SQL Server ビッグ データ クラスターの紹介
適用対象: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
SQL Server 2019 (15.x) では、SQL Server ビッグ データ クラスターを使用すると、Kubernetes 上で動作する SQL Server、Spark、および HDFS コンテナーのスケーラブルなクラスターを展開できます。 これらのコンポーネントを並行して実行し、Transact-SQL または Spark からのビッグ データの読み取り、書き込み、処理を行うことができるので、高価値のリレーショナル データと大量のビッグ データを簡単に組み合わせて分析できます。
作業の開始
- まず、「SQL Server ビッグ データ クラスター展開の概要」を参照してください。
- 最新リリースの新機能については、リリース ノートを参照してください。
- よく寄せられる質問については、ビッグ データ クラスターのよくあるご質問を参照してください。
ビッグ データ クラスターのアーキテクチャ
次の図は、SQL Server ビッグ データ クラスターのコンポーネントを示しています。

コントローラー
コントローラーには、クラスターの管理とセキュリティ機能があります。 これには、制御サービス、構成ストア、および Kibana、Grafana、Elasticsearch などのその他のクラスターレベルサービスが含まれています。
計算プール
コンピューティング プールは、クラスターにコンピューティング リソースを提供します。 これには SQL Server on Linux ポッドを実行するノードが含まれます。 コンピューティング プール内のポッドは、特定の処理タスクのために SQL コンピューティング インスタンスに分割されます。
データ プール
データ プールはデータの永続化に使用されます。 データ プールは、SQL Server on Linux を実行している 1 つ以上のポッドで構成されます。 これは、SQL クエリまたは Spark ジョブからデータを取り込むために使用されます。
記憶域プール
記憶域プールは、SQL Server on Linux、Spark、および HDFS で構成される記憶域プール ポッドで構成されます。 SQL Server ビッグ データ クラスター内のすべての記憶域ノードは、HDFS クラスターのメンバーです。
ヒント
ビッグ データ クラスターのアーキテクチャとインストールの詳細については、「ワークショップ: Microsoft SQL Server ビッグ データ クラスターのアーキテクチャ」を参照してください。
アプリケーション プール
アプリケーション展開は、アプリケーションを作成、管理、および実行するためのインターフェイスを提供することにより、SQL Server ビッグ データ クラスターでアプリケーションの展開を可能にします。
シナリオと機能
SQL Server ビッグ データ クラスターを使用すると、ビッグ データの操作が柔軟になります。 外部データ ソースに対してクエリを実行する、SQL Server が管理する HDFS にビッグ データを格納する、またはクラスターを介して複数の外部データ ソースのデータに対してクエリを実行することができます。 このデータは、AI、機械学習、その他の分析タスクに使用できます。
SQL Server ビッグ データ クラスターを使用して次のことを行います。
- Kubernetes で実行している SQL Server、Spark、HDFS コンテナーのスケーラブルなクラスターを配置します。
- Transact-SQL または Spark からビッグ データの読み取り、書き込み、処理を行います。
- 大量のビッグ データを使用して、価値の高いリレーショナル データを簡単に組み合わせて分析します。
- 外部データ ソースを照会します。
- SQL Server によって管理される HDFS にビッグ データを格納します。
- クラスターを介して複数の外部データ ソースからデータを照会します。
- AI、機械学習、その他の分析タスクにデータを使用します。
- ビッグデータクラスターでアプリケーションのデプロイと実行を行います。
- PolyBase を使用してデータを仮想化します。 外部テーブルを使用して、外部の SQL Server、Oracle、Teradata、MongoDB、汎用 ODBC データ ソースから、データを照会します。
- Always On 可用性グループ テクノロジを使用して、SQL Server マスター インスタンスとすべてのデータベースの高可用性を実現します。
以下に、これらのシナリオについて詳しく説明します。
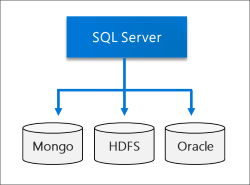
データの仮想化
PolyBase を利用することで、SQL Server ビッグ データ クラスターでは、データを移動またはコピーすることなく、外部データ ソースに対してクエリを実行できます。 SQL Server 2019 (15.x) では、データ ソースに新しいコネクタが導入されています。詳細については、「PolyBase 2019 の新機能」を参照してください。
データ レイク
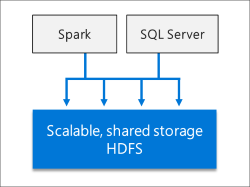
SQL Server ビッグ データ クラスターには、スケーラブルな HDFS 記憶域プールが含まれています。 これは、複数の外部ソースから取り込まれた可能性があるビッグ データを格納するために使用できます。 ビッグ データ クラスターの HDFS にビッグ データが格納されたら、そのデータを分析してクエリを実行し、リレーショナル データと組み合わせることができます。
統合された AI と機械学習
SQL Server ビッグ データ クラスターを使用すると、HDFS 記憶域プールとデータ プールに格納されているデータに対して AI と機械学習タスクを実行できます。 R、Python、Scala、または Java を使用し、Spark だけでなく SQL Server の組み込みの AI ツールを使用できます。

管理と監視
管理と監視は、コマンド ライン ツール、API、ポータル、および動的管理ビューを組み合わせて実行できます。
Azure Data Studio を使用すると、ビッグ データ クラスターに対してさまざまなタスクを実行できます。
- 一般的な管理タスク用の組み込みスニペット。
- HDFS の参照、ファイルのアップロード、ファイルのプレビュー、およびディレクトリの作成を行う機能。
- Jupyter 互換ノートブックを作成、開く、および実行する機能。
- 外部データ ソースの作成を簡易化するデータ仮想化ウィザード (データ仮想化の拡張機能によって有効化されます)。
Kubernetes の概念
SQL Server ビッグ データ クラスターは、Kubernetes によって調整された Linux コンテナーのクラスターです。
Kubernetes はオープン ソースのコンテナー オーケストレーターであり、必要に応じてコンテナーの展開を拡張できます。 次の表では、重要な Kubernetes 用語をいくつか定義します。
| 期間 | 説明 |
|---|---|
| クラスター | Kubernetes クラスターは、ノードと呼ばれる一連のマシンです。 1 つのノードがクラスターを制御し、マスター ノードに指定されます。残りのノードはワーカー ノードです。 Kubernetes マスターは、ワーカー間で作業を分散し、クラスターの正常性を監視する役割を担います。 |
| Node | ノードによって、コンテナー化されたアプリケーションが実行されます。 物理マシンまたは仮想マシンのいずれかです。 Kubernetes クラスターには、物理マシンと仮想マシンの両方のノードを含めることができます。 |
| ポッド | ポッドは、Kubernetes のアトミック展開単位です。 ポッドは、アプリケーションの実行に必要な 1 つ以上のコンテナーと関連するリソースの論理グループです。 各ポッドはノード上で実行されます。ノードでは、1 つ以上のポッドを実行できます。 Kubernetes マスターによって、クラスター内のノードにポッドが自動的に割り当てられます。 |
SQL Server ビッグ データ クラスターでは、Kubernetes がクラスターの状態を担当します。 Kubernetes によってクラスター ノードの構築と構成が行われ、ポッドがノードに割り当てられ、クラスターの正常性が監視されます。
関連するコンテンツ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示