この記事では、Analytics Platform System (PDW) または APS アプライアンスで PolyBase を使用して Hadoop の外部データにクエリを実行する方法について説明します。
前提条件
PolyBase は、Hortonworks Data Platform (HDP) と Cloudera Distributed Hadoop (CDH) の 2 つの Hadoop プロバイダーをサポートしています。 Hadoop では、新規リリースについて "Major.Minor.Version" パターンを採用しており、サポートされているメジャーおよびマイナー リリース内のすべてのバージョンがサポートされています。 次の Hadoop プロバイダーがサポートされています。
- Linux/Windows Server 上の Hortonworks HDP 1.3
- Linux 上の Hortonworks HDP 2.1 ~ 2.6
- Linux 上の Hortonworks HDP 3.0 ~ 3.1
- Windows Server 上の Hortonworks HDP 2.1 - 2.3
- Linux 上の Cloudera CDH 4.3
- Linux 上の Cloudera CDH 5.1 から 5.5、5.9 から 5.13、5.15 および 5.16
Hadoop 接続を構成する
まず、特定の Hadoop プロバイダーを使用するように APS を構成します。
'hadoop connectivity' を使用して sp_configure を実行し、プロバイダーに対する適切な値を設定します。 プロバイダーの値を見つけるには、PolyBase 接続構成 に関する記事を参照してください。
-- Values map to various external data sources. -- Example: value 7 stands for Hortonworks HDP 2.1 to 2.6 and 3.0 - 3.1 on Linux, -- 2.1 to 2.3 on Windows Server, and Azure Blob Storage sp_configure @configname = 'hadoop connectivity', @configvalue = 7; GO RECONFIGURE GO[Appliance Configuration Manager] の [サービスの状態] ページを使用して APS リージョンを再起動します。
プッシュダウン計算を有効にする
クエリ パフォーマンスを高めるには、Hadoop クラスターへのプッシュダウン計算を有効にします。
APS PDW コントロール ノードへのリモート デスクトップ接続を開きます。
制御ノードでファイル
yarn-site.xmlを見つけます。 通常、このパスはC:\Program Files\Microsoft SQL Server Parallel Data Warehouse\100\Hadoop\conf\です。Hadoop コンピューターで、Hadoop 構成ディレクトリ内の対応するファイルを検索します。 このファイル内の構成キー
yarn.application.classpathの値をコピーします。yarn.site.xmlファイル内の 制御ノードで、yarn.application.classpathプロパティを見つけます。 Hadoop コンピューターからこの値要素に値を貼り付けます。すべての CDH 5.X バージョンでは、
mapreduce.application.classpath構成パラメーターをyarn.site.xmlファイルの末尾またはmapred-site.xmlファイル内に追加する必要があります。 HortonWorks では、yarn.application.classpath構成内にこれらの構成が含まれます。 例については、「PolyBase の構成」を参照してください。
CDH 5.X クラスター用のサンプル XML ファイルの規定値
Yarn-site.xml と yarn.application.classpath および mapreduce.application.classpath の構成。
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/,$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
2 つの構成設定を mapred-site.xml と yarn-site.xml に分割する場合、ファイルは次のようになります。
yarn-site.xmlの場合:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
mapred-site.xmlの場合:
プロパティ mapreduce.application.classpath をメモします。 CDH 5.x では、Ambari の同じ命名規則に構成値があります。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<property>
<name>mapred.min.split.size</name>
<value>1073741824</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH</value>
</property>
<!--kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>mapreduce.jobhistory.principal</name>
<value></value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value></value>
</property>
-->
</configuration>
HDP 3.X クラスターの既定値の XML ファイルの例
yarn-site.xml の場合:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CONF_DIR,/usr/hdp/3.1.0.0-78/hadoop/*,/usr/hdp/3.1.0.0-78/hadoop/lib/*,/usr/hdp/current/hadoop-hdfs-client/*,/usr/hdp/current/hadoop-hdfs-client/lib/*,/usr/hdp/current/hadoop-yarn-client/*,/usr/hdp/current/hadoop-yarn-client/lib/*,/usr/hdp/3.1.0.0-78/hadoop-mapreduce/*,/usr/hdp/3.1.0.0-78/hadoop-yarn/*,/usr/hdp/3.1.0.0-78/hadoop-yarn/lib/*,/usr/hdp/3.1.0.0-78/hadoop-mapreduce/lib/*,/usr/hdp/share/hadoop/common/*,/usr/hdp/share/hadoop/common/lib/*,/usr/hdp/share/hadoop/tools/lib/*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
外部テーブルを構成する
Hadoop データ ソース内のデータのクエリを実行するには、Transact-SQL クエリで使用する外部テーブルを定義する必要があります。 次の手順では、外部テーブルを構成する方法を説明します。
