適用対象:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Microsoft SQL Server 2019 ビッグ データ クラスターは廃止されました。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日の時点で終了しました。 詳細については、Microsoft SQL Server プラットフォーム の発表ブログ投稿 と ビッグ データ オプションを参照してください。
SQL Server には、展開ノートブックを含む Azure Data Studio の拡張機能が用意されています。 展開ノートブックには、SQL Server ビッグ データ クラスターを作成するために Azure Data Studio 内で使用できるドキュメントとコードが含まれています。
もともとは、オープン ソース プロジェクトとして実装され、ノートブックは Azure Data Studio 内に実装されていました。 テキスト セル内のテキストに対してはマークダウンを、また、コード セル内にコードを記述するには利用可能なカーネルの 1 つを使用できます。
ノートブックを使用して SQL Server ビッグ データ クラスター を展開できます。
Prerequisites
ノートブックも起動するには、次の前提条件が要件です。
- Azure Data Studio Insiders ビルドの最新バージョンがインストールされていること
上記に加えて、ビッグ データ クラスターを展開するには、以下も必要になります。
ノートブックを起動する
Azure Data Studio を起動します。
[接続] タブで、省略記号 [...] を選択し、 [Deploy SQL Server...](SQL Server の展開...) を選択します。
展開のオプションで、 [SQL Server Big Data Cluster](SQL Server ビッグ データ クラスター) を選択します。
[オプション] 下にある [展開ターゲット] から、 [New Azure Kubernetes Cluster](新しい Azure Kubernetes クラスター) または [Existing Azure Kubernetes Service cluster](既存の Azure Kubernetes Service クラスター) のどちらかを選択します。
プライバシーとライセンス条項に同意します。
このダイアログでは、選択した種類の SQL 展開に必要なツールがホストに存在するかどうかも確認されます。 ツールの確認が成功するまで、 [選択] ボタンは有効になりません。
[選択] ボタンを選択します。 この操作により、展開エクスペリエンスが起動されます。
展開構成テンプレートを設定する
以下の手順のようにして、展開プロファイルの設定をカスタマイズできます。
