SQL Server ビッグ データ クラスター上の Azure Data Studio で Spark ジョブを送信する
適用対象:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
ビッグ データ クラスターの主なシナリオの 1 つに、SQL Server 用の Spark ジョブを送信する機能があります。 Spark ジョブ送信機能を使用すると、SQL Server 2019 ビッグ データ クラスターへの参照を含むローカル Jar ファイルまたは Py ファイルを送信できます。 また、HDFS ファイル システムに既に配置されている Jar ファイルまたは Py ファイルを実行することもできます。
前提条件
-
- Azure Data Studio
- SQL Server 2019 の拡張機能
- kubectl
Spark ジョブの送信ダイアログを開く
Spark ジョブの送信ダイアログを開くには、いくつかの方法があります。 ダッシュボード、オブジェクト エクスプローラーのコンテキスト メニュー、コマンド パレットなどの方法があります。
Spark ジョブの送信ダイアログを開くには、ダッシュボードで [New Spark Job](新しい Spark ジョブ) をクリックします。
![ダッシュボードをクリックした [Submit]\(送信\) メニュー](media/submit-spark-job/new-spark-job.png?view=sql-server-ver15)
または、オブジェクト エクスプローラーでクラスターを右クリックし、コンテキスト メニューから [Submit Spark Job](Spark ジョブの送信) を選択します。
