| マヤーナ ペレイラ | Scott Christiansen |
|---|---|
| CELA データ サイエンス | 顧客のセキュリティと信頼 |
| Microsoft | Microsoft |
抽象 — セキュリティ バグ レポート (SDR) の特定は、ソフトウェア開発のライフサイクルにおける重要なステップです。 教師あり機械学習ベースのアプローチでは、通常、バグ レポート全体をトレーニングに使用でき、ラベルがノイズフリーであると想定します。 私たちの知識の限りでは、これはタイトルのみが利用可能であり、ラベルノイズが存在する場合でも、SBRに対して正確なラベル予測が可能であることを示した初めての研究です。
インデックス用語 — 機械学習、誤ラベル付け、ノイズ、セキュリティ バグ レポート、バグ リポジトリ
I. 紹介
報告されたバグ間でセキュリティ関連の問題を特定することは、ソフトウェア開発チームの間で差し迫ったニーズです。このような問題では、コンプライアンス要件を満たし、ソフトウェアと顧客データの整合性を確保するために、より迅速な修正が必要です。
機械学習と人工知能ツールは、ソフトウェア開発の高速化、アジャイル化、修正を約束します。 複数の研究者が、セキュリティバグを特定する問題に機械学習を適用しました [2], [7], [8], [18].以前に公開された研究では、機械学習モデルのトレーニングとスコア付けにバグ レポート全体を使用できるものとします。 必ずしもそうであるとは限りません。 バグ レポート全体を使用できない場合があります。 たとえば、バグ レポートには、パスワード、個人を識別する情報 (PII)、またはその他の種類の機密データ (現在 Microsoft で直面しているケース) が含まれている場合があります。 そのため、バグ レポートのタイトルのみが使用可能な場合など、より少ない情報を使用して、セキュリティ バグ識別をどの程度適切に実行できるかを確立することが重要です。
さらに、バグ リポジトリには、多くの場合、誤ったラベル付けされたエントリが含まれています [7]: セキュリティ関連として分類されたセキュリティ以外のバグ レポート、またはその逆です。 開発チームのセキュリティに関する専門知識の不足から、特定の問題のあいまいさなど、誤ったラベル付けの発生にはいくつかの理由があります。たとえば、セキュリティへの影響を引き起こす間接的な方法でセキュリティ以外のバグが悪用される可能性があります。 SDR のラベル付けが間違っているため、これは重大な問題です。セキュリティの専門家は、コストと時間のかかる作業でバグ データベースを手動で確認する必要があります。 ノイズがさまざまな分類子に与える影響と、さまざまな種類のノイズで汚染されたデータ セットが存在する場合に、異なる機械学習手法の堅牢性 (または脆弱) を理解することは、ソフトウェア エンジニアリングの実践に自動分類を適用するために対処する必要がある問題です。
予備的な作業では、バグ リポジトリは本質的にノイズが多く、ノイズがパフォーマンス機械学習分類子に悪影響を及ぼす可能性があると主張しています [7]。 ただし、さまざまなレベルと種類のノイズが、セキュリティ バグ レポート (SRB) の特定の問題に対するさまざまな教師あり機械学習アルゴリズムのパフォーマンスに与える影響を体系的かつ定量的に調査することはできません。
この研究では、タイトルのみがトレーニングとスコアリングに使用できる場合でも、バグ レポートの分類を実行できることを示します。 私たちの知識を最大限に活用するために、これはそれを行う最初の仕事です。 また、バグ報告分類におけるノイズの影響に関する最初の体系的な研究を提供します。 クラスに依存しないノイズに対する 3 つの機械学習手法 (ロジスティック回帰、ナイーブ ベイズ、AdaBoost) の堅牢性の比較研究を行います。