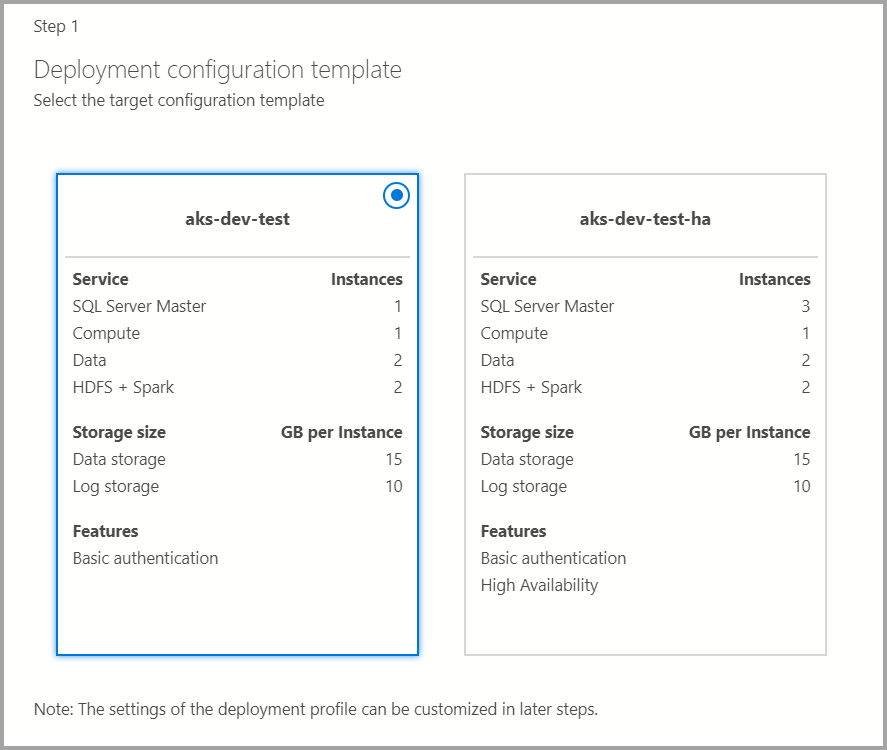
対象の構成テンプレート
使用可能なテンプレートから対象の構成テンプレートを選択します。 使用可能なプロファイルは、前のダイアログで選択した展開ターゲットの種類に応じてフィルター処理されています。
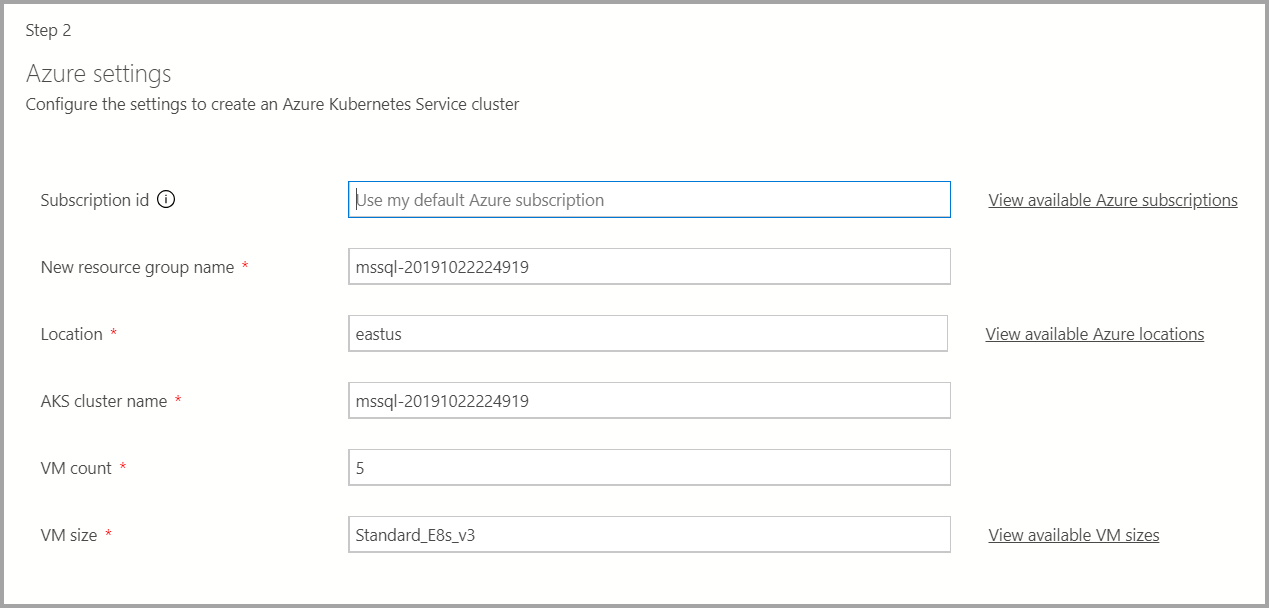
Azure settings
展開ターゲットが新しい Azure Kubernetes Service (AKS) の場合、AKS クラスターを作成するには、Azure サブスクリプション ID、リソース グループ、AKS クラスター名、VM 数、サイズ、その他の追加情報が必要です。
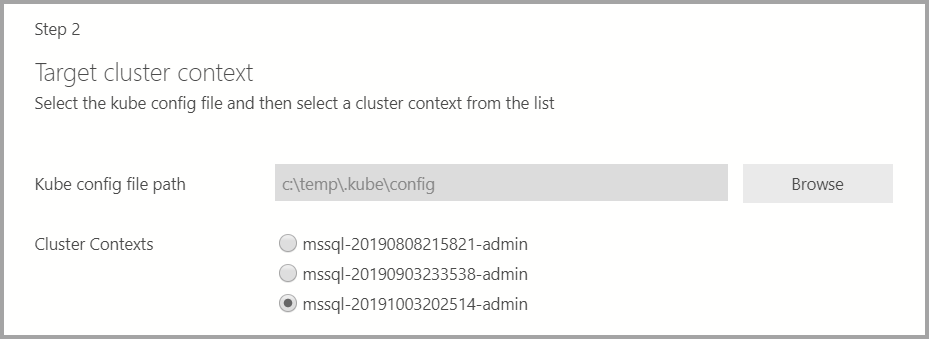
展開ターゲットが既存の Kubernetes クラスターの場合は、ウィザードによって、Kubernetes クラスターの設定をインポートするための kube 構成ファイルへのパスを入力するように求められます。 SQL Server 2019 ビッグ データ クラスターを展開できる、適切なクラスター コンテキストが選択されていることを確認します。
クラスター、Docker、AD の設定
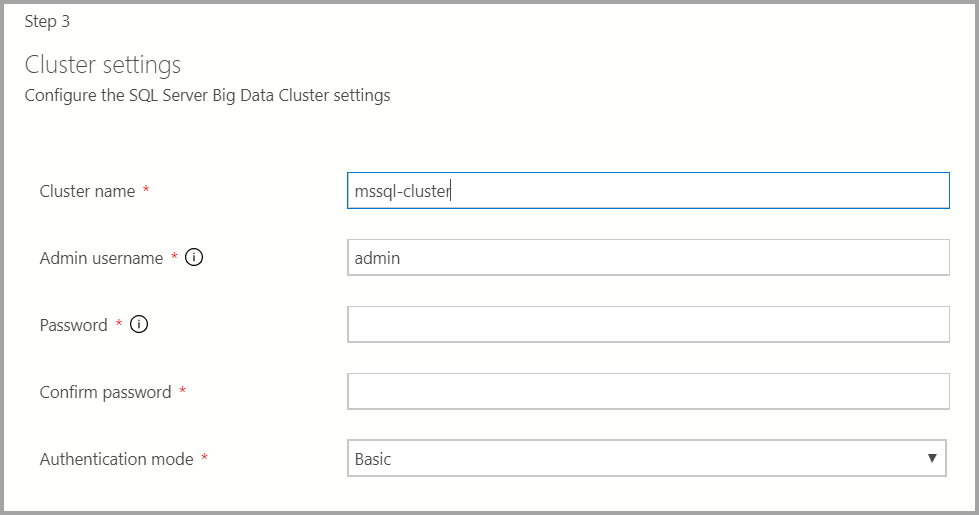