![ファイルを右クリックした [Submit]\(送信\) メニュー](media/submit-spark-job/submit-spark-job-1.png?view=sql-server-ver15)
Jar/Py フィールドが事前に設定された状態で Spark ジョブの送信ダイアログを開くには、オブジェクト エクスプローラーで Jar/Py ファイルを右クリックし、コンテキスト メニューから [Submit Spark Job](Spark ジョブの送信) を選択します。
![クラスターを右クリックした [Submit]\(送信\) メニュー](media/submit-spark-job/submit-spark-job.png?view=sql-server-ver15)
コマンド パレットから [Submit Spark Job](Spark ジョブの送信) を使用するには、Ctrl + Shift + P キー (Windows の場合 ) と Cmd + Shift + P キー (Mac の場合) を入力します。
![Windows の [Submit]\(送信\) メニュー コマンド パレット](media/submit-spark-job/submit-spark-job-3.png?view=sql-server-ver15)
Spark ジョブを送信する
Spark ジョブの送信ダイアログは、次のように表示されます。 ジョブ名、JAR/Py ファイル パス、メイン クラス、およびその他のフィールドを入力します。 Jar/Py ファイル ソースは、ローカルまたは HDFS のものである可能性があります。 Spark ジョブに参照 Jar、Py ファイル、または追加ファイルがある場合は、 [ADVANCED](詳細設定) タブをクリックし、対応するファイル パスを入力します。 [Submit](送信) をクリックして Spark ジョブを送信します。
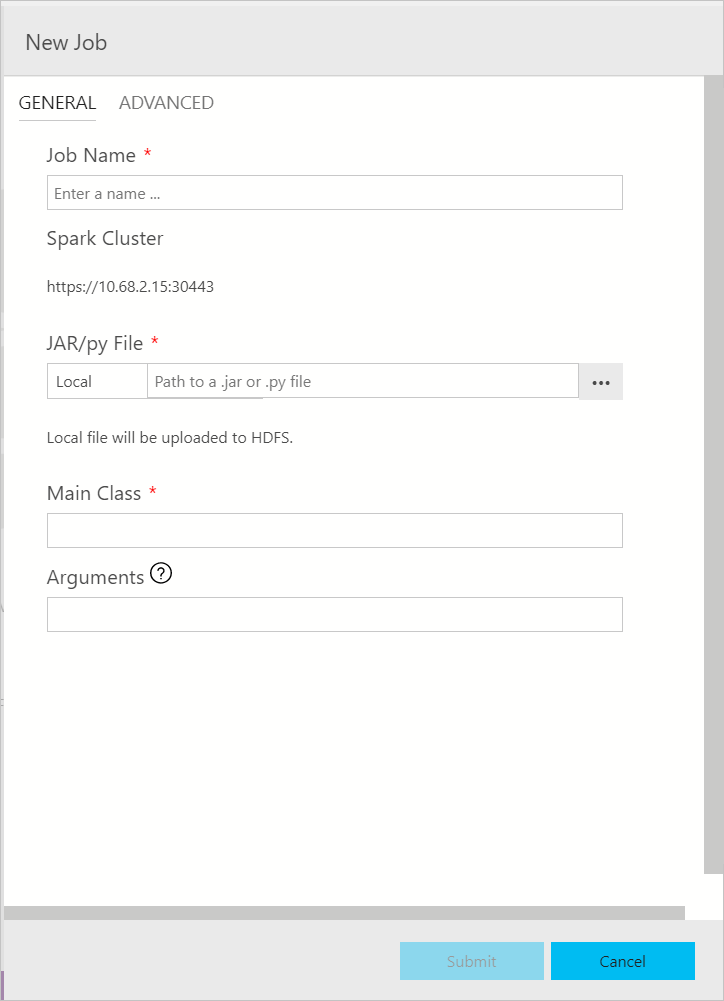
![[Advanced]\(詳細設定\) ダイアログ](media/submit-spark-job/submit-spark-job-section-1.png?view=sql-server-ver15)
Spark ジョブの送信を監視する
Spark ジョブが送信されると、Spark ジョブの送信と実行状態の情報が、左側の [Task History](タスク履歴) に表示されます。 進行状況とログの詳細も、 [OUTPUT](出力) ウィンドウの下部に表示されます。
Spark ジョブが進行中の場合、進行状況に合わせて [Task History](タスク履歴) パネルと [OUTPUT](出力) ウィンドウが更新されます。
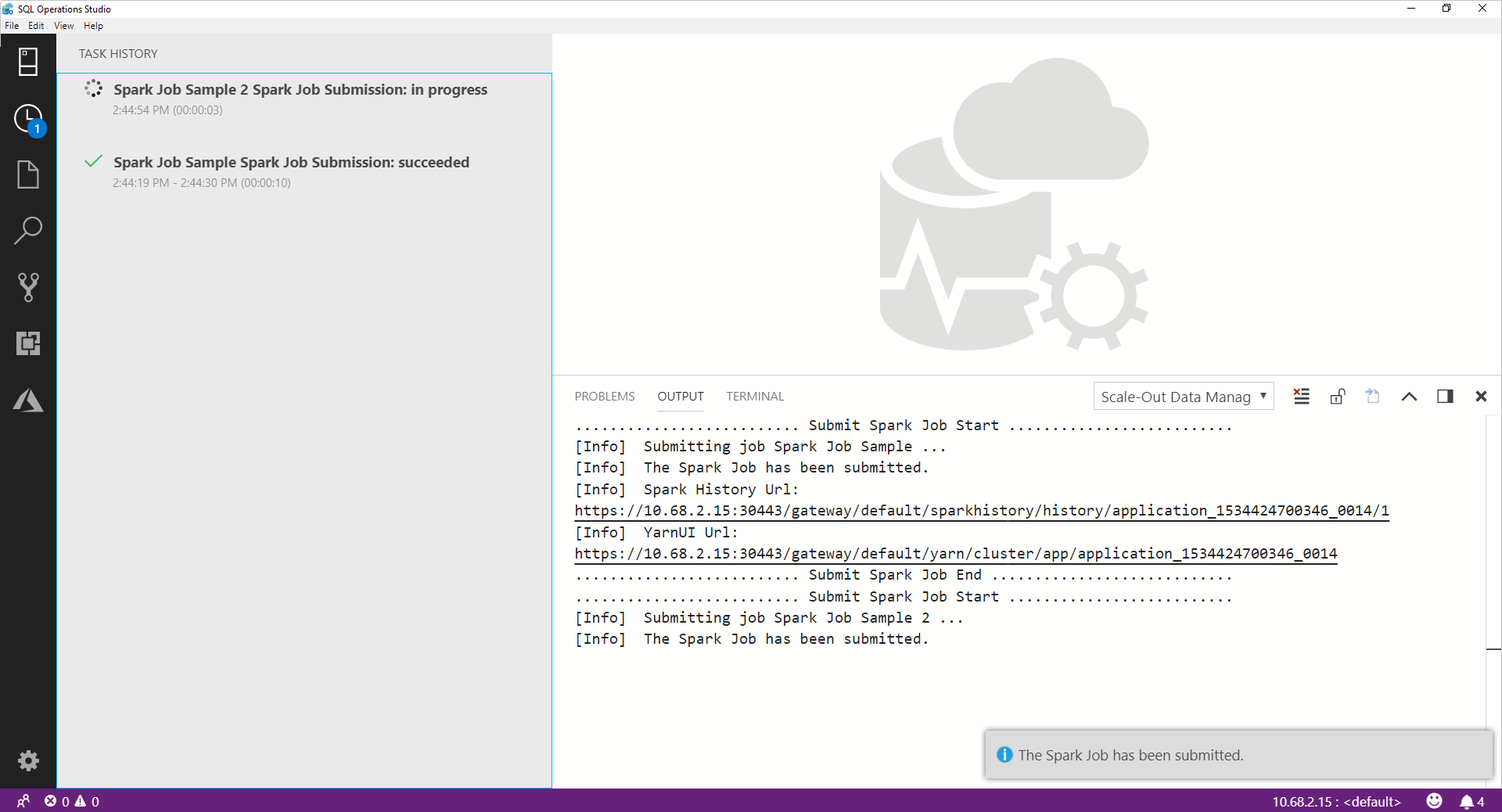
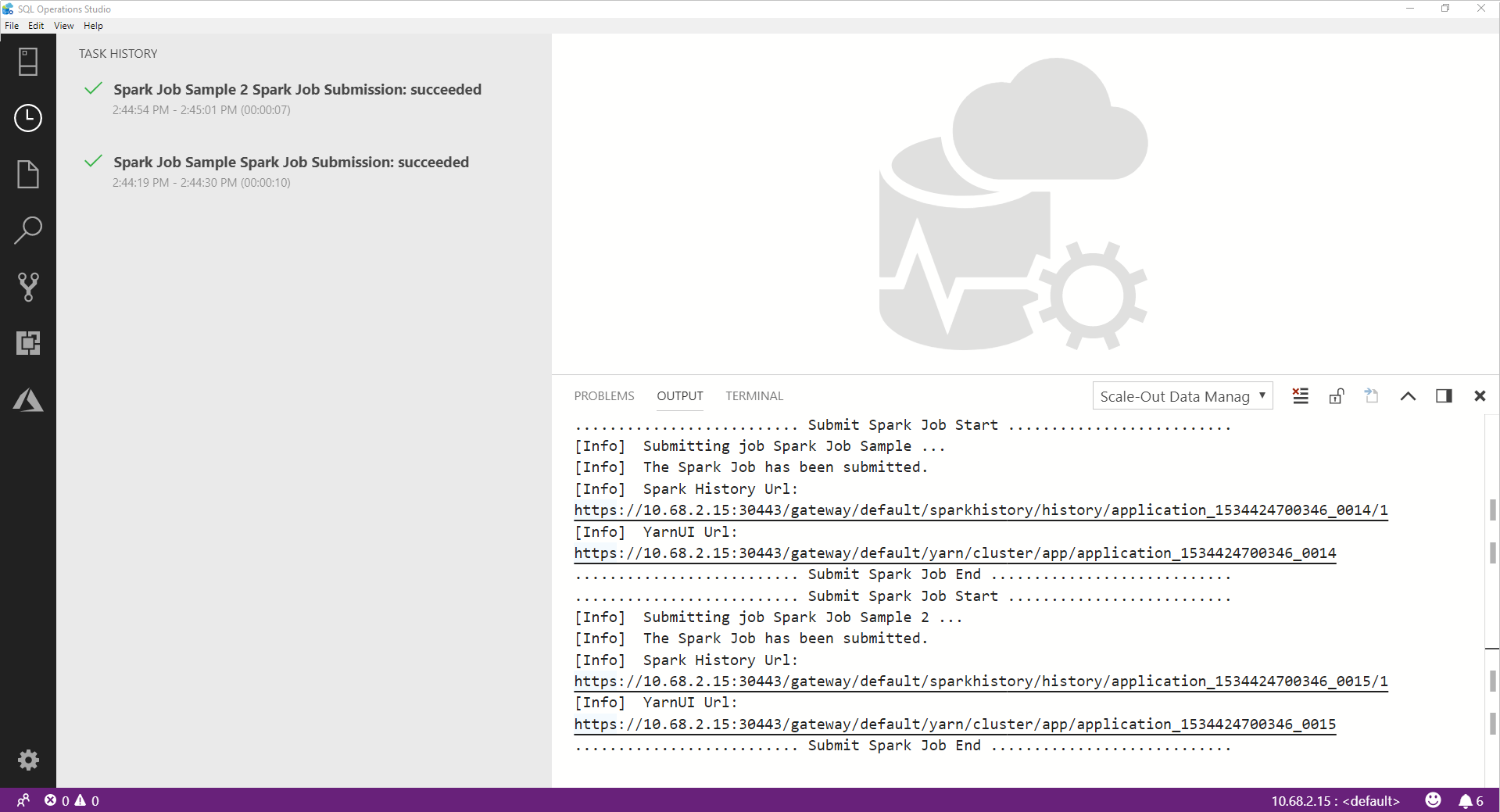
Spark ジョブが正常に完了すると、 [OUTPUT](出力) ウィンドウに Spark UI と Yarn UI のリンクが表示されます。 詳細については、リンクをクリックしてください。
次のステップ
SQL Server ビッグ データ クラスターと関連するシナリオの詳細については、「SQL Server ビッグ データ クラスターとは」を参照してください。