いくつかの単純な分類子 [5]、[6] のノイズの一般的な影響をキャプチャする分析モデルがいくつかありますが、これらの結果は精度に対するノイズの影響に厳密な境界を提供せず、特定の機械学習手法に対してのみ有効です。 機械学習モデルにおけるノイズの影響を正確に分析するには、通常、計算実験を実行します。 このような分析は、ソフトウェア測定データ[4]から衛星画像分類[13]、医療データ[12]まで、いくつかのシナリオで行われています。 しかし、これらの結果は、データ セットの性質と基になる分類の問題に対する依存関係が高いため、特定の問題に変換できません。 私たちの知る限り、特にセキュリティバグレポートの分類におけるノイズの多いデータセットの影響に関する公表された結果は存在しません。
私たちの研究への貢献:
レポートのタイトルのみに基づいて、セキュリティ バグ レポート (SDR) を識別するための分類子をトレーニングします。 私たちの知識を最大限に活用するために、これはそれを行う最初の仕事です。 以前の作品では、完全なバグ レポートを使用するか、追加の補完機能を使用してバグ レポートを強化しました。 タイルのみに基づいてバグを分類することは、プライバシーに関する懸念のために完全なバグ レポートを利用できない場合に特に関連します。 たとえば、パスワードやその他の機密データを含むバグ レポートの場合は、悪名高いケースです。
また、SPR の自動分類に使用されるさまざまな機械学習モデルと手法のラベルノイズ許容度に関する最初の体系的な研究も提供します。 クラス依存ノイズとクラス非依存ノイズに対する 3 つの異なる機械学習手法 (ロジスティック回帰、ナイーブ ベイズ、AdaBoost) の堅牢性を比較研究します。
残りの論文は次のように示されています:セクションIIでは、文献の前の作品のいくつかを紹介します。 セクション III では、データ セットとデータの前処理方法について説明します。 この方法論については、セクション IV と、セクション V で分析した実験の結果について説明します。最後に、私たちの結論と将来の作品をVIで発表します。
II. 前の作品
バグ リポジトリへの機械学習アプリケーション。
セキュリティバグ検出[2]、[7]、[8]、[18]、バグ重複識別[3]、バグトリアージ[1]、[11]などの面倒なタスクを自動化しようと、バグリポジトリにテキストマイニング、自然言語処理、機械学習を適用する際には、広範な文献が存在します。 理想的には、機械学習 (ML) と自然言語処理の結婚によって、バグ データベースのキュレーションに必要な手動作業が減り、これらのタスクを実行するために必要な時間が短縮され、結果の信頼性が向上する可能性があります。
[7] 著者らは、バグの説明に基づいて SDR の分類を自動化する自然言語モデルを提案している。 作成者は、トレーニング データ セット内のすべてのバグ説明からボキャブラリを抽出し、関連する単語、ストップ ワード (分類に無関係と思われる一般的な単語)、シノニムの 3 つのリストに手動でキュレーションします。 これらは、セキュリティ エンジニアによってすべて評価されるデータに対してトレーニングされたセキュリティ バグ分類子のパフォーマンスと、一般的にバグ レポーターによってラベル付けされたデータでトレーニングされた分類子を比較します。 モデルは、セキュリティ エンジニアによってレビューされたデータに基づいてトレーニングすると明らかに効果的ですが、提案されたモデルは手動で派生したボキャブラリに基づいており、人間のキュレーションに依存します。 さらに、異なるレベルのノイズがモデルに与える影響、異なる分類子がノイズに応答する方法、およびいずれかのクラスのノイズがパフォーマンスに異なる影響を与えるかどうかの分析はありません。
Zia et.al [18] バグ レポートに含まれる複数の種類の情報を利用します。この情報には、バグ レポートの非テキスト フィールド (メタ機能、時間、重大度、優先度など) とバグ レポートのテキスト コンテンツ (テキスト機能、要約フィールド内のテキストなど) が含まれます。 これらの機能に基づいて、自然言語処理と機械学習手法を使用して SDR を自動的に識別するモデルを構築します。 [8] 著者は同様の分析を実行しますが、さらに教師あり機械学習手法と教師なし機械学習手法のパフォーマンスを比較し、モデルのトレーニングに必要なデータ量を調査しています。