ビッグ データ クラスターのクラスター名、管理者ユーザー名、およびパスワードを入力します。 この同じアカウントは、コントローラーと SQL Server にも使用されます。
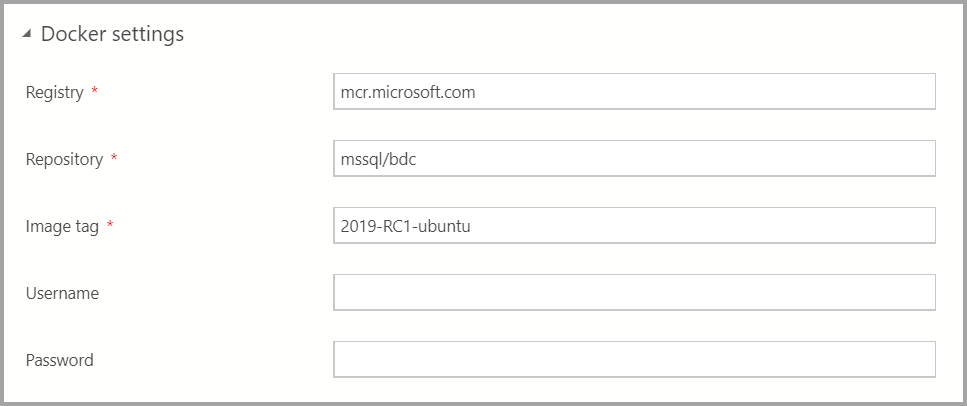
必要に応じて Docker の設定を入力します。
Important
イメージ タグ フィールドが最新であることを確認します: 2019-CU13-ubuntu-20.04
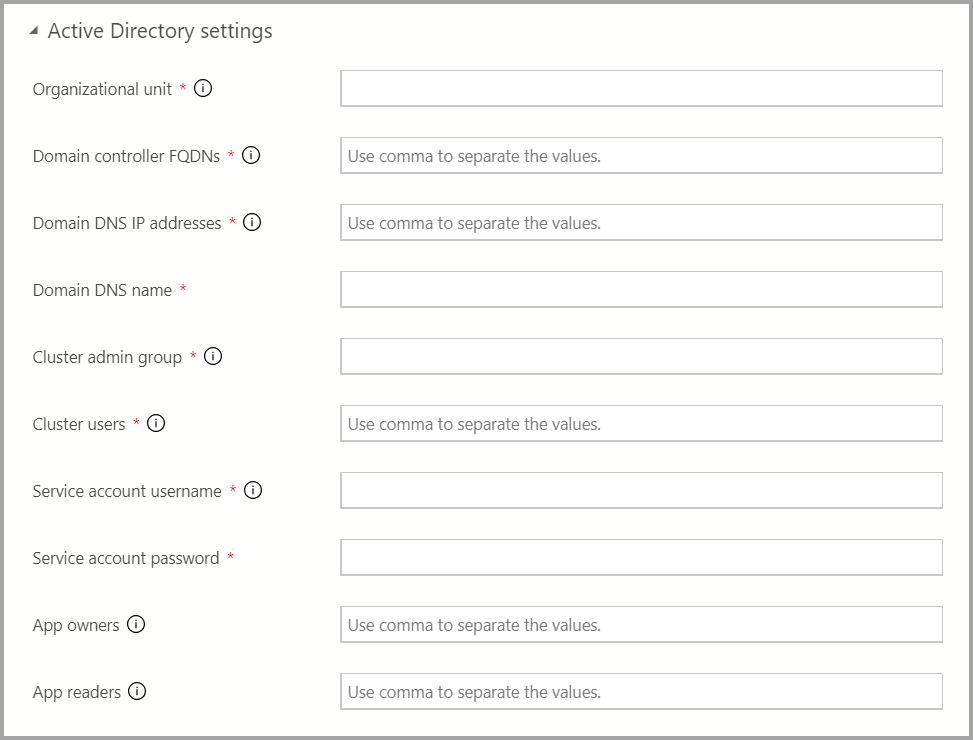
AD 認証が使用可能な場合は、AD の設定を入力します。
Service settings
この画面には、スケール、エンドポイント、ストレージ、その他の詳細なストレージ設定など、さまざまな設定の入力があります。 適切な値を入力し、 [次へ] を選択します。
Scale settings
ビッグ データ クラスター内の各コンポーネントのインスタンス数を入力します。
Spark インスタンスは HDFS に含めることができます。 それは、記憶域プールに含まれるか、または専用の Spark プールに含まれます。
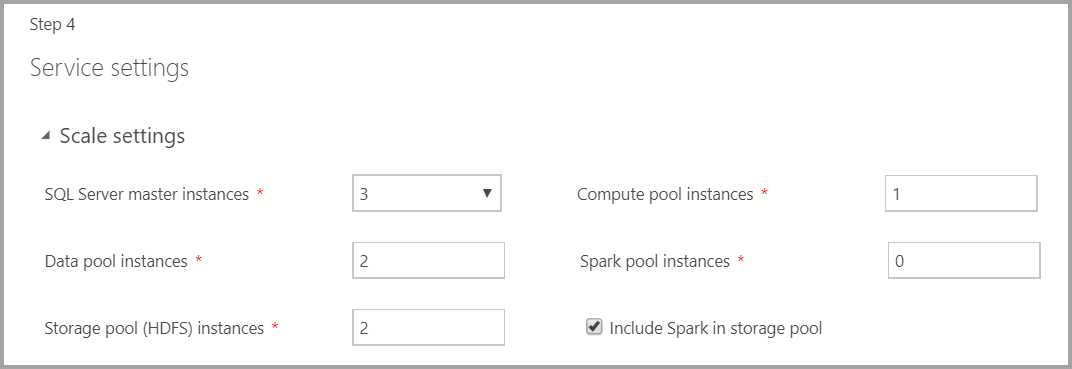
これらの各コンポーネントの詳細については、マスター インスタンス、データ プール、記憶域プール、コンピューティング プールを参照してください。
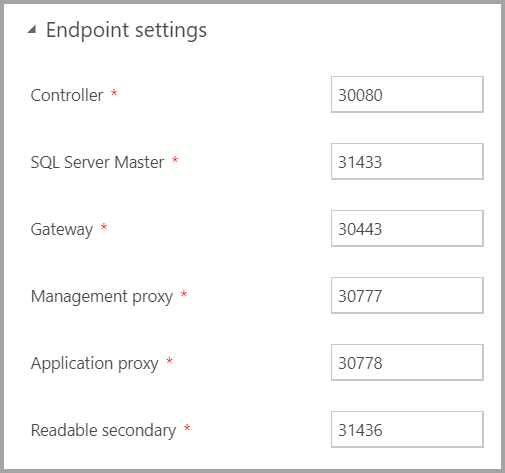