データベースにマスター キーを作成します。 資格情報のシークレットの暗号化に必須です。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';Kerberos でセキュリティ保護された Hadoop クラスターのデータベース スコープ資格情報を作成します。
-- IDENTITY: the Kerberos user name. -- SECRET: the Kerberos password CREATE DATABASE SCOPED CREDENTIAL HadoopUser1 WITH IDENTITY = '<hadoop_user_name>', Secret = '<hadoop_password>';CREATE EXTERNAL DATA SOURCE を使用して外部データ ソースを作成します。
-- LOCATION (Required) : Hadoop Name Node IP address and port. -- RESOURCE MANAGER LOCATION (Optional): Hadoop Resource Manager location to enable pushdown computation. -- CREDENTIAL (Optional): the database scoped credential, created above. CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH ( TYPE = HADOOP, LOCATION ='hdfs://10.xxx.xx.xxx:xxxx', RESOURCE_MANAGER_LOCATION = '10.xxx.xx.xxx:xxxx', CREDENTIAL = HadoopUser1 );CREATE EXTERNAL FILE FORMAT を使用して外部ファイル形式を作成します。
-- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET). CREATE EXTERNAL FILE FORMAT TextFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE)CREATE EXTERNAL TABLEを使用して、Hadoop に格納されているデータをポイントする外部テーブルを作成します。 この例では、外部データには車両センサー データが含まれています。
-- LOCATION: path to file or directory that contains the data (relative to HDFS root). CREATE EXTERNAL TABLE [dbo].[CarSensor_Data] ( [SensorKey] int NOT NULL, [CustomerKey] int NOT NULL, [GeographyKey] int NULL, [Speed] float NOT NULL, [YearMeasured] int NOT NULL ) WITH (LOCATION='/Demo/', DATA_SOURCE = MyHadoopCluster, FILE_FORMAT = TextFileFormat );外部テーブルの統計を作成します。
CREATE STATISTICS StatsForSensors on CarSensor_Data(CustomerKey, Speed)
PolyBase クエリ
PolyBase が適している機能には、次の 3 つがあります。
- 外部テーブルに対するアドホック クエリ。
- データのインポート。
- データのエクスポート。
次のクエリでは、架空の車両センサー データの例を示します。
アドホック クエリ
次のアドホック クエリでは、Hadoop データを結合します。 時速 35 マイルを越えて走行している顧客を選択し、APS に格納されている構造化された顧客データと Hadoop に格納されている車両センサー データを結合します。
SELECT DISTINCT Insured_Customers.FirstName,Insured_Customers.LastName,
Insured_Customers. YearlyIncome, CarSensor_Data.Speed
FROM Insured_Customers, CarSensor_Data
WHERE Insured_Customers.CustomerKey = CarSensor_Data.CustomerKey and CarSensor_Data.Speed > 35
ORDER BY CarSensor_Data.Speed DESC
OPTION (FORCE EXTERNALPUSHDOWN); -- or OPTION (DISABLE EXTERNALPUSHDOWN)
データのインポート
次のクエリでは、外部データを APS にインポートします。 この例では、高速走行しているドライバーのデータを、さらに詳細な分析を実行するために APS にインポートします。 パフォーマンスを向上させるために、APS の列ストア テクノロジが活用されています。
CREATE TABLE Fast_Customers
WITH
(CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH (CustomerKey))
AS
SELECT DISTINCT
Insured_Customers.CustomerKey, Insured_Customers.FirstName, Insured_Customers.LastName,
Insured_Customers.YearlyIncome, Insured_Customers.MaritalStatus
from Insured_Customers INNER JOIN
(
SELECT * FROM CarSensor_Data where Speed > 35
) AS SensorD
ON Insured_Customers.CustomerKey = SensorD.CustomerKey
データのエクスポート
次のクエリは、APS から Hadoop にデータをエクスポートします。 リレーショナル データを Hadoop にアーカイブしながらクエリを実行するために使用できます。
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
CREATE EXTERNAL TABLE [dbo].[FastCustomers2009]
WITH (
LOCATION='/archive/customer/2009',
DATA_SOURCE = HadoopHDP2,
FILE_FORMAT = TextFileFormat
)
AS
SELECT T.* FROM Insured_Customers T1 JOIN CarSensor_Data T2
ON (T1.CustomerKey = T2.CustomerKey)
WHERE T2.YearMeasured = 2009 and T2.Speed > 40;
SSDT での PolyBase オブジェクトの表示
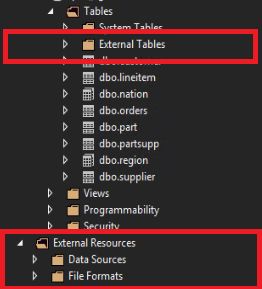
SQL Server Data Tools では、外部テーブルが別のフォルダー [外部テーブル]に表示されます。 外部データ ソースおよび外部ファイル形式は、 [外部リソース]の下のサブフォルダーにあります。
関連するコンテンツ
- Hadoop のセキュリティ設定については、「Hadoop セキュリティの構成」を参照してください。
- PolyBase について詳しくは、「PolyBase とは」をご覧ください。