また、[2] 著者たちは、バグを説明に基づいて SPR または NSBR (セキュリティ以外のバグ レポート) として分類するためのさまざまな機械学習手法を調べる。 TFIDF に基づくデータ処理とモデル トレーニングのパイプラインを提案します。 提案されたパイプラインを、バッグオブワードとナイーブベイズに基づくモデルと比較します。 Wijayasekaraら[16]はまた、テキストマイニング技術を使用して、頻繁な単語に基づいて各バグレポートの特徴ベクトルを生成し、隠れた影響バグ(HIB)を特定した。 Yang ら [17] は、Term Frequency (TF) と naïve Bayes の助けを借りて、影響の大きいバグ レポート (SDR など) を特定すると主張した。 [9] 著者は、バグの重大度を予測するモデルを提案しています。
ラベル ノイズ
ラベル ノイズを含むデータ セットの処理の問題は、広範囲に調査されています。 Frenay と Verleysen は、さまざまな種類のノイズ ラベルを区別するために、[6] のラベル ノイズ分類を提案しています。 著者らは、真のクラスとインスタンス特徴の値とは無関係に発生するラベルノイズという3種類のノイズを提案している。真のラベルのみに依存するラベルノイズ。誤ラベル付け確率も特徴値に依存するラベル ノイズ。 私たちの研究では、最初の2種類のノイズを研究しています。 理論上の観点から見ると、ラベル ノイズは通常、特定のケース [14] を除き、モデルのパフォーマンス [10] を低下させます。 一般に、堅牢な方法は、ラベル ノイズを処理するためにオーバーフィット回避に依存します [15]。 分類におけるノイズ効果の研究は、衛星画像分類[13]、ソフトウェア品質分類[4]、医療領域分類[12]などの多くの分野で以前に行われています。 私たちの知る限りでは、SBR分類の問題におけるノイズラベルの効果の正確な定量化を研究した公開された作品はありません。 このシナリオでは、ノイズ レベル、ノイズの種類、パフォーマンスの低下の間で正確な関係が確立されていません。 さらに、ノイズが存在する場合にさまざまな分類子がどのように動作するかを理解する価値があります。 一般的には、ソフトウェア バグ レポートのコンテキストで、ノイズの多いデータ セットがさまざまな機械学習アルゴリズムのパフォーマンスに及ぼす影響を体系的に調査する作業は認識されません。
III. データ セットの説明
このデータ セットは、1,073,149 個のバグ タイトルで構成され、そのうち 552,073 個が SDR に対応し、521,076 個が NSPR に対応しています。 このデータは、2015 年、2016 年、2017 年、2018 年の各チームから収集されました。 すべてのラベルは、署名ベースのバグ検証システムまたは人間のラベル付けによって取得されました。 データセット内のバグ タイトルは非常に短いテキストで、約 10 語が含まれています。この問題の概要が示されています。
A. データ前処理 各バグ タイトルを空白スペースで解析し、トークンの一覧を作成します。 トークンの各リストは次のように処理されます。
ファイル パスであるすべてのトークンを削除する
次の記号が存在する分割トークン: { , (, ), -, }, {, [, ], }
停止単語、数字のみで構成されるトークン、およびコーパス全体で 5 回未満に表示されるトークンを削除します。
IV. 方法論
機械学習モデルをトレーニングするプロセスは、特徴ベクトルへのデータのエンコードと教師あり機械学習分類子のトレーニングという 2 つの主要な手順で構成されています。
A. 特徴ベクトルと機械学習手法