Endpoint settings
既定のエンドポイントがあらかじめ入力されています。 ただし、必要に応じて変更できます。
Storage settings
ストレージの設定には、データとログのストレージ クラスおよび要求サイズが含まれます。 設定は、ストレージ、データ、および SQL Server のマスター プール全体に適用できます。

詳細なストレージ設定
[Advanced storage settings](詳細なストレージ設定) では、その他のストレージ設定を追加できます
記憶域プール (HDFS)
Data pool
SQL Server マスター

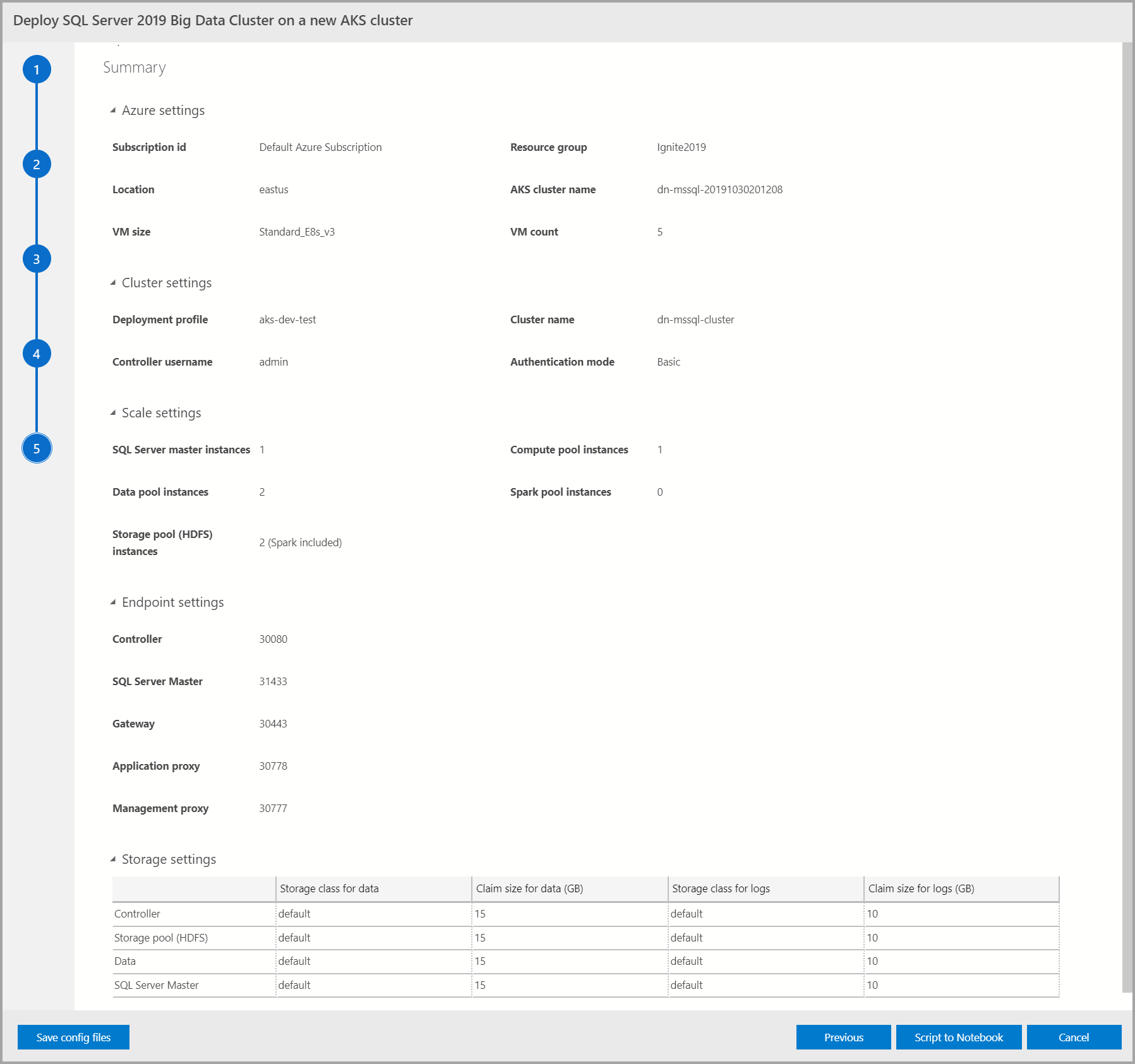
Summary
この画面には、ビッグ データ クラスターを展開するために指定したすべての入力がまとめられています。 [Save config files](構成ファイルの保存) ボタンを使用して、構成ファイルをダウンロードできます。 展開の構成全体をノートブックにスクリプト化するには、 [ノートブックへのスクリプト] を選択します。 ノートブックが開いたら、 [セルの実行] を選択して、選択したターゲットへのビッグ データ クラスターの展開を開始します。
Next steps
展開の詳細については、SQL Server ビッグ データ クラスターの展開ガイダンスに関するページを参照してください。