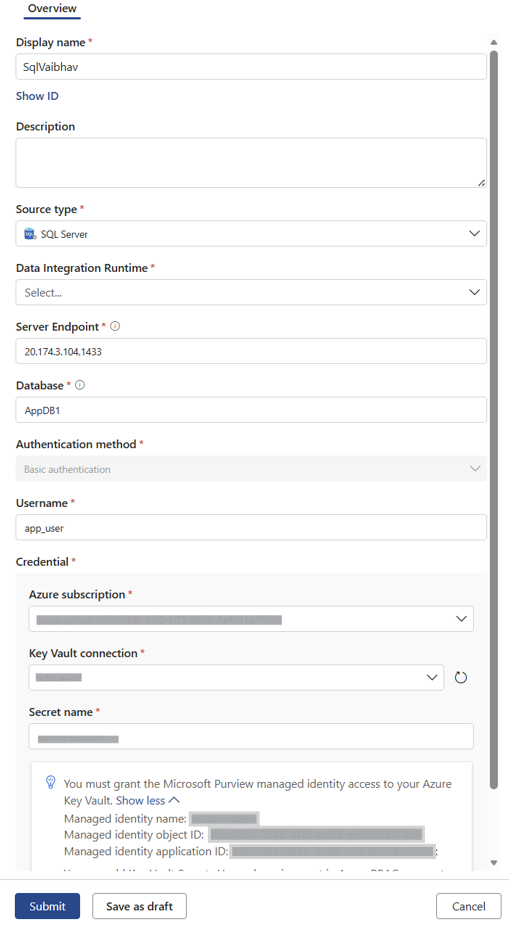
接続を正常に設定するには、次の情報を追加します。
- 接続の 表示名 を入力します。
- [説明] を入力します。
- [ソースの種類]で、[SQL Server] を選択します。
- 前提条件の一部として作成した データ統合ランタイム を選択します。
- サーバー エンドポイントを入力します。
- [データベース名] を入力します。
- 認証方法を選択します。
- [ユーザー名] を入力します。
- [資格情報] で、Azure サブスクリプション、Azure Key Vault接続、シークレット名を入力します。
- [ 送信] を 選択して、接続のセットアップを完了します。
ヒント
必要な情報がすべてない場合は、[ 下書きとして保存] を選択し、残りの情報がある場合は後で続行して接続のセットアップを完了します。
次の図は、接続を作成する方法を示しています。
データ品質スキャン
接続のセットアップが完了したら、データ品質プロファイルとスキャン ドキュメントに従って、Oracle とオンプレミスのデータ ソースのデータ品質SQL Server測定および監視します。
高可用性とスケーラビリティ
Kubernetes でサポートされているセルフホステッド統合ランタイムのインストール中にノード セレクターを使用して、高可用性のために Kubernetes クラスター内の複数のノードを割り当てます。 複数のノードを使用する利点は次のとおりです。
セルフホステッド統合ランタイムの可用性が高まるため、スキャンの単一障害点ではありません。
より多くの同時実行スキャン。 各ノードは、多数のスキャン実行を同時に処理できます。 より多くの同時スキャンが必要な場合は、Kubernetes クラスターのノードを手動でスケールアウトできます。
BLOB、Azure Data Lake Storage Gen2、Azure Filesなどの一部のソースAzureスキャンする場合、各スキャン実行で複数のノードを使用してスキャンパフォーマンスを向上させることができます。 その他のソースの場合、スキャンはいずれかのノードでのみ実行されます。
Kubernetes クラスターのノードを手動でスケールアウトまたはスケーリングすることで、Kubernetes でサポートされているセルフホステッド統合ランタイムの機能を更新できます。
注:
スキャンに必要なすべてのドライバーを新しいノードごとにアップロードする必要があります。
ネットワーク要件
| ドメイン名 | 送信ポート | 説明 |
|---|---|---|
パブリック クラウド: <tenantID>-api.purview-service.microsoft.com Azure Government: <tenantID>-api.purview-service.microsoft.us 中国: <tenantID>-api.purview-service.microsoft.cn |
443 | Microsoft Purview サービスに接続するために必要です。 Microsoft Purview プライベート エンドポイントを使用する場合、アカウントプライベート エンドポイントはこのエンドポイントを対象とします。 |
パブリック クラウド: <purview_account>.purview.azure.com Azure Government: <purview_account>.purview.azure.us 中国: <purview_account>.purview.azure.cn |
443 | Microsoft Purview サービスに接続するために必要です。 Microsoft Purview プライベート エンドポイントを使用する場合、アカウントプライベート エンドポイントはこのエンドポイントを対象とします。 |
| mcr.microsoft.com | 443 | イメージをダウンロードするために必要です。 |
| *.data.mcr.microsoft.com | 443 | イメージをダウンロードするために必要です。 |