最初の部分では、[2] で使用される frequencyinverse ドキュメント頻度アルゴリズム (TF-IDF) という用語を使用して、特徴ベクトルにデータをエンコードします。 TF-IDF は、用語頻度 (TF) とその逆ドキュメント頻度 (IDF) を重み付けする情報取得手法です。 各単語または用語には、それぞれの TF スコアと IDF スコアがあります。 TF-IDF アルゴリズムは、ドキュメントに出現する回数に基づいてその単語に重要度を割り当てます。さらに重要なのは、データ セット内のタイトルのコレクション全体でキーワードがどの程度関連性を持っているかを確認することです。 Naïve Bayes (NB)、ブースト デシジョン ツリー (AdaBoost) とロジスティック回帰 (LR) の 3 つの分類手法をトレーニングして比較しました。 これらの手法は、文献のレポート全体に基づいてセキュリティ バグ レポートを特定する関連タスクに対してパフォーマンスが良好に示されているため、選択しました。 これらの結果は、これら 3 つの分類子がサポート ベクター マシンとランダム フォレストを上回る予備的な分析で確認されました。 実験では、エンコードとモデルトレーニングに scikit-learn ライブラリを使用します。
B: ノイズの種類
この作業で調査したノイズは、トレーニング データ内のクラス ラベルのノイズを指します。 このようなノイズが存在すると、結果として、誤ったラベル付けされた例によって学習プロセスと結果モデルが損なわれます。 クラス情報に適用されるさまざまなノイズ レベルの影響を分析します。 ラベル ノイズの種類は、さまざまな用語を使用して文献で既に説明されています。 この作業では、分類子の 2 つの異なるラベル ノイズの影響を分析します。クラスに依存しないラベル ノイズは、インスタンスをランダムに選択し、ラベルを反転することによって導入されます。クラスがノイズになる可能性が異なるクラス依存ノイズ。
a) クラスに依存しないノイズ: クラスに依存しないノイズは、インスタンスの真のクラスとは無関係に発生するノイズを指します。 この種類のノイズでは、データ セット内のすべてのインスタンスで pbr のラベル付けの誤りが発生する可能性が同じです。 データ セット内の各ラベルを確率 pbrでランダムに反転することで、クラスに依存しないノイズをデータセットに導入します。
b) クラス依存ノイズ: クラス依存ノイズは、インスタンスの真のクラスに依存するノイズを指します。 この種のノイズでは、SBRクラスでの誤ラベルの確率はpsbrで、NSBRクラスでの誤ラベルの確率はpnsbrです。 実際のラベルが SBR であるデータセットの各エントリを確率 psbrで変更することにより、クラス依存ノイズをデータセットに導入します。 同様に、確率 pで NSBR インスタンスのクラスラベルを nsbrに変更します。
c) 単一クラスノイズ: 単一クラスノイズはクラス依存ノイズの特殊なケースであり、pnsbr = 0、psbr> 0 です。 クラスに依存しないノイズの場合、psbr = pnsbr = pbrがあります。
C: ノイズ生成
この実験では、SBR 分類子のトレーニングにおけるさまざまなノイズの種類とレベルの影響を調査します。 実験では、データセットの 25% をテスト データとして設定し、10% を検証として、65% をトレーニング データとして設定します。
さまざまなレベルの pbr、psbr、pnsbr のトレーニングおよび検証データセットにノイズを追加します。 テスト データ セットに変更を加える必要はありません。 使用されるノイズ レベルは、P = {0.05 × i|0 < i < 10} です。
クラスに依存しないノイズ実験では、pbr ∈ P について、次の操作を行います。
トレーニングデータセットと検証データセットのノイズを生成する。
トレーニング データセット (ノイズあり) を使用して、ロジスティック回帰、単純ベイズ、AdaBoost モデルをトレーニングします。*検証データセット(ノイズ付き)を使用してモデルを調整します。
テスト データセットを使用してモデルをテストする (ノイズレス)。
クラス依存ノイズ実験では、psbr ∈ P と pnsbr ∈ P について、psbr と pnsbrのすべての組み合わせについて以下を行います。
トレーニングデータセットと検証データセットのノイズを生成する。
トレーニング データセット (ノイズあり) を使用して、ロジスティック回帰、単純ベイズ、AdaBoost モデルをトレーニングします。
検証データセット (ノイズあり) を使用してモデルを調整する。
テスト データセットを使用してモデルをテストする (ノイズレス)。
V. 実験結果
このセクションでは、セクション IV に記載されている手法に従って行われた実験の結果を分析します。
a) トレーニング データセットのノイズのないパフォーマンスをモデル化する: このホワイト ペーパーの貢献の 1 つは、意思決定のためのデータとしてバグのタイトルのみを使用してセキュリティバグを識別する機械学習モデルの提案です。 これにより、機密データが存在するため、開発チームがバグ レポートを完全に共有したくない場合でも、機械学習モデルのトレーニングが可能になります。 バグ タイトルのみを使用してトレーニングした場合の 3 つの機械学習モデルのパフォーマンスを比較します。
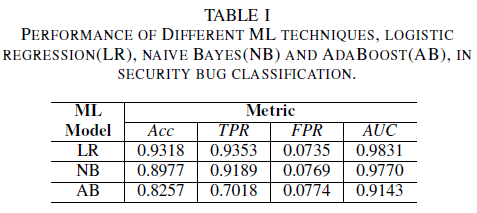
ロジスティック回帰モデルは、最もパフォーマンスの高い分類子です。 これは、FPR 値が 0.0735 の場合、AUC 値が最も高い 0.9826、再現率が 0.9353 の分類子です。 単純ベイズ分類子は、ロジスティック回帰分類子よりもパフォーマンスが若干低く、AUC は 0.9779、FPR が 0.0769 の場合は 0.9189 です。 AdaBoost 分類子は、前述の 2 つの分類子と比較してパフォーマンスが低くなります。 AUC 値 0.9143 を達成し、FPR 値 0.0774 に対して再現率は 0.7018 でした。 ROC 曲線 (AUC) の下の領域は、TPR と FPR の関係を 1 つの値で要約しているため、複数のモデルのパフォーマンスを比較するための適切なメトリックです。 その後の分析では、比較分析を AUC 値に制限します。
A. クラス ノイズ: 単一クラス
すべてのバグが既定でクラス NSBR に割り当てられ、バグ リポジトリを確認するセキュリティ専門家が存在する場合にのみ、バグがクラス SBR に割り当てられるシナリオを想像できます。 このシナリオは、単一クラスの実験設定で表されます。ここで、pnsbr = 0 と 0 < psbr< 0.5 であると仮定します。
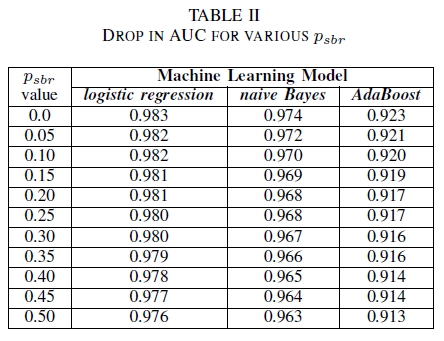
表 II では、3 つの分類子すべてに対する AUC の影響が非常に小さいことを確認します。 psbr = 0 でトレーニングされたモデルの AUC-ROC は、psbr = 0.25 のモデルの AUC-ROC と比較すると、ロジスティック回帰では0.003、ナイーブベイズでは0.006、AdaBoost では0.006だけ異なります。 psbr = 0.50 の場合、各モデルで測定された AUC は、ロジスティック回帰の場合は psbr = 0 .007、naïve Bayes の場合は 0.011、AdaBoost の場合は 0.010 でトレーニングされたモデルとは異なります。 単一クラスのノイズの存在下でトレーニングされたロジスティック回帰分類器は、その AUC メトリックの中で最も小さなバリエーションを示します。つまり、naïve Bayes および AdaBoost 分類子と比較すると、より堅牢な動作になります。
B: クラス ノイズ: クラスに依存しない
クラスに依存しないノイズによってトレーニング セットが破損した場合の 3 つの分類子のパフォーマンスを比較します。 トレーニング データで異なるレベルの pbr でトレーニングされた各モデルの AUC を測定します。
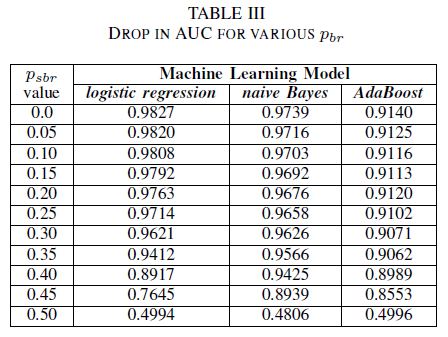
表 III では、実験内のすべてのノイズ増分の AUC-ROC の減少を観察します。 ノイズレス データでトレーニングされたモデルから測定された AUC-ROC は、pbr = 0.25 でクラスに依存しないノイズでトレーニングされたモデルの AUC-ROC と比較すると、ロジスティック回帰では 0.011、naïve Bayes では 0.008、AdaBoost では 0.0038 で異なります。 ノイズ レベルが 40%未満の場合、ラベル ノイズが Naïve Bayes および AdaBoost 分類子の AUC に大きな影響を与えるわけではないことを確認します。 一方、ロジスティック回帰分類器は、ラベルノイズレベルが30%を超えると、AUC指標に影響を受けます。
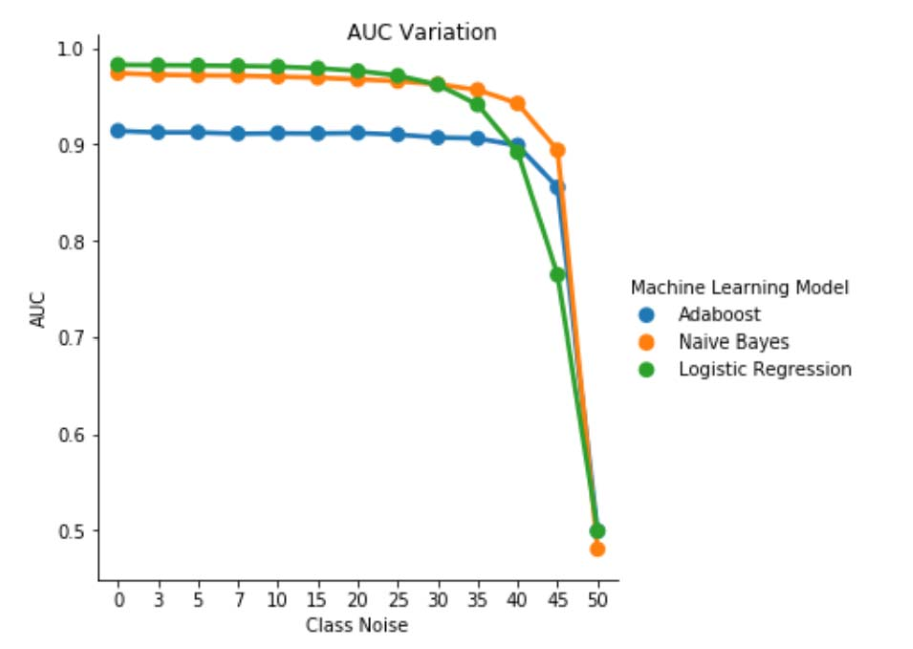
図 1. クラスに依存しないノイズでの AUC-ROC の変動。 ノイズ レベル pbr =0.5 の場合、分類子はランダム分類子 (AUC≈0.5) のように機能します。 しかし、低ノイズ レベル (pbr ≤ 0.30) では、ロジスティック回帰学習器が他の 2 つのモデルと比較して優れたパフォーマンスを示すことを確認できます。 ただし、0.35≤ pbr ≤0.45 の範囲では、ナイーブベイズ学習者がより優れたAUCROC指標を示します。
C: クラスノイズ: クラス依存
実験の最後のセットでは、異なるクラスに異なるノイズ レベル (psbr ≠ pnsbr) が含まれるシナリオを検討します。 トレーニング データの psbr と pnsbr を 0.05 ずつ体系的にインクリメントし、3 つの分類子の動作の変化を観察します。
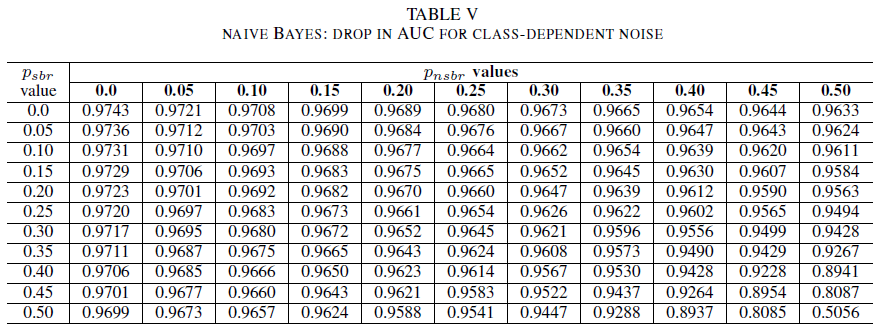
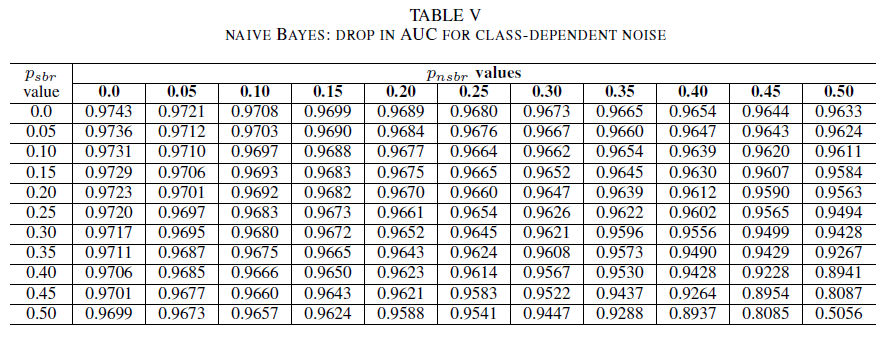
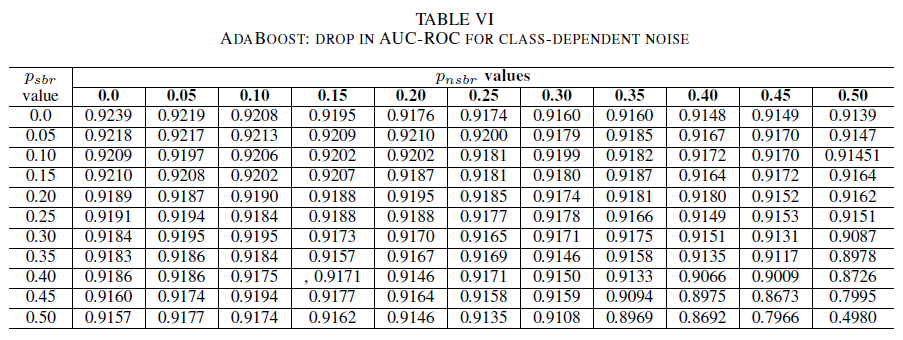
表IV、V、VIは、表IVのロジスティック回帰、表Vのナイーブベイ、および表VIのAdaBoostについて、各クラスの異なるレベルでノイズが増加するにつれてAUCの変動を示す。 すべての分類子について、両方のクラスに 30%を超えるノイズ レベルが含まれている場合、AUC メトリックに影響があります。 単純ベイズの動作が最も堅牢です。 負のクラスに 30% 以下のノイズ ラベルが含まれている場合、正のクラスのラベルの 50% が反転した場合でも、AUC への影響は非常に小さくなります。 この場合、AUC のドロップは 0.03 です。 AdaBoost は、3 つの分類子の中で最も堅牢な動作を示しました。 AUC の大幅な変更は、両方のクラスで 45% を超えるノイズ レベルでのみ発生します。 その場合、0.02 を超える AUC 減衰の観測を開始します。
D: 元のデータセットに残留ノイズが存在する場合
私たちのデータセットは、署名ベースの自動化システムと人間の専門家によってラベル付けされました。 さらに、すべてのバグレポートは、人間の専門家によってさらに見直され、閉鎖されています。 データセット内のノイズの量は最小限であり、統計的に有意なものではありませんが、残留ノイズが存在しても結論は無効になりません。 実際、説明のために、クラスに依存しないノイズ (0 < p < 1/2) によって元のデータ セットが破損しており、すべてのエントリに等しく分散されている (i.i.d) ものと想定しましょう。
元のノイズに加えて、確率 pbr i.i.d のクラスに依存しないノイズを追加すると、エントリあたりの結果のノイズは p∗ = p(1 - pbr )+(1 − p)pbr になります。 0 < p,pbr< 1/2 の場合、ラベル p∗ あたりの実際のノイズは、データ セット pbr に人為的に追加したノイズよりも厳密に大きくなります。 したがって、分類子が最初に完全にノイズのないデータセット (p = 0) でトレーニングされた場合、分類子のパフォーマンスはさらに向上します。 要約すると、実際のデータセットに残留ノイズが存在することは、分類子のノイズに対する回復性が、ここで示した結果よりも優れていることを意味します。 さらに、データセット内の残余ノイズが統計的に関連している場合、分類子の AUC は、厳密に 0.5 未満のレベルのノイズに対して 0.5 (ランダムな推測) になります。 このような動作は、結果には見つかりません。
VI. 結論と今後の取り組み
この論文における私たちの貢献は2倍です。
まず、バグ レポートのタイトルのみに基づいて、セキュリティ バグ レポートの分類の実現可能性を示しました。 これは、プライバシーの制約のためにバグ レポート全体を使用できないシナリオで特に関連します。 たとえば、この例では、バグ レポートにはパスワードや暗号化キーなどの個人情報が含まれており、分類子のトレーニングには使用できませんでした。 結果は、レポート タイトルのみが使用可能な場合でも、SBR 識別を高い精度で実行できることを示しています。 TF-IDF とロジスティック回帰の組み合わせを利用した分類モデルは、AUC 0.9831 で実行されます。
次に、誤ったラベル付けされたトレーニングデータと検証データの影響を分析しました。 ここでは、3 つの既知の機械学習分類手法 (naïve Bayes、ロジスティック回帰、AdaBoost) を、さまざまなノイズの種類とノイズ レベルに対する堅牢性の観点から比較しました。 3 つの分類子はすべて、単一クラスのノイズに対して堅牢です。 トレーニング データのノイズは、結果の分類子に大きな影響を与える影響はありません。 AUCの減少は、騒音レベルが50%の時に非常に小さい(0.01)です。 クラスに共通して存在し、クラスに依存しないノイズに対して、naïve BayesモデルとAdaBoostモデルは、ノイズレベルが40%を超えるデータセットでトレーニングされた場合にのみ、AUCに著しい変動を示します。
最後に、クラスに依存するノイズは、両方のクラスに 35 個の% ノイズがある場合にのみ、AUC に大きな影響を与えます。 AdaBoost は最も堅牢性を示しました。 肯定クラスのラベルが50% のノイズである場合でも、負のクラスが45% 以下のノイズラベルを含む限り、AUCへの影響は非常に小さいです。 この場合、AUC の低下は 0.03 未満です。 私たちの知識を最大限に活用するために、これはセキュリティバグレポート識別のためのノイズデータセットの影響に関する最初の体系的な研究です。
未来の作品
このホワイト ペーパーでは、セキュリティバグを特定するための機械学習分類器のパフォーマンスにおけるノイズの影響の体系的な研究を開始しました。 この作業には、セキュリティバグの重大度レベルを決定する際のノイズの多いデータセットの影響を調べるなど、いくつかの興味深い続編があります。クラスの不均衡がノイズに対するトレーニング済みモデルの回復性に及ぼす影響を理解する。は、データ セットに逆境的に導入されるノイズの影響を理解します。
参照
[1] John Anvik、Lyndon Hiew、Gail C Murphy。 誰がこのバグを修正する必要がありますか? ソフトウェアエンジニアリングに関する第28回国際会議の議事録, ページ 361-370. ACM、2006 年。
[2] ディクシャ・ベール、サヒル・ハンダ、アヌジャ・アローラ。 単純ベイと tf-idf を使用してセキュリティバグを識別および分析するためのバグ マイニング ツール。 2014 年開催の "最適化、信頼性、および情報技術に関する国際会議 (ICROIT)"、294 - 299 ページ。 IEEE、2014。
[3] ニコラ・ベットンブルク、ラーフル・プレムラジ、トーマス・ツィンマーマン、スングン・キム。 重複するバグ レポートは本当に有害と見なされますか? 「Software maintenance, 2008. ICSM 2008. IEEE international conference on」、337 ~ 345 ページ。 IEEE、2008。
[4] Andres Folleco、Taghi M Khoshgoftaar、Jason Van Hulse、Lofton Bullard。 低品質のデータに対して堅牢な学習者を識別する。 情報の再利用と統合、2008 年。IRI 2008。に関するIEEE国際会議、190-195ページ。 IEEE、2008。
[5] Benoˆıt Frenay.' 機械学習における不確定性とラベルノイズ. 2013年、ルーヴァン・ラ・ヌーヴ・カトリック大学博士論文。
[6] Benoˆıt Frenay と Michel Verleysen. ラベル ノイズが存在する場合の分類: アンケート。 ニューラル ネットワークおよび学習システムに関する IEEE の議事録、25 (5): 845 - 869 ページ、2014 年。
[7] Michael Gegick、Pete Rotella、Tao Xie。 テキスト マイニングを使用したセキュリティ バグ レポートの特定: 産業ケース スタディ。 "2010 年開催の第 7 回ソフトウェア リポジトリ マイニング (MSR) に関する IEEE の作業部会"、11 - 20 ページ。 IEEE、2010。
カテリーナ・Goseva-Popstojanova とジェイコブ・ティヨ 「Identification of security related bug reports via text mining using supervised and unsupervised classification (教師ありおよび教師なしの分類を使用した、テキスト マイニングによるセキュリティ関連バグ レポートの識別)」。 2018 IEEE ソフトウェアの品質、信頼性、セキュリティに関する国際会議 (QRS)、 344 - 355、2018 ページ。
アハメド・ラムカンフィ、セルジュ・デメイヤー、エマニュエル・ギガー、バート・ゲーサルス 報告されたバグの重大度を予測する。 マイニングソフトウェアリポジトリ (MSR) に関する2010年第7回IEEEワーキングカンファレンスでの論文、ページ1~10。 IEEE、2010。
[10] ナレス・マンワナとPSサストリー。 リスク最小化下のノイズ許容度。 IEEE トランザクションズ オン サイバネティックス, 43(3):1146-1151, 2013.
[11] GマーフィーとDカブラニック。 テキスト分類を使用した自動バグトリアージ。 第 16 回ソフトウェア エンジニアリングおよびナレッジ エンジニアリングに関する国際会議の議事録。 シテセアー、2004年。
[12] Mykola Pechenizkiy、Alexey Tsymbal、Seppo Puuronen、Oleksandr Pechenizkiy。 医療分野におけるクラスノイズと教師あり学習:特徴抽出の効果。 nullでは、708 から 713 ページ。 IEEE、2006。
[13] シャーロット・ペレティエ、シルビア・ヴァレロ、ジョルディ・イングラダ、ニコラ・チャンピオン、クレア・マレ・シクレ、ジェラルド・デデューによる、衛星画像時系列による陸上カバーマッピングの分類性能に対するトレーニングクラスラベルノイズの影響。 リモートセンシング, 9(2):173, 2017.
[14] PS Sastry、GD Nagendra、Naresh Manwani。 半空間のノイズ耐性学習のための連続行動学習自動装置のチーム。 システム、マン、サイバネティックに関する IEEE トランザクション、パート B (サイバネティック)、40(1):19-28、2010 年。
[15] Choh-Man Teng。 ノイズ処理手法の比較。 "FLAIRS カンファレンス"、269 - 273 ページ、2001 年。
[16] ドゥミドゥ・ウィジャヤセカラ、ミロス・マニック、マイルス・マックイーン。 テキスト マイニング バグ データベースを使用した脆弱性の識別と分類。 2014 年開催の第 40 回 IEEE Industrial Electronics Society (IECON) 年次会議、3612 - 3618 ページ。
[17] シンリ・ヤン、David Lo、チャオ・ホアン、シン・シャ、およびジャンリン・スン。 不均衡な学習戦略を活用した、影響の大きいバグ レポートの自動識別。 コンピューター ソフトウェアおよびアプリケーション会議 (COMPSAC) では、2016 年 IEEE 第 40 回年次、第 1 巻、227 ~ 232 ページ。 IEEE、2016。
[18] デチン・ズー、ジジュン・デン、ヂェン・リー、ハイジン。 マルチタイプ機能分析を使用してセキュリティ バグ レポートを自動的に識別する。 オーストラレーシア情報セキュリティおよびプライバシー会議、619-633ページ。 Springer、2018